

Stealthwriter AI Detector Test: Does “Humanized” Writing Actually Look Human?
AI humanizers promise something students instantly understand: take a robotic draft, rewrite it, and make it sound natural. But there is a more important question hiding underneath that promise. If a tool can raise a detector score, does that mean the writing is actually better, safer, or more believable?
To answer that, 100 Stealthwriter AI rewrites were tested across five AI detectors: Copyleaks, GPTZero.me, Originality AI, Quillbot AI, and ZeroGPT. The detector results were converted into human scores, so a higher number means the text looked more human to the detector. For example, an 80% human score means the detector leaned toward “human-written,” while a 20% human score means it leaned toward “AI-written.”
The results were not simple. Stealthwriter did well against some detectors, struggled badly against others, and sometimes produced rewrites that looked human to software but still sounded awkward to a real reader.
Also Read: Can Stealthwriter AI Beat QuillBot's AI Detector? We Tested 100 Rewrites
Main Findings From 100 Samples
- Best average result: Quillbot AI gave Stealthwriter rewrites an average 81.4% human score.
- Weakest average result: GPTZero.me gave the same rewrites only a 47.2% average human score.
- Overall average across all detectors: 65.8% human across 500 total detector checks.
- Only 4 out of 100 rewrites scored 80%+ human on every detector.
- 21 out of 100 rewrites averaged below 50% human across the detector set.
The Scoreboard: Which Detectors Were Easier to Beat?
The first chart shows the average human score given by each detector. This is the simplest way to see where Stealthwriter looked strongest.
Also Read: [STUDY] StealthWriter vs Sapling AI: Can 100 Humanized Rewrites Slip Through?
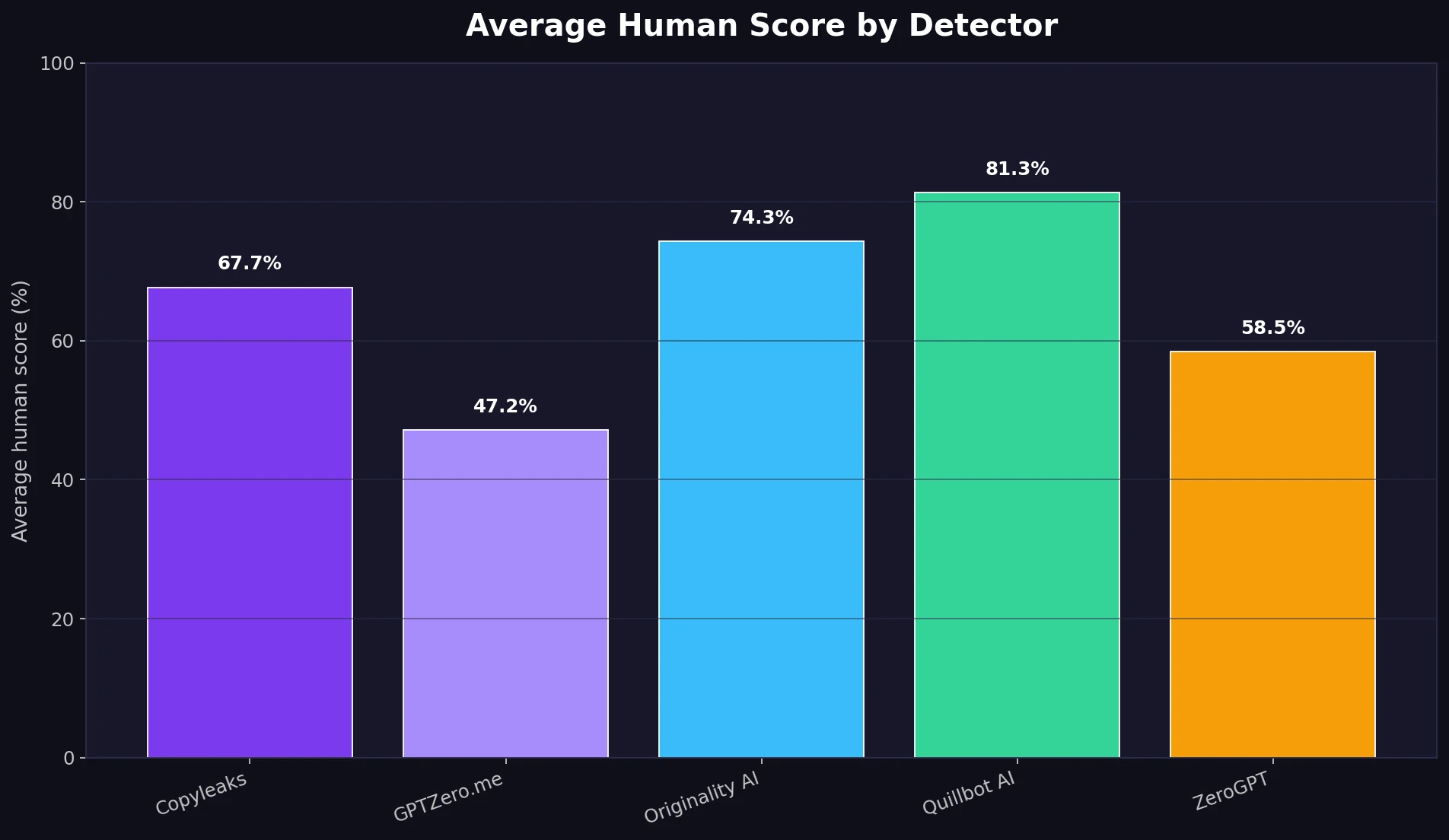
Quillbot AI was the most forgiving detector in this dataset, giving the rewrites an average score of 81.4% human. Originality AI was also relatively high at 74.3%, followed by Copyleaks at 67.7%. ZeroGPT was more cautious at 58.5%, while GPTZero.me was the hardest for Stealthwriter to pass, averaging just 47.2%.
For students, the lesson is straightforward: there is no single “AI detector result.” The same rewritten paragraph can look human to one detector and suspicious to another. That makes detector-based confidence much less stable than it may seem.
Also Read: [STUDY] Can Stealthwriter Really Bypass Copyleaks? What 100 Samples Show
Passing Scores: The 50% and 80% Question
Averages are useful, but students usually care about a more practical question: “How often did the rewrite pass?” To keep this simple, this analysis uses two lines. A 50%+ human score means the detector leaned human. An 80%+ human score means the detector gave a much stronger human-looking result.
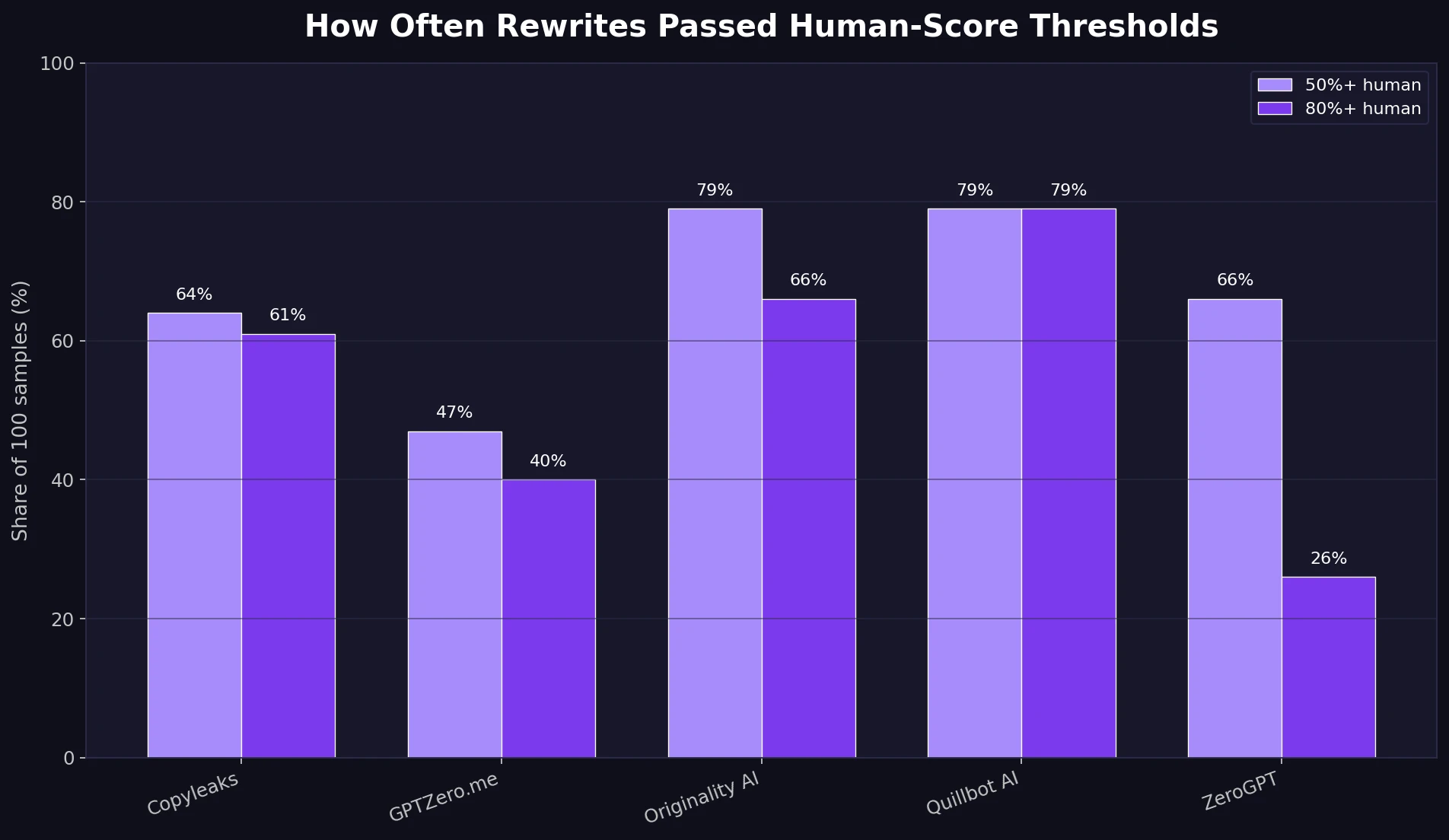
At the 80%+ human level, Stealthwriter passed 79% of samples on Quillbot AI, 66% on Originality AI, and 61% on Copyleaks. But that success dropped to 40% on GPTZero.me and only 26% on ZeroGPT.
This matters because a humanizer is not just trying to win against the easiest detector. In real academic or publishing situations, the text may be checked with different tools, updated models, or more than one detector. A rewrite that passes one scanner is not automatically protected everywhere else.
Also Read: [STUDY] Can Stealthwriter Outsmart GPTZero? A 100-Sample Test
The Bigger Problem: Detectors Disagreed A Lot
The most surprising part of the test was not that some detectors were stricter. It was how strongly they disagreed. In many samples, one detector gave a near-perfect human score while another gave almost zero.
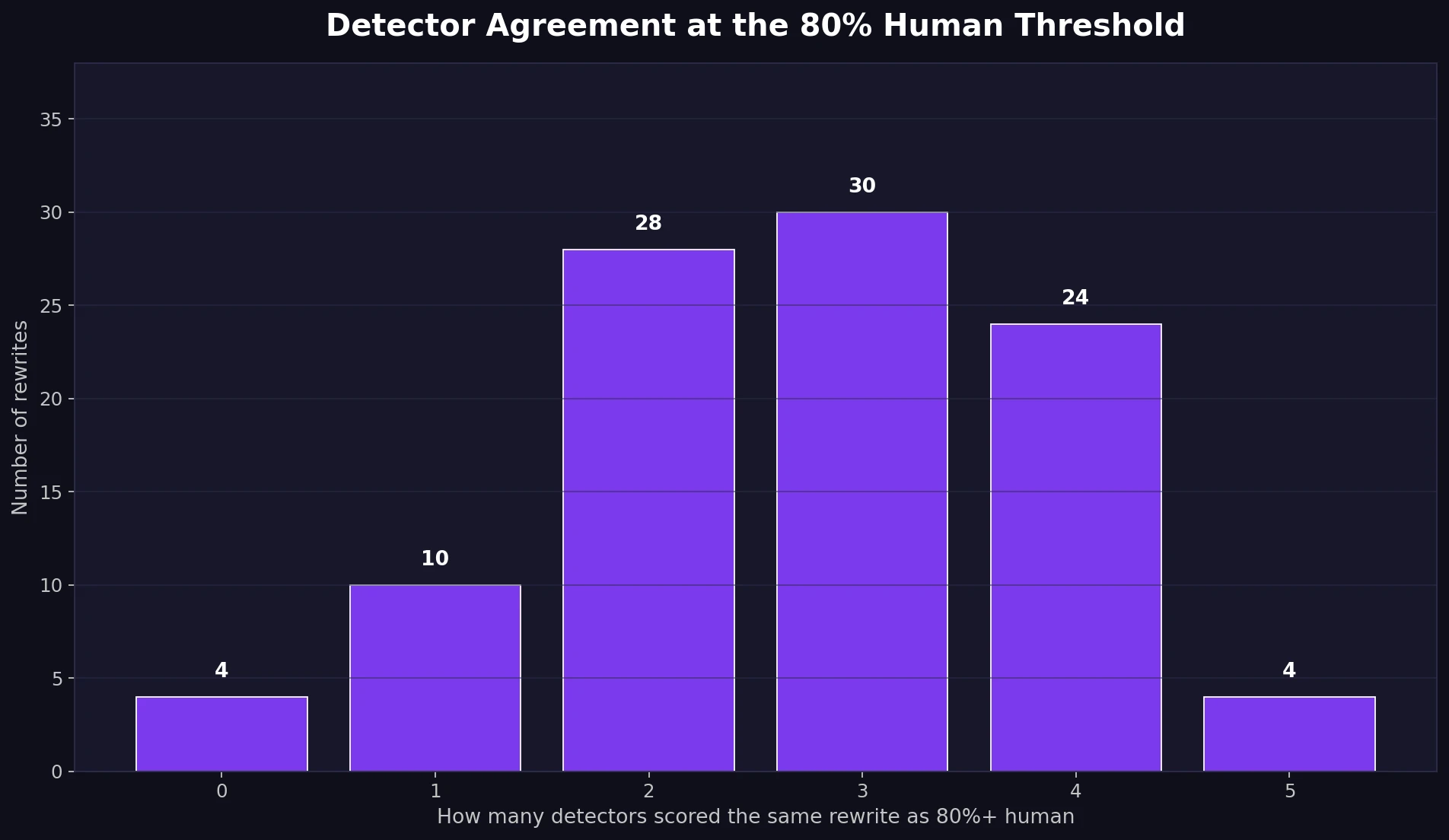
Only 4 samples cleared the 80%+ human mark on all five detectors. Another 4 samples failed to reach 80% on any detector. Most samples landed in the messy middle, where two, three, or four detectors treated the rewrite as human-looking while the others did not.
The score spread chart below shows the same issue from another angle. A “spread” simply means how far apart the scores were. When the spread is wide, the detectors are not agreeing.
Also Read: Stealthwriter vs ZeroGPT: I Tested 100 Rewrites, and the Results Were Complicated!
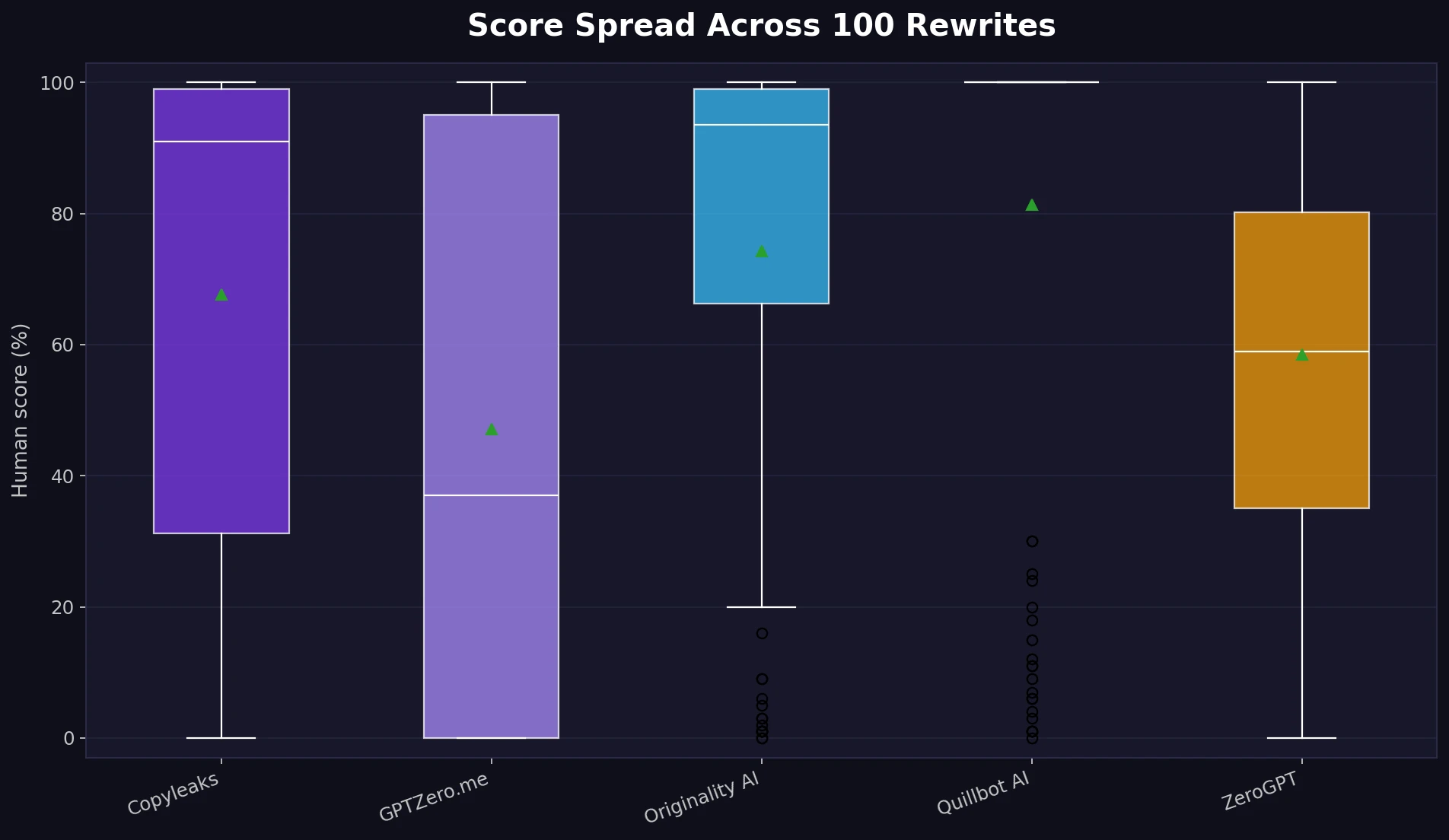
Across the dataset, the average gap between the highest and lowest detector score for the same rewrite was 80.6 percentage points. The median gap was even larger at 96.5 points. In plain English: detector results were often wildly different for the exact same rewritten text.
Human Score Does Not Mean Human Quality
Detector scores are only one part of the story. The rewritten text also needs to make sense. When the CSVs were reviewed for rewrite quality, several problems appeared that a detector score alone would not catch.
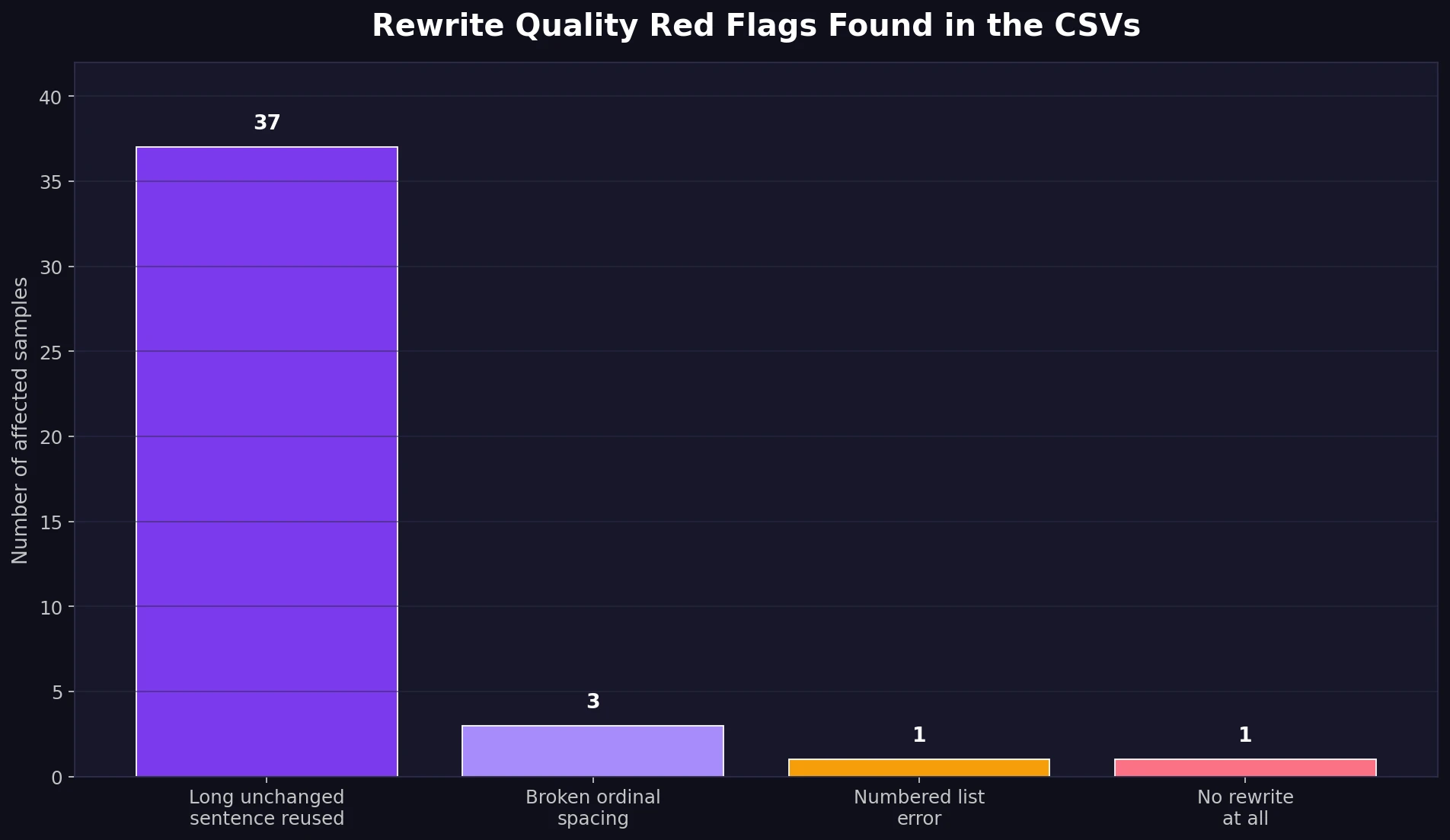
Rewrite Problems Found in the Samples
- Unchanged content: 37 samples reused at least one long sentence from the original. One sample on chaos theory appeared to be unchanged.
- Formatting slips: Some ordinal numbers were broken into forms like “17 th,” “18 th,” and “21 st.”
- List numbering mistake: One breakfast list changed the first item into “2,” creating duplicate numbering.
- Meaning changes: A rewrite said Amazon Prime “no longer” offered two-day shipping, which changes the meaning of the original point.
- Fact/name error: Chang’e from Chinese mythology was rewritten as “Changyu,” which is a clear name mistake.
- Awkward instructions: “Brew a shot of espresso” became “Grind a shot of espresso,” and one hammer-safety explanation became confusing enough to hurt clarity.
- Broken headings: “Master Selection and Masking Techniques” became “Learn to select and mask master,” which reads like a scrambled heading.
These issues are important because they show the danger of judging a rewrite only by detector scores. A student might get a high human score and still submit a paragraph with a factual error, strange phrasing, or broken formatting. In an essay, those problems can be more obvious to a teacher than an AI detector result.
What Students Should Take Away
- Stealthwriter can improve detector scores, but not reliably across every detector.
- Quillbot AI, Originality AI, and Copyleaks were easier for these rewrites to pass than GPTZero.me and ZeroGPT.
- A single high score should not be treated as proof that the writing is safe, accurate, or genuinely human.
- Manual editing is still necessary. Check facts, names, headings, lists, and sentence meaning before using any rewritten text.
Final Verdict
Stealthwriter AI showed real strength as an AI humanizer, especially when judged by the more forgiving detectors in this test. But the overall result is not a clean victory. The average across all detector checks was 65.8% human, and only 4% of rewrites passed the strong 80%+ human mark on all five detectors.
The bigger lesson is that “humanized” does not always mean “good.” Some rewrites passed detectors while still carrying awkward phrasing, formatting mistakes, reused sentences, and even meaning changes. For students, the safest conclusion is this: use AI rewriting tools as a draft assistant, not as a final answer machine. A detector may be fooled for a moment, but a careful reader will still notice unclear thinking.