![[STUDY] StealthWriter vs Sapling AI: Can 100 Humanized Rewrites Slip Through?](/static/images/stealthwriter-ai-vs-sapling-featured-imagepngpng.webp)

AI detectors can feel like final judges, but the real question is simpler: when an AI humanizer rewrites text, does another detector actually treat it as human? To test that, we checked 100 StealthWriter AI rewrites in Sapling AI and converted Sapling's result into a human score. A higher number means Sapling was more likely to see the text as human-written. The results were not smooth, not predictable, and not as comforting as a single screenshot might suggest.
How This Test Was Set Up
The dataset contains 100 text samples. Each sample has the original text, the StealthWriter rewrite, and the Sapling human score. In simple terms, a score of 100% means Sapling treated the rewrite as fully human, while 0% means Sapling treated it as fully AI. For this article, I used 50% human as the basic “bypass” line because anything below that still leans more AI than human.
This is not a courtroom-level study, and students should not treat any detector as perfect proof. It is a practical stress test: if a student, blogger, or researcher used StealthWriter and then checked the output in Sapling, what kind of result would they usually see?
Also Read: [STUDY] Can Stealthwriter Outsmart GPTZero? A 100-Sample Test
What the 100-sample test showed:
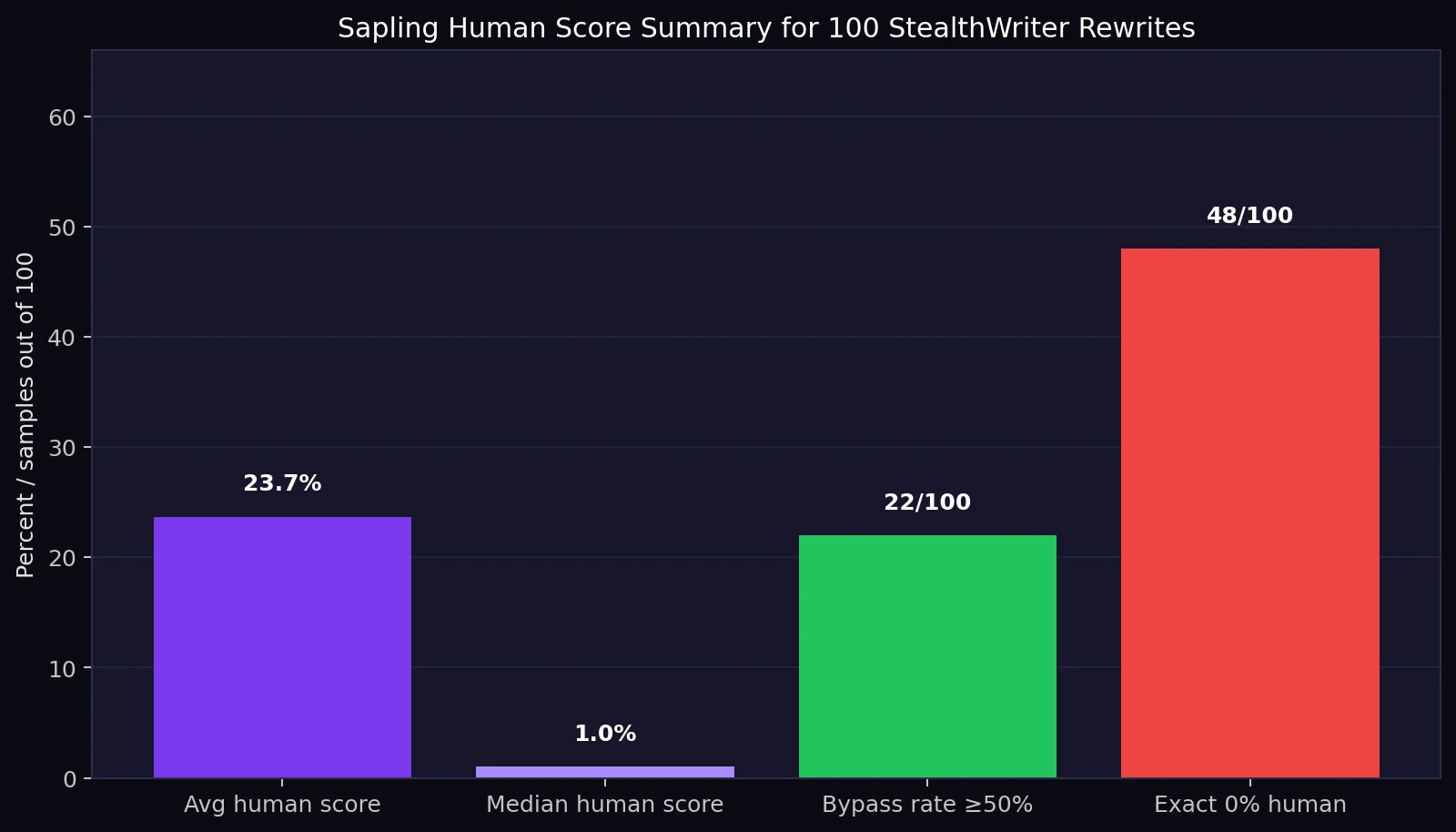
- Average Sapling human score: 23.7%. In everyday words, Sapling still leaned heavily toward “AI” for most rewrites.
- Middle score: 1.0%. The middle score means half the samples scored at or below 1% human.
- Basic bypass rate: 22 out of 100 rewrites scored 50% human or higher.
- Hard failures: 48 out of 100 rewrites received exactly 0% human.
The Main Finding: StealthWriter Did Not Consistently Bypass Sapling
The most important result is the average human score: 23.7%. That is low. If the goal is to make Sapling believe the rewrite is human-written, most samples did not get close. The median, or middle score, is even more revealing at 1.0%. Median is useful here because it is not pulled upward by a small group of perfect scores. It tells us what a typical result looked like, and the typical result was very poor.
The distribution was also uneven. Some rewrites scored very high, including several at 100%. But nearly half of the test set scored 0%. That means StealthWriter did not produce a steady improvement across the whole dataset. Instead, the results looked like a split: some outputs slipped through, while a much larger group was still flagged strongly by Sapling.
Also Read: Stealthwriter vs ZeroGPT: I Tested 100 Rewrites, and the Results Were Complicated!
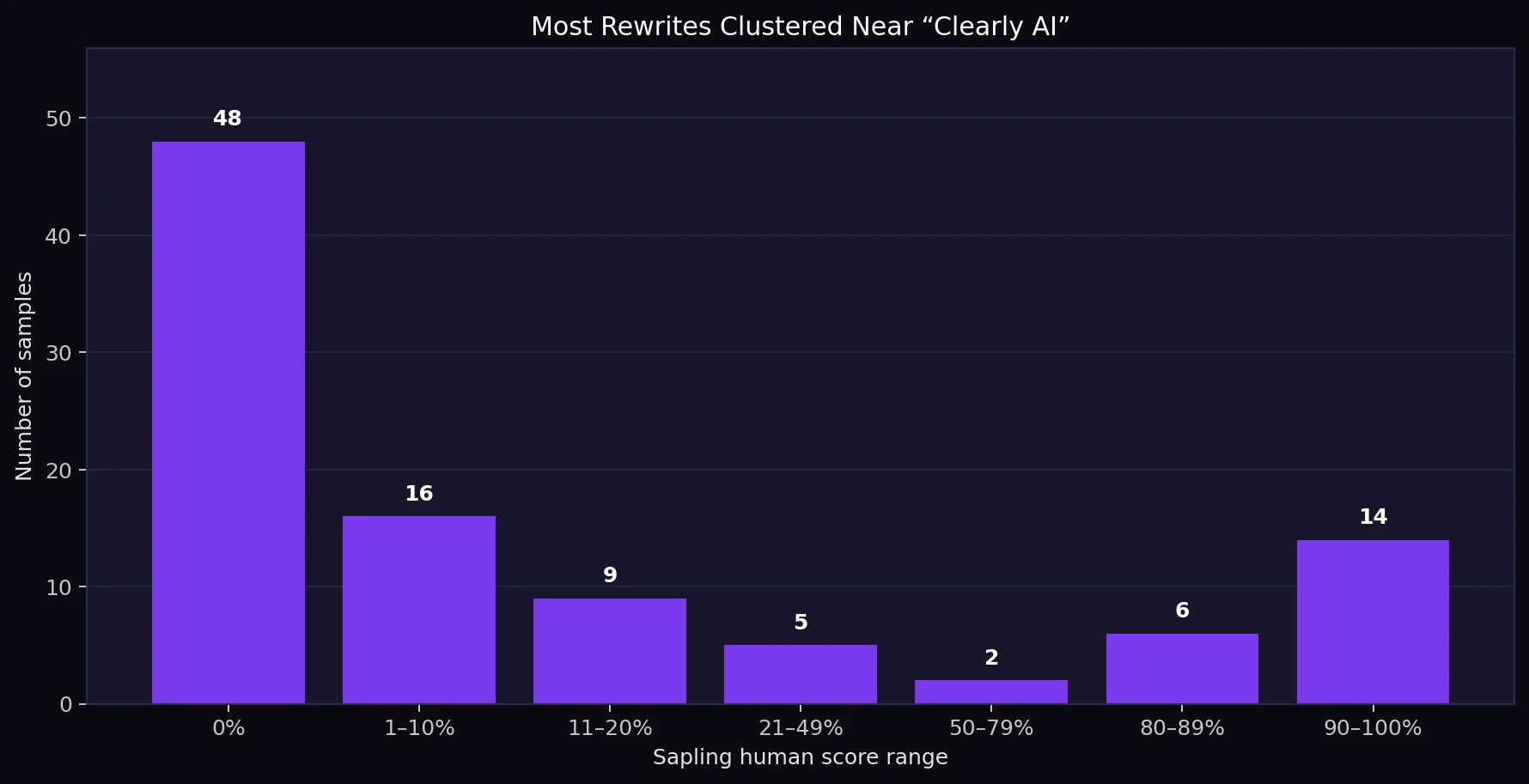
What Counts as a Pass Depends on How Strict You Are
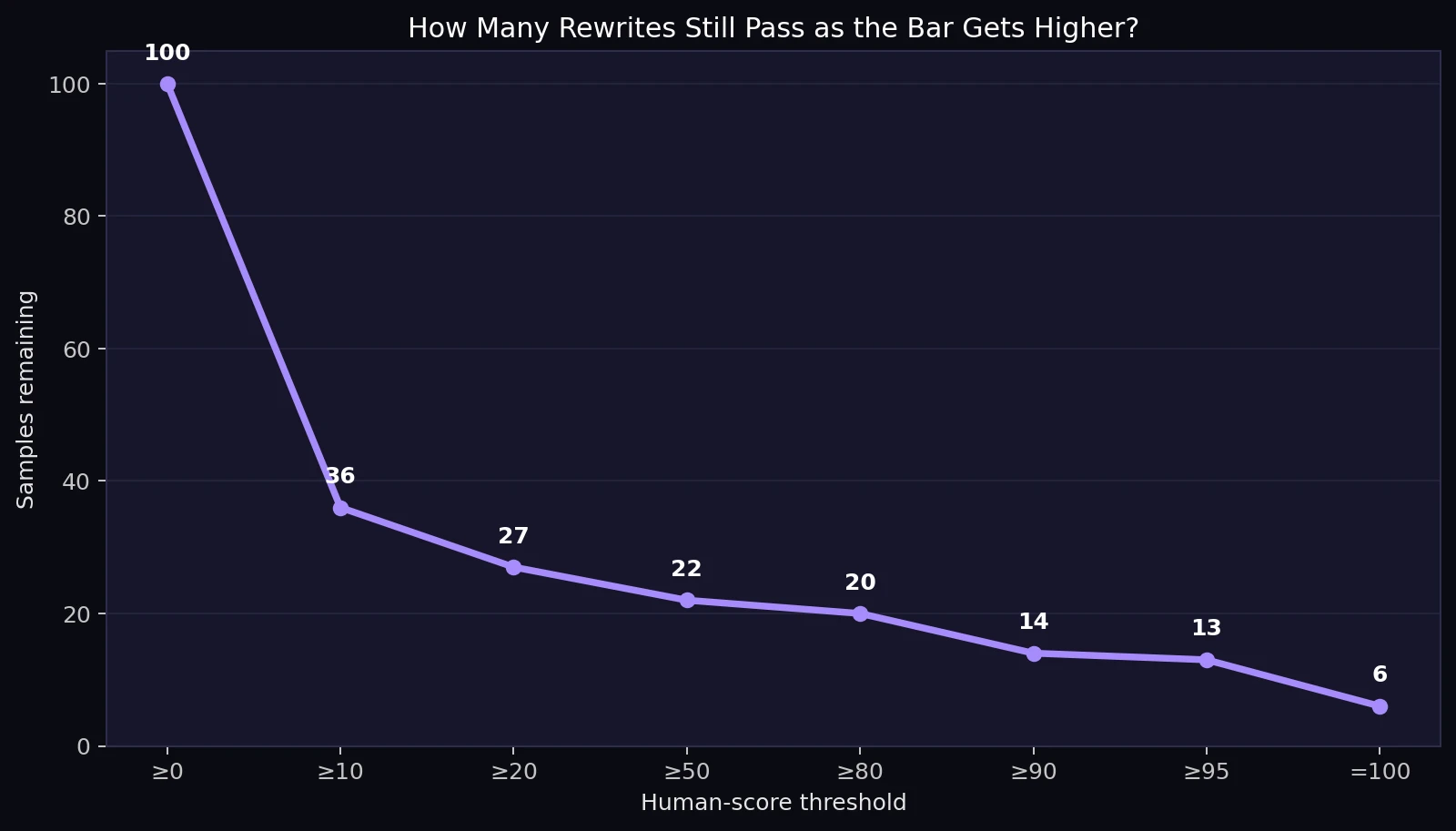
A 50% score is a generous pass line. It only means Sapling leaned slightly more human than AI. Under that standard, 22% of rewrites passed. If the standard is raised to 80%, only 20 samples remained. At 90%, the number dropped to 14. Only 6 samples reached a perfect 100% human score.
This matters because many users do not simply want a borderline result. They want a clean result that looks safely human. On that tougher standard, StealthWriter's performance becomes less impressive. A few wins are real, but they do not represent the whole batch.
Also Read: [STUDY] Can Stealthwriter really slip past Originality.ai? I tested 100 rewrites to find out.
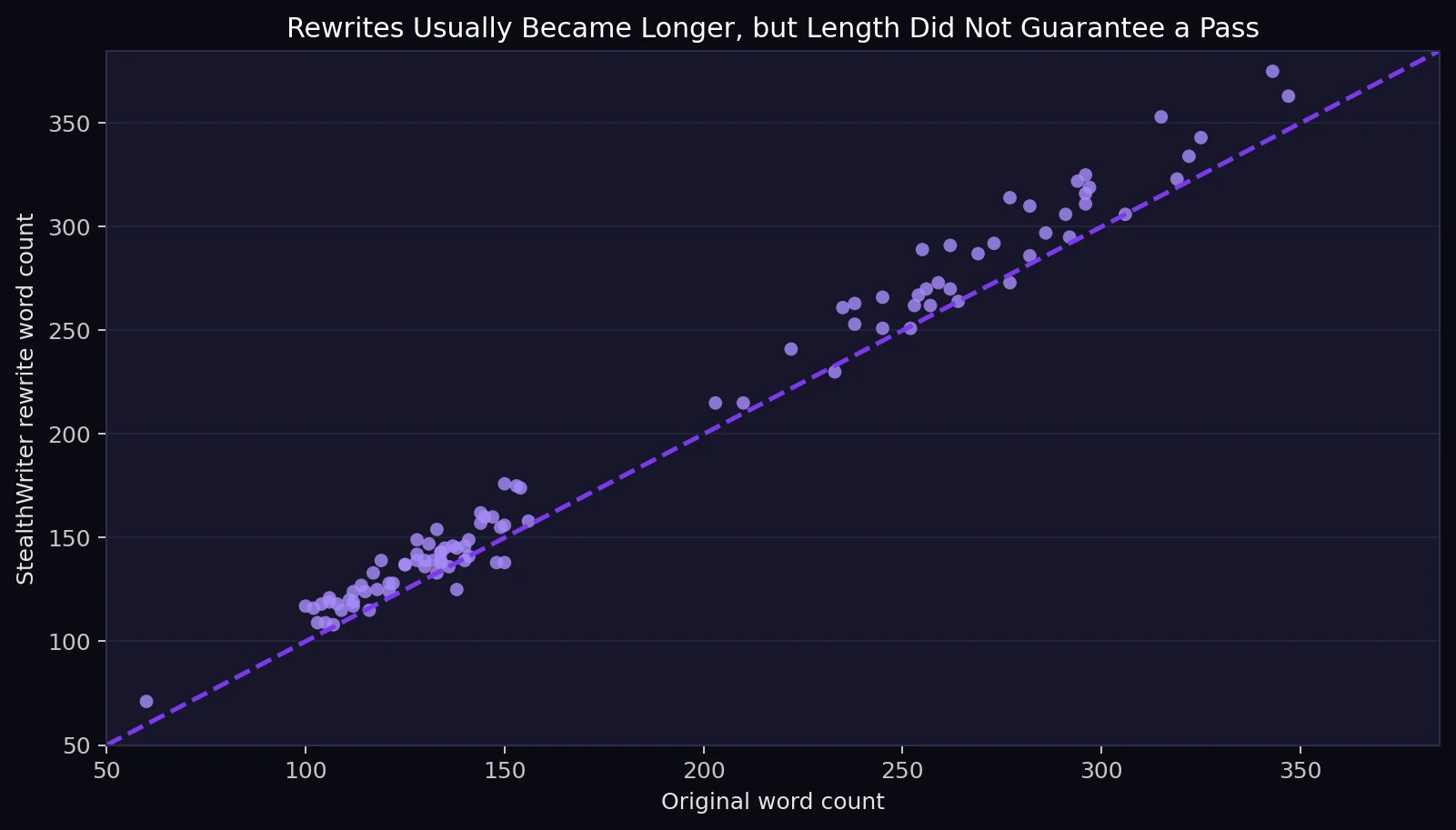
Longer Rewrites Did Not Automatically Look More Human
StealthWriter usually expanded the text. The original samples averaged about 185 words, while the rewrites averaged about 197 words. In 87 out of 100 cases, the rewrite was longer than the original. That might sound helpful, but the chart below shows that length was not the secret ingredient. Shorter and longer rewrites both failed, and some long rewrites still scored near zero.
For students, the lesson is simple: adding more words does not automatically make writing sound human. Human writing is not just longer. It is accurate, clear, varied, and specific.
The Hidden Problem: Some High Scores Still Had Bad Rewrites
The detector score is only one part of the story. While reviewing the rewritten text, several quality issues appeared. This is important because a rewrite can pass a detector and still be weak, awkward, or factually wrong.
One rewrite about Amazon Prime said the company “no longer” offered two-day shipping, even though the original meaning was that Prime expanded beyond just two-day shipping. That is a meaning change. A section about bees changed the explanation of pollination and made the direction of pollen transfer confusing. In a battery safety sample, “unplug your device once it reaches full charge” became “discharge your gadget after it is fully charged,” which is not the same advice.
There were also formatting and polish issues. One breakfast list repeated the number 2 twice, creating a broken sequence. A vegetable-checking sample had a lowercase heading: “3. smell the vegetables.” Several dates and centuries were spaced oddly, such as 17 th, 18 th, and 21 st. Some wording was noticeably unnatural, such as “Fungi are very simple to ignore” and “mushrooms... cap and skeleton.”
These problems matter more than the detector score. If a teacher, editor, or reader notices a contradiction, strange phrase, or broken list, the text loses trust immediately. Passing a detector cannot fix a bad sentence.
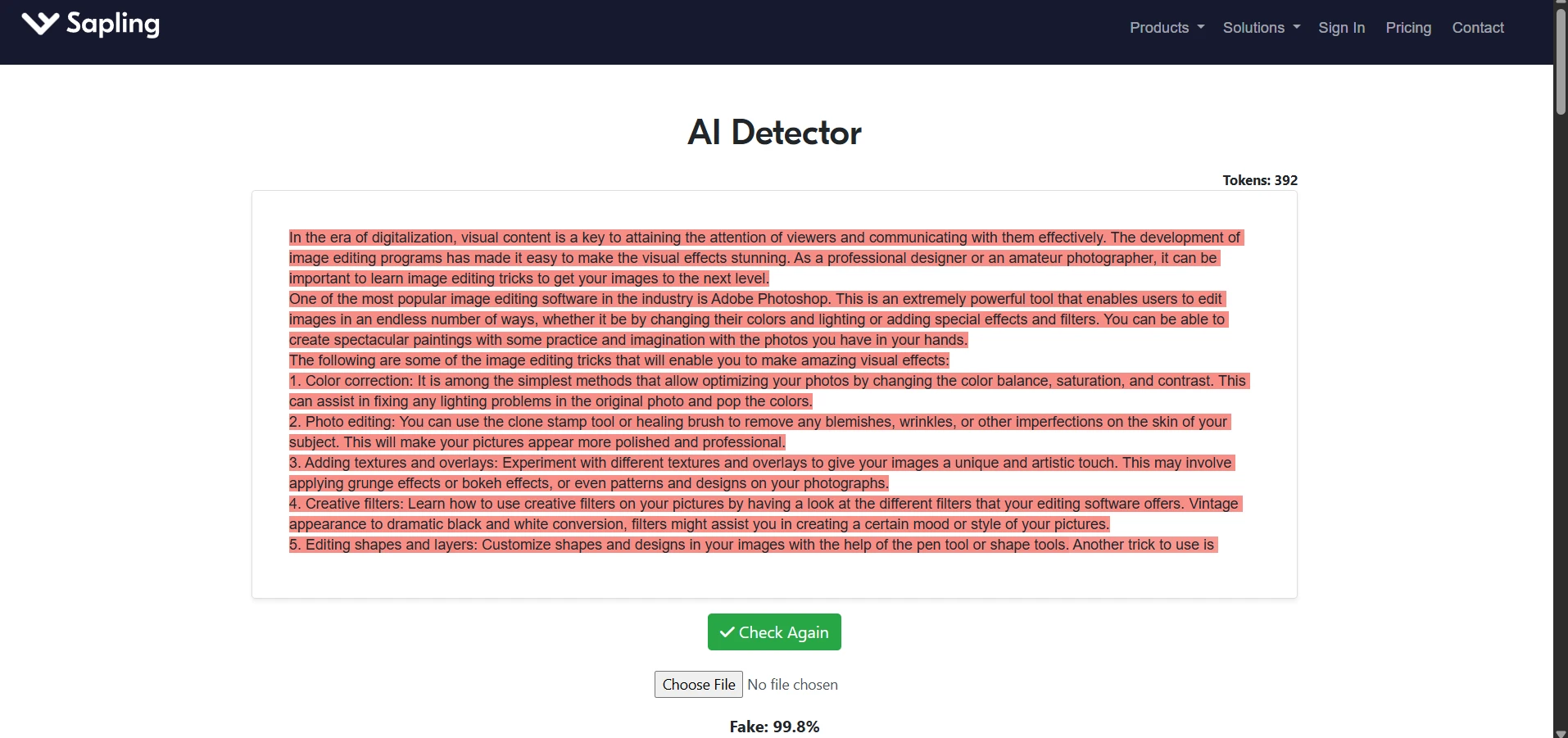
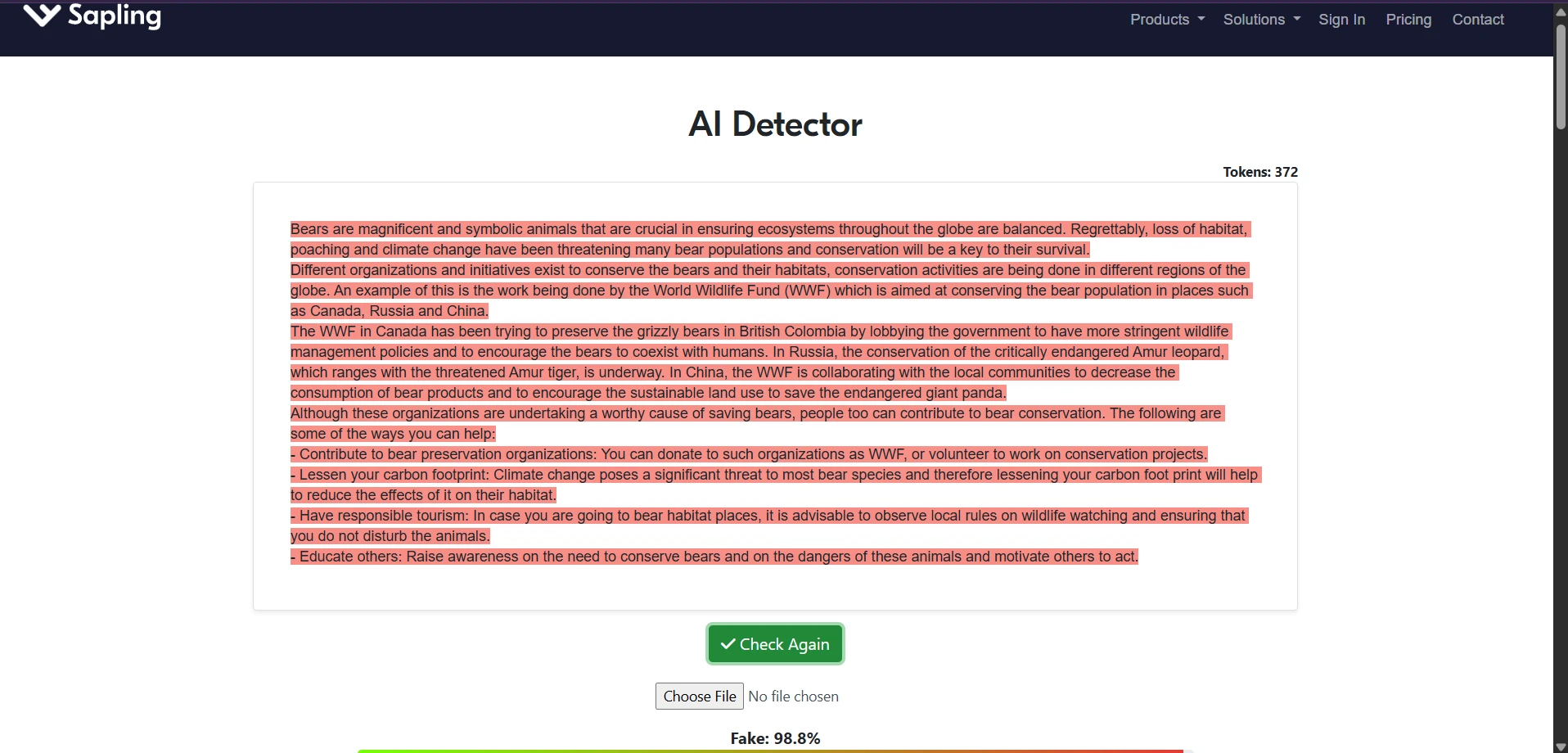
Sample Screenshots From the Test
The screenshots below show the kind of testing workflow used: StealthWriter outputs on one side and Sapling AI checks on the other. They also show why a few green-looking results should not be confused with a full victory across all 100 samples.
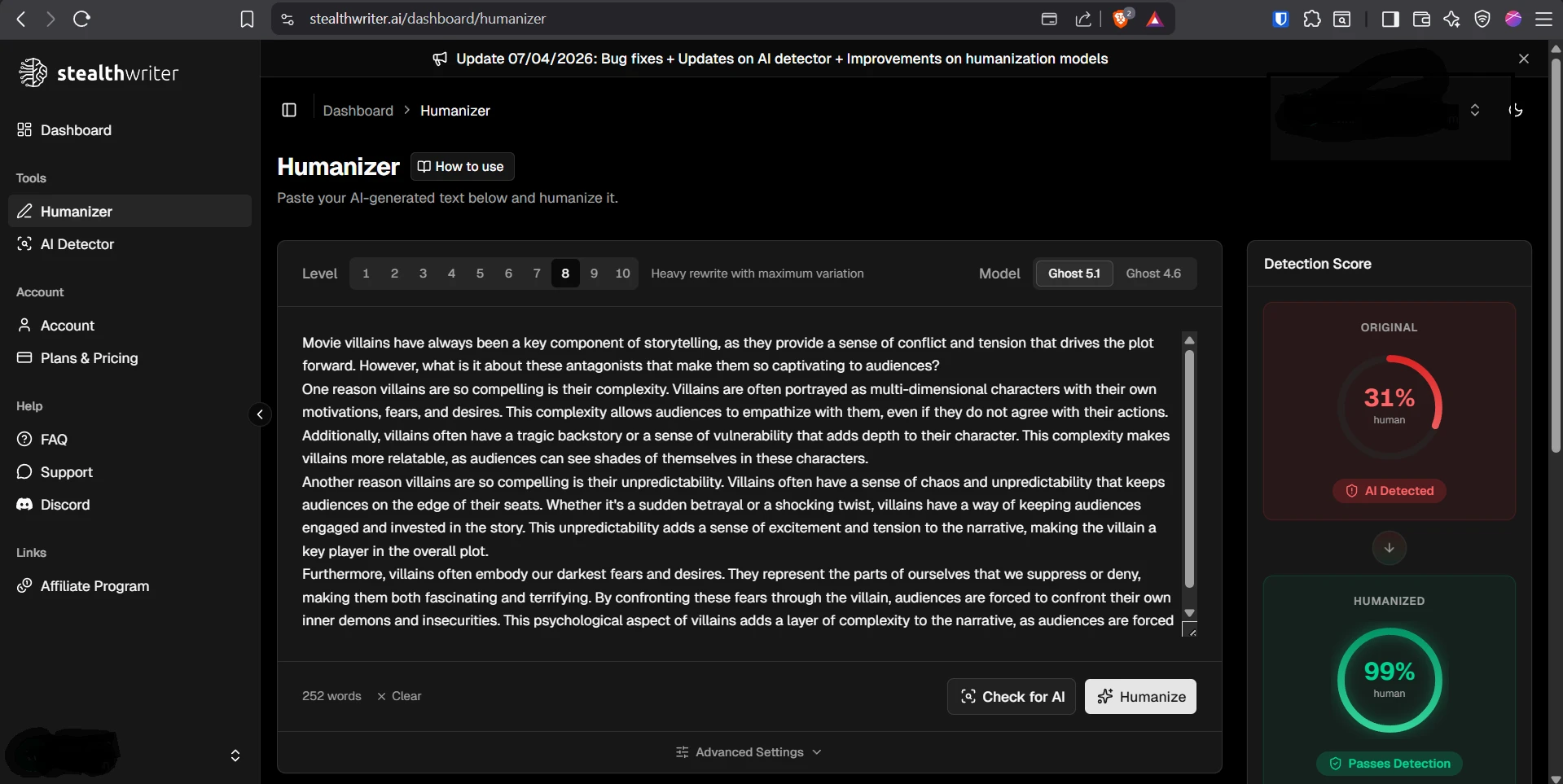
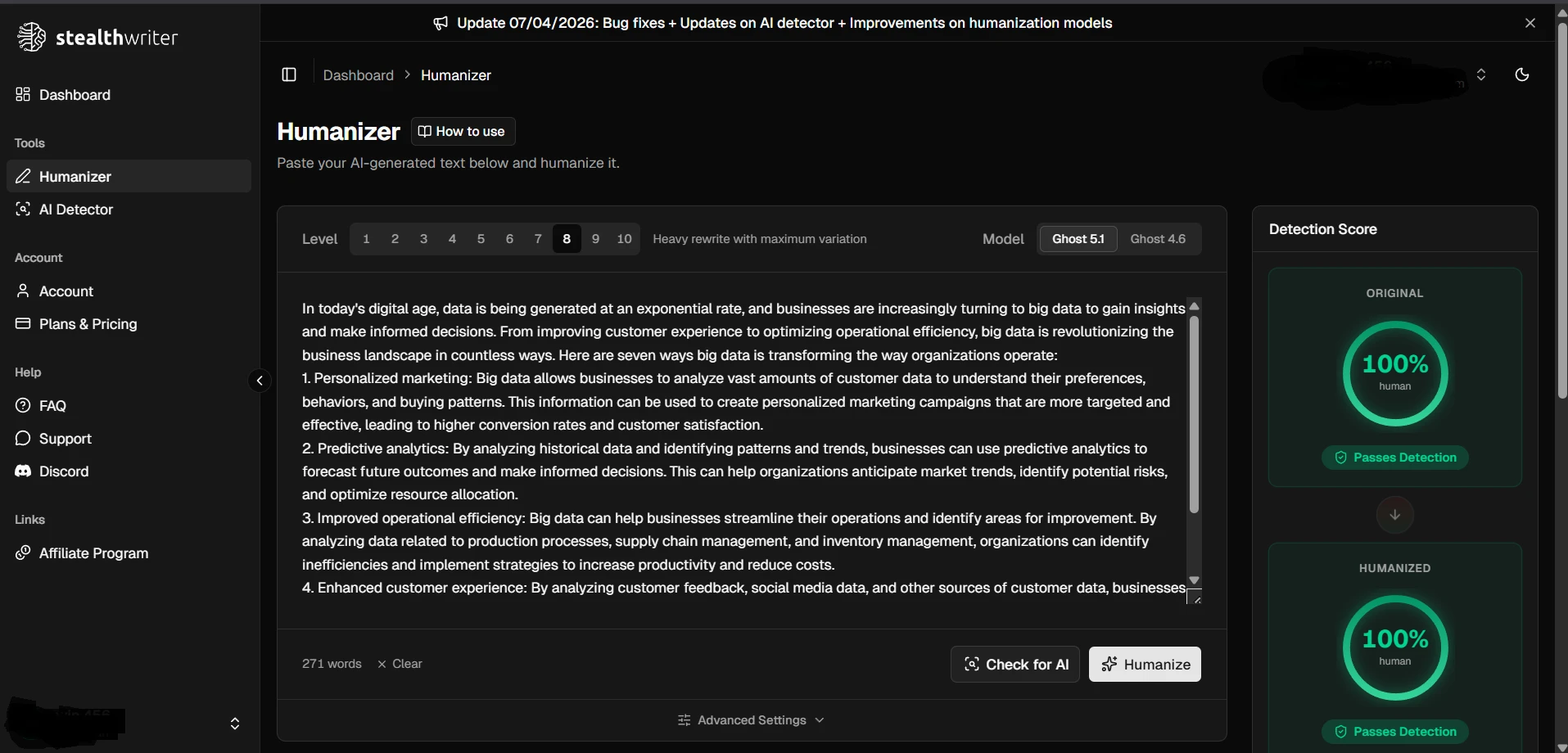
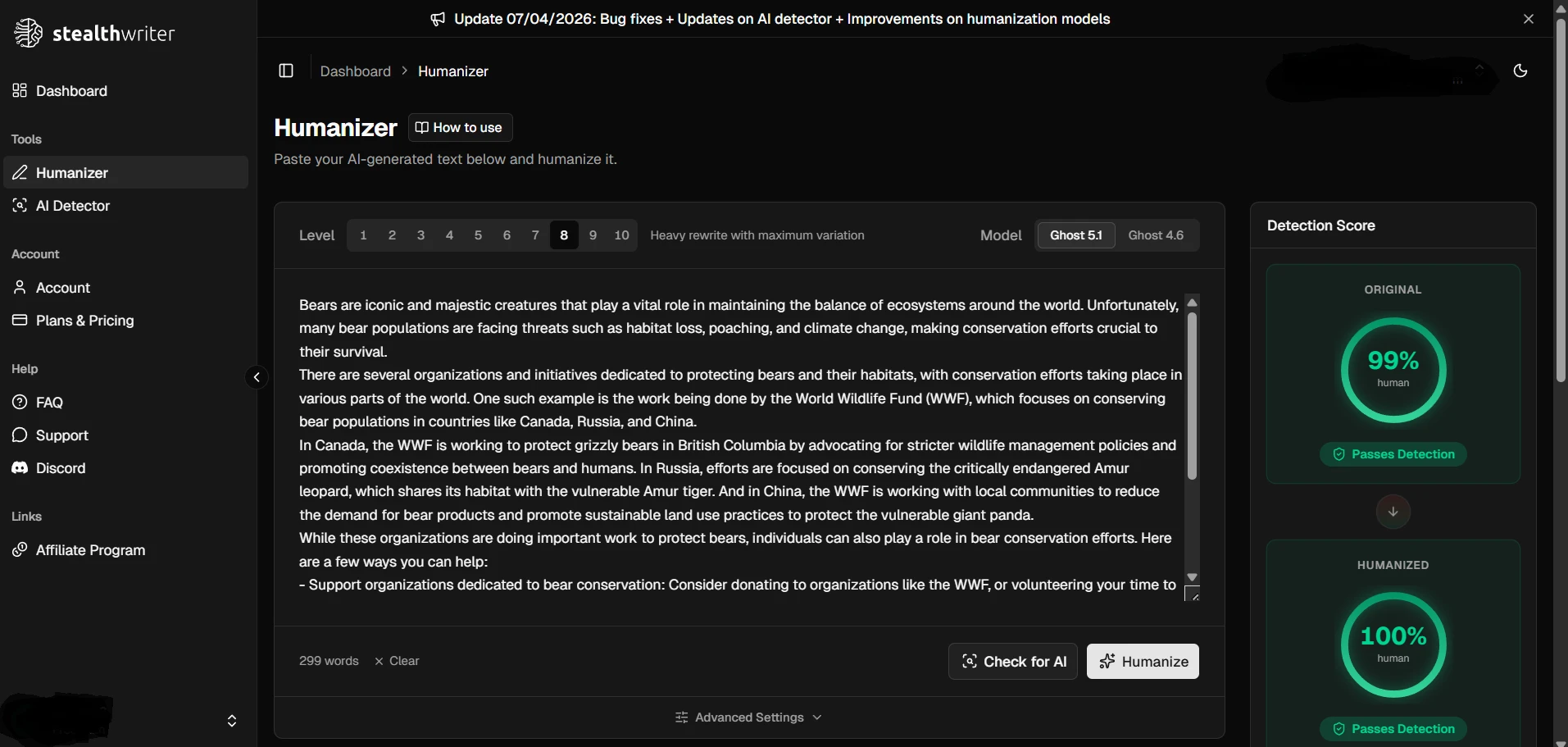
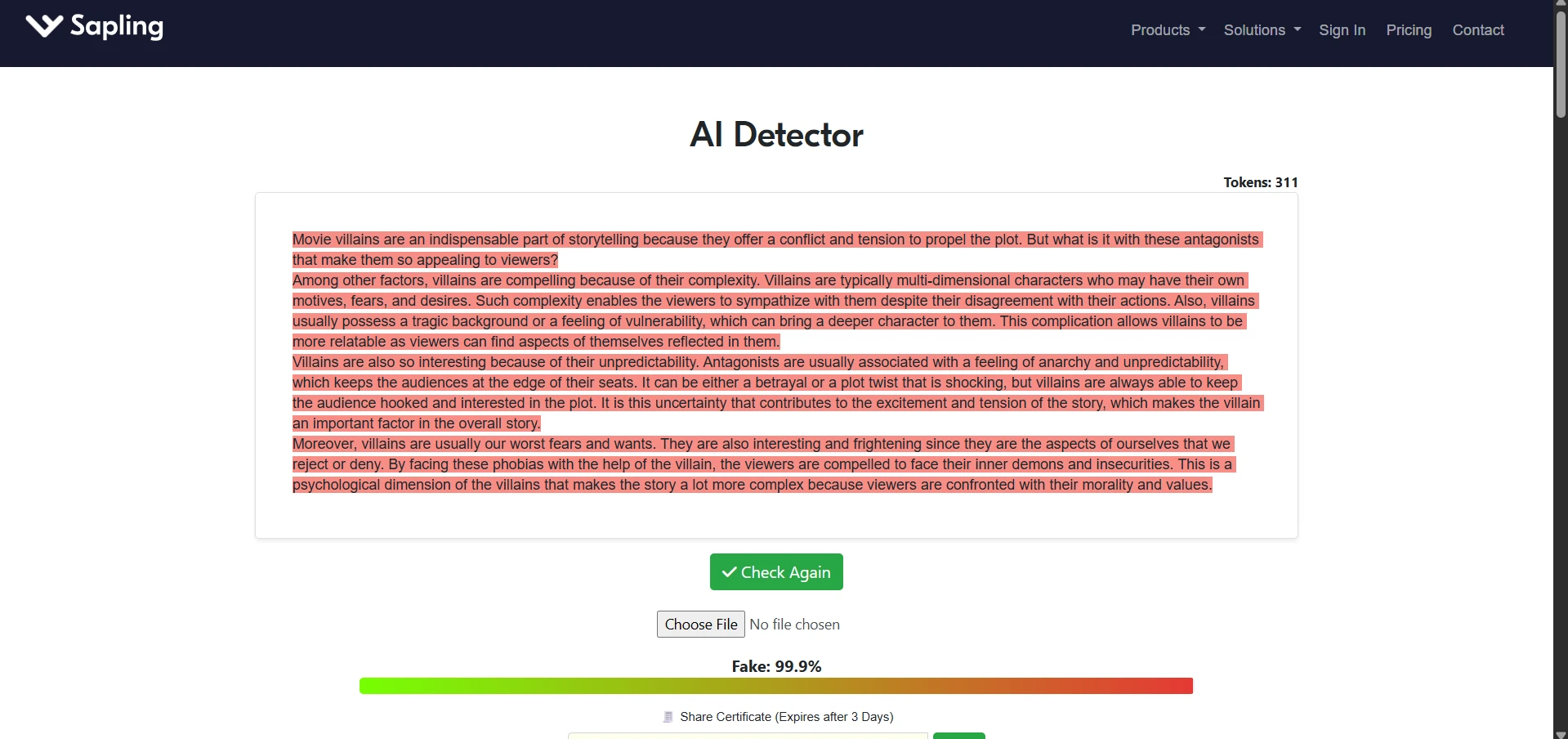
Final Verdict: Useful Sometimes, Risky as a Strategy
Across 100 samples, StealthWriter AI was not consistently effective at bypassing Sapling AI. The average human score was only 23.7%, and only 22 out of 100 rewrites crossed the basic 50% human line. That means Sapling still flagged most outputs as more AI than human.
The bigger takeaway is about writing quality. Some rewrites changed meaning, introduced awkward wording, or damaged formatting. For students, this is the real warning: do not judge your work by a detector score alone. A strong piece of writing should make sense, preserve facts, sound natural, and feel like something you can confidently explain. If a tool helps you revise, use it carefully. But never let it replace your own reading, checking, and thinking.