![[STUDY] Can Undetectable AI Bypass Originality AI? A 100-Sample Reality Check](/static/images/undetectable-ai-vs-originality-featured-imagepng.webp)

Here is the uncomfortable question: if a rewriting tool earns a “human” score from an AI detector, does that mean the writing is actually better, or does it only mean the detector became less confident? To test that, 100 rewritten samples were checked in Originality AI after being processed with Undetectable AI.
This study uses human scores. Originality AI normally focuses on whether text looks AI-generated, but the results here were converted so that a higher number means “more likely human.” A score of 100% means the detector judged the text as fully human. A score near 0% means the detector strongly suspected AI.
The Quick Answer: The Scores Look Strong
On the detector side, Undetectable AI performed very well. Across all 100 samples, the average human score was 92.0%, and the median was 100%. The median is simply the middle value when all scores are lined up from lowest to highest, so this tells us that at least half of the rewrites landed at the top end of the scale.
Main Results From the Dataset
- 100 total rewritten samples were checked in Originality AI.
- 89 samples scored between 90% and 100% human.
- 74 samples scored between 99% and 100% human.
- 7 samples scored below 50% human, meaning they failed badly.
- The rewrites became 23.1% longer on average, so the tool often expanded the text rather than just rephrasing it.
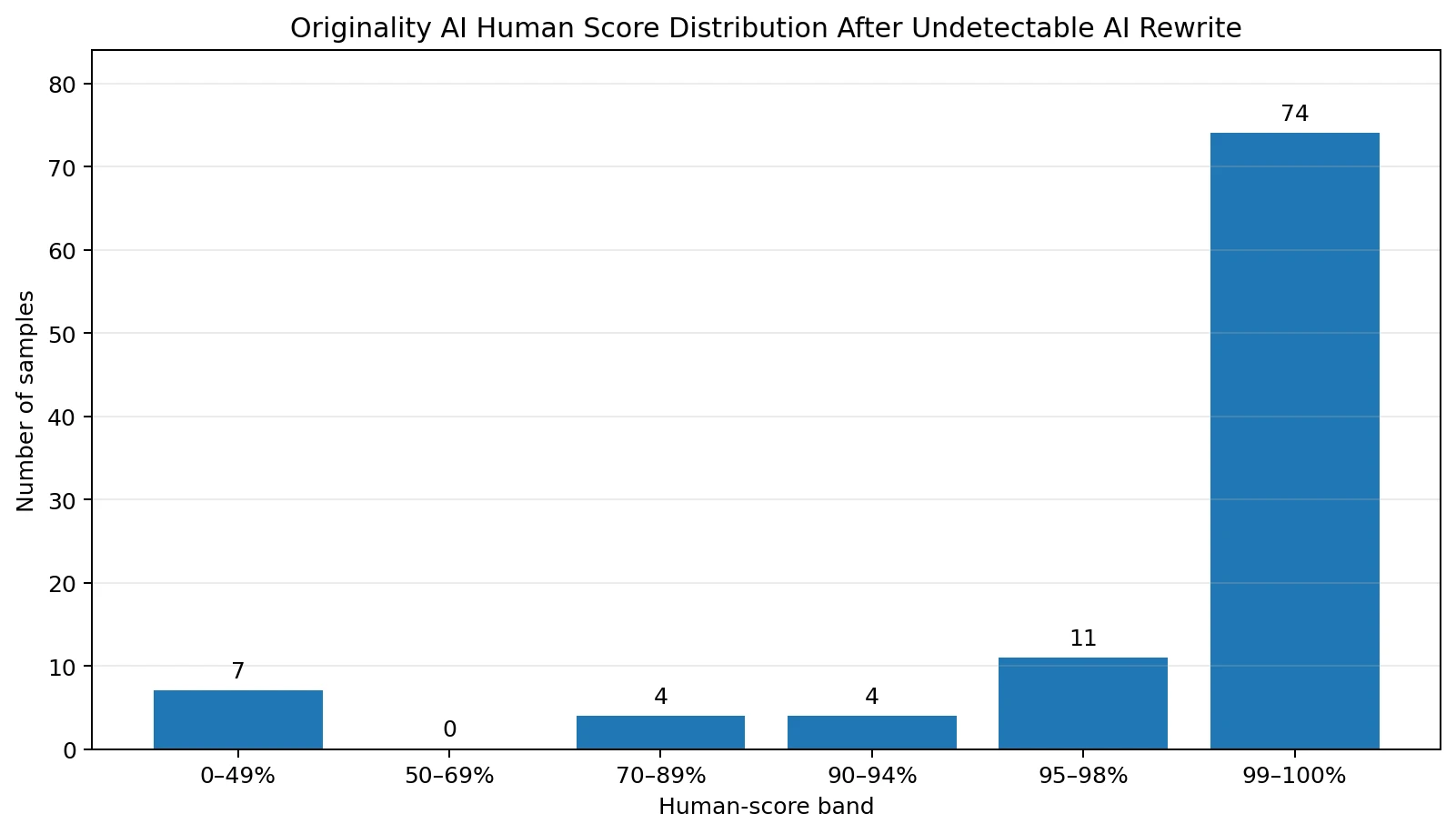
The chart makes the main result obvious. If the goal is only to make Originality AI assign a high human score, Undetectable AI passed most of the time. But students should be careful with that sentence. A high detector score is not the same as a strong essay, a correct answer, or a clean paragraph.
Also Read: [STUDY] Can Stealthwriter really slip past Originality.ai? I tested 100 rewrites to find out.
The Pass Rate Is Impressive, But Not Perfect
To make the results easier to read, the samples can be split into three groups: high human score, middle zone, and low human score. The high group is where Undetectable AI clearly appeared to bypass the detector. The low group is where the rewrite still looked suspicious to Originality AI.
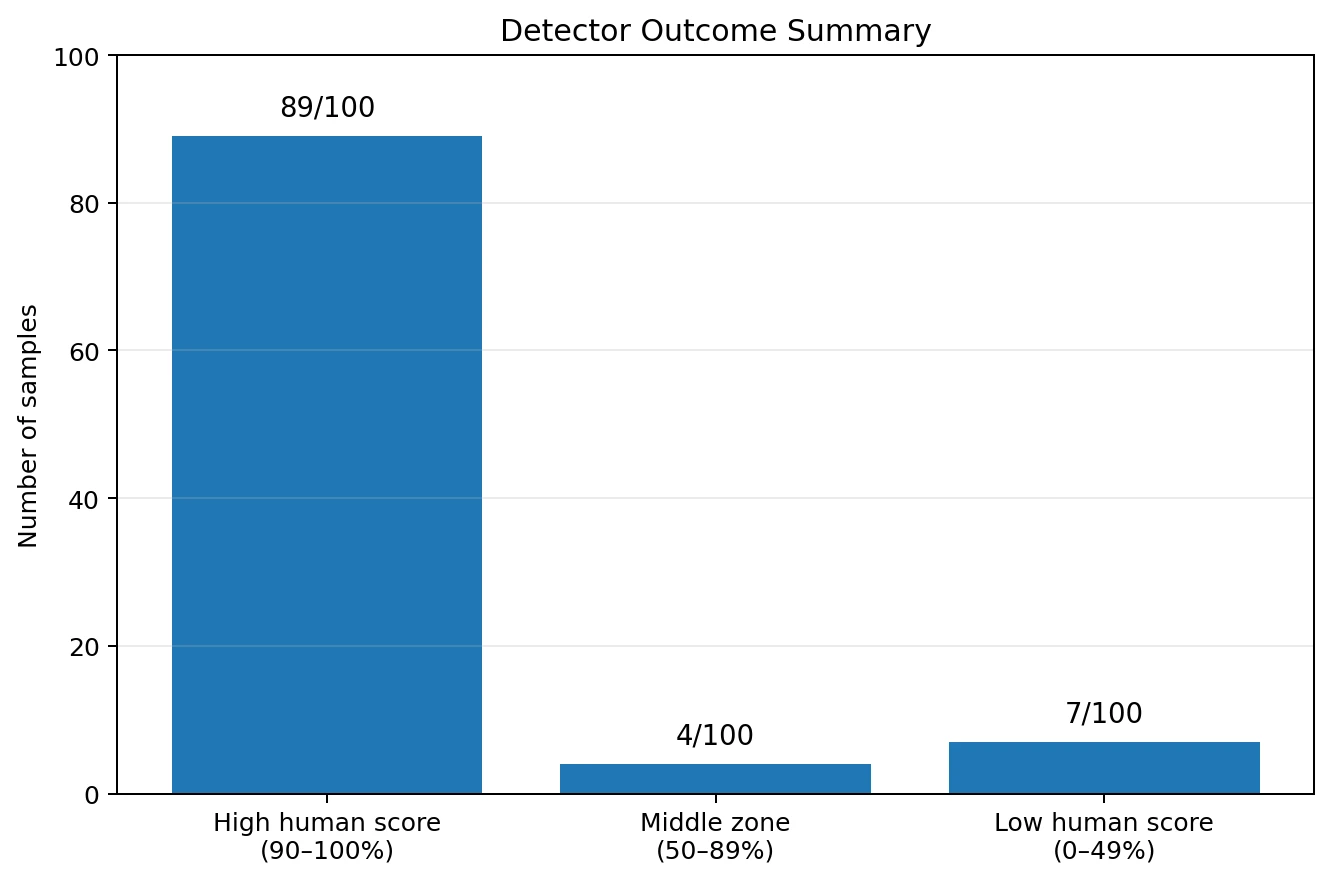
That means the tool was highly effective in this dataset, but not reliable enough to be treated as automatic protection. A student who assumes every rewrite will pass is taking a risk. In this test, about 1 in 14 samples still landed in the danger zone.
Also Read: I Tested 100 Phrasly Rewrites Against Originality.ai. The Results Were Hard to Ignore.
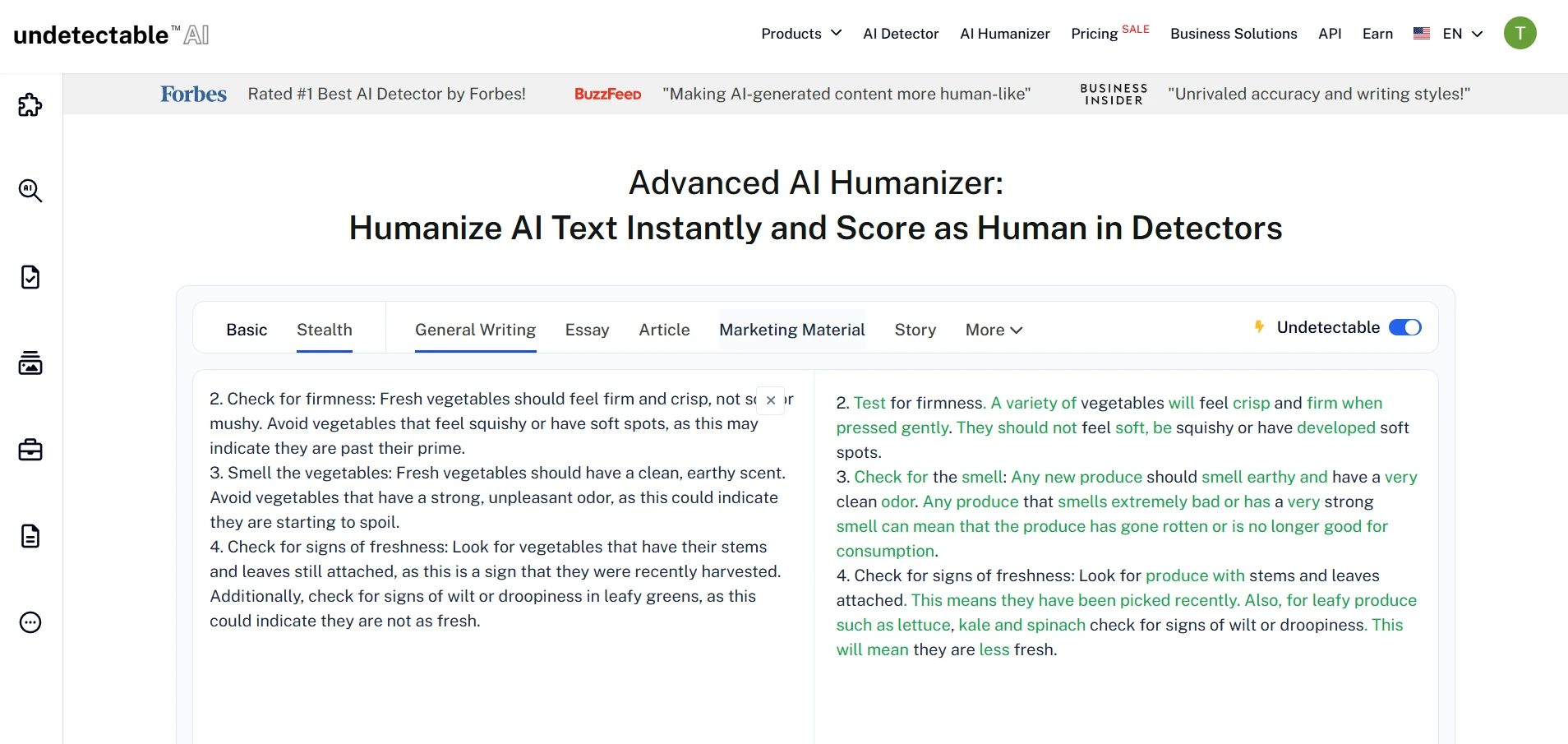
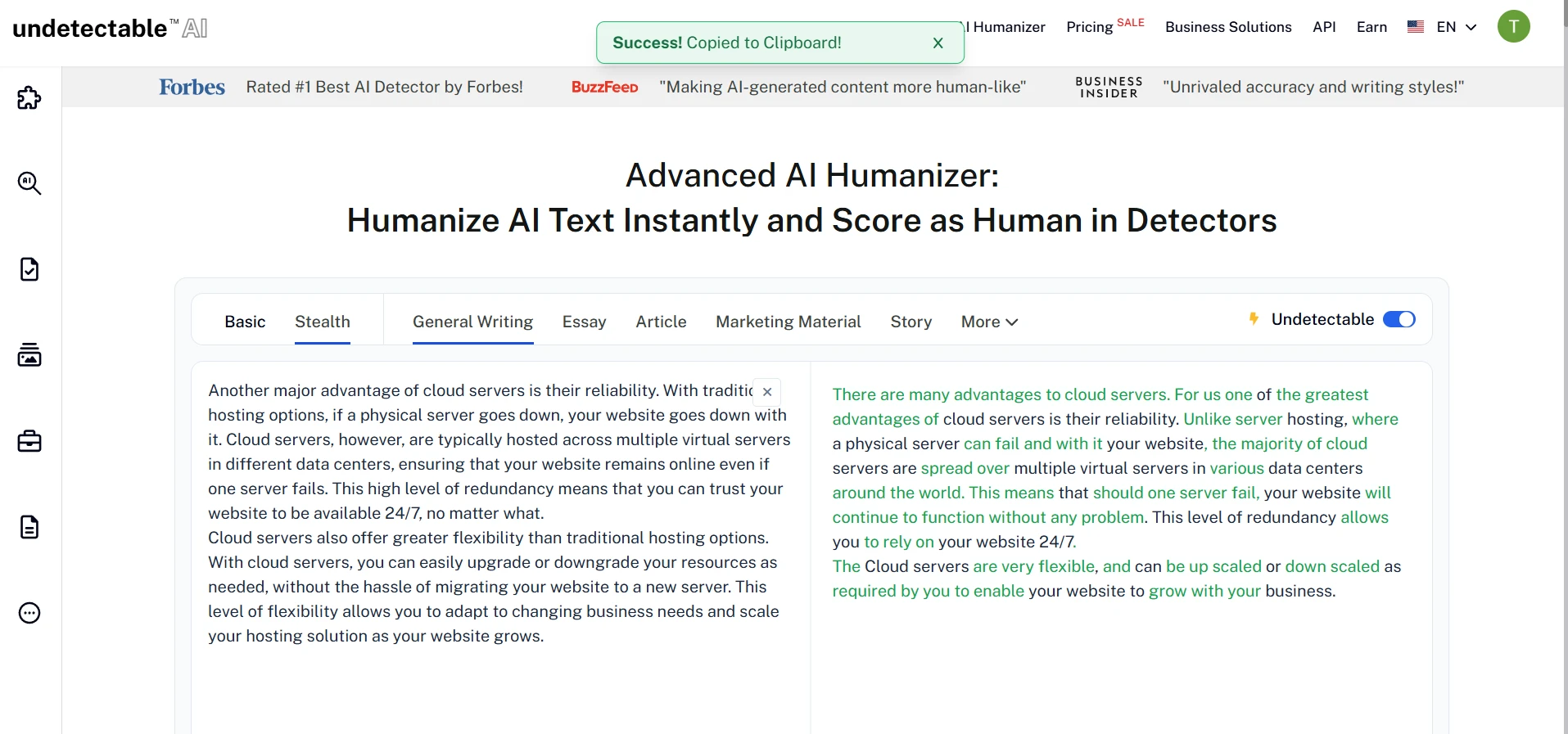
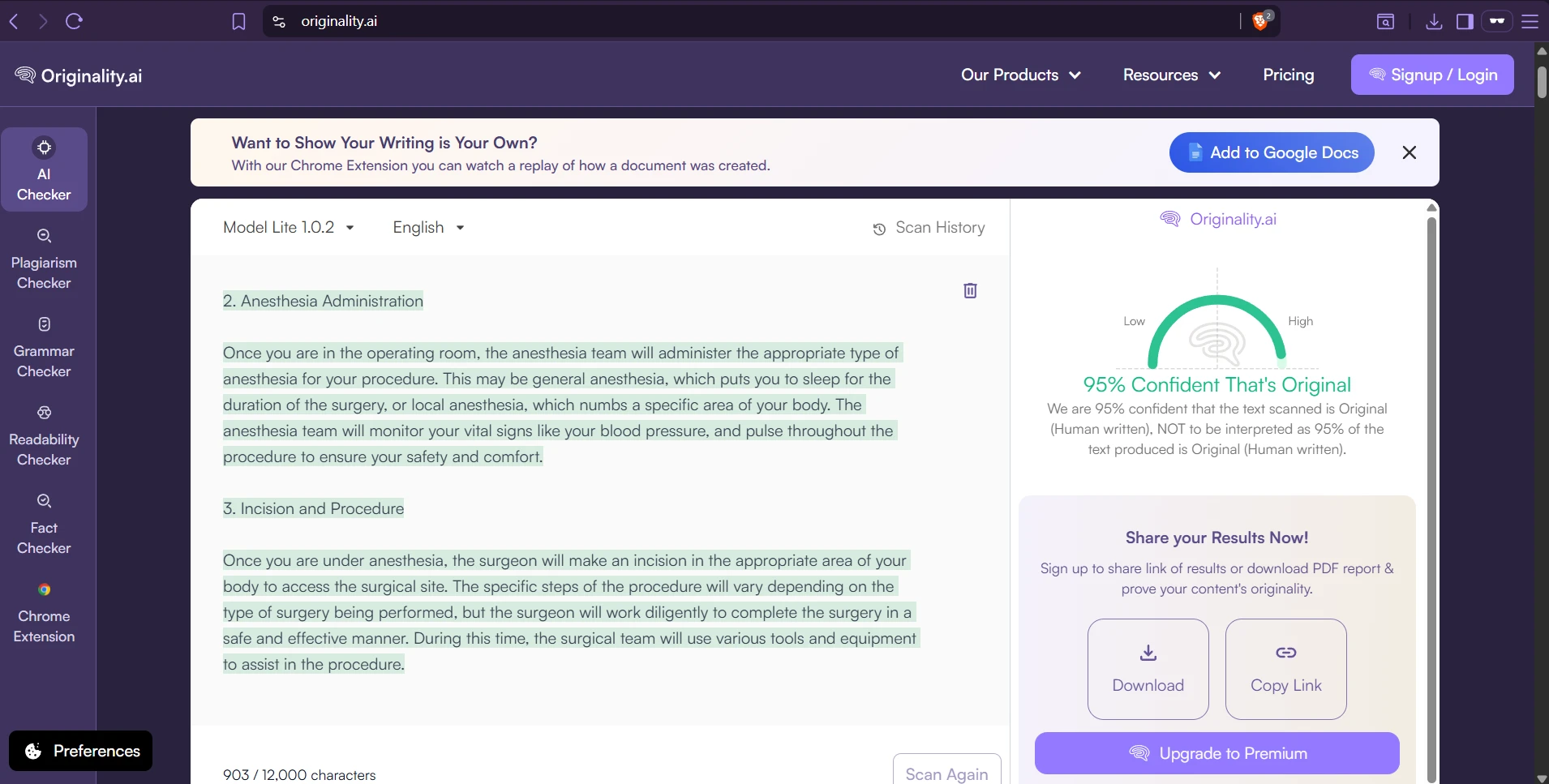
What the Tool Looked Like During Testing
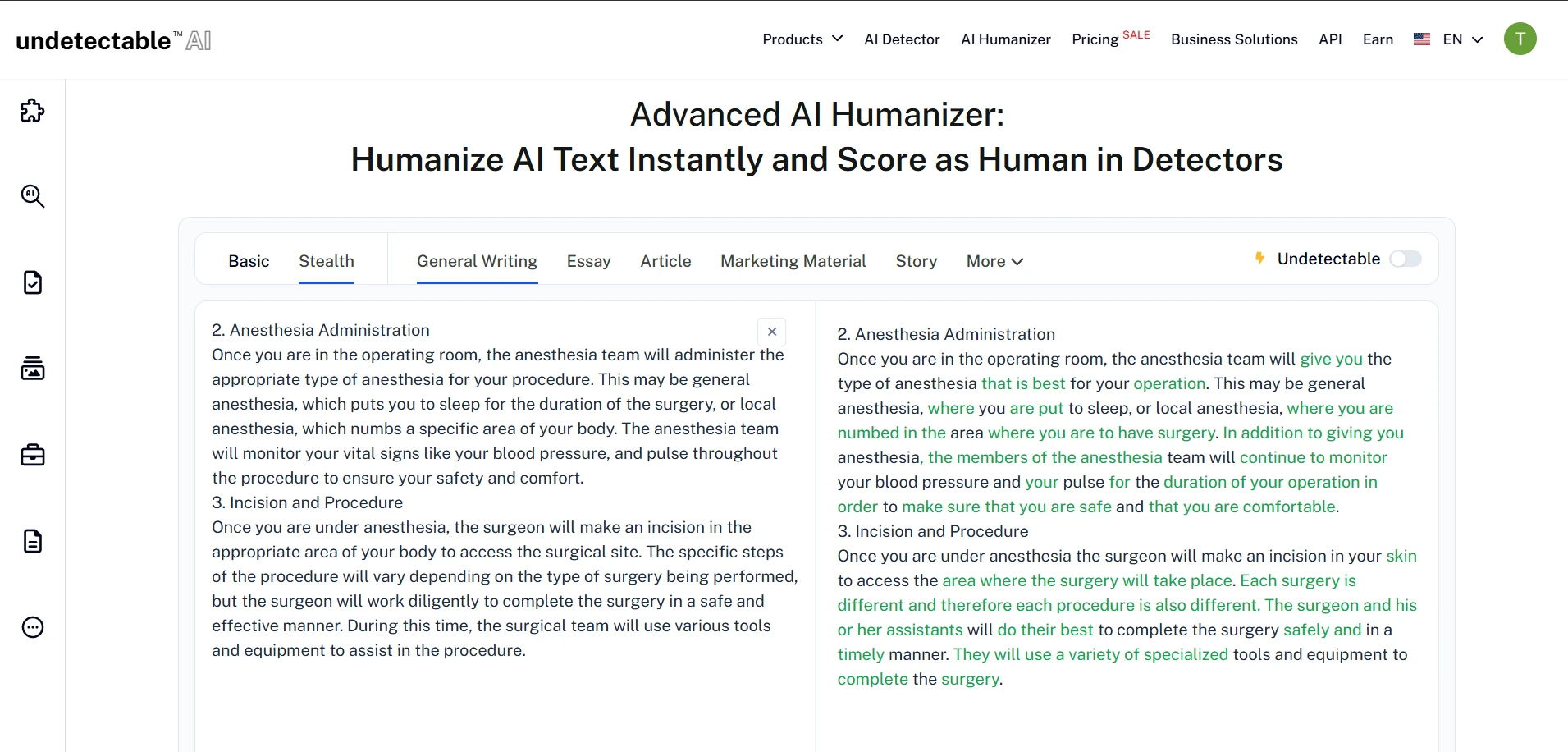
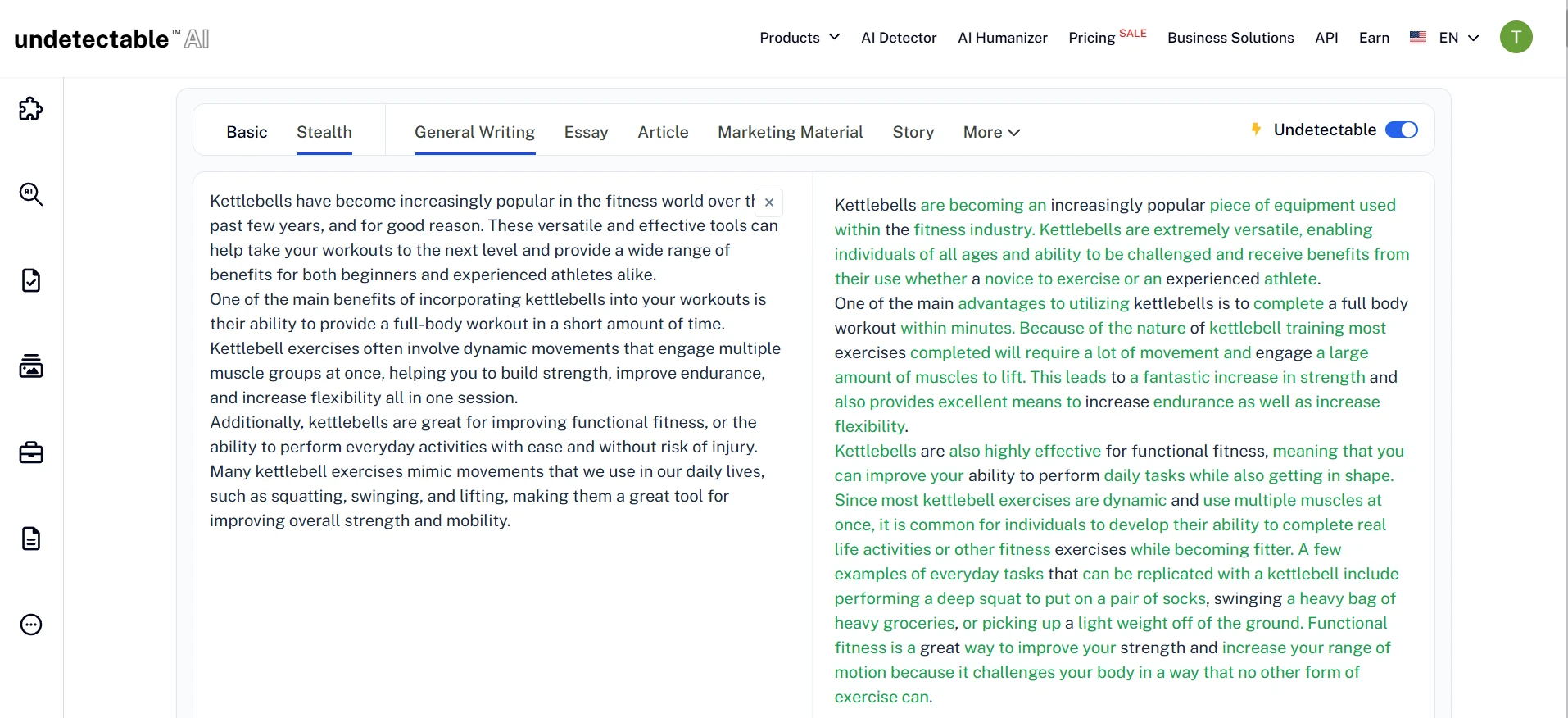
The rewrite interface produced side-by-side text, with green highlights showing changed wording. In many cases, the rewritten text became longer, softer, and more conversational. These screenshots show the kind of output that later received high human scores in Originality AI.
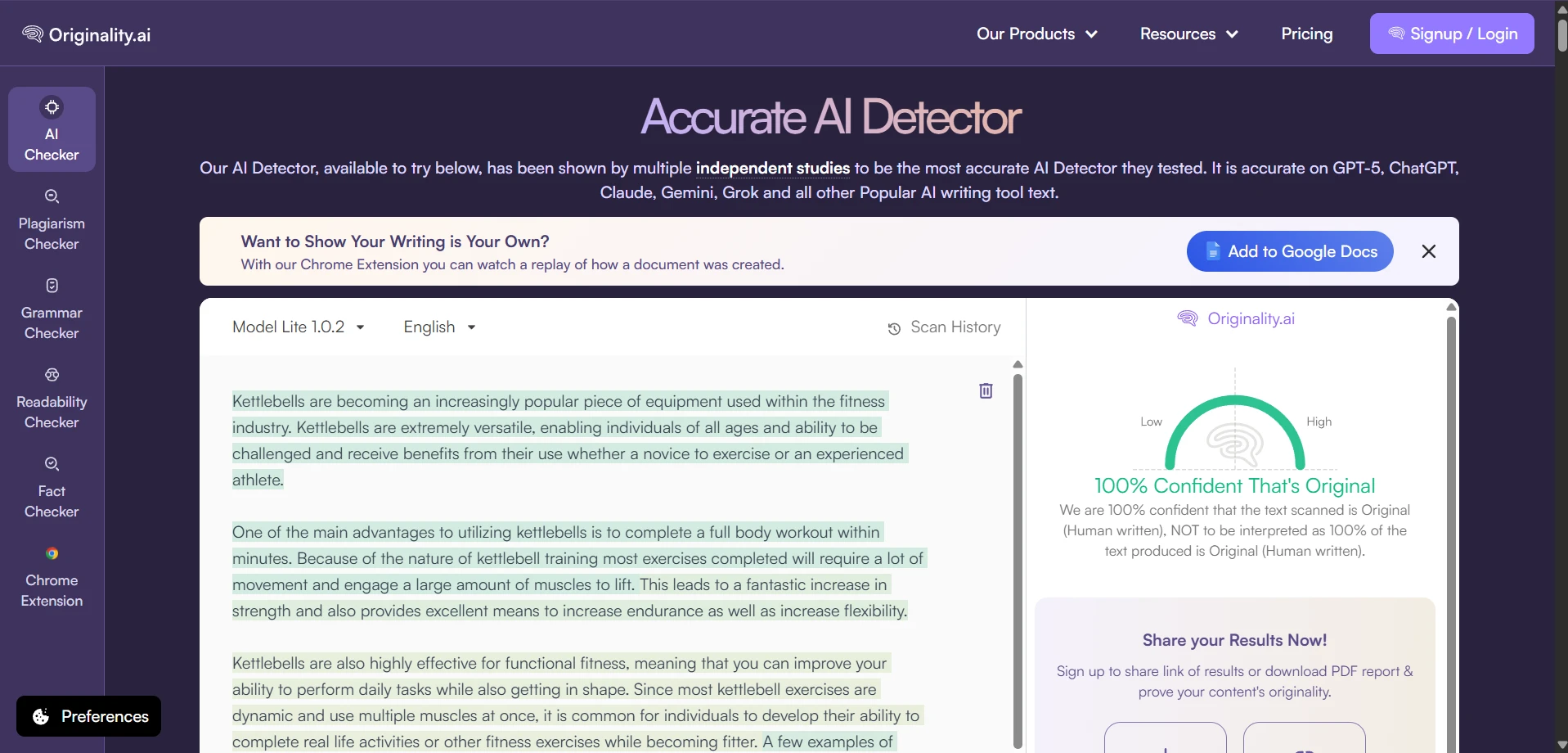
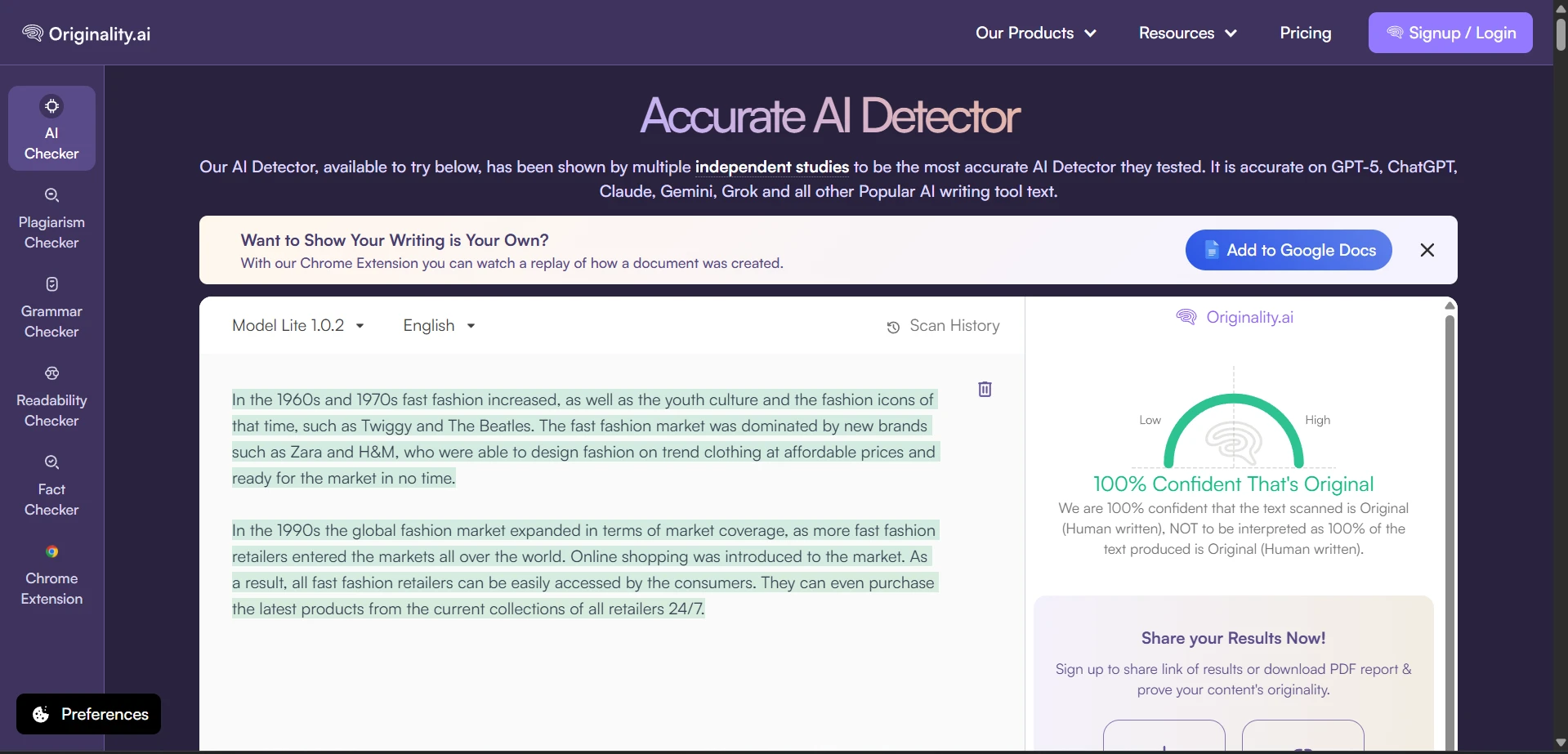
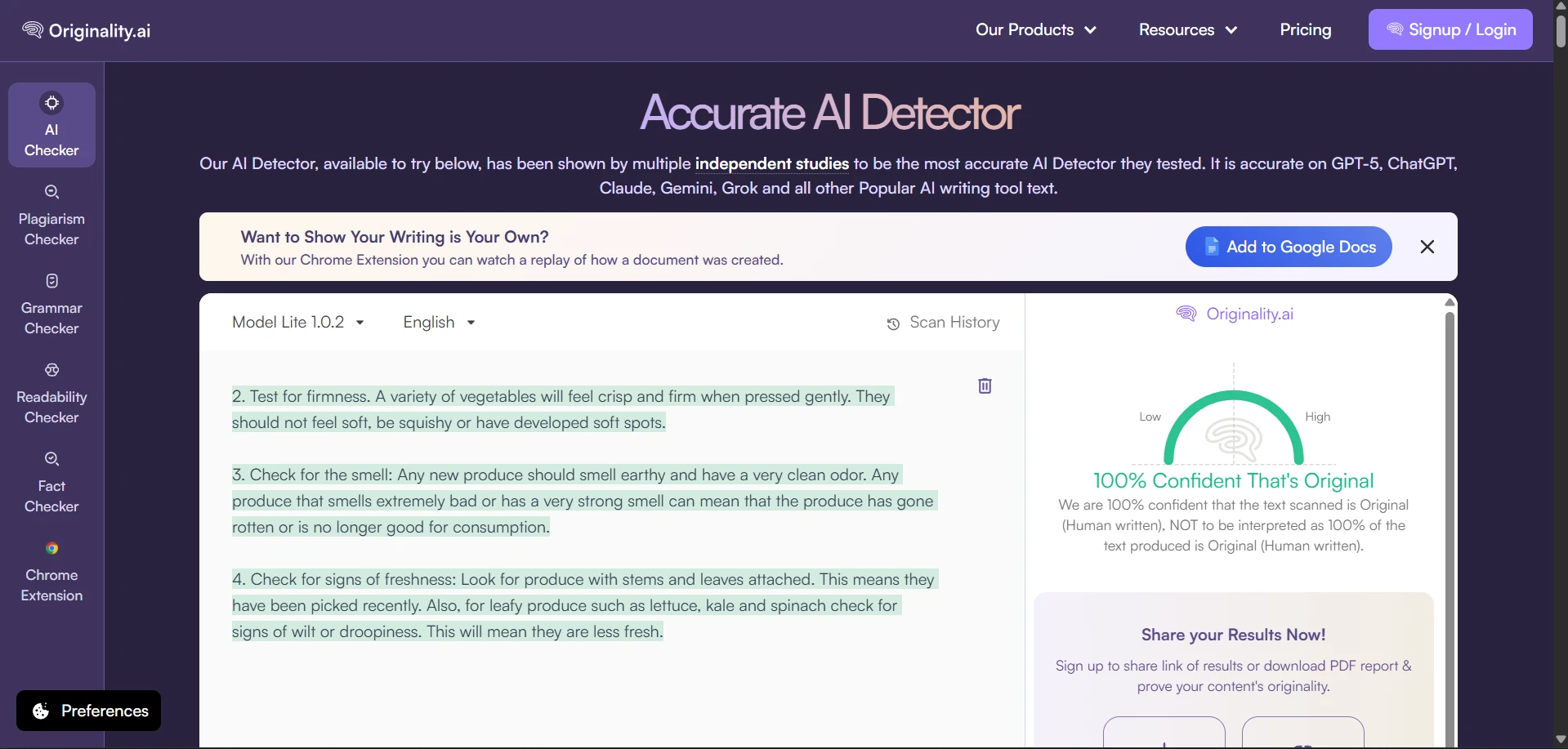
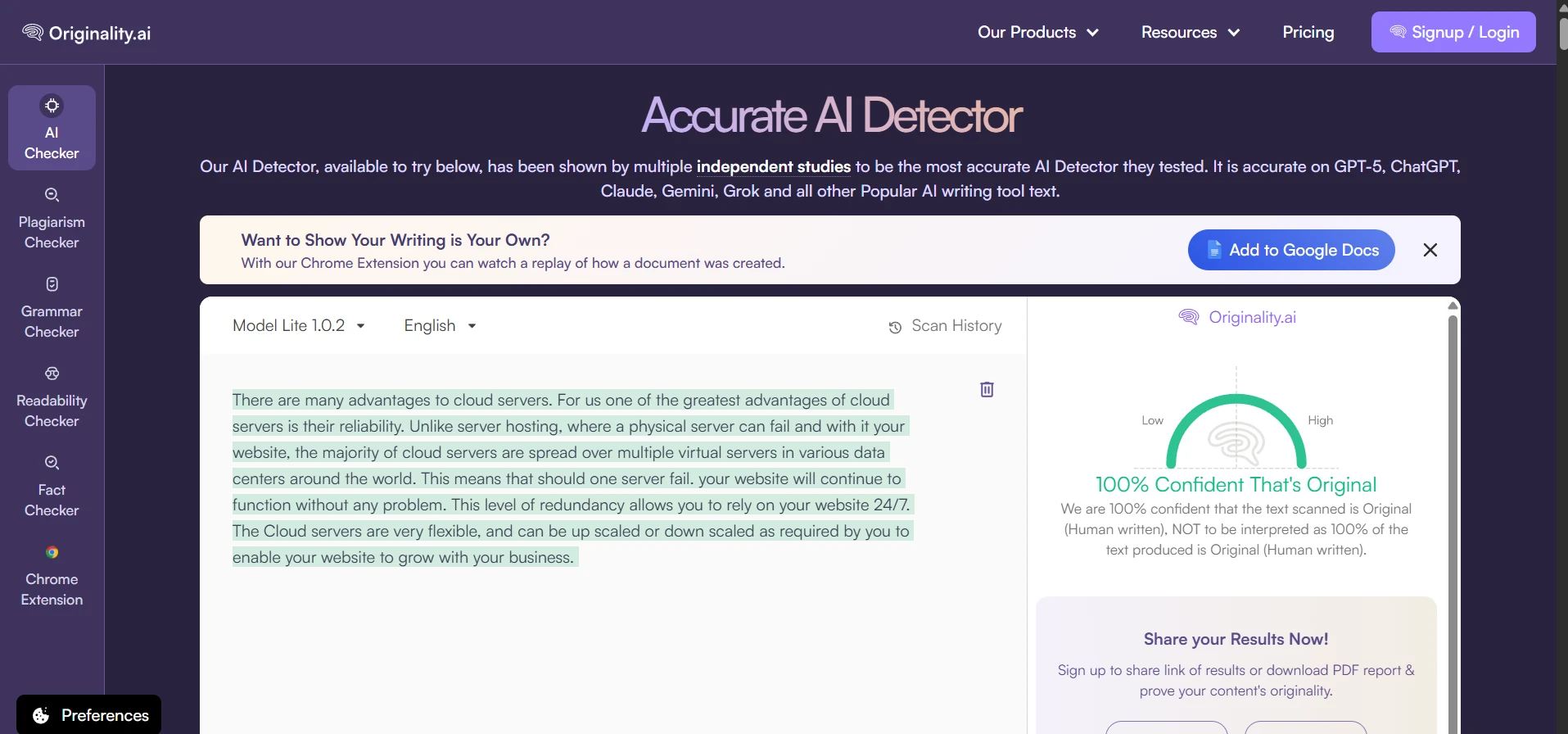
The Part Students Should Not Ignore: The Writing Often Got Worse
The detector scores tell only half the story. A separate review of the rewrites found several quality problems. This matters because teachers, editors, and readers do not grade only with detectors. They notice strange wording, broken ideas, and claims that suddenly appear from nowhere.
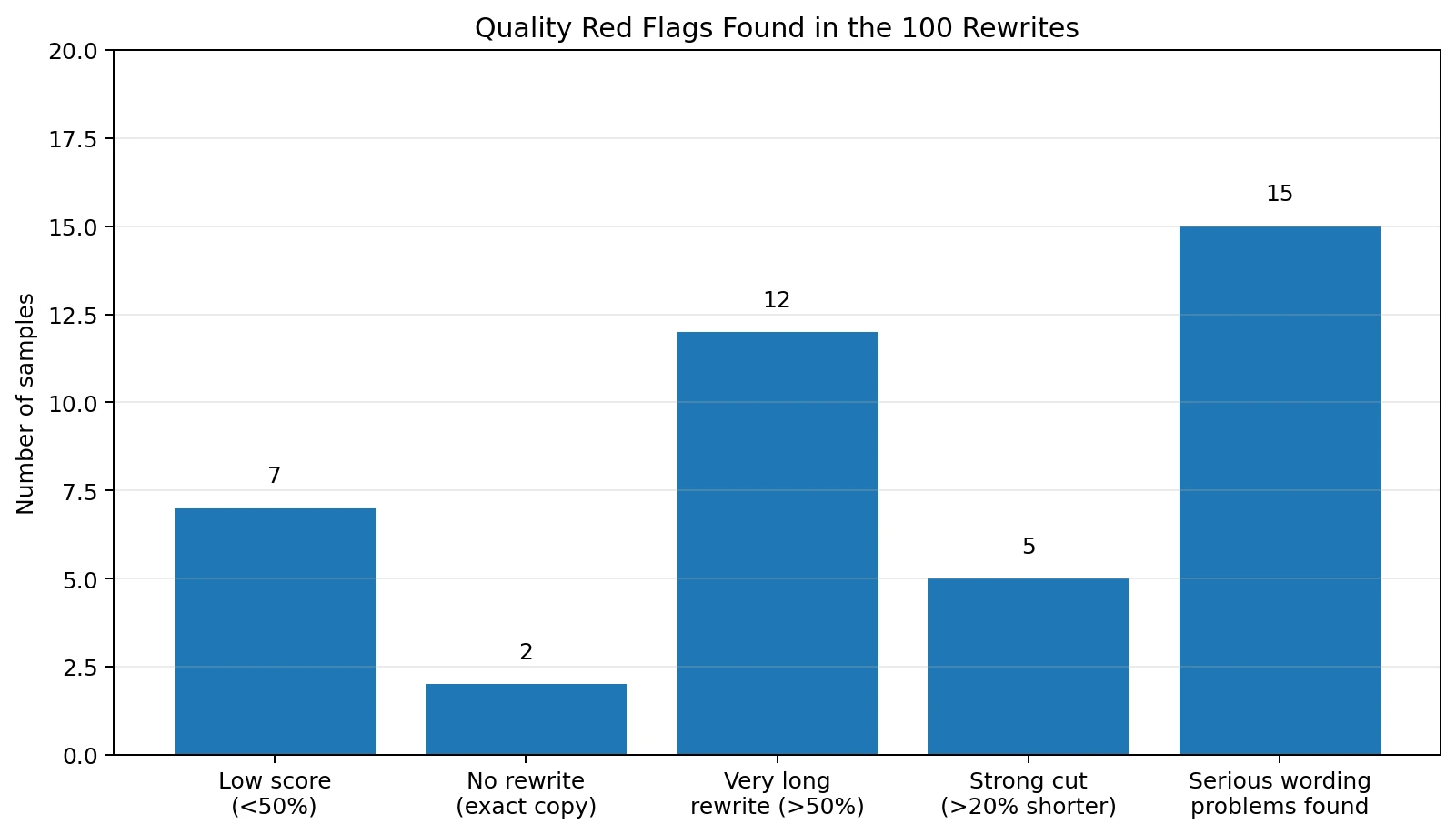
Rewrite Problems Found in the Samples
- Exact-copy problem: 2 samples were not meaningfully rewritten at all. One even received a strong human score, showing that detector results can be inconsistent.
- Gibberish and broken openings: examples included phrases like “Nut senior sports enthusiasts,” “There that exist in the animated world,” and “Fire are used to locate a mate.”
- Meaning drift: some rewrites added details not clearly present in the original, such as a “2 Degrees initiative” in a fossil-fuel divestment passage or a branded-looking title added to an Amazon warehouse article.
- Formatting damage: some sentences had smashed-together words, unfinished fragments, repeated headings, or stray text such as “The1970s” and “Advantages of Fixed Deposits for Financial Stability.The.”
- Over-expansion: 12 rewrites grew by more than 50%, which can make a simple answer feel padded and less focused.
This is the key lesson: bypassing a detector is not the same as producing trustworthy writing. A student may get a 100% human score and still submit a paragraph that sounds unnatural, adds unsupported claims, or loses the point of the original text.
Did Longer Rewrites Get Better Scores?
One possible theory is that longer rewrites might look more human. The data does not strongly support that. The relationship between length change and score was almost flat. In simple terms, a correlation tells us whether two things move together. Here, the correlation between word-count change and human score was close to zero, meaning longer rewrites were not automatically safer.
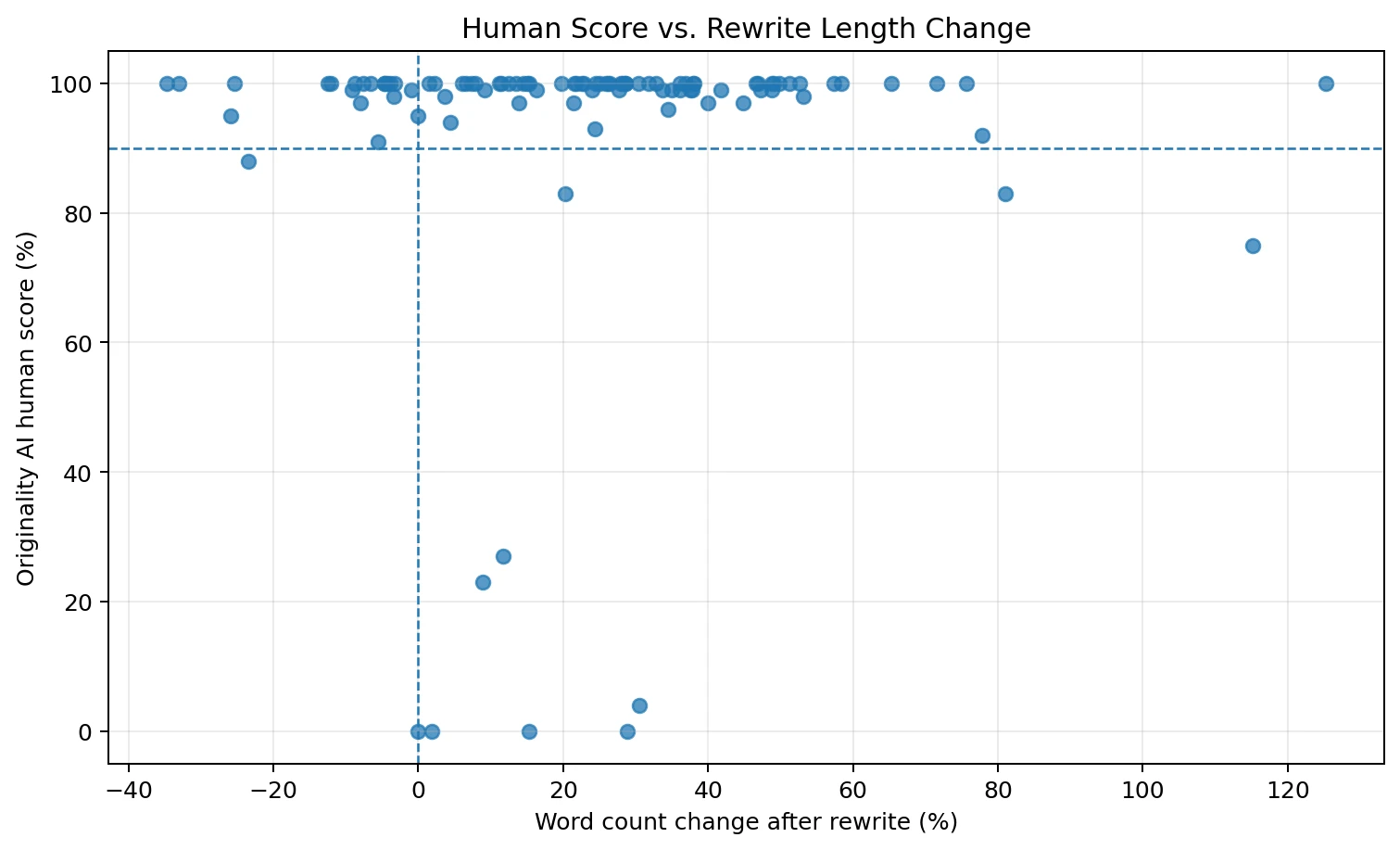
The average rewrite was longer by about 23%, but the low-scoring samples were not all short, and the high-scoring samples were not all long. The detector seemed to respond to patterns in wording, structure, and style rather than only word count.
Final Verdict
In this 100-sample test, Undetectable AI was effective at getting high human scores from Originality AI. With 89% of samples scoring at least 90% human and 74% reaching 99–100%, the detector-level result is hard to ignore.
But the more important finding is less comfortable: the rewrites were not consistently clean. Some were unchanged, some became awkward, and some introduced confusing or unsupported wording. For students, the practical takeaway is clear. A detector score can be useful data, but it should never replace reading the work carefully. The real test is not only “Can it pass Originality AI?” The better question is: would this still make sense to a human reader?