![[STUDY] Does Undetectable AI Really Work?](/static/images/screenshot_2026-05-29_233723png.webp)

Everyone talks about AI humanizers as if they have cracked the code. Paste in robotic text, click a button, and suddenly every detector is supposed to wave it through. That promise is exactly why this test matters. I ran 100 rewritten samples from Undetectable AI through five different detectors and converted each detector’s AI score into a human score, where a higher number means the text looked more human. The result was not a clean win or a clean fail. It was messier, more interesting, and much more useful than a slogan.
What this test actually measured
For each of the 100 samples, I compared how the rewritten text scored on Originality AI, GPTZero, ZeroGPT, Turnitin, and Sapling. I am focusing on the rewritten output because that is what students, bloggers, and marketers actually care about: does the “humanized” version get treated like human writing?
Quick note: in this article, a human score of 100% means the detector strongly believed a human wrote it. A score of 0% means the detector strongly believed it was AI. I also use a simple 50% line as a practical pass mark. That is not a universal law, but it is an easy way to compare the tools side by side.
Also Read: Can Undetectable AI Bypass Turnitin? A 100-Sample Test Students Should Read Carefully
Big takeaways from the 100-sample test
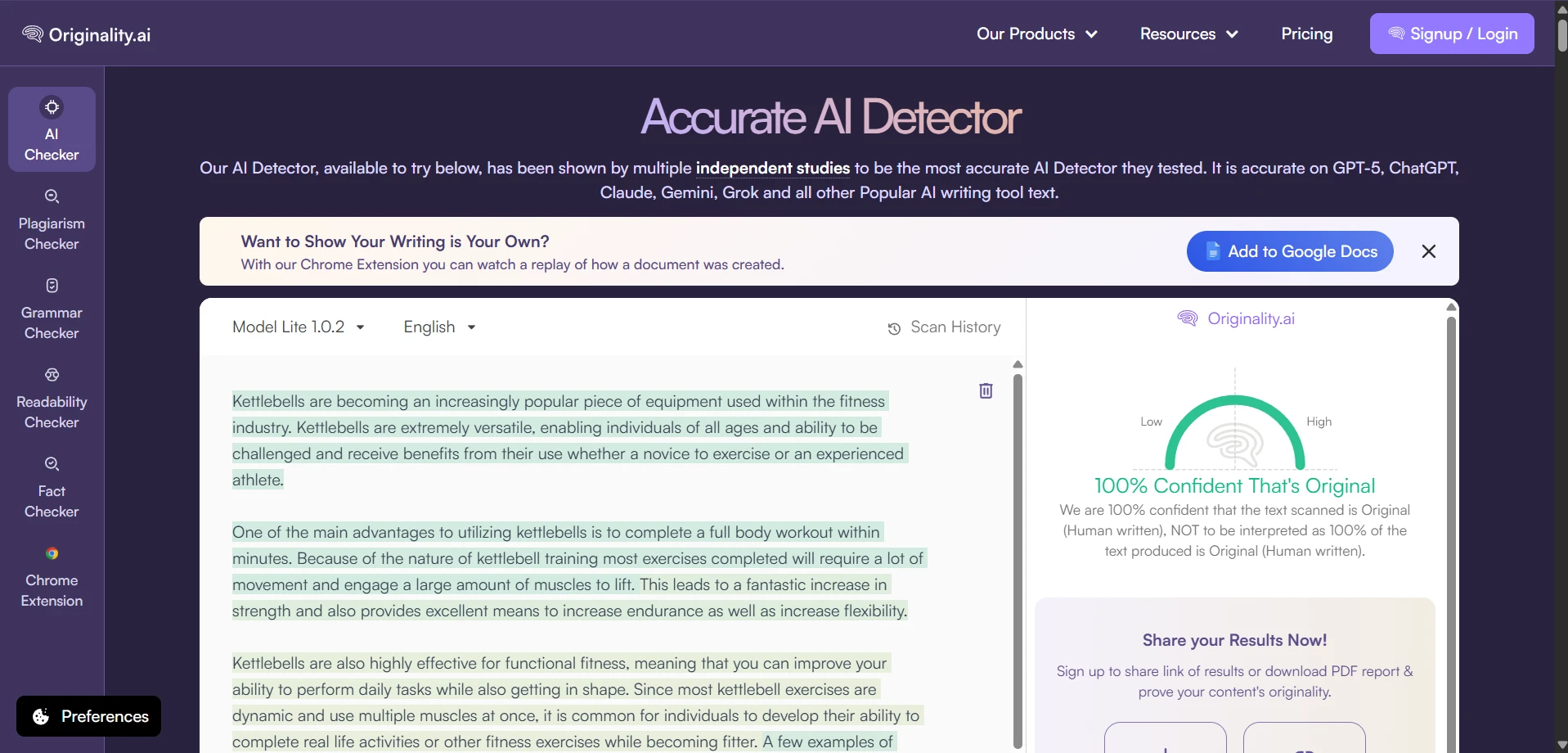
- Originality AI: average human score 92.0%; 93/100 samples reached at least 50% human.
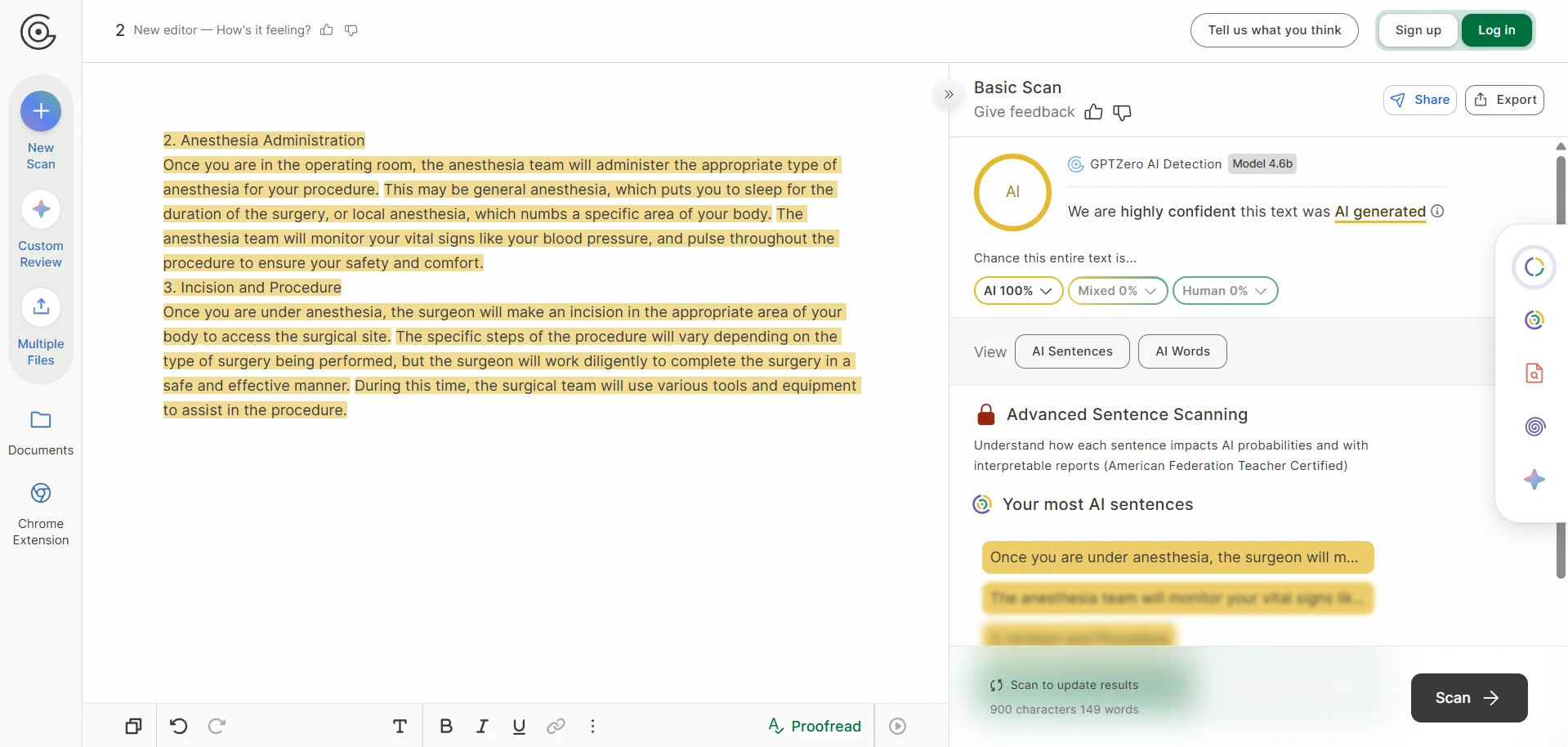
- GPTZero: average human score 91.4%; 93/100 samples reached at least 50% human.
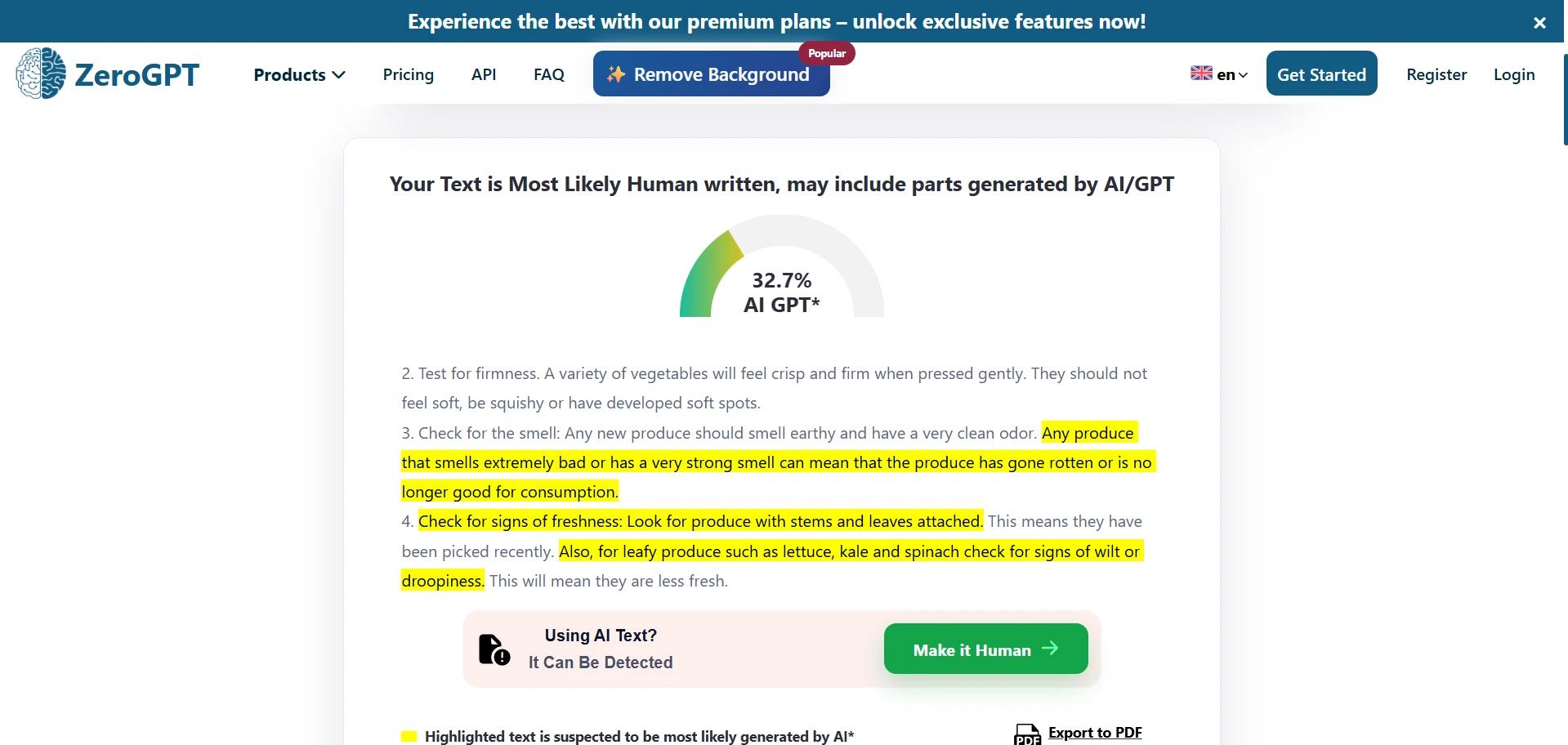
- ZeroGPT: average human score 79.2%; solid but less generous at 79.2%.
- Turnitin: mixed results, with an average of 58.9%.
- Sapling: the toughest detector in this dataset, with just 25.3% average human.
- Across all five detectors: only 16/100 samples cleared the 50% human line everywhere, while 54/100 cleared it in at least four out of five tools.
So, does Undetectable AI really work?
The honest answer is yes in some places, no in others.
If your only question is whether Undetectable AI can raise human-looking scores, the answer is clearly yes. On average, it performed extremely well against Originality AI and GPTZero. It also did reasonably well against ZeroGPT. But the word undetectable goes too far. Against Sapling, the same rewritten texts usually did not look human at all. Turnitin sat in the middle: sometimes impressed, sometimes not.
Also Read: Can Undetectable.ai Really Slip Past Sapling AI? We Tested 100 Rewrites to Find Out.
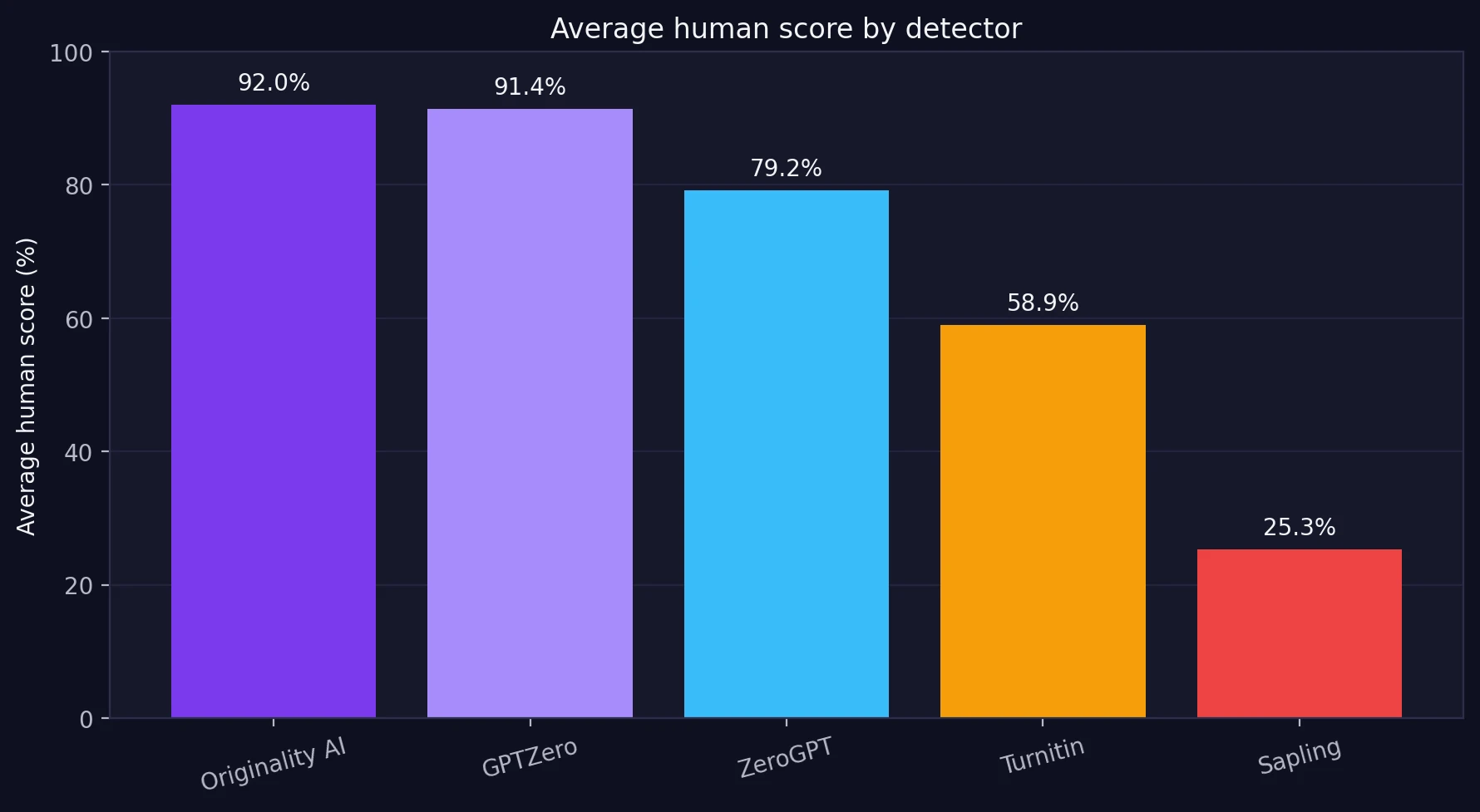
The first chart makes the core story hard to ignore. Originality AI (92.0%) and GPTZero (91.4%) were the easiest to fool overall. ZeroGPT (79.2%) still leaned in Undetectable AI’s favor, but not as strongly. Turnitin (58.9%) was inconsistent. Sapling (25.3%) was the clear holdout.
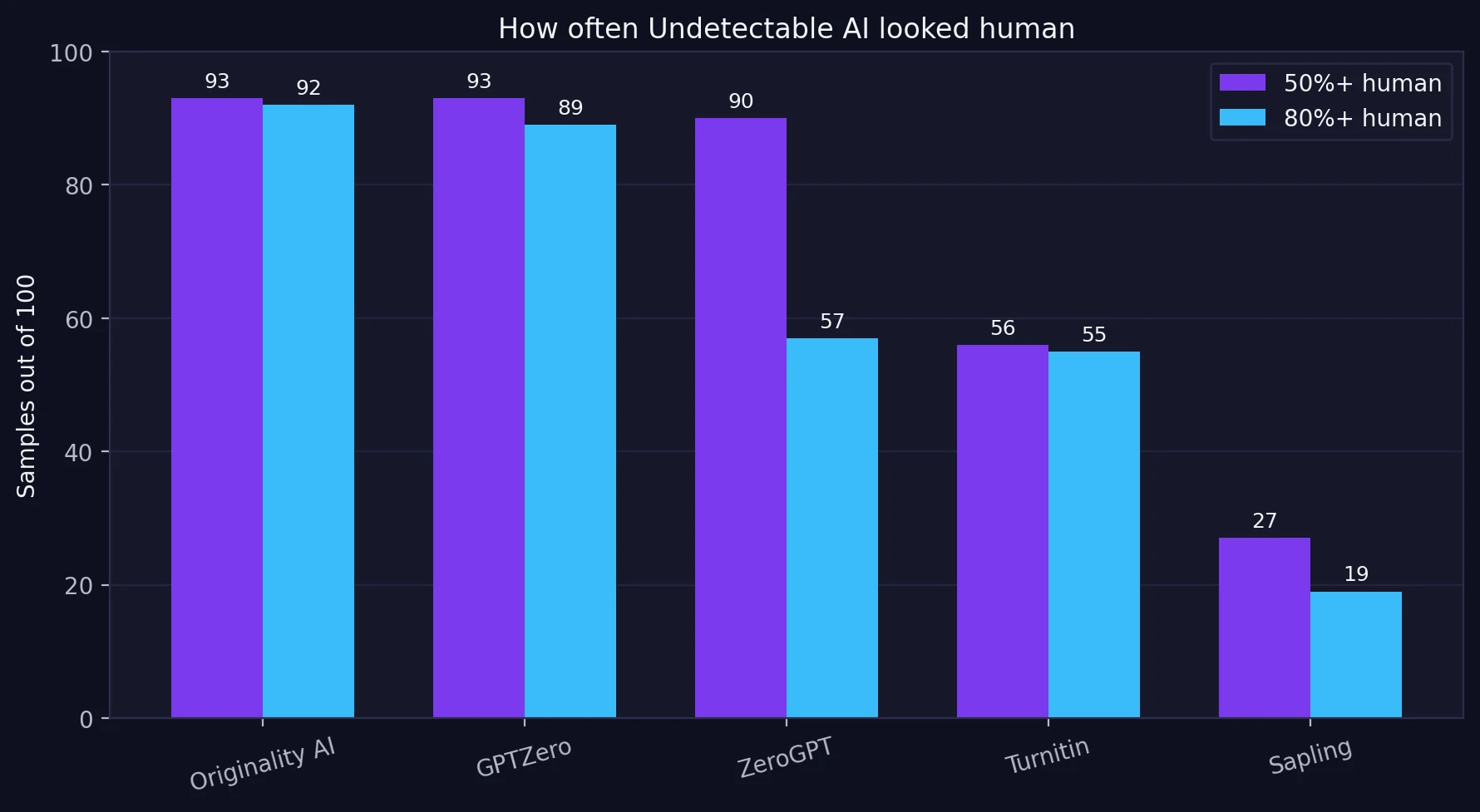
The threshold view tells a similar story. Undetectable AI crossed the 80% human mark in 92 Originality AI tests and 89 GPTZero tests, but only 19 Sapling tests. That gap matters because it shows this is not a universal bypass. It is more like a detector-by-detector gamble.
The bigger surprise: the detectors disagreed with each other constantly
This may be the most important lesson for students. A detector score can look authoritative, but the tools in this dataset often behaved like they were reading different pieces of text. In 72/100 samples, at least one detector gave a near-certain human verdict while another gave a near-certain AI verdict on the same rewrite. The median gap between the strictest and most forgiving detector on a single sample was 99 points.
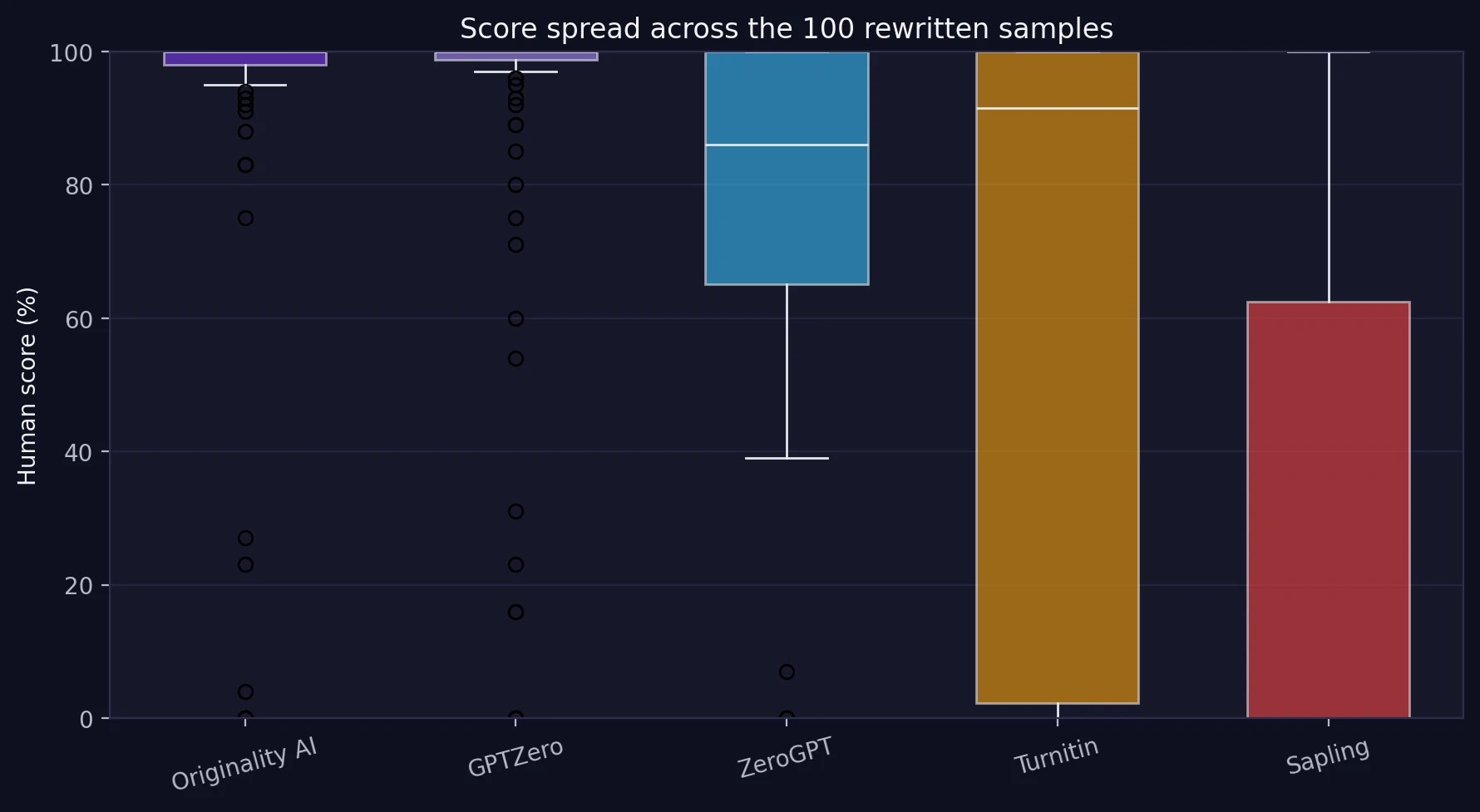
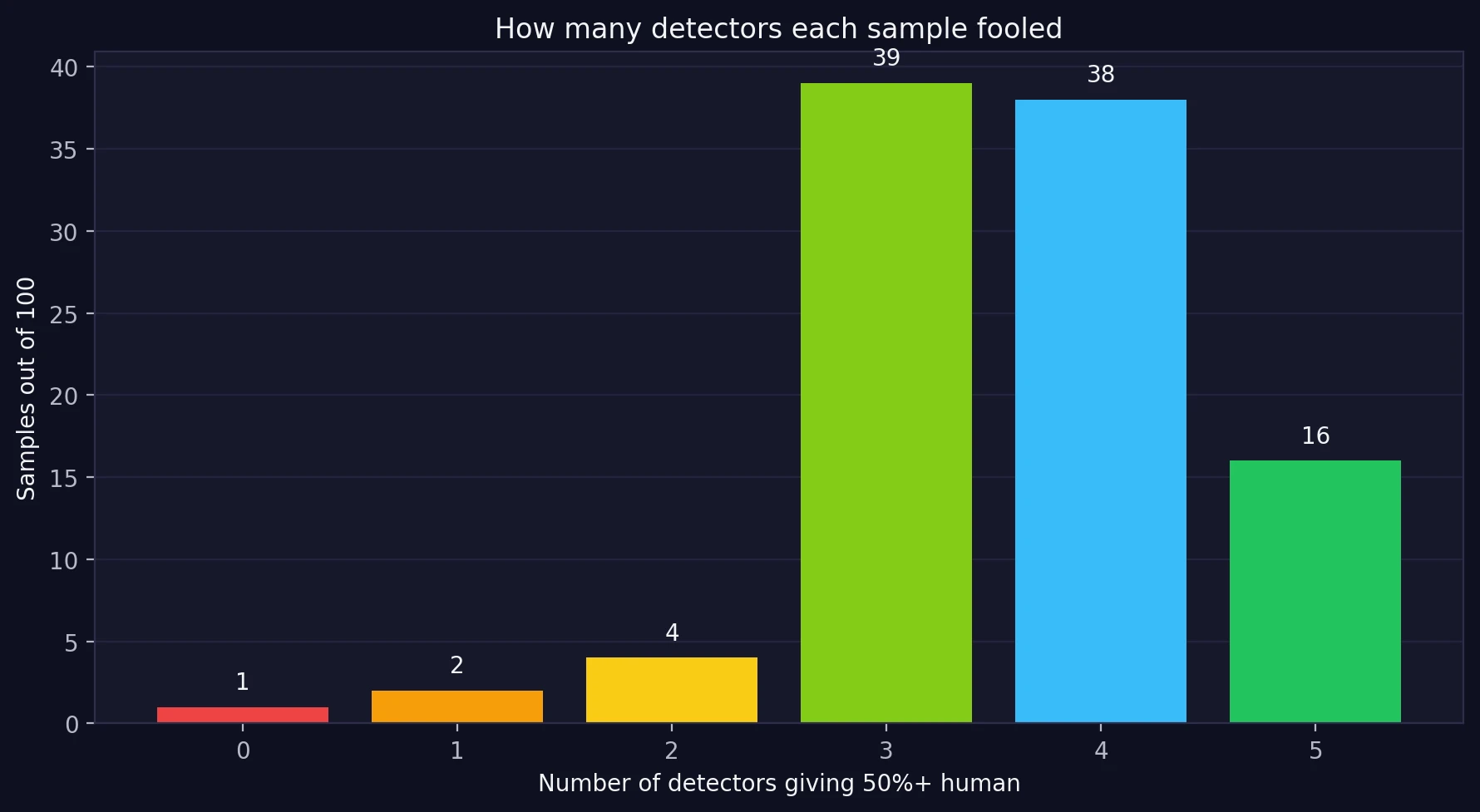
That is why a single screenshot is never the whole story. In this test, 16 samples fooled every detector at the 50% line, but 1 failed everywhere. Most sat in the middle. In plain English: Undetectable AI often improved its chances, but it did not become invisible.
Also Read: [STUDY] Can Undetectable AI Bypass GPTZero? A 100-Sample Reality Check
Bypassing a detector is not the same as producing a strong rewrite
This is where the experiment becomes more interesting than a scoreboard. I also screened the rewritten texts themselves for obvious rewrite problems. Some of them passed detectors while still showing signs of low-quality editing.
- 1 sample was effectively an exact copy of the source text.
- 18 samples changed or added numbers and dates.
- 9 samples were noticeably shorter than the source, suggesting loss of detail.
- 7 samples showed formatting or stitching glitches, such as mashed words or broken sentence joins.
- 4 samples looked cut off before the thought was finished.
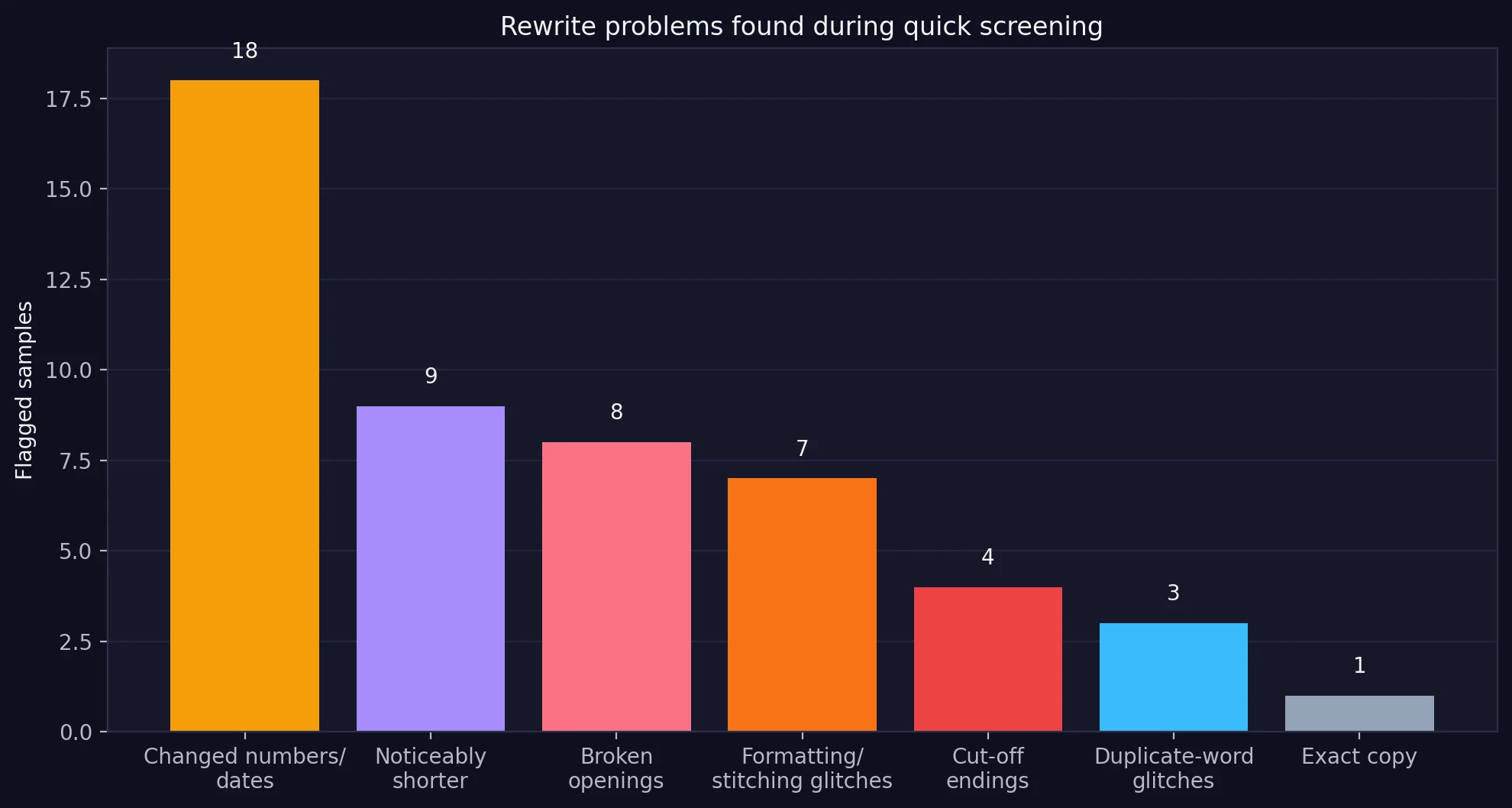
Some examples were hard to miss. One rewrite inserted a new “24/7” claim that was not in the source. Another brought in the phrase “2 Degrees initiative”, adding context that the original text did not include. In another case, words were visibly stitched together into broken phrasing like “King1332” or “Useboards”. Those are not tiny style changes. They are signs of meaning drift and text corruption.
Meaning drift simply means the rewrite starts saying something slightly different from the original. That matters. A paragraph can earn a high human-looking score and still become less accurate, less clear, or less trustworthy.
Also Read: [STUDY] Can Undetectable AI Bypass Originality AI? A 100-Sample Reality Check
What students should take from this
If you are a student, the main lesson is not “this tool beats that tool.” It is that AI detection is still unstable, and rewrite tools introduce their own risks.
- Do not treat one detector score as final truth. This dataset showed huge disagreements across tools.
- High human scores do not guarantee high-quality writing. Some rewrites looked more human to detectors while becoming worse for real readers.
- Human review still matters. Read the rewrite carefully for broken logic, changed facts, awkward wording, and missing details.
- “Undetectable” is marketing language, not a scientific guarantee. It worked very well against some detectors and very poorly against others.
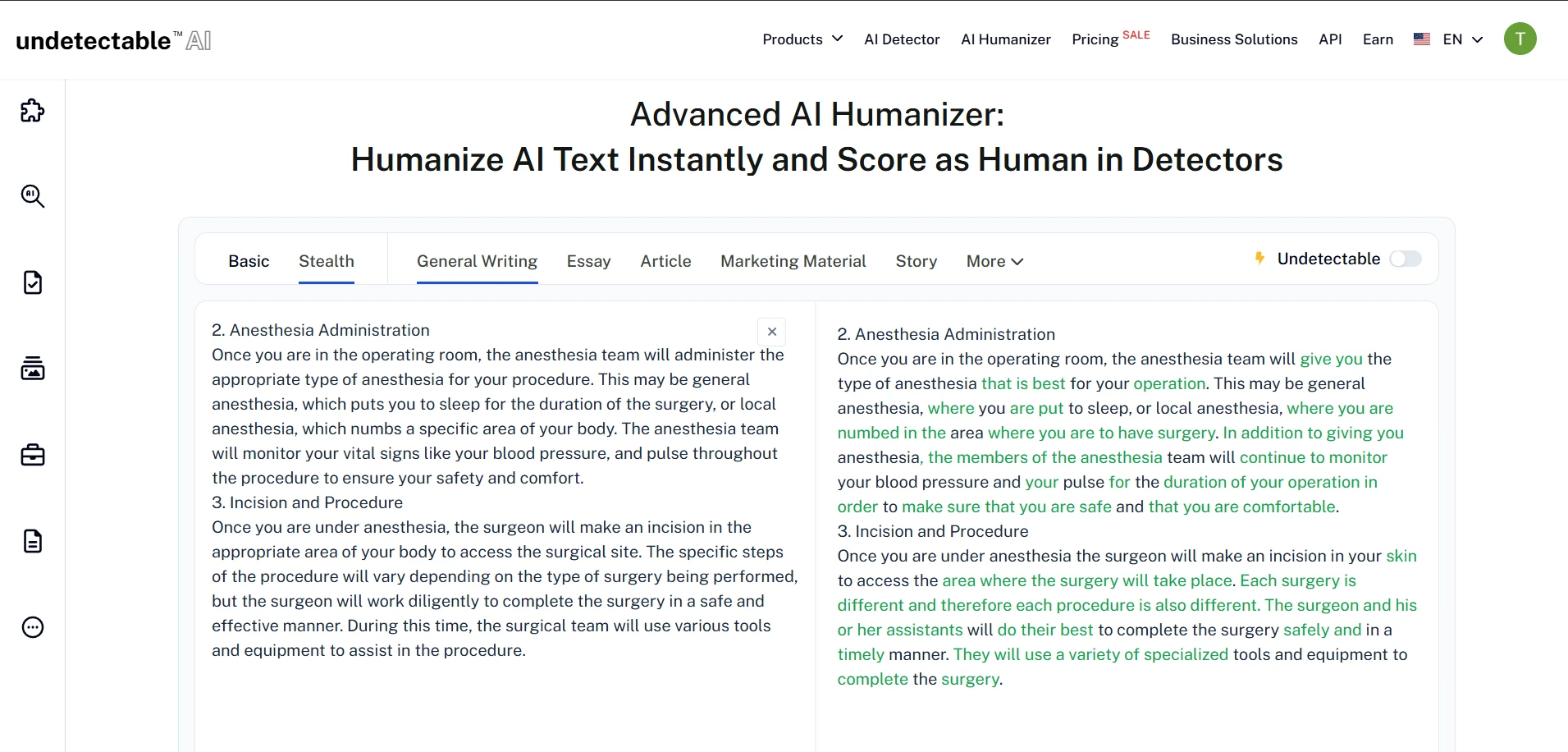
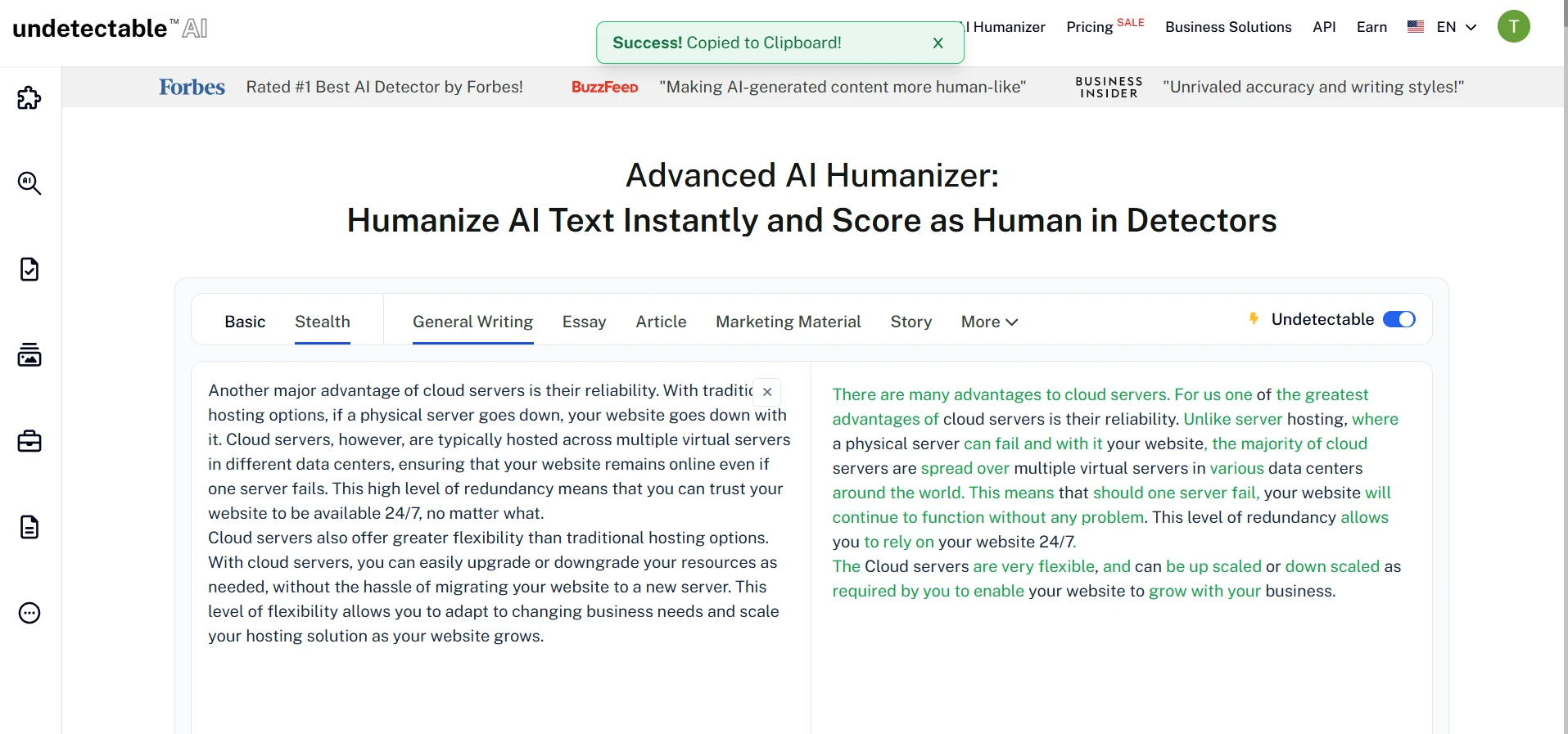
The verdict
Undetectable AI does work sometimes, but not in the way its name suggests. In this 100-sample test, it was highly effective against Originality AI and GPTZero, fairly effective against ZeroGPT, unpredictable against Turnitin, and weak against Sapling.
The more important finding is that bypassing a detector is only half the story. A rewrite that scores as “human” can still contain broken formatting, changed facts, cut-off ideas, or awkward wording. For students and anyone publishing serious work, that means the smartest question is not just Can this fool a detector? It is What does the rewrite do to the quality and meaning of the writing?