

If a tool promises to make AI writing look human, the real question is not whether the output sounds smoother. The real question is whether a detector actually starts treating that text like it came from a person. To test that idea, we looked at 100 Undetectable.ai rewrites and checked their human scores from Sapling AI. In this dataset, a higher score means the rewrite looked more human. What we found was not a steady win story. It was a story of inconsistency, inflated rewrites, and quality trade-offs.
How This Test Worked
Each row in the dataset contains an original passage, an Undetectable.ai rewrite, and the final Sapling score converted into a human score. That means 1.0 = 100% human-looking and 0.0 = 0% human-looking. I also reviewed the text itself, not just the score, because a rewrite can sometimes push the detector in the right direction while still damaging clarity or meaning.
- Sample size: 100 rewritten passages
- Detector: Sapling AI
- Main metric: Human score
- Extra review: wording changes, length changes, number/date changes, formatting damage, and obvious text corruption
Two simple terms used in this article: median means the middle result after sorting all 100 samples, and distribution means how the scores are spread out instead of just looking at the average.
What stood out immediately
- Average human score: 25.3%
- Median human score: 0%
- Samples that scored exactly 0% human: 51 out of 100
- Samples that reached 50% human or better: 27 out of 100
- Samples that reached 90% human or better: 17 out of 100
- Average length change after rewriting: +22.2%
The Big Picture: Sapling Rejected Most of These Rewrites
The average score already looks weak, but the more revealing number is the median of 0%. In plain English, the middle sample in this set still landed at the floor. That tells us this was not a case where most rewrites were “sort of” convincing. A large share of them simply failed.
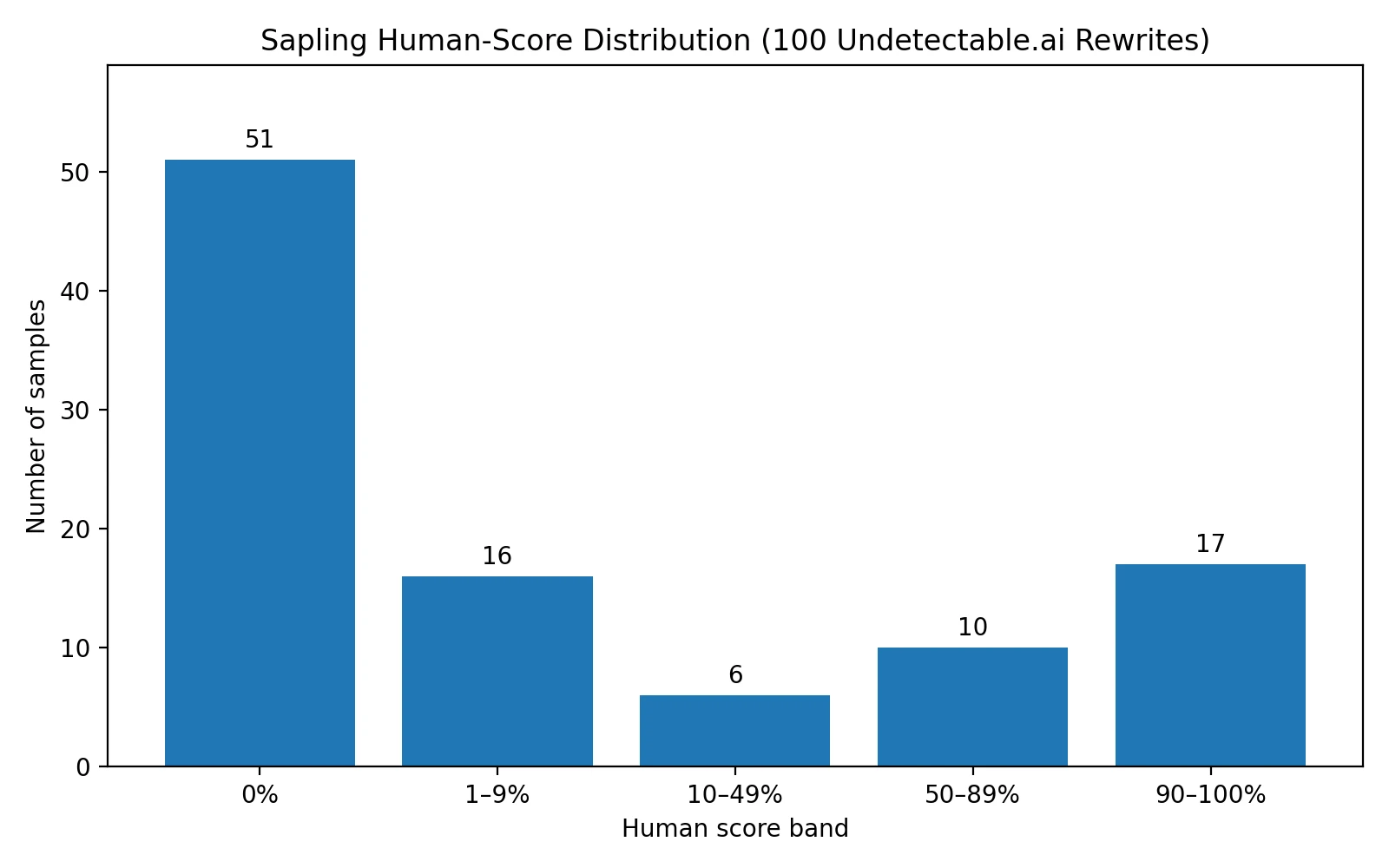
The score distribution is especially interesting because Sapling was rarely undecided. There were zero samples in the 25–49% band. Instead, the detector often behaved like a hard gate: either it strongly rejected the rewrite, or it occasionally let one through with a high score. That kind of all-or-nothing behavior matters for students because it means you cannot rely on a “pretty good” middle zone to save you.
Also Read: [STUDY] Can Undetectable AI Bypass GPTZero? A 100-Sample Reality Check
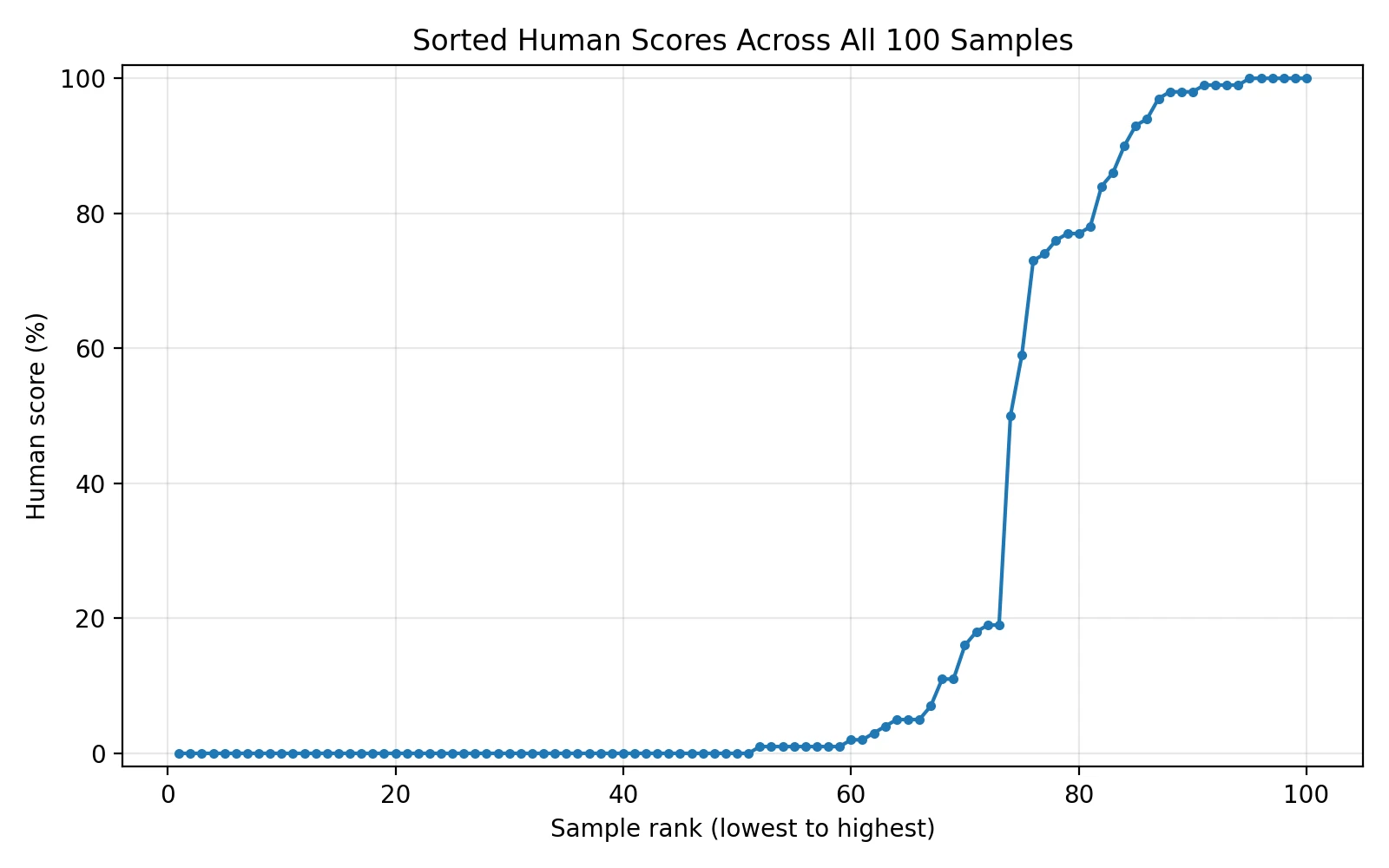
That last point is important. This was not a complete shutout. Seventeen rewrites scored between 90% and 100% human, and ten of those hit 99% or 100%. So the honest conclusion is not “it never works.” The honest conclusion is that it works sometimes, but the success pattern is too uneven to call it reliable.
Making the Text Longer Did Not Solve the Problem
One common belief is that if a humanizer expands the text, adds more transitions, and sounds more conversational, detectors will be easier to fool. This dataset does not support that idea very well.
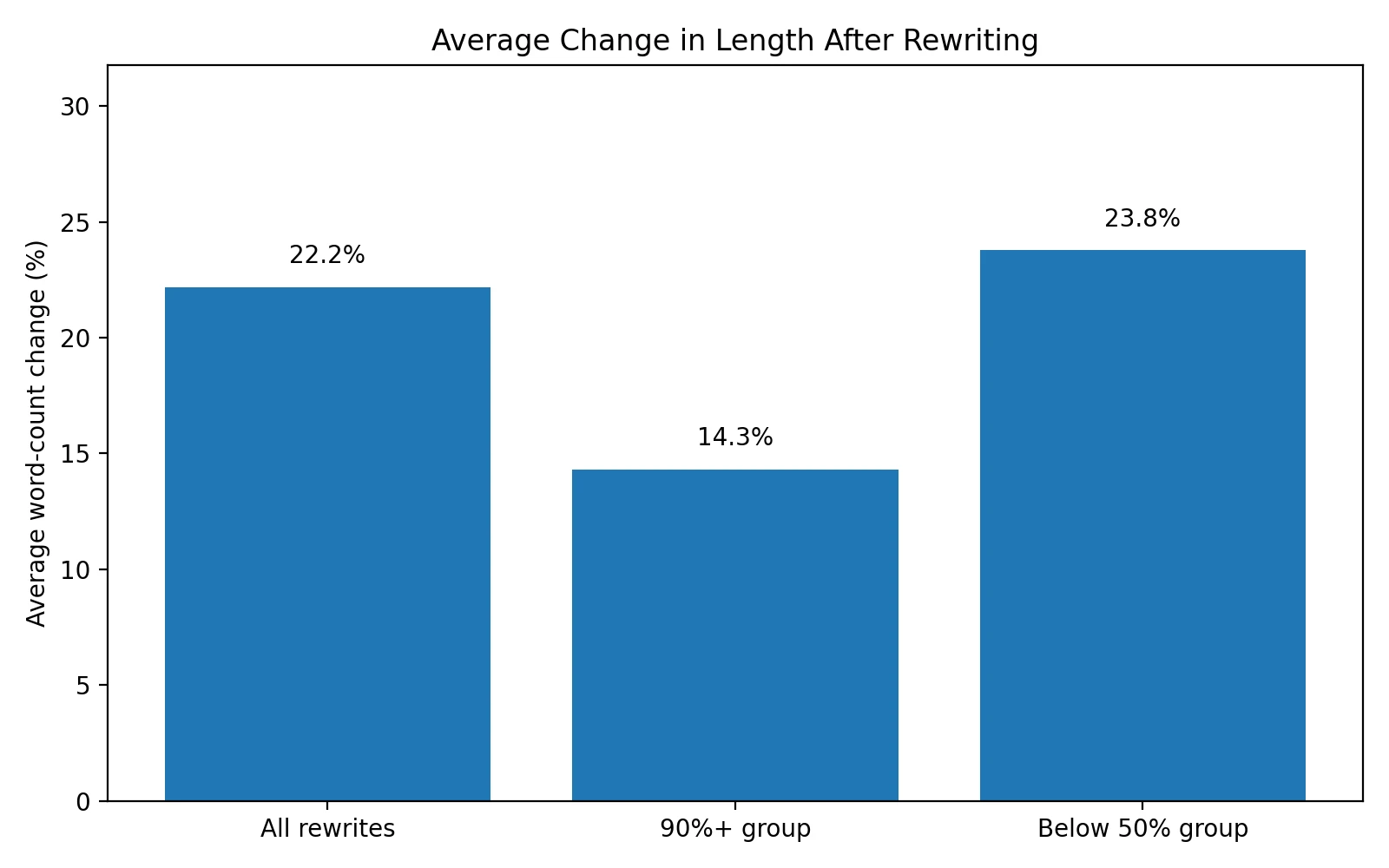
Across the full set, the rewrites were about 22% longer than the originals. But the 90%+ group only expanded by about 14% on average, while the below-50% group expanded by about 24%. In other words, the weaker outputs were often the more bloated ones. That suggests extra wording may have made some passages sound less natural, not more natural.
Also Read: [STUDY] Can Undetectable AI Bypass Originality AI? A 100-Sample Reality Check
The Hidden Cost: Rewrite Quality Problems
Detector scores are only half the story. If a rewrite passes but damages the writing, that is still a bad outcome. After reviewing the CSV, several patterns showed up again and again.
1) Over-expansion and padding
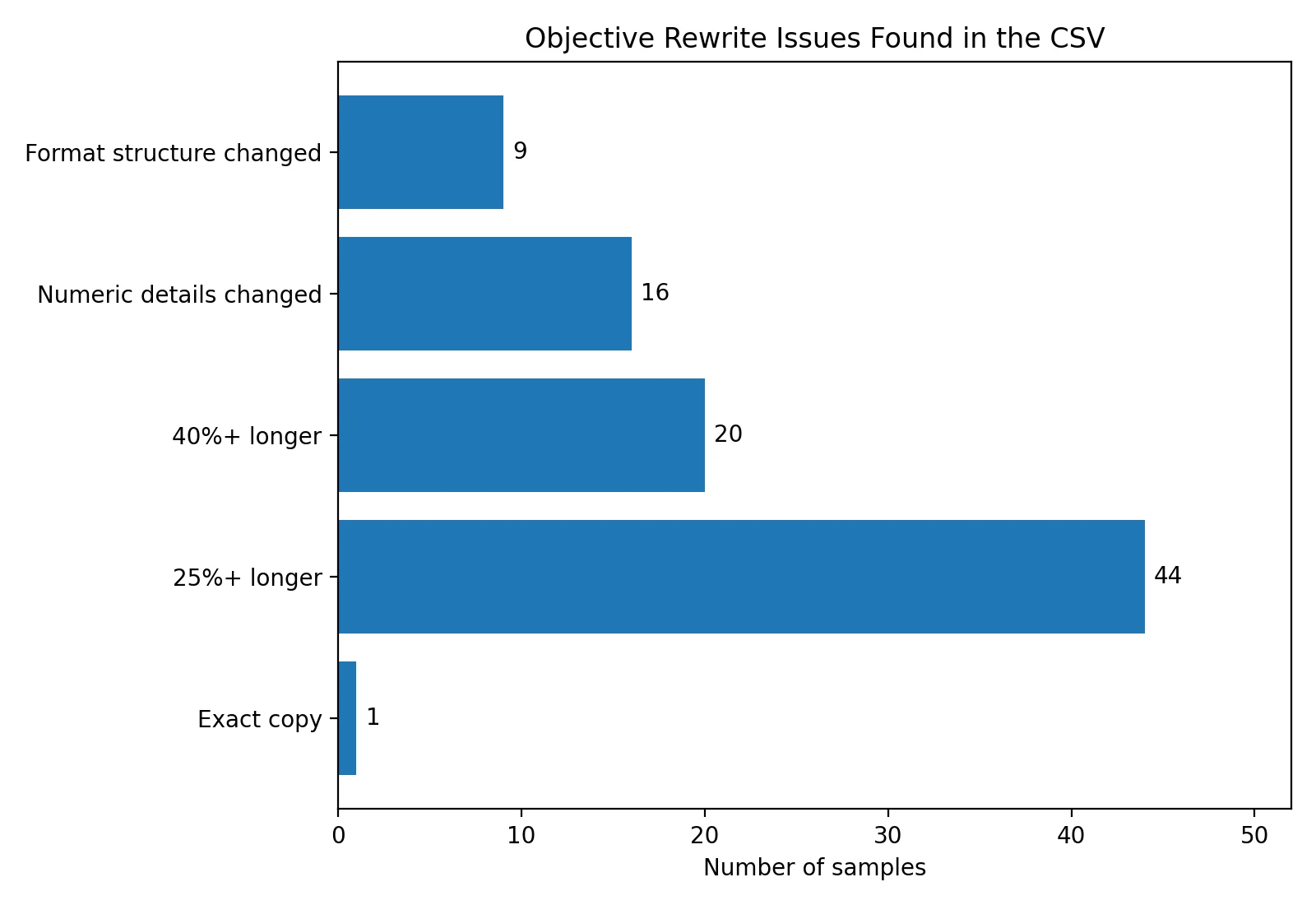
Undetectable.ai often rewrote by adding more words rather than sharpening the original idea. In this set, 44 rewrites were at least 25% longer, and 20 were more than 40% longer. For students, that matters because longer does not always mean better. It can make an answer sound repetitive, vague, and harder to follow.
2) Meaning drift
In 16 rows, the rewrite changed or introduced a number, date, time reference, or similar factual detail. That does not automatically mean every one of those rows became false, but it does mean the text moved beyond safe paraphrasing.
- A fast-fashion rewrite added a 24/7 shopping idea that was not stated in the original passage.
- Another rewrite brought in the phrase “2 Degrees initiative” even though it was not in the source text.
- A historical example around King Tut became visibly mangled, mixing dates and words into a broken opening.
For school writing, this is a serious issue. A detector score is pointless if the rewritten paragraph quietly changes the meaning of the source.
3) Formatting damage
I found 9 samples where structure changed in a noticeable way, such as altered label formatting, changed line-break structure, or lost colon-based headings. That may sound minor, but if you are rewriting study notes, procedures, step-by-step instructions, or outlines, formatting is part of the meaning.
4) Exact copy and near-copy behavior
One row in the CSV was an exact copy of the original text rather than a real rewrite. That is a problem on its own, but it is also revealing: the copied row still scored 0% human. A “humanizer” that sometimes fails to meaningfully change the text is not giving you a dependable shortcut.
5) Gibberish and broken wording
Some of the weakest outputs did not just sound awkward. They looked corrupted. A battery-related passage began with “The them to over heat or even leak”. A historical rewrite started with “King1332”. A GPS example merged words into “The1970s”. These are not subtle style problems. They are the kind of mistakes that make readers stop and wonder what happened.
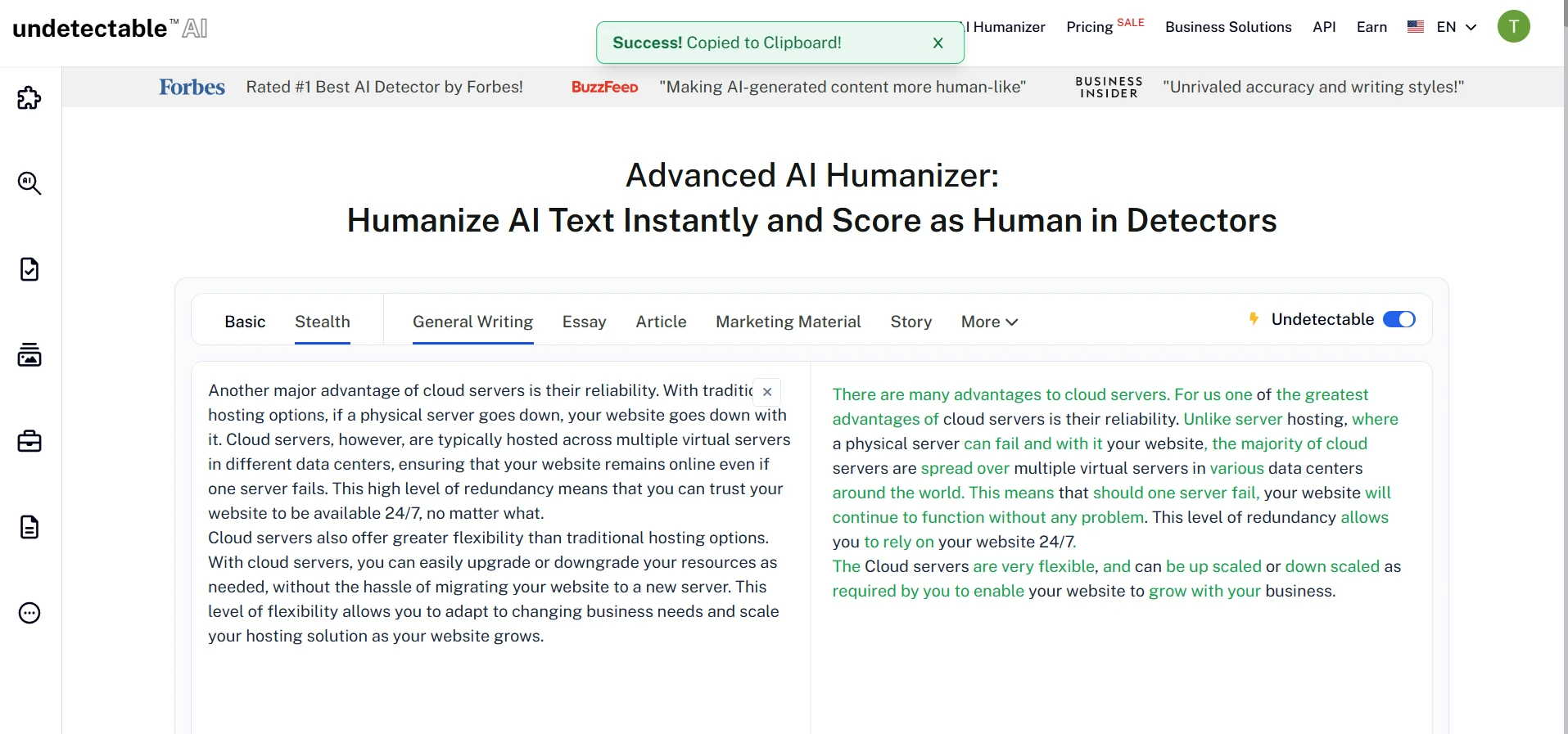
What the Rewrites Looked Like in Practice
The screenshots below show the general style of the Undetectable.ai rewrites used in this test. Some outputs clearly try to sound more human by using simpler wording and extra explanation, but that does not always translate into a stronger detector result.
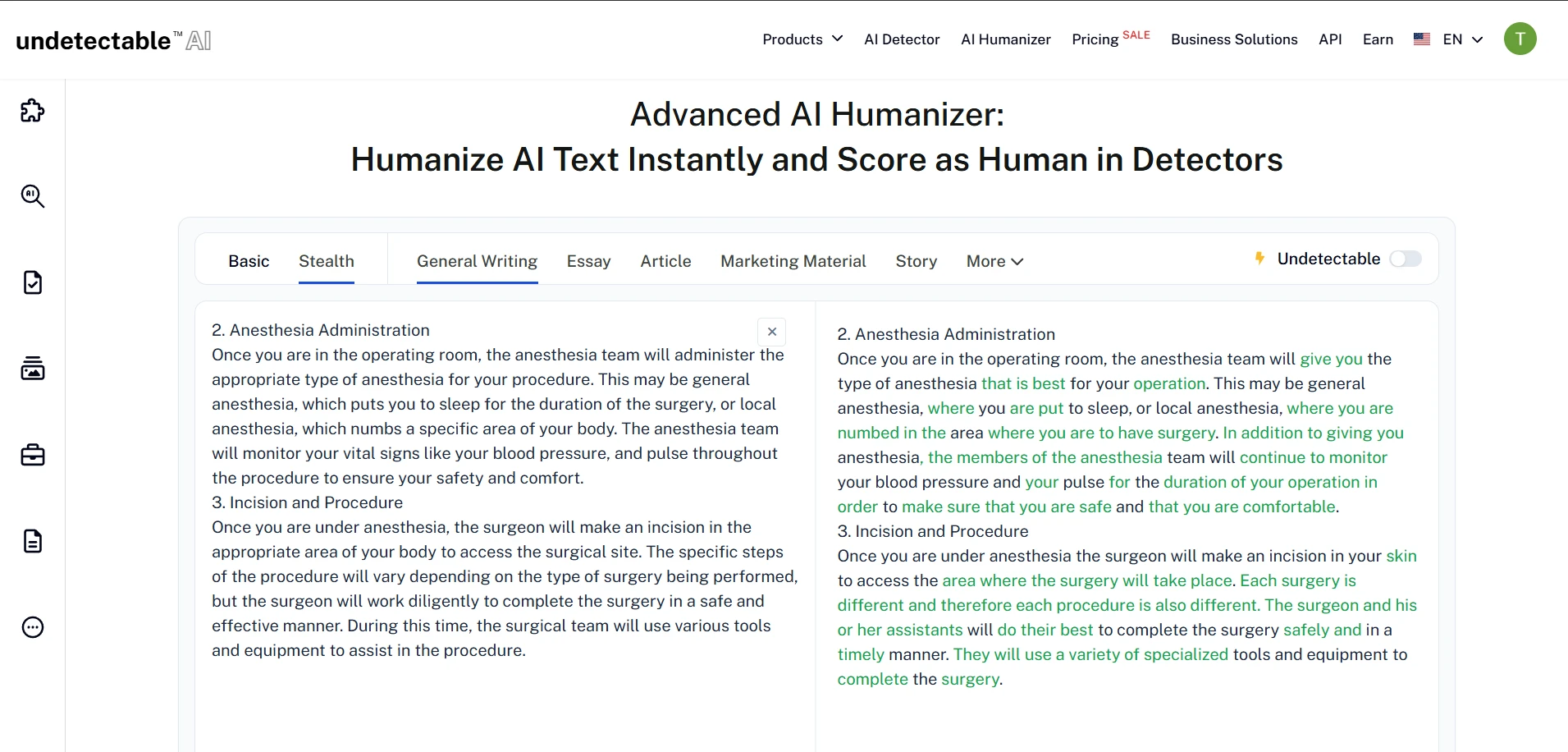
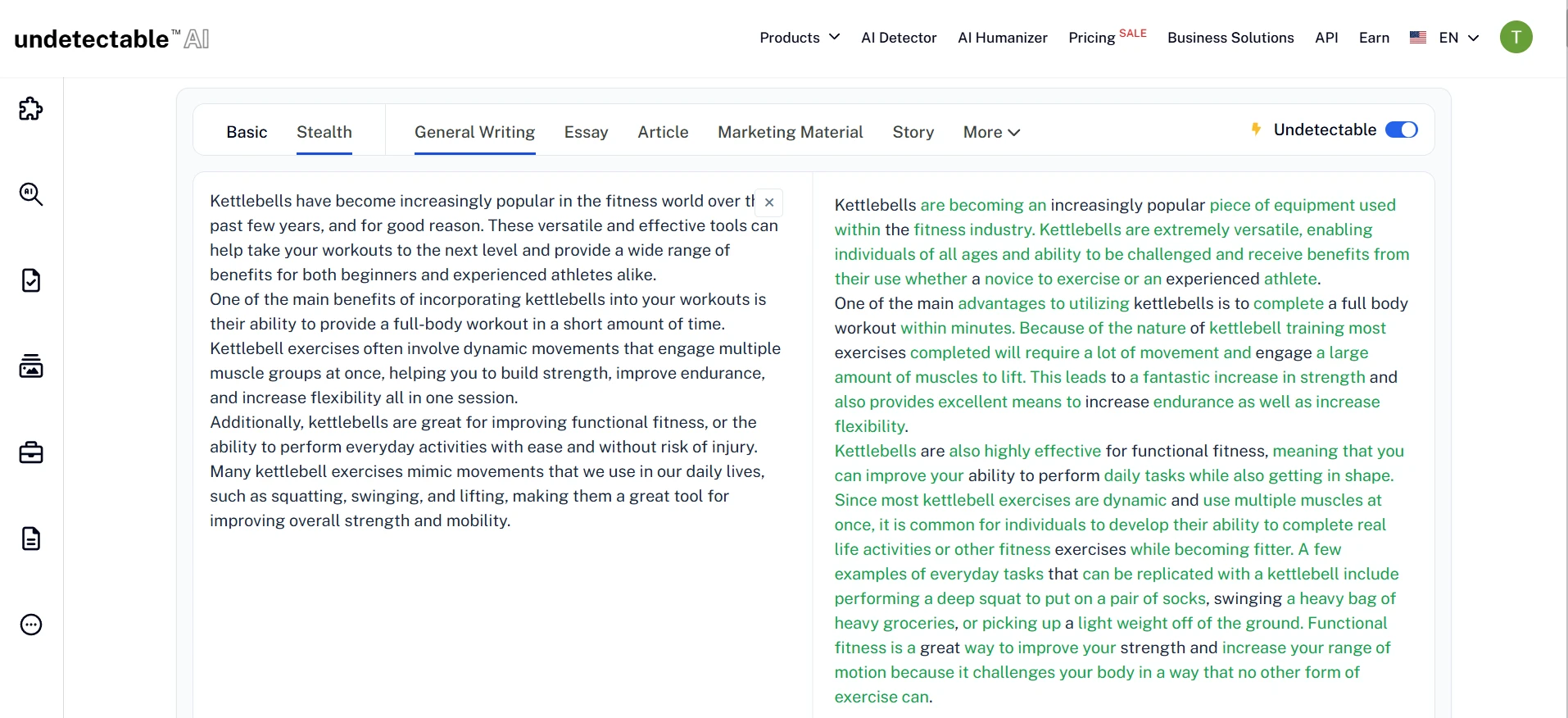
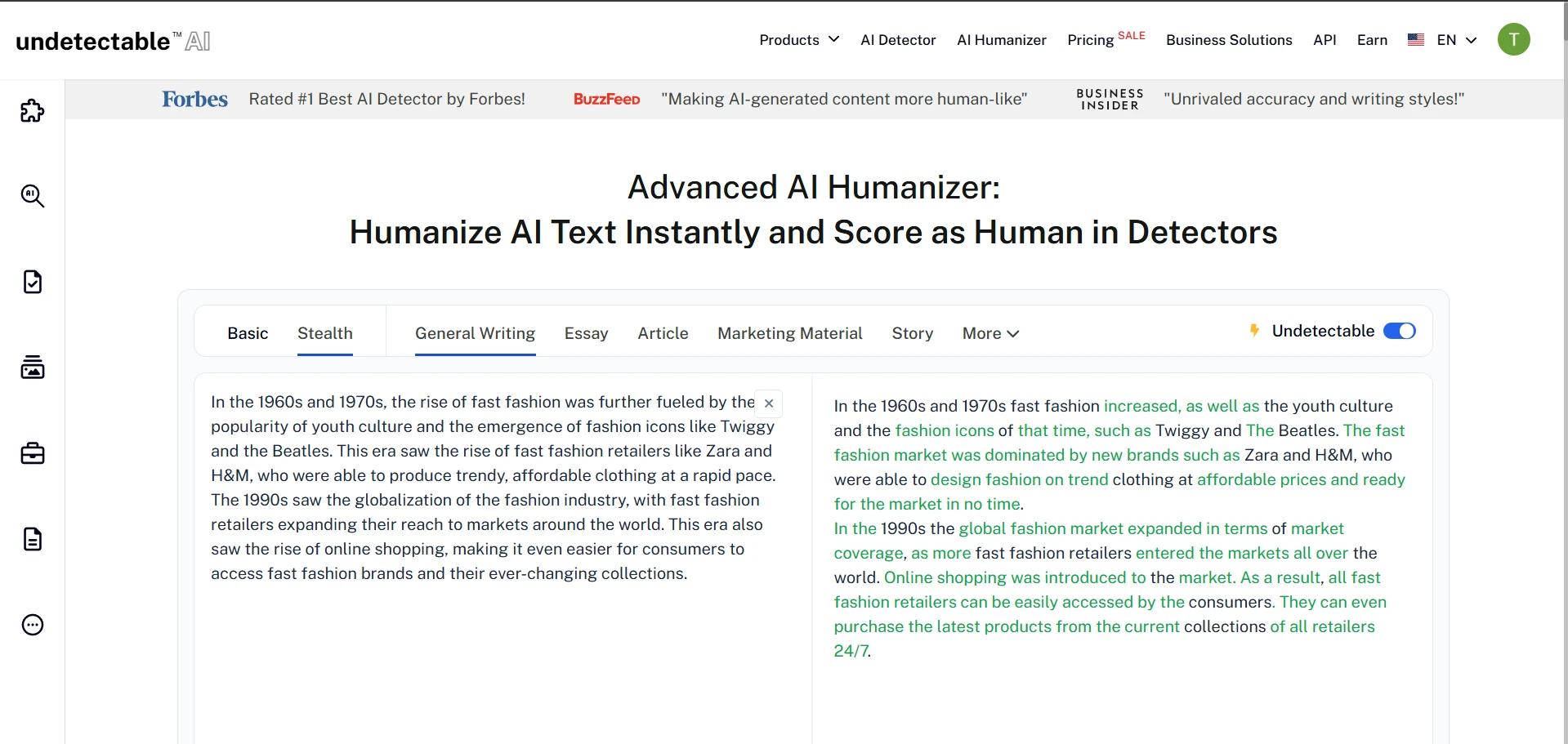
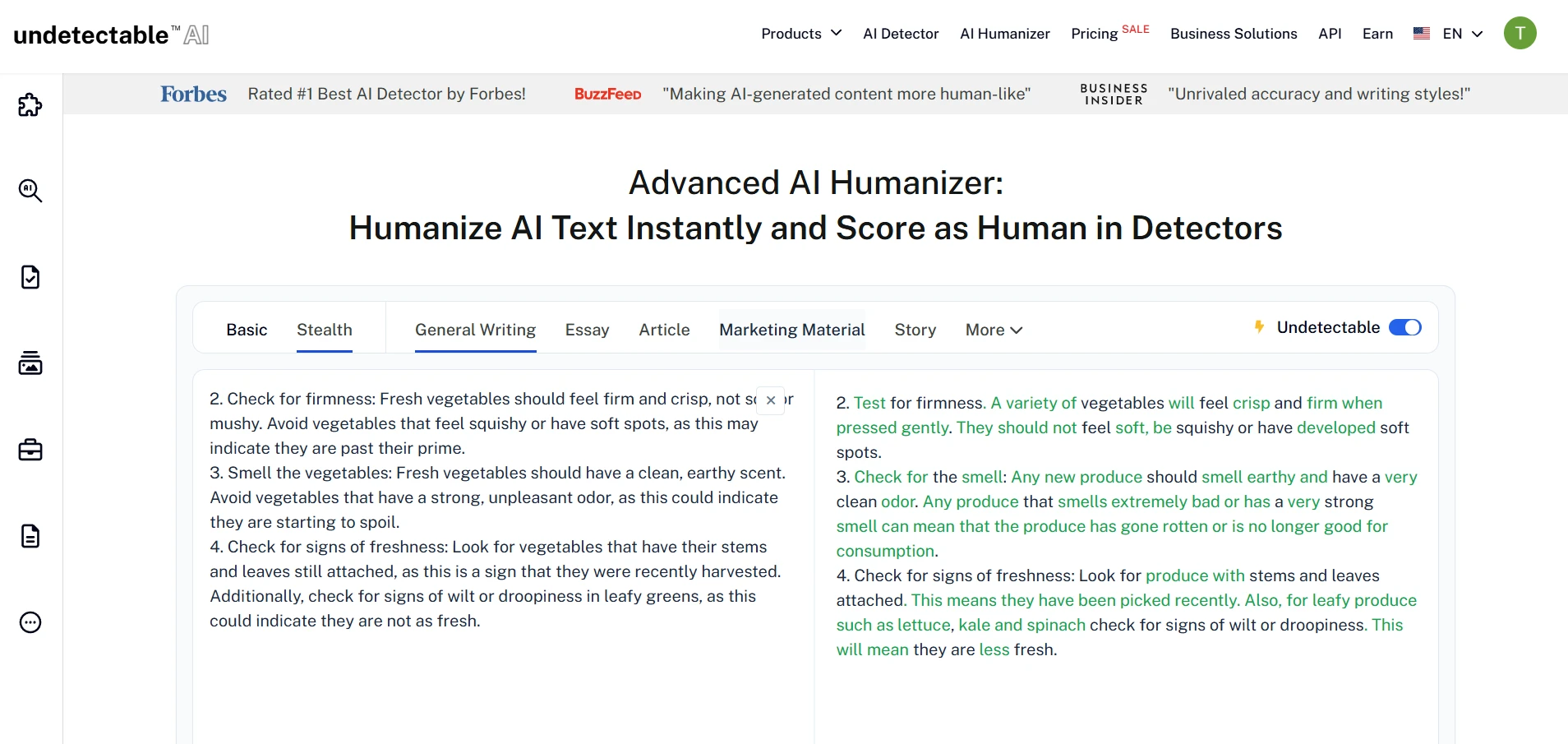
Final Verdict: Occasional Wins, Weak Reliability
If your question is whether Undetectable.ai can sometimes bypass Sapling AI, the answer is yes. A small group of rewrites scored extremely well. But if your question is whether it can do this consistently, the answer from this 100-sample dataset is no.
Most rewrites failed outright, the median score was 0%, and the text quality problems were too frequent to ignore. For students, that is the real lesson. Even when a humanizer improves the detector score, it may also stretch the text, disturb formatting, or drift away from the original meaning. A tool that occasionally delivers a high score but often creates new writing problems is not a dependable safety net.