

A high detector score can look impressive on a dashboard. But students do not submit dashboards—they submit sentences. In this test, Undetectable AI often pushed ZeroGPT toward a more human-looking result. At the same time, many rewrites became longer, clumsier, and sometimes stranger. The big takeaway is simple: detector evasion and good writing are not the same thing.
How This Test Was Set Up
I worked with a dataset of 100 original passages. Each one was rewritten with Undetectable AI and then checked in ZeroGPT. ZeroGPT gives an AI score, but for clarity I converted that into a human score. That means:
- 100% = ZeroGPT treated the passage as fully human.
- 0% = ZeroGPT treated the passage as fully AI.
- Higher scores are better if your goal is to make AI text look human to ZeroGPT.
This is an important limit to keep in mind: the study measures how ZeroGPT reacts, not whether the rewrite is actually strong, accurate, or worth turning in. That difference matters a lot for students.
Also Read: [STUDY] Can Undetectable AI Bypass GPTZero? A 100-Sample Reality Check
What Stands Out Right Away
- Average human score: 79.2% across all 100 rewrites.
- Median human score: 86%. The median is the middle value after sorting all scores, so it helps show the typical result without being skewed by a few extremes.
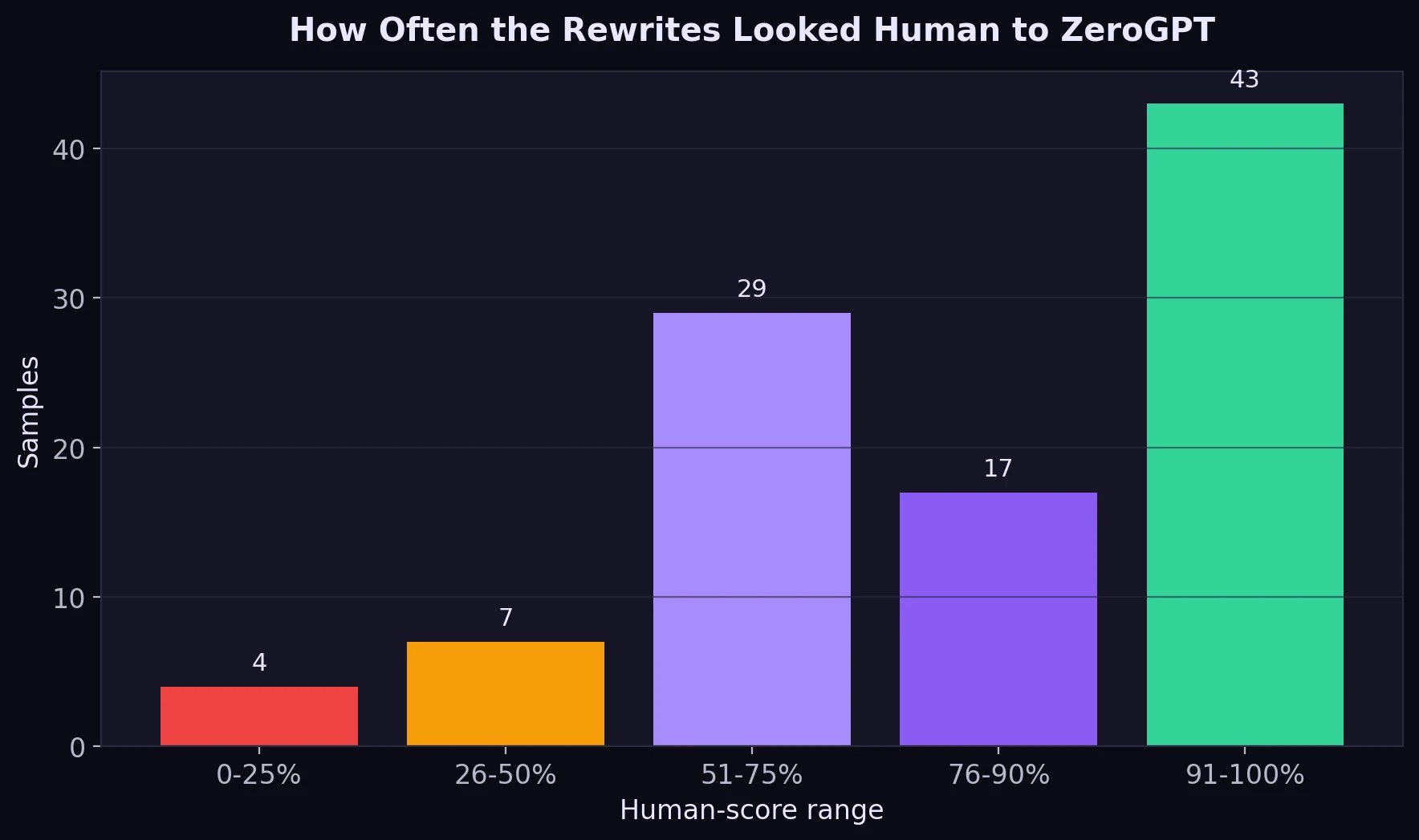
- High-end results: 43 out of 100 samples landed in the 91% to 100% range.
- Weak results still existed: 11 samples scored 50% human or lower.
- Length inflation: the rewrites were about 23% longer on average, which suggests the tool often adds words to sound more human.
The First Pattern: Undetectable AI Often Helps, but It Is Not a Guaranteed Pass
The overall score distribution leans positive. Most of the dataset sits above the halfway mark, and a large chunk lands very high. That tells us Undetectable AI is often effective against ZeroGPT, at least in a one-detector test like this one.
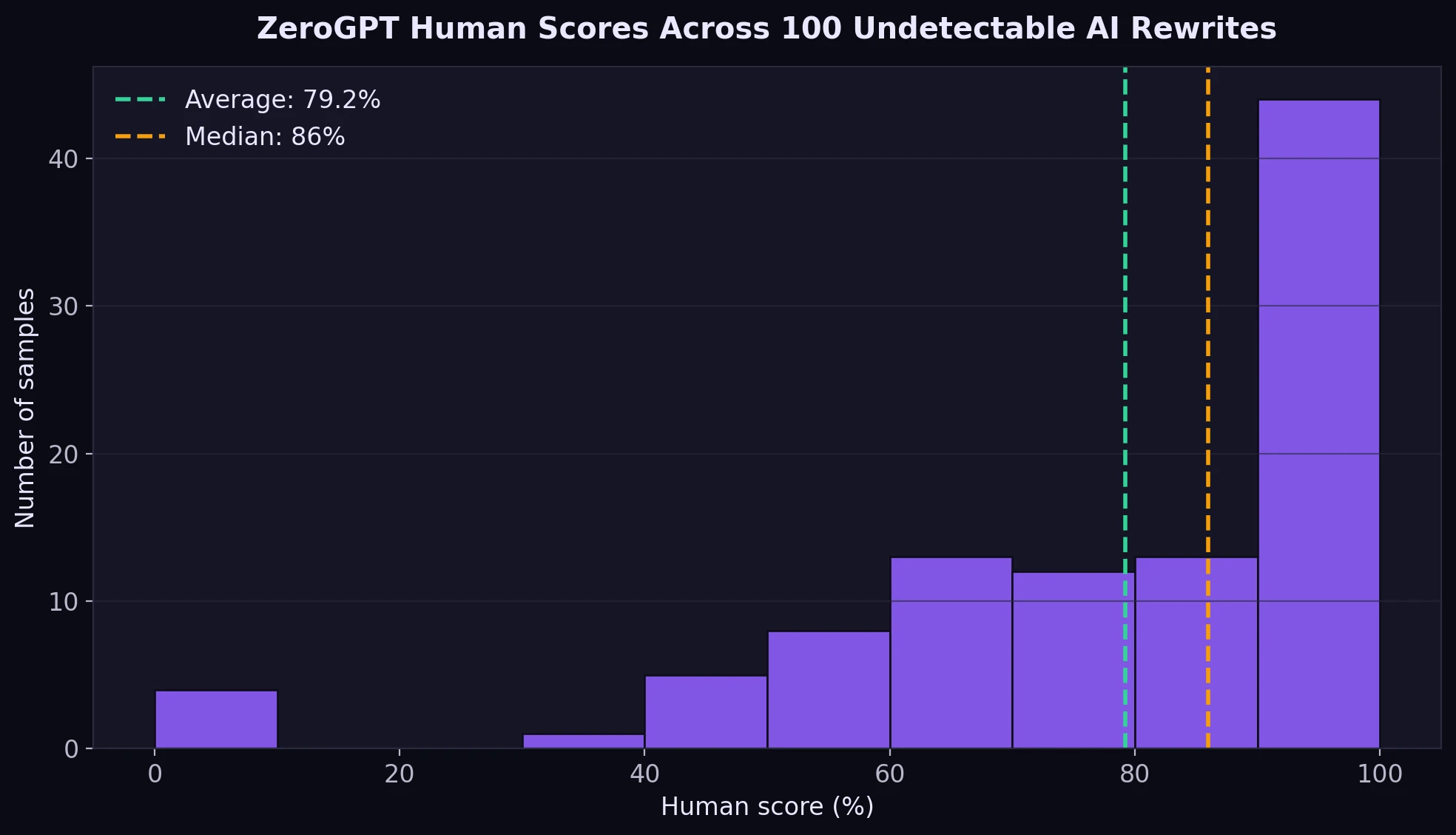
The bucket view makes that even clearer. Nearly half the dataset scored above 90% human, which is a very strong result. But the bottom of the chart matters too: some rewrites still looked obviously AI-like to ZeroGPT.
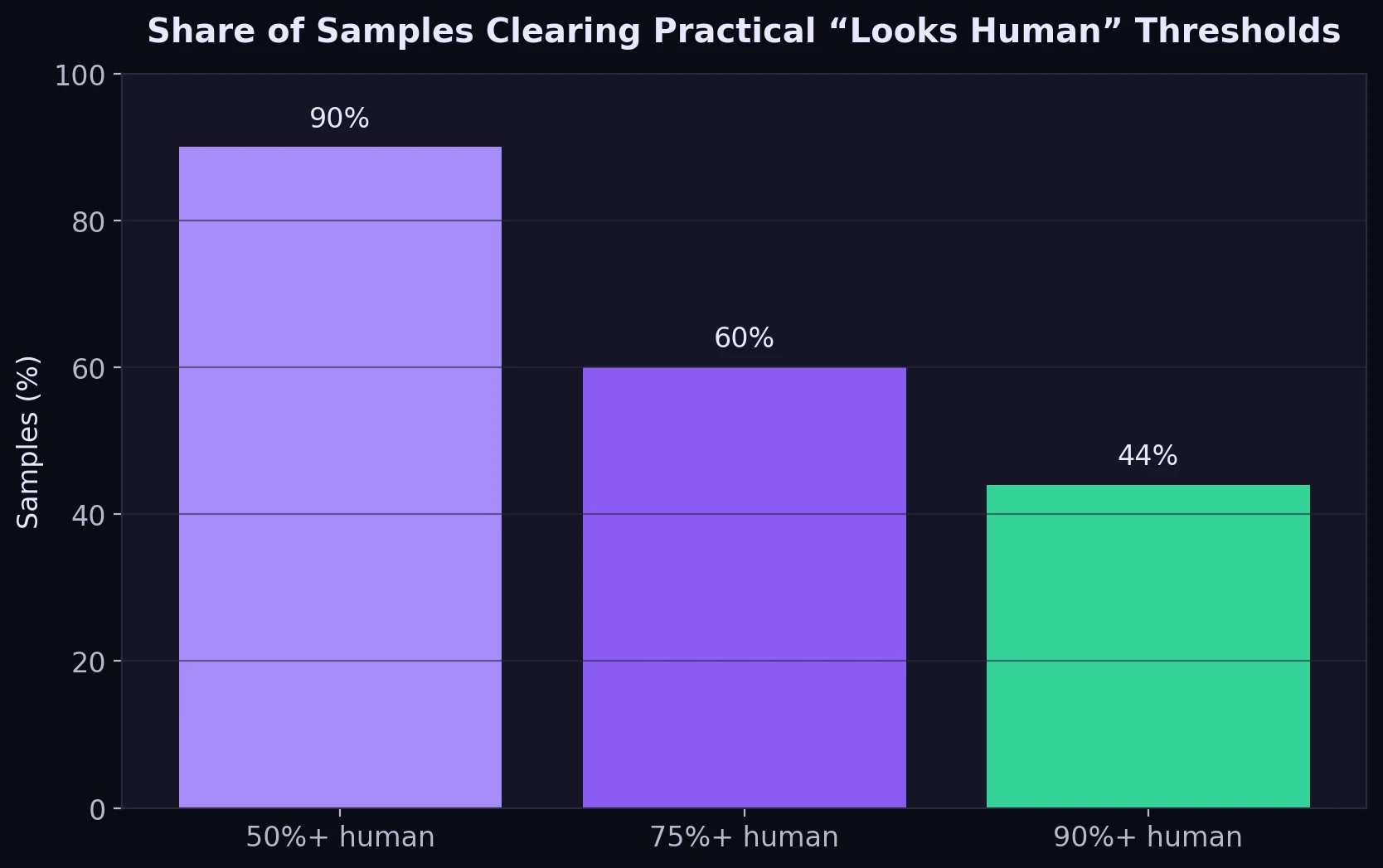
If you think in terms of practical thresholds, the story becomes easier to read:
- 90% of samples cleared 50% human.
- 60% cleared 75% human.
- 44% cleared 90% human.
That is good enough to call the tool useful, but not good enough to call it reliable in every case.
Also Read: [STUDY] Can Undetectable AI Bypass Originality AI? A 100-Sample Reality Check
The Second Pattern: The More Aggressively It Rewrites, the Better It Usually Scores
I also compared each original passage with its rewritten version to see how much wording stayed the same. Put simply, I measured word overlap. Lower overlap means a more aggressive rewrite. Higher overlap means the tool stayed closer to the original phrasing.
That relationship mattered a lot. The most aggressive quarter of rewrites averaged about 90.3% human, while the quarter that stayed closest to the original averaged only about 59.8% human.
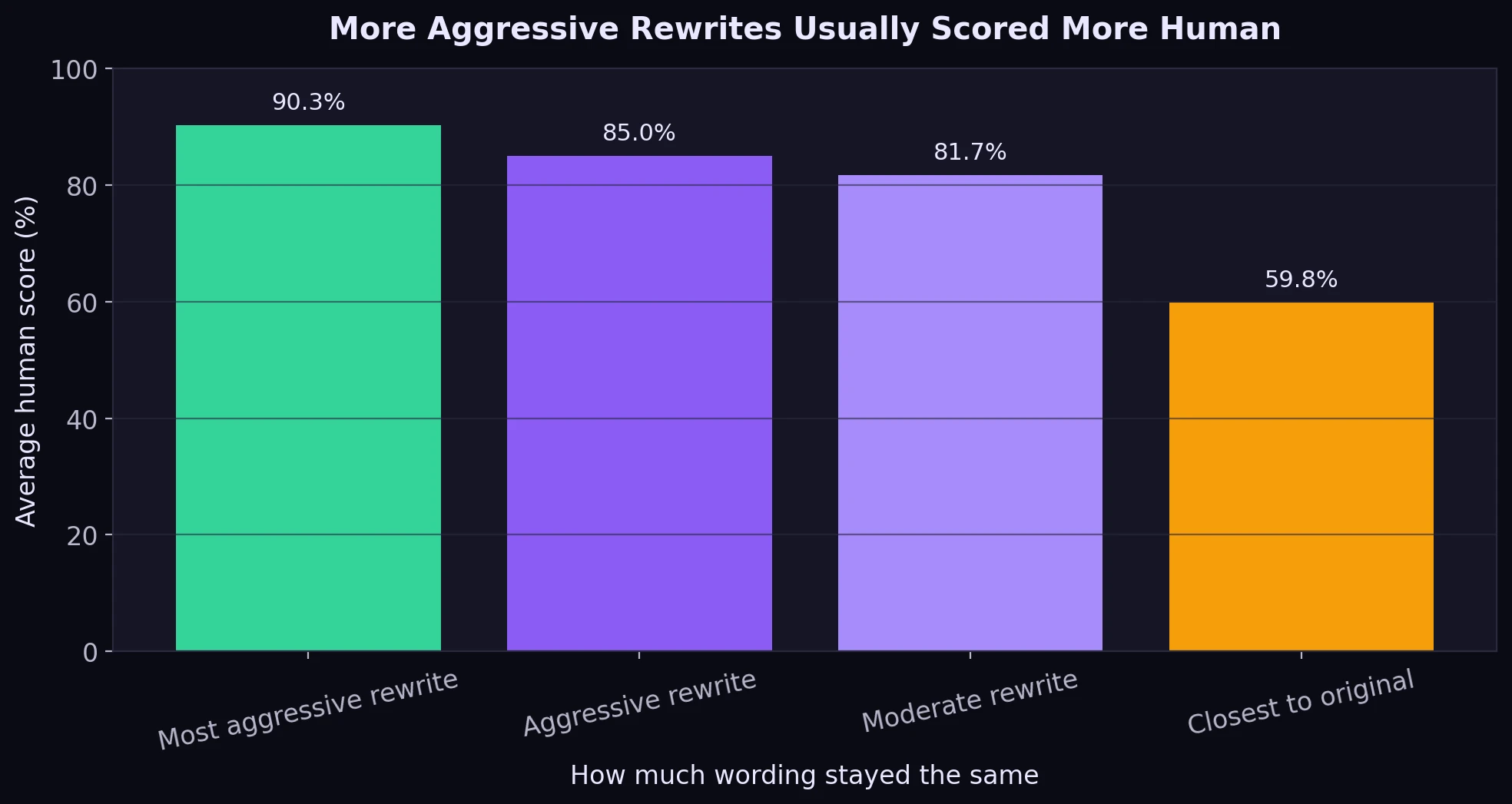
In simple terms, ZeroGPT was often harder to fool with light editing, but easier to fool when the text was heavily reshaped. That sounds like a win for the humanizer—until you actually read some of the rewritten passages.
Here Is the Catch: Better Scores Often Came with Worse Writing
This was the most interesting part of the CSV. A close read of the rewrites showed that strong detector scores did not always mean strong output. In fact, some of the highest-scoring passages were among the messiest to read.
Across the dataset, I repeatedly found several rewrite problems:
- Meaning drift: the rewrite kept the topic but changed the claim, softened it, exaggerated it, or added details that were not in the source.
- Formatting damage: headings, numbering, and punctuation were sometimes changed in awkward ways.
- Grammar breaks: some passages looked like English, but not natural English.
- Gibberish or broken phrasing: a few lines were clearly worse than the original even when they scored very high.
- Wordy inflation: the tool often added filler rather than clarity.
Examples of Rewrite Problems Found in the CSV
Some examples were hard to ignore. One passage about the Golden Ratio produced the line “She is not only found in art”, which turns a mathematical concept into a person. Another rewrite about soundproofing produced “Weather your home through the edges of your doors and windows”, which is not what the original meant at all.
“A the railways...” / “The in the home is in the kitchen” / “high high water marks and low low water marks”Those are not isolated slips. I also found duplicated headings, random capitalization, repeated words, and lines that read like a machine trying to imitate a human voice one clause at a time. In a few places the rewrite added new details—for example extra descriptive wording or stronger claims—without clear support from the original.
For students, that matters. A detector might be fooled by surface-level variety, but a teacher still reads for clarity, logic, and accuracy. If a rewritten sentence sounds unnatural or drifts away from the source idea, the detector score stops being the most important part of the assignment.
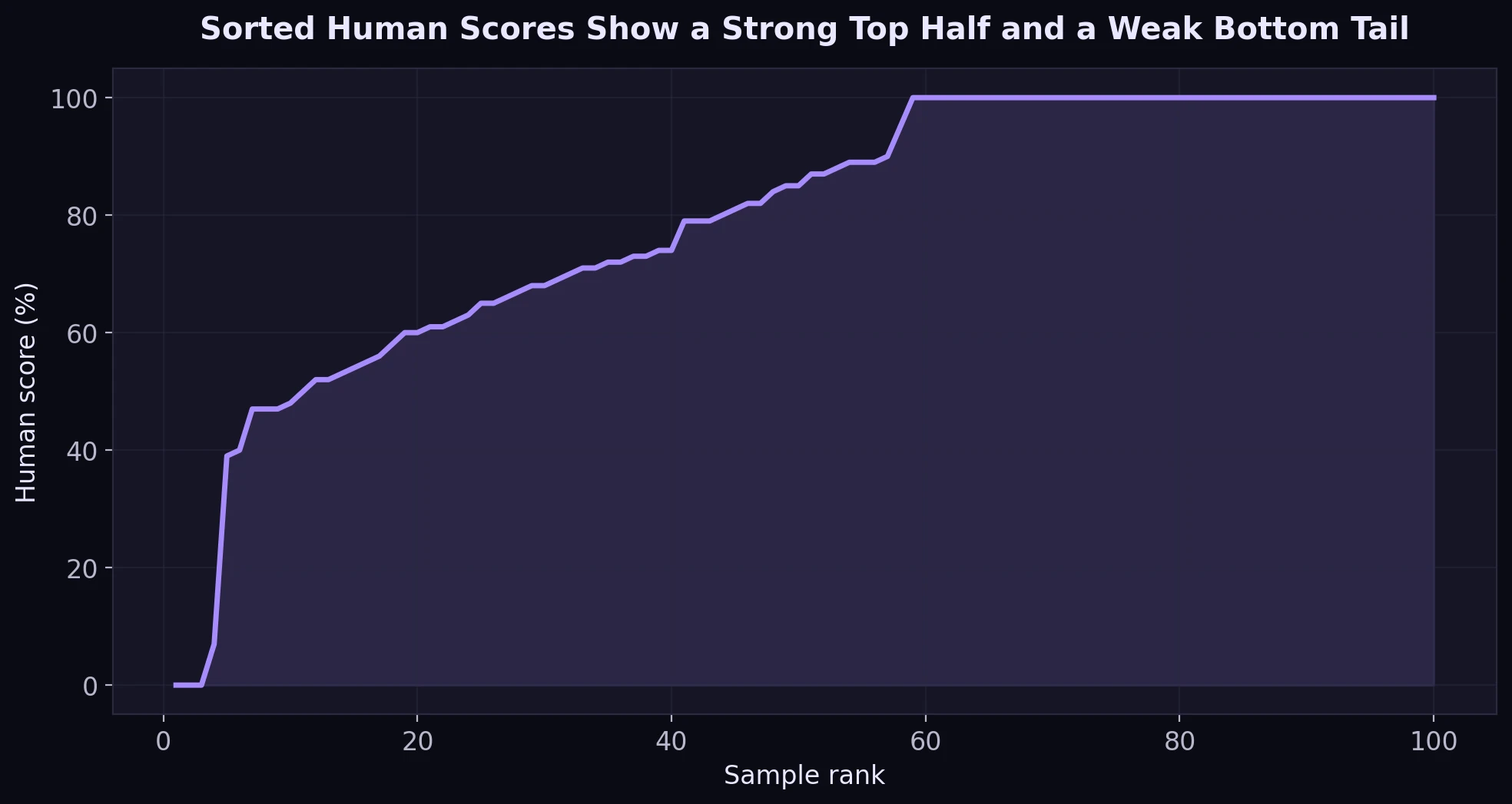
What the Full Score Curve Suggests
When the scores are sorted from lowest to highest, the shape of the curve tells a useful story. The top half of the dataset is strong. The bottom section, however, drops sharply. That means Undetectable AI was not simply “good” or “bad.” It was inconsistent.
What the Screenshots Show
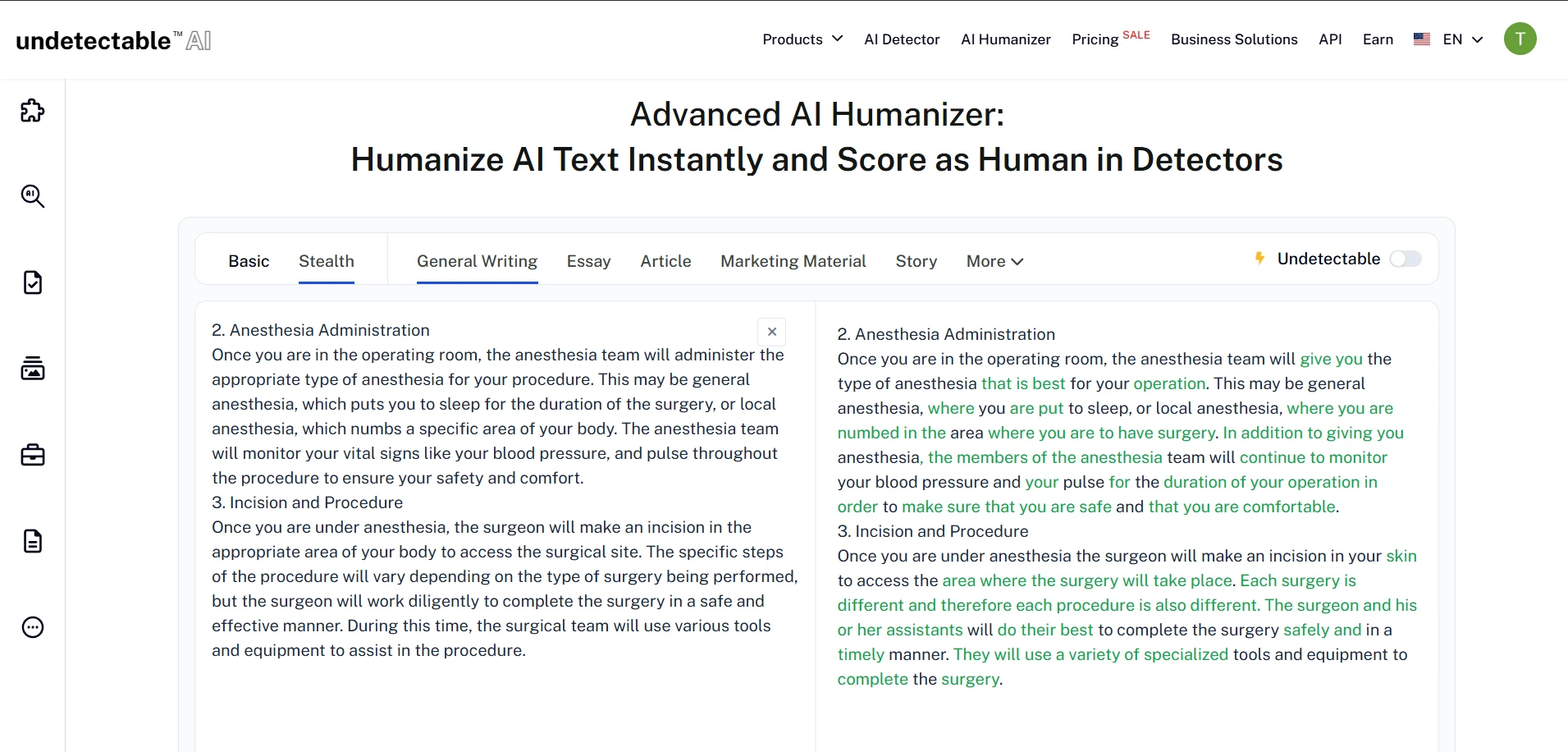
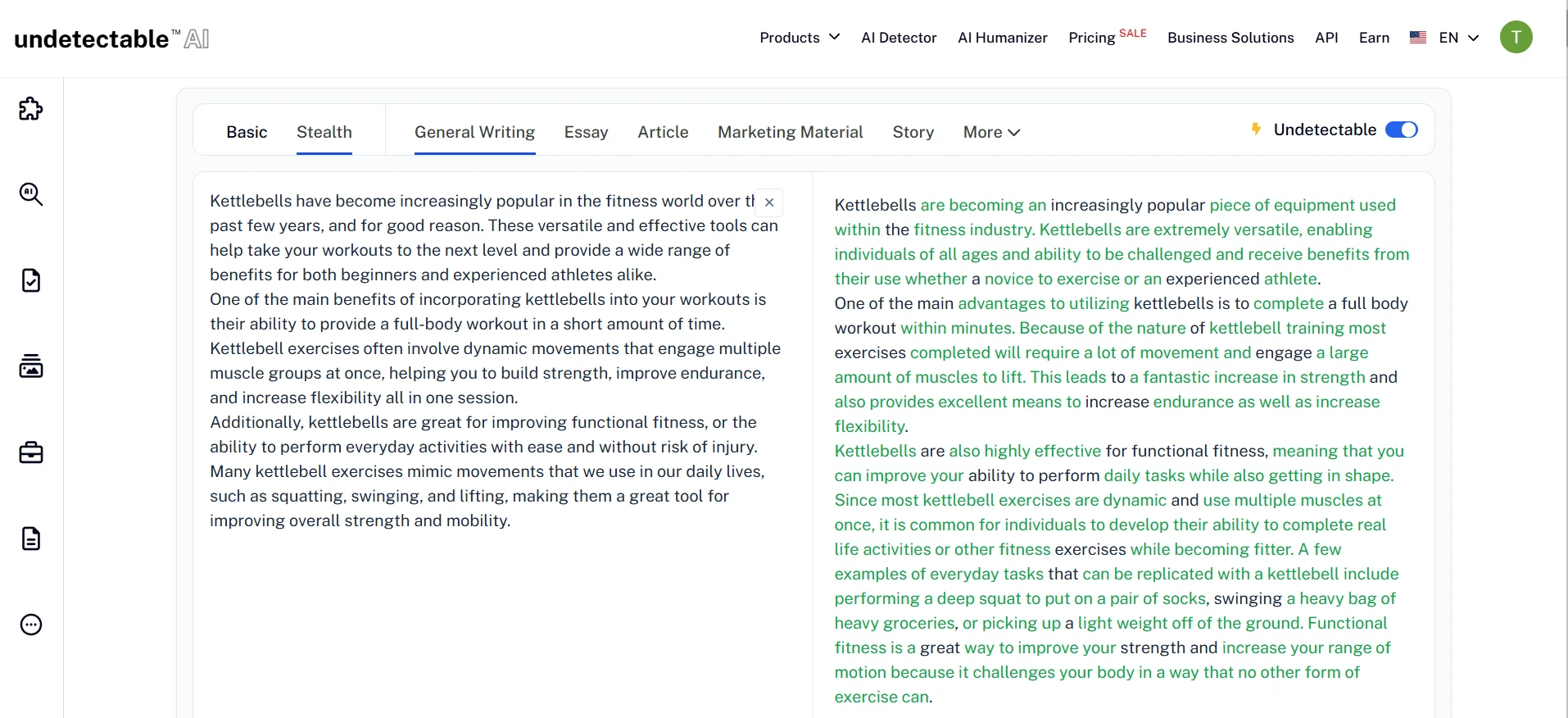
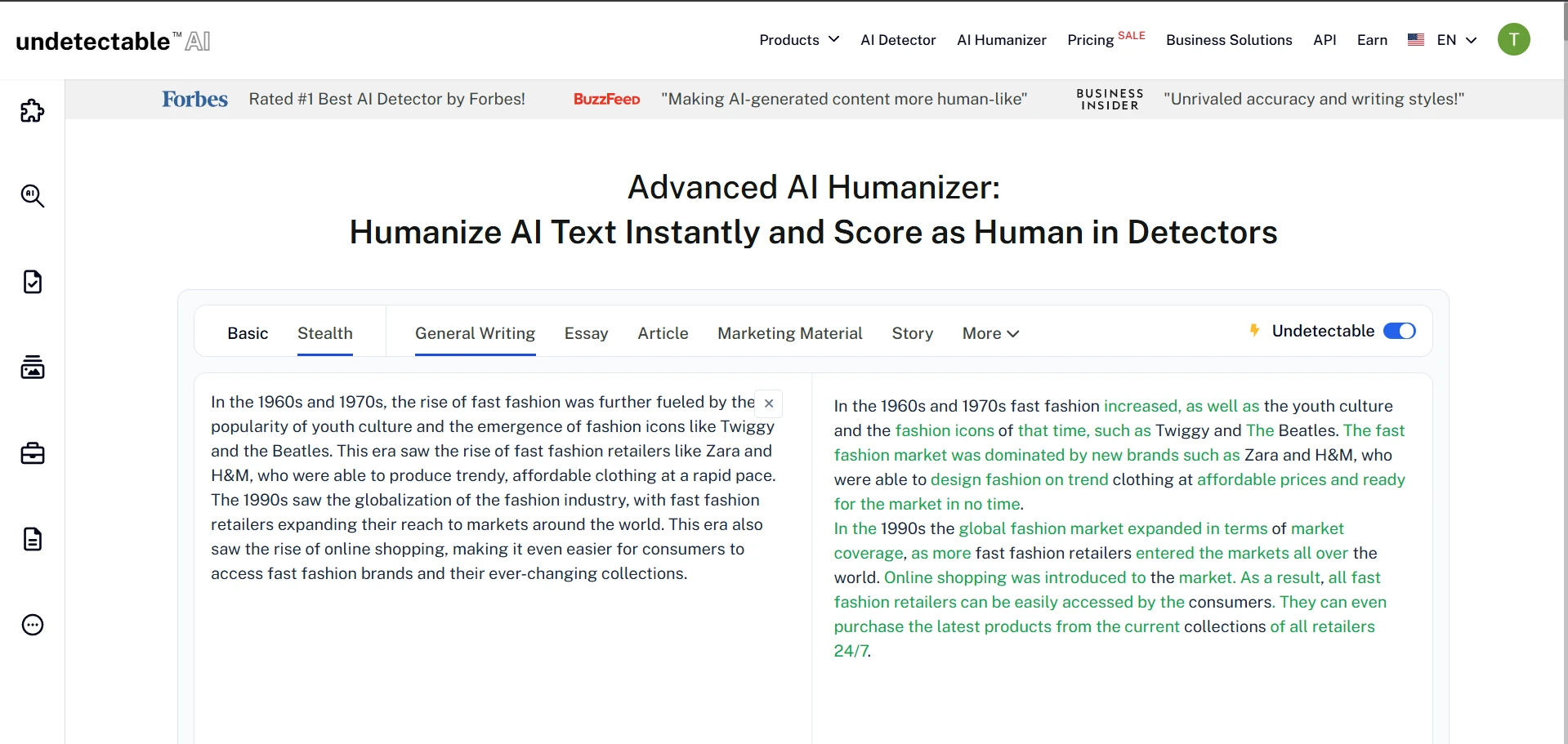
The screenshots below match the broader pattern in the numbers. ZeroGPT often reacts favorably to the rewritten versions, and the Undetectable AI interface clearly pushes the text toward a more detector-friendly form. But once you read closely, you can see the trade-off: the wording is often more artificial, more inflated, or less precise than the original.
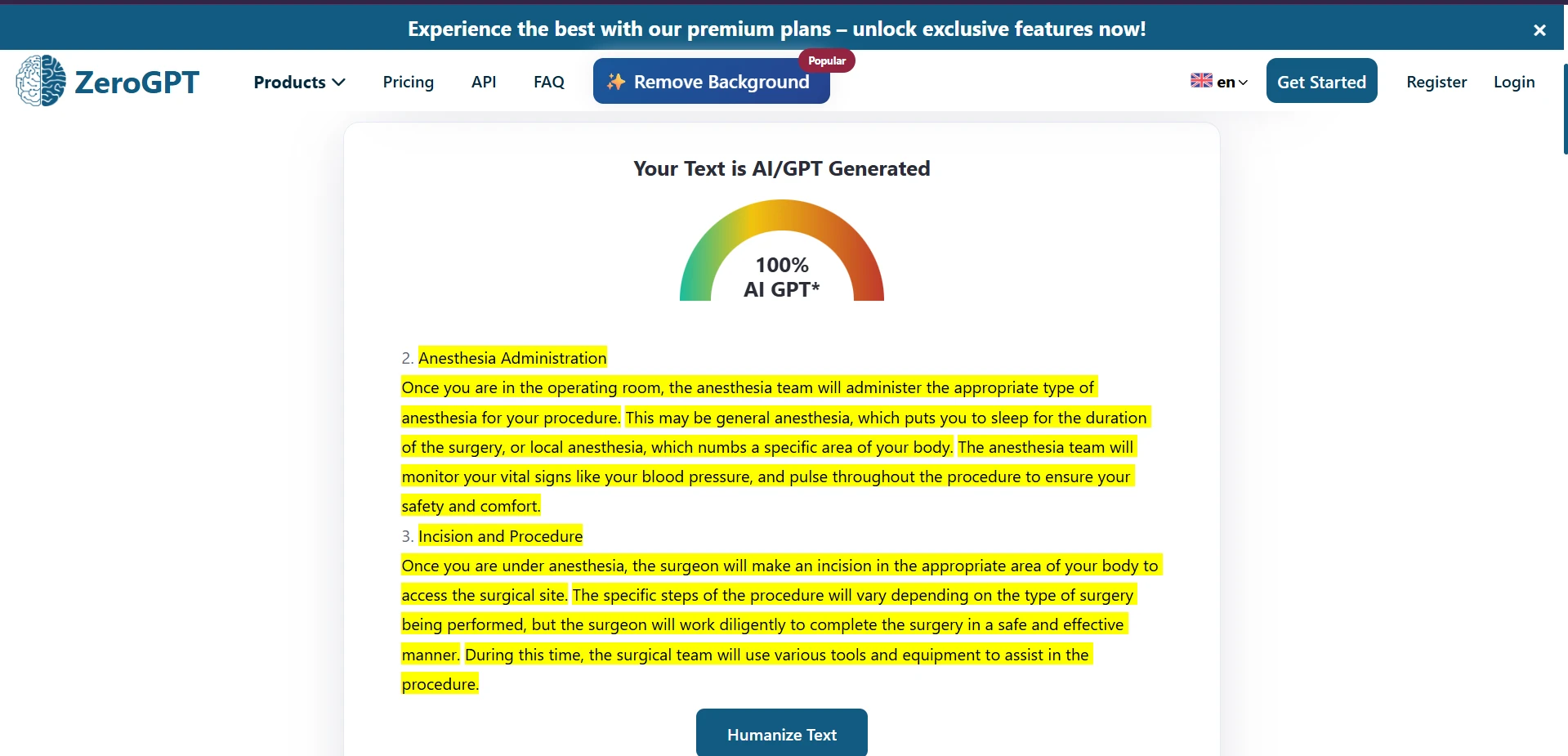
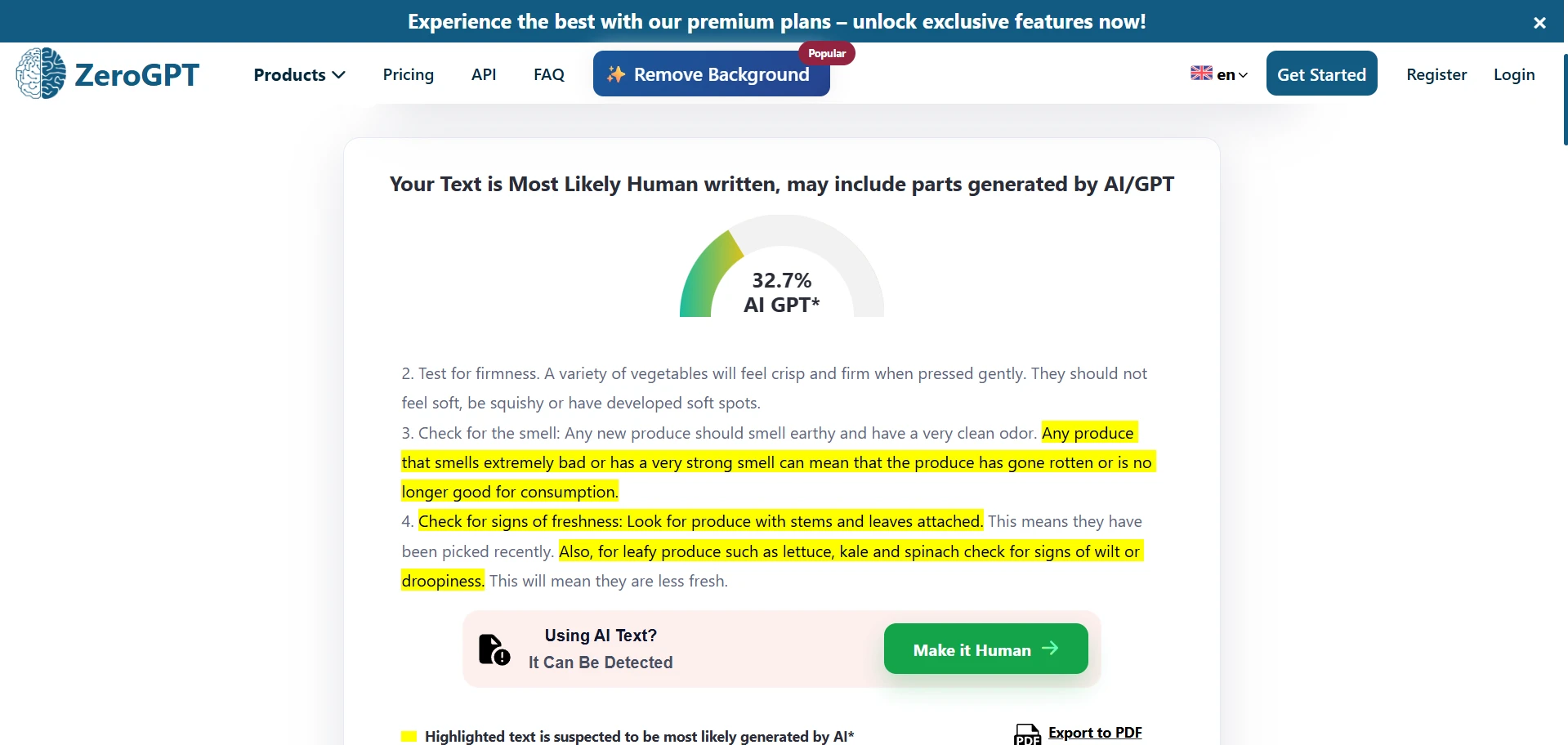
ZeroGPT Detection Results
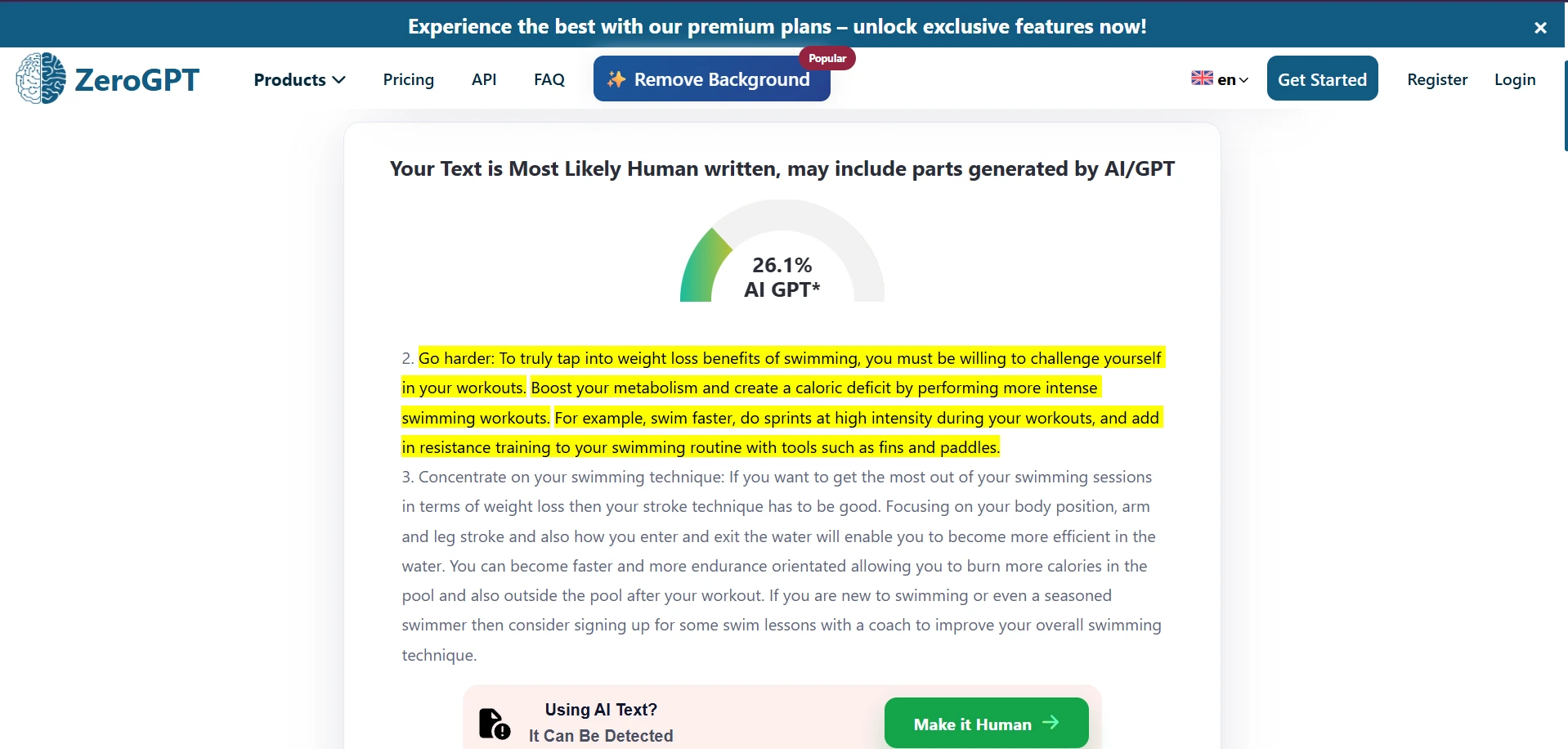

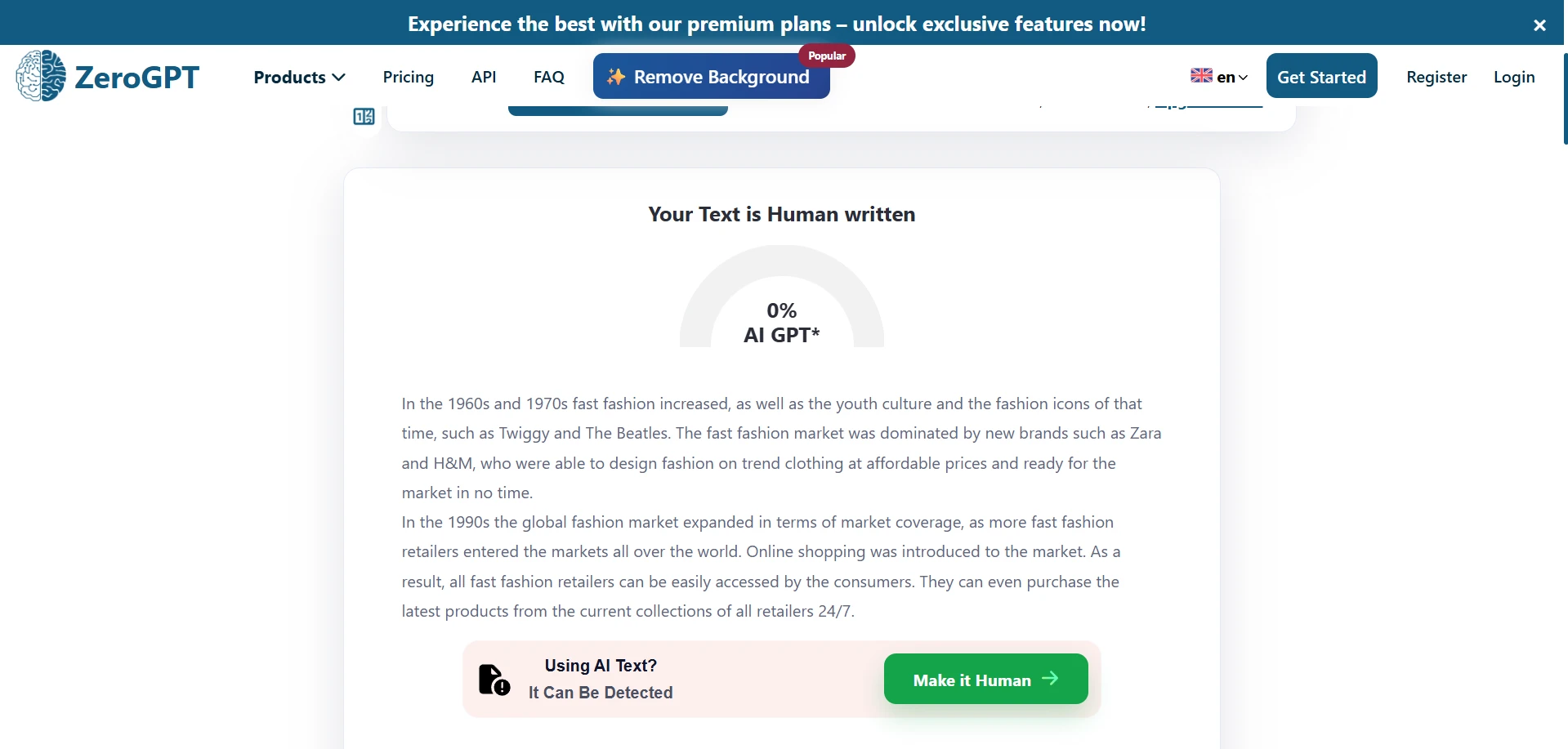
Undetectable AI Rewrite Screens
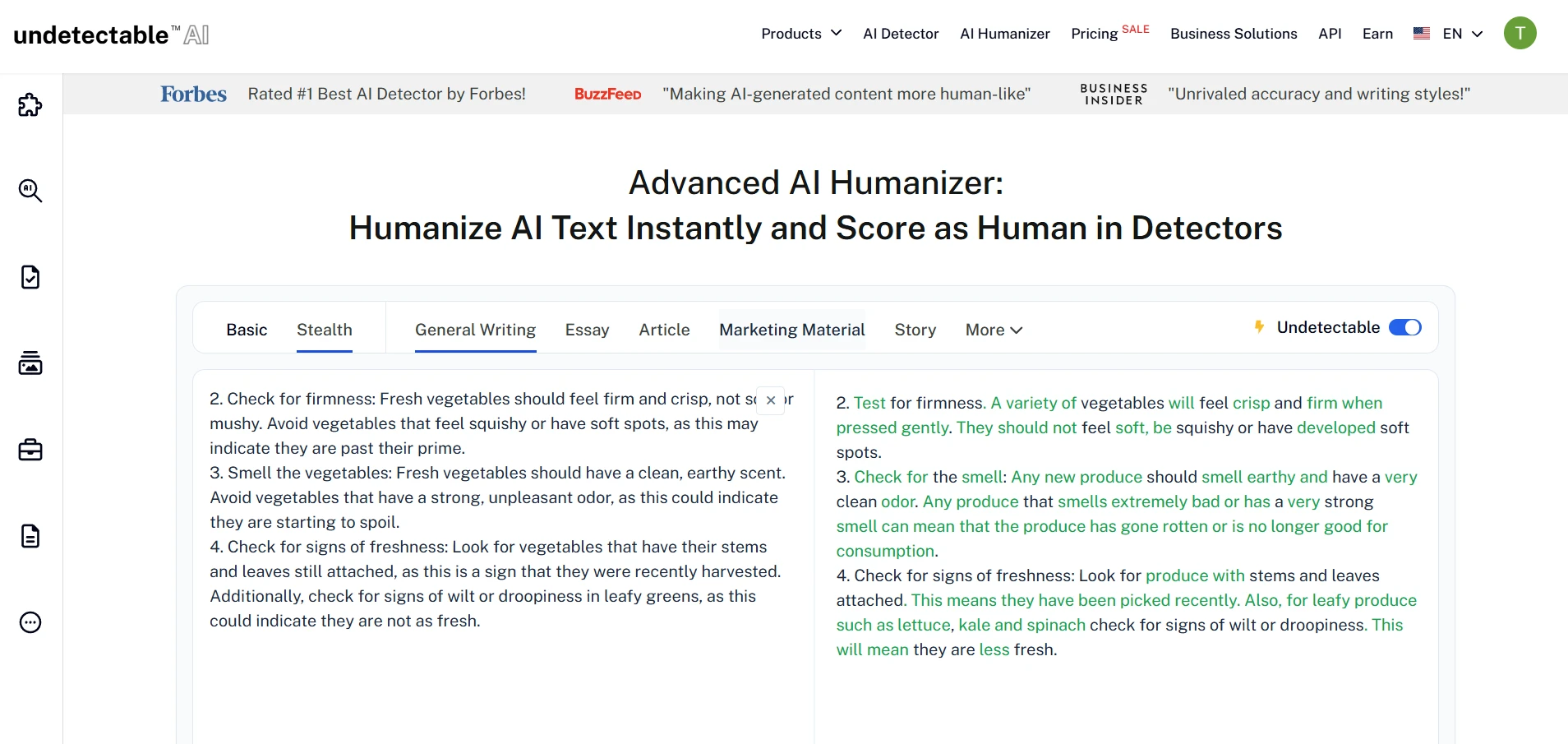
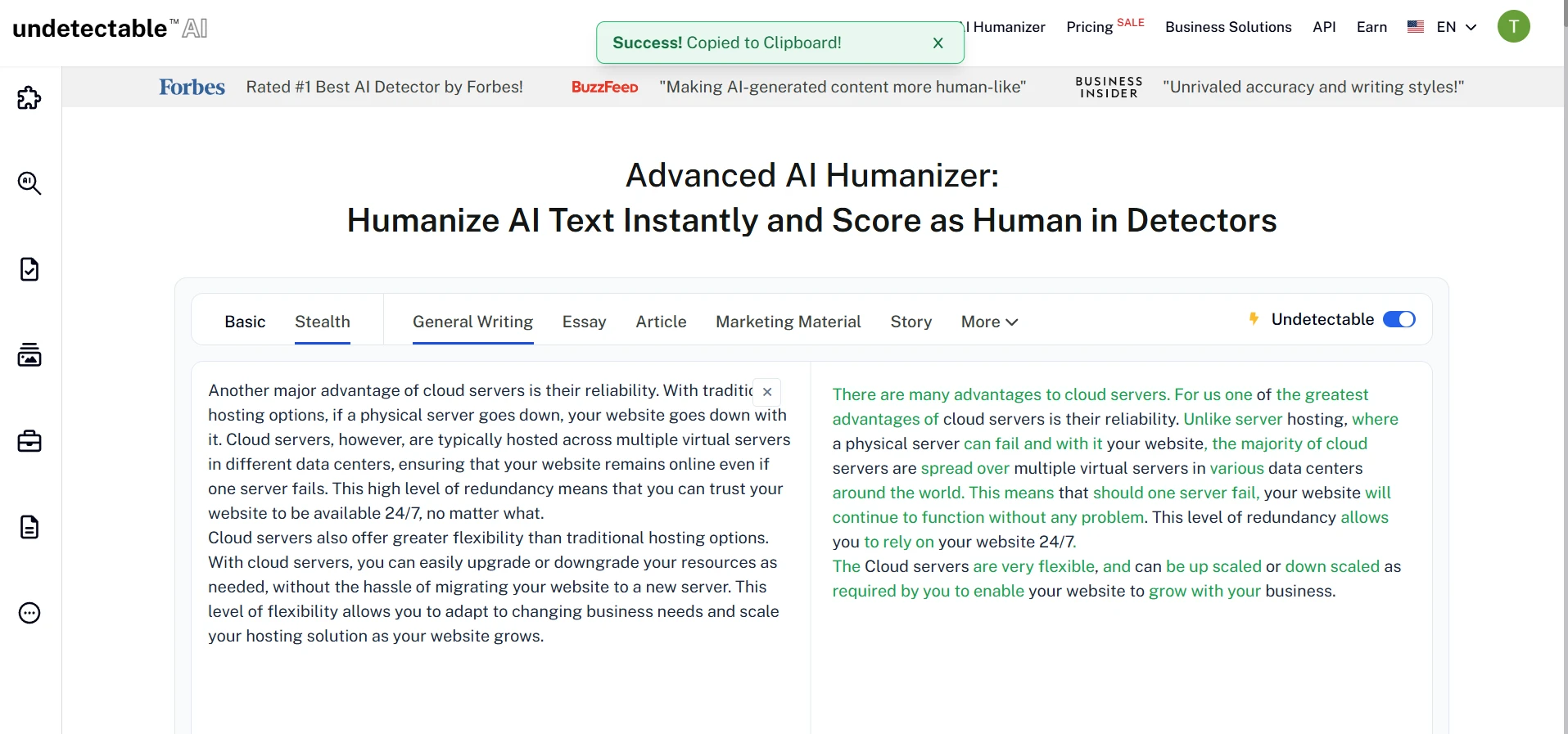
The Verdict
Undetectable AI was fairly effective at pushing ZeroGPT toward higher human scores. On the numbers alone, that much is clear. The average result was strong, and many samples scored in the 90% to 100% human range.
But the writing itself tells the more useful story. The tool often improved detector performance by making bigger wording changes, and those changes sometimes introduced awkward grammar, strange phrasing, extra filler, and small shifts in meaning. In other words, it could beat the detector while still harming the paragraph.
For students, that is the real lesson. If your standard is only “Can this get past ZeroGPT?” the tool often works. If your standard is “Will this still sound clear, accurate, and natural to a human reader?” the answer is much less comfortable.