

There is a tempting promise behind every AI “humanizer”: paste in robotic text, press a button, and come out the other side looking natural. But a detector score is only part of the story. If the rewrite beats the detector while adding awkward wording, broken numbering, or factual drift, did it really solve the problem? To answer that, I reviewed a CSV of 100 Stealthwriter rewrites and looked at both the numbers and the writing itself.
What exactly was tested?
Each row in the dataset included an original passage, a Stealthwriter rewrite, and a score from ZeroGPT that had already been converted into a human score. That matters because detector tools usually talk in terms of “AI percentage.” Here, the scale is flipped: the higher the number, the more human the text appeared.
This means the goal of the test was practical, not philosophical. I was not trying to prove whether ZeroGPT is the final judge of what is or is not human writing. I was testing something simpler: when Stealthwriter rewrites text, how often does ZeroGPT treat that output as human-looking? For students, that is the real question, because consistency matters more than one lucky result.
Also Read: [STUDY] Can Stealthwriter really slip past Originality.ai? I tested 100 rewrites to find out.
The headline numbers
- Average human score: 58.5/100
- Median human score: 59/100
- Practical 50+ cutoff: 66 out of 100 rewrites cleared it
- Strong 80+ result: only 26 out of 100 reached that level
- Extreme volatility: 11 samples scored 0, while 23 scored 100
The most important word here is volatility. In simple terms, volatility means the results jump around a lot instead of landing in a tight, predictable range. That is exactly what happened. The average was decent, but the spread was huge. Some rewrites looked extremely human to ZeroGPT, while others fell flat immediately. For anyone hoping for a reliable one-click bypass, that inconsistency is the central finding.
The score distribution tells a much messier story than the average
An average can hide a lot. A score near 60 sounds respectable until you realize how many texts were nowhere near 60 at all. The chart below shows how the 100 rewrites were distributed across score ranges.
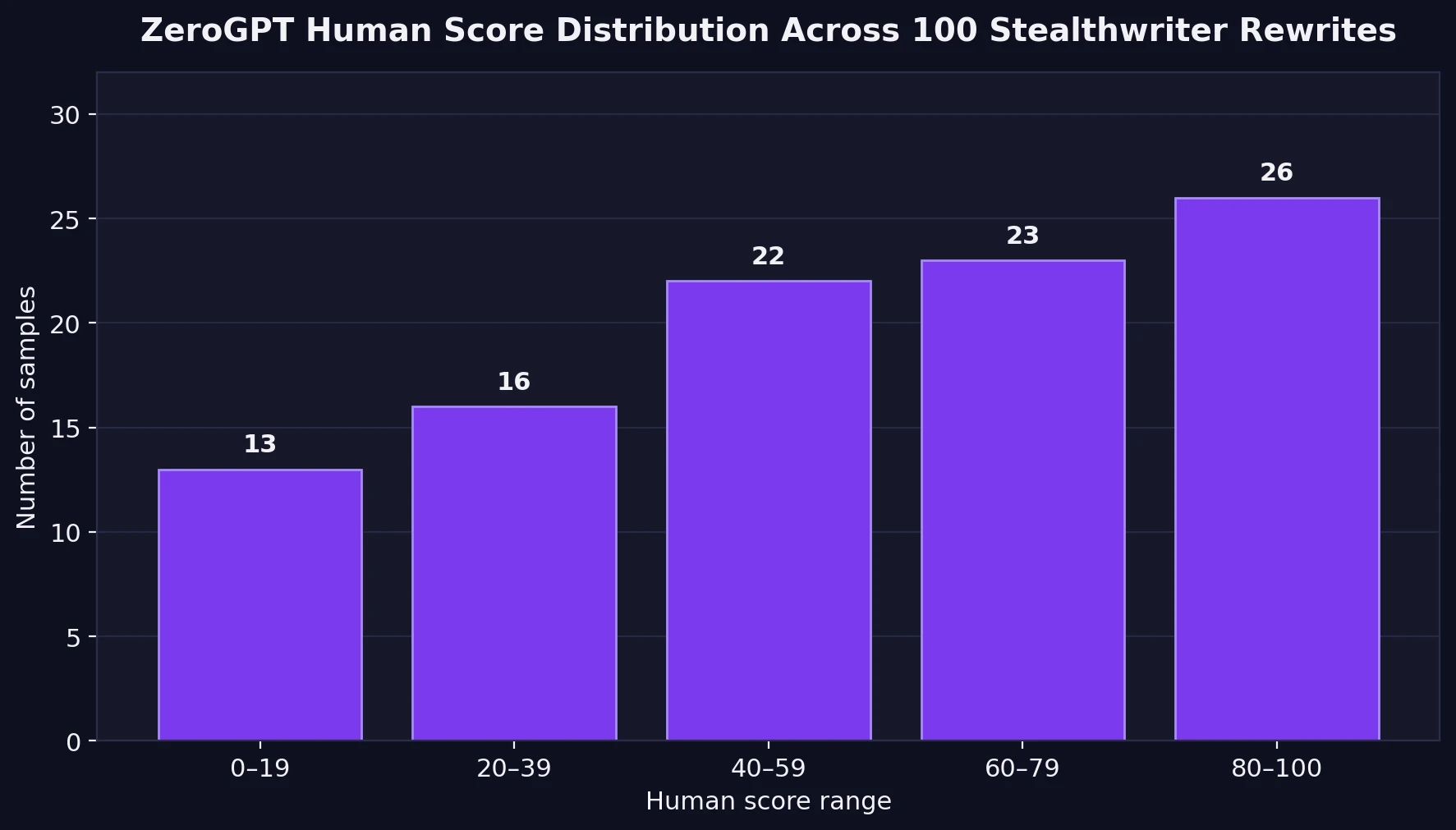
Only 26% of the rewrites landed in the strongest band, 80–100 human. Meanwhile, 29% scored below 40 human, which is a serious warning sign if the goal is to appear convincingly human. The middle of the chart is crowded too, which means many outputs are not outright failures, but they are not especially safe either. They sit in a gray zone where a student could still feel exposed.
How often did the rewrites actually clear useful thresholds?
To make the results easier to read, I also checked how often the rewrites crossed common checkpoints. I used a straightforward interpretation: a 50+ human score is the bare minimum for looking more human than AI, while 80+ is a much more comfortable result.
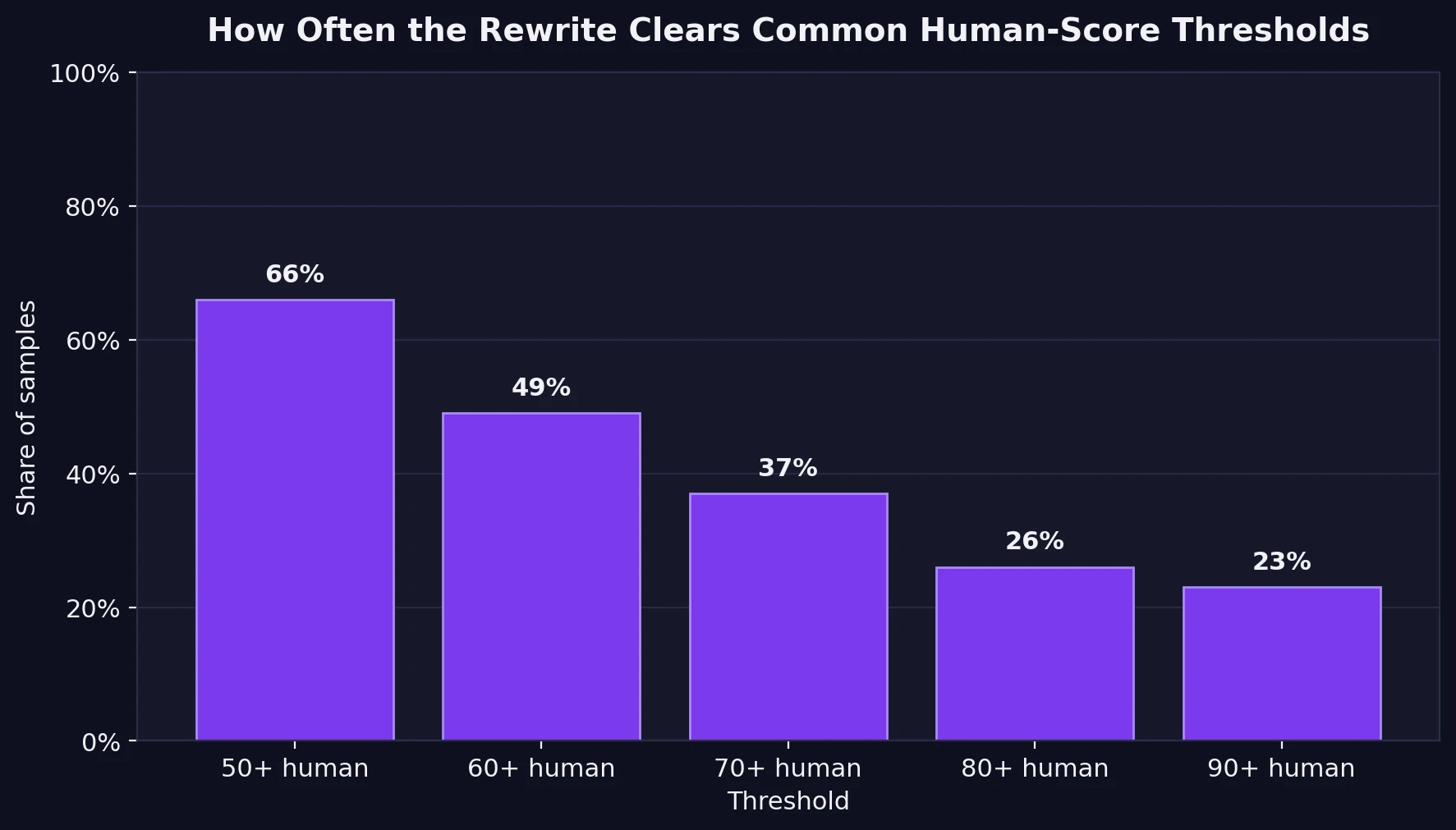
This is where the test stops looking like a clean win. Yes, 66% of the rewrites cleared the 50 mark. But once the standard becomes stricter, the success rate collapses: 49% reached 60+, 37% reached 70+, and only 23% reached 90+. In other words, Stealthwriter can work, but it does not work with the kind of consistency that students usually imagine when they hear the word “bypass.”
Copying less helped. Making the text longer did not.
I also compared each rewrite to its original source text. A simple similarity check showed a negative correlation of -0.45 between overlap and human score. That sounds technical, but the idea is simple: when the rewritten version stayed too close to the original wording, the human score usually dropped.
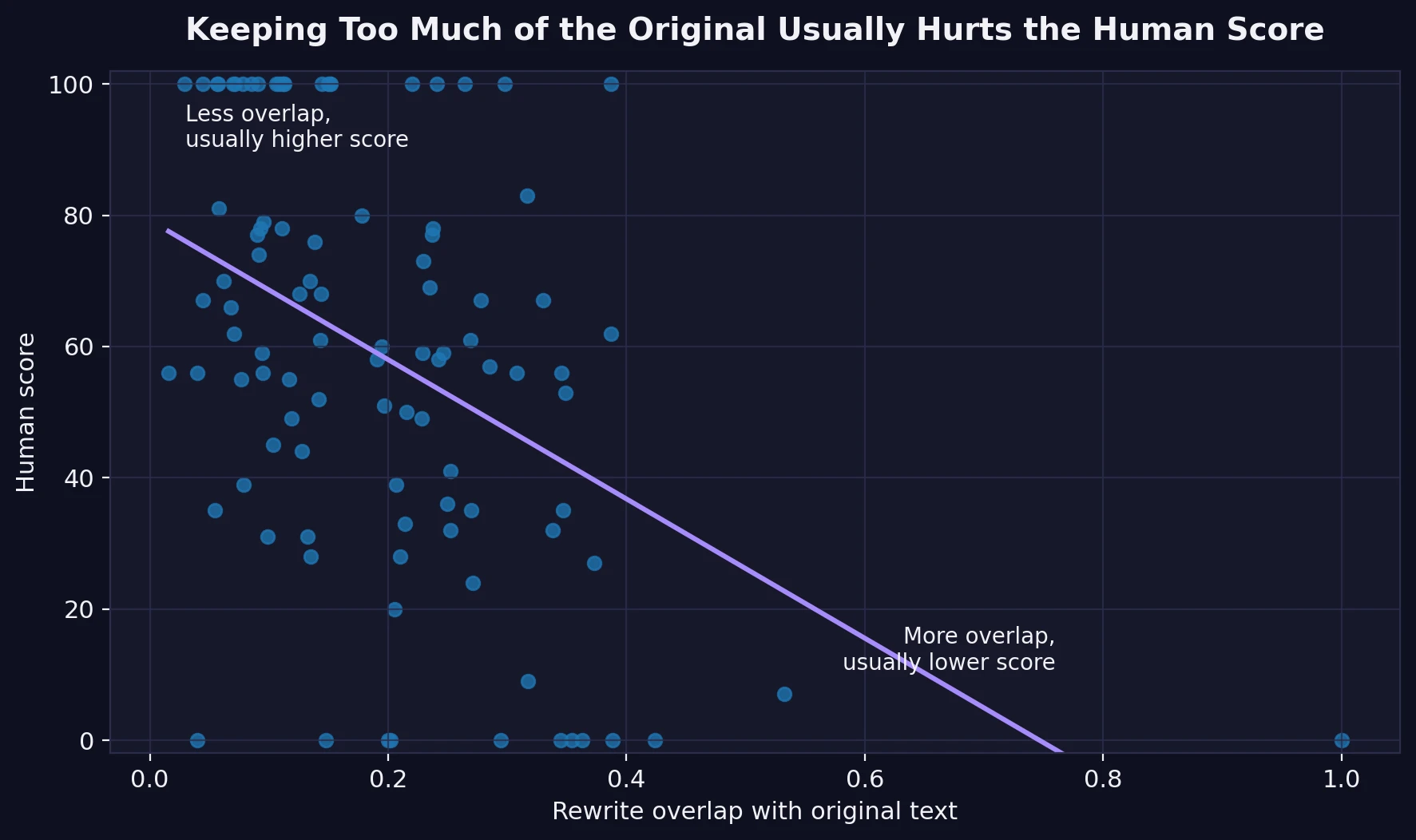
The difference was not small. The 18 most copy-heavy rewrites averaged just 32.6 human. The rest averaged 64.1 human. One chaos-theory sample was effectively copied over almost word for word and scored 0. That is a useful lesson: a humanizer cannot merely shuffle a few words and hope for the best.
At the same time, length alone was not the answer. On average, Stealthwriter made the text about 6.6% longer, but length barely moved with score at all. The relationship between word-count change and human score was weak, with a correlation of just 0.14.
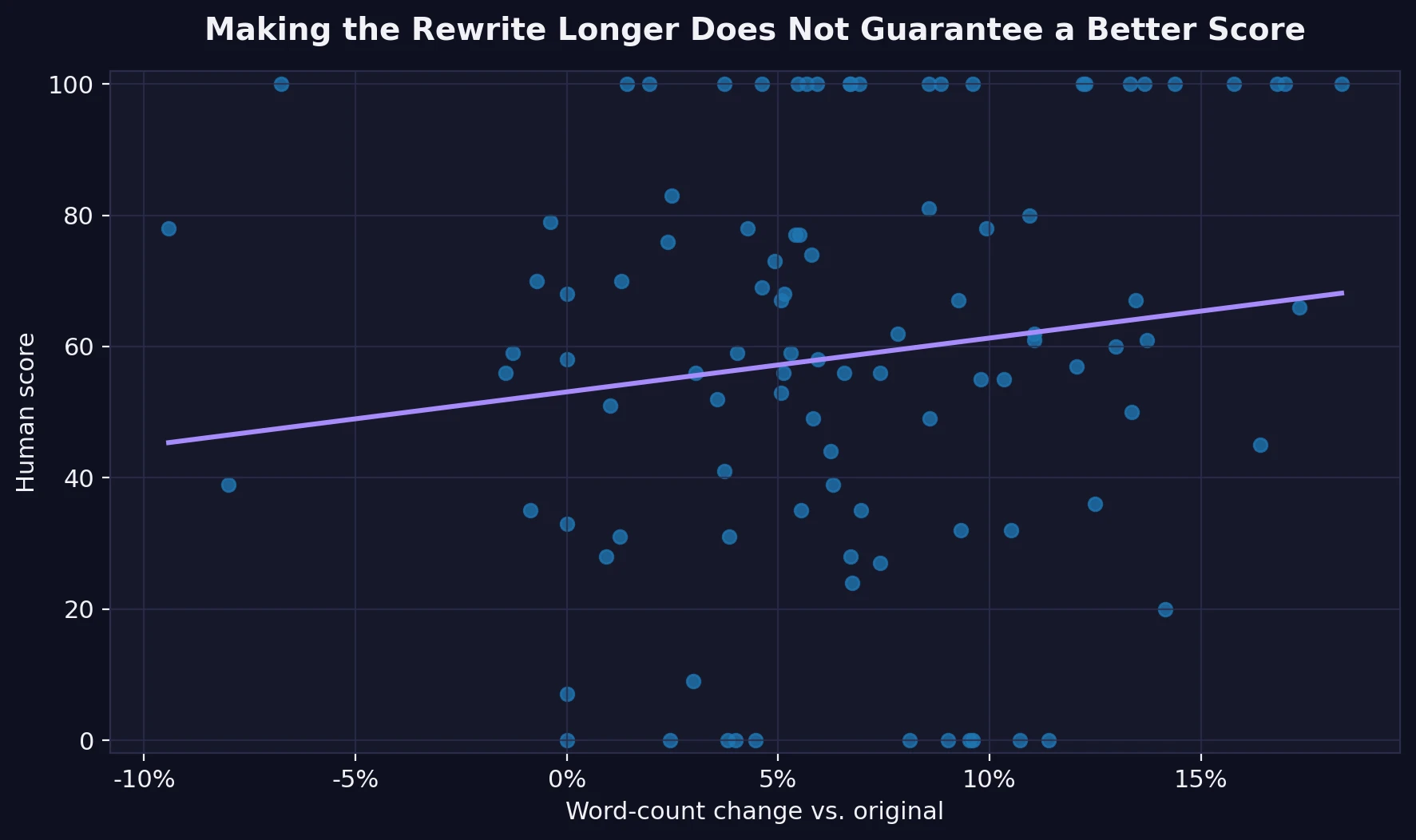
The bigger problem: some rewrites looked worse even when the score improved
This is the part of the dataset that matters most to real readers. I did not just look at the scores. I compared the original and rewritten text side by side, and several recurring problems stood out.
First, some rewrites were not really rewrites. One entry remained almost unchanged and got punished with a 0. That is the clearest failure mode: if the tool barely transforms the source, it is easy for the detector to reject it.
Second, formatting damage showed up in places where clean writing should have been easy. In one breakfast article, the list numbering broke and repeated the number 2. In another sample, Stealthwriter produced split ordinals like 17 th century, 18 th dynasty, and 20 th / 21 st century. These are small details, but they matter. Students know that teachers do notice when writing looks oddly assembled.
Third, the rewrite engine sometimes introduced visible word corruption. Examples in the CSV included fragments such as fast fons, Obsel the vegetables, sound-proofing md, consiat, and sharpiredients. These are not subtle style changes. They are obvious text glitches.
Fourth, meaning drift appeared in a few samples. A mythology passage changed Chang’e into Changyu. A tool-use example shifted forming wood into bend wood. A coffee recipe ended with the odd phrase coffee snack. None of these errors completely destroys the passage, but they show the hidden price of automatic rewriting: the output may pass a detector while becoming less accurate or less natural.
This is why a detector score should never be confused with writing quality. In fact, some of the 100-human outputs still contained clunky or damaged phrasing. A perfect detector score is not the same thing as a polished paragraph.
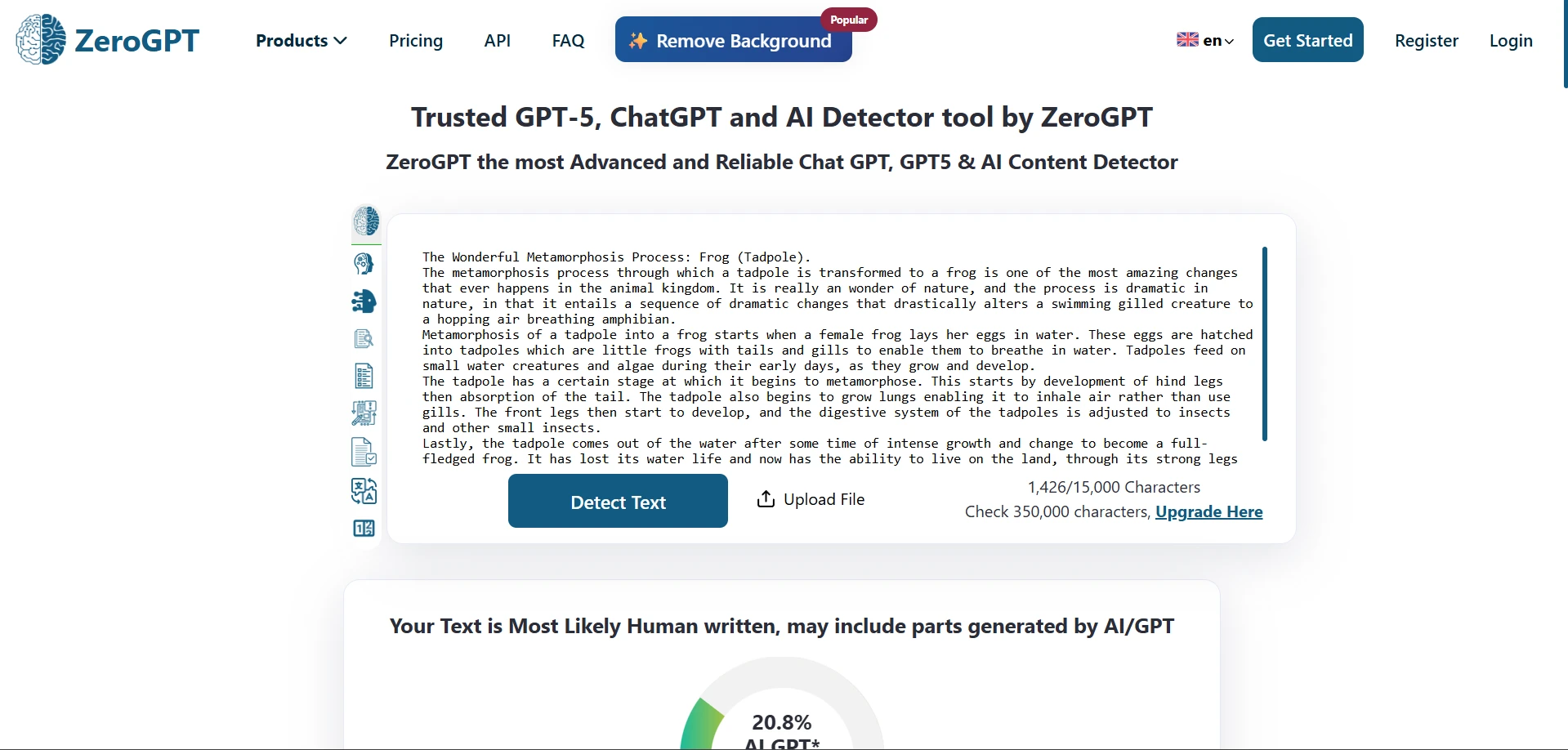
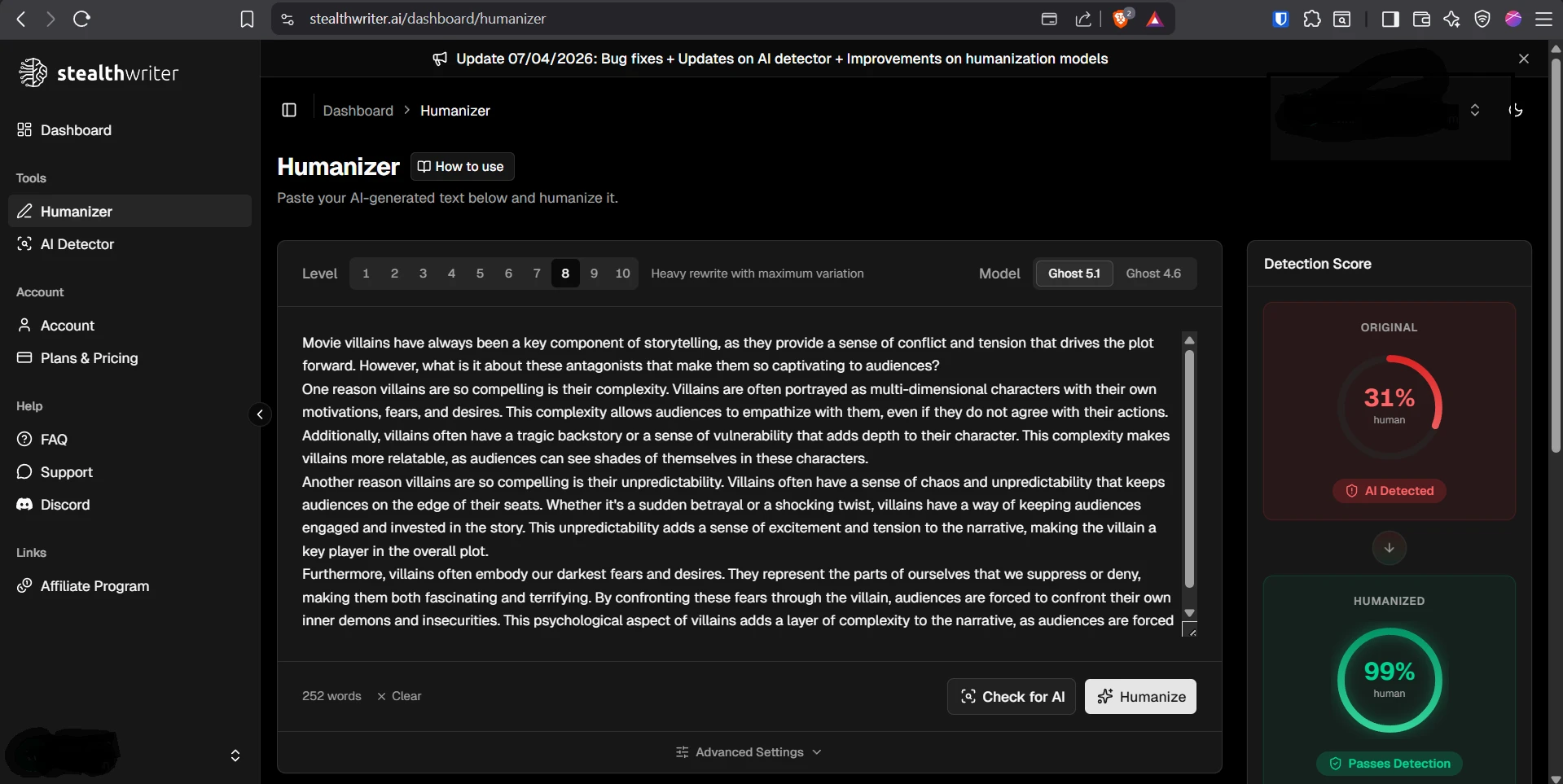
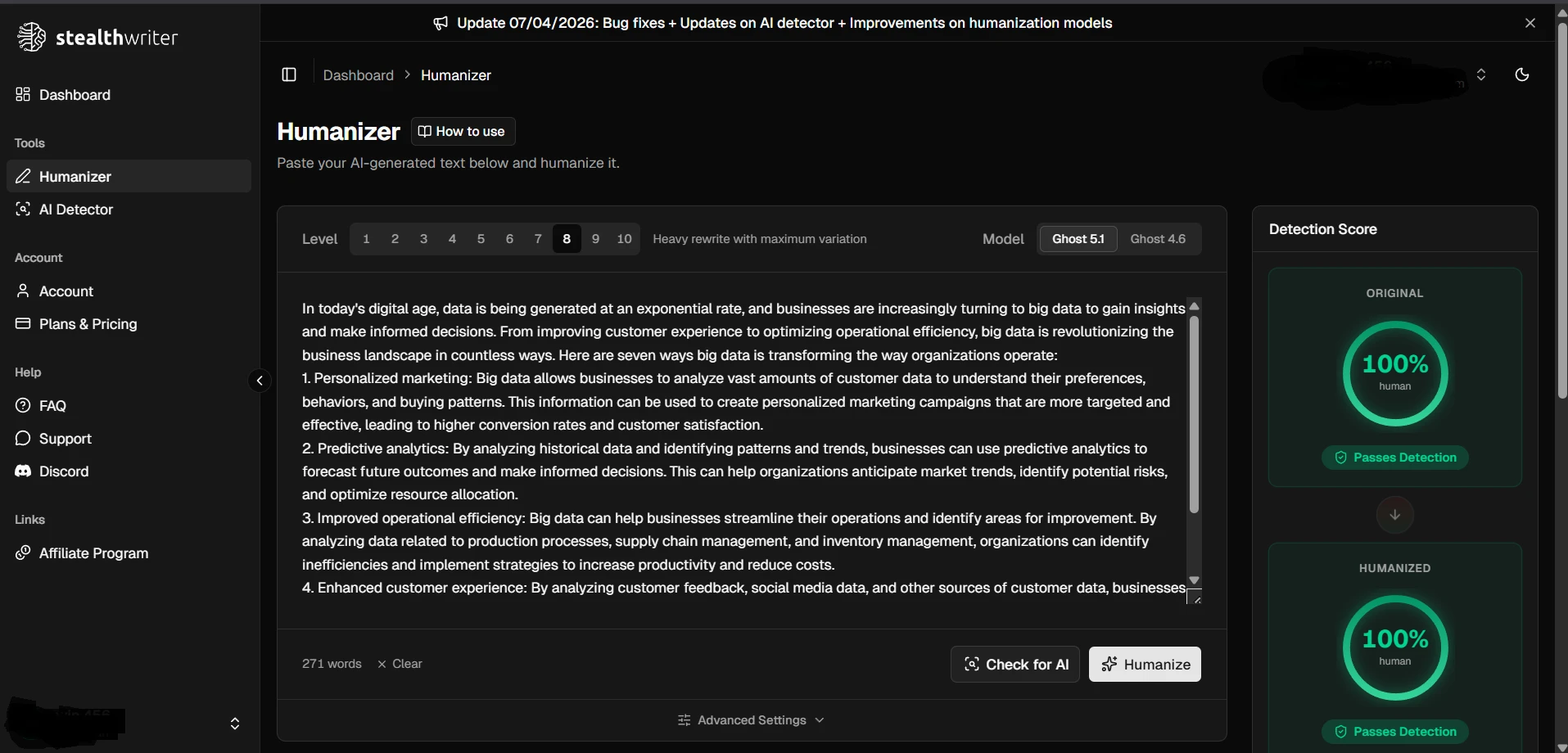
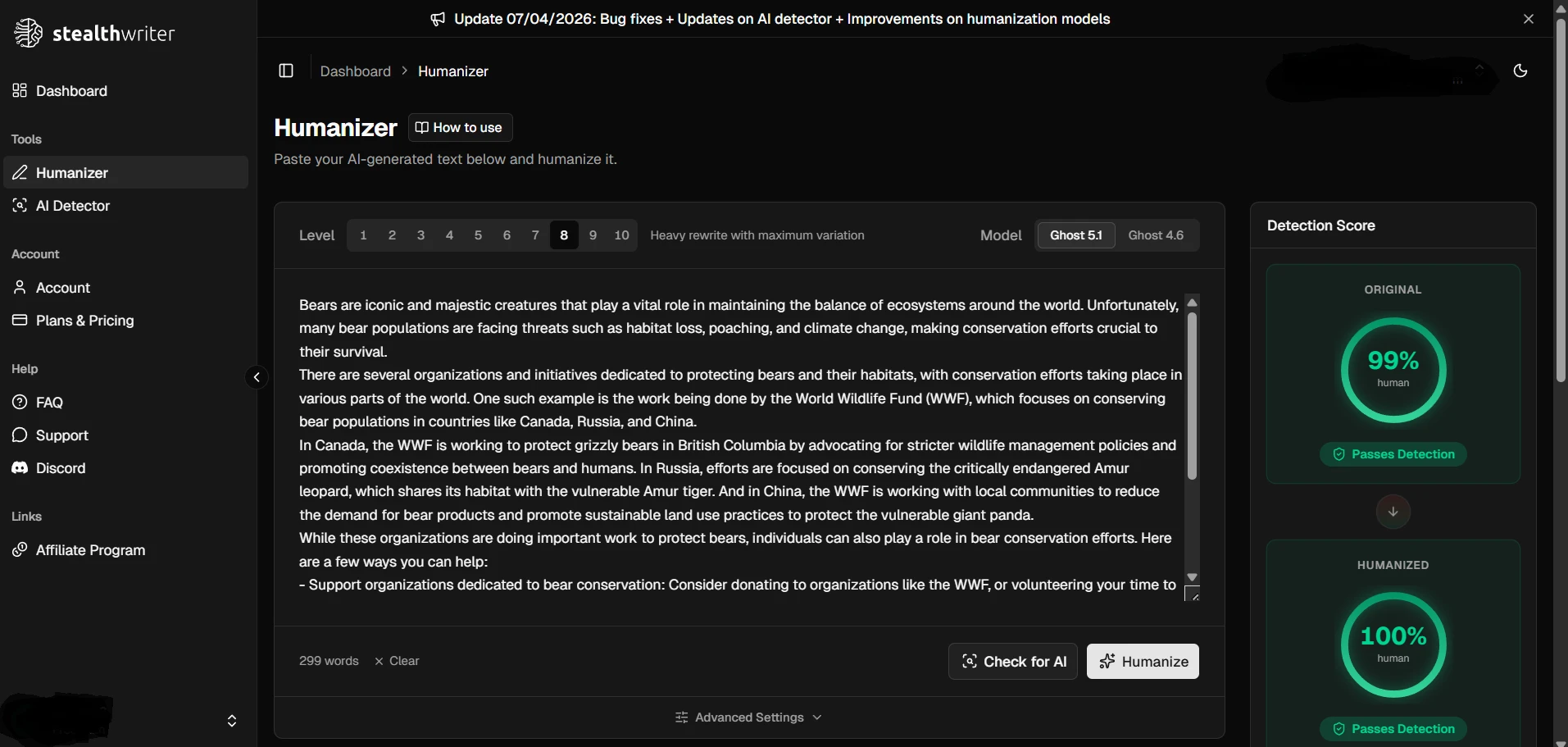
What the screenshots show
The screenshots below give a feel for how these results looked in practice. The first set shows ZeroGPT outcomes from the testing workflow, and the second set shows Stealthwriter’s humanizer interface working on sample passages.
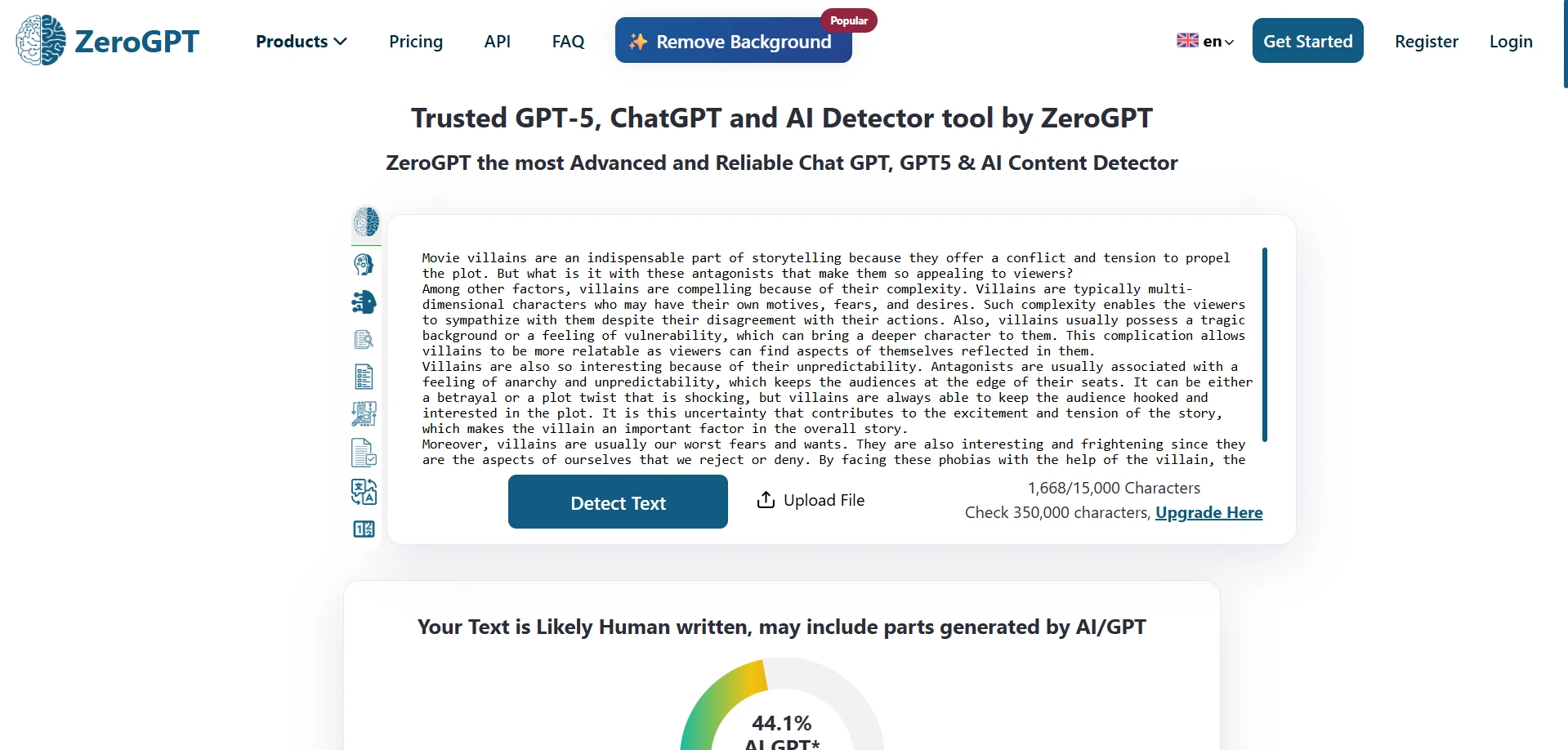
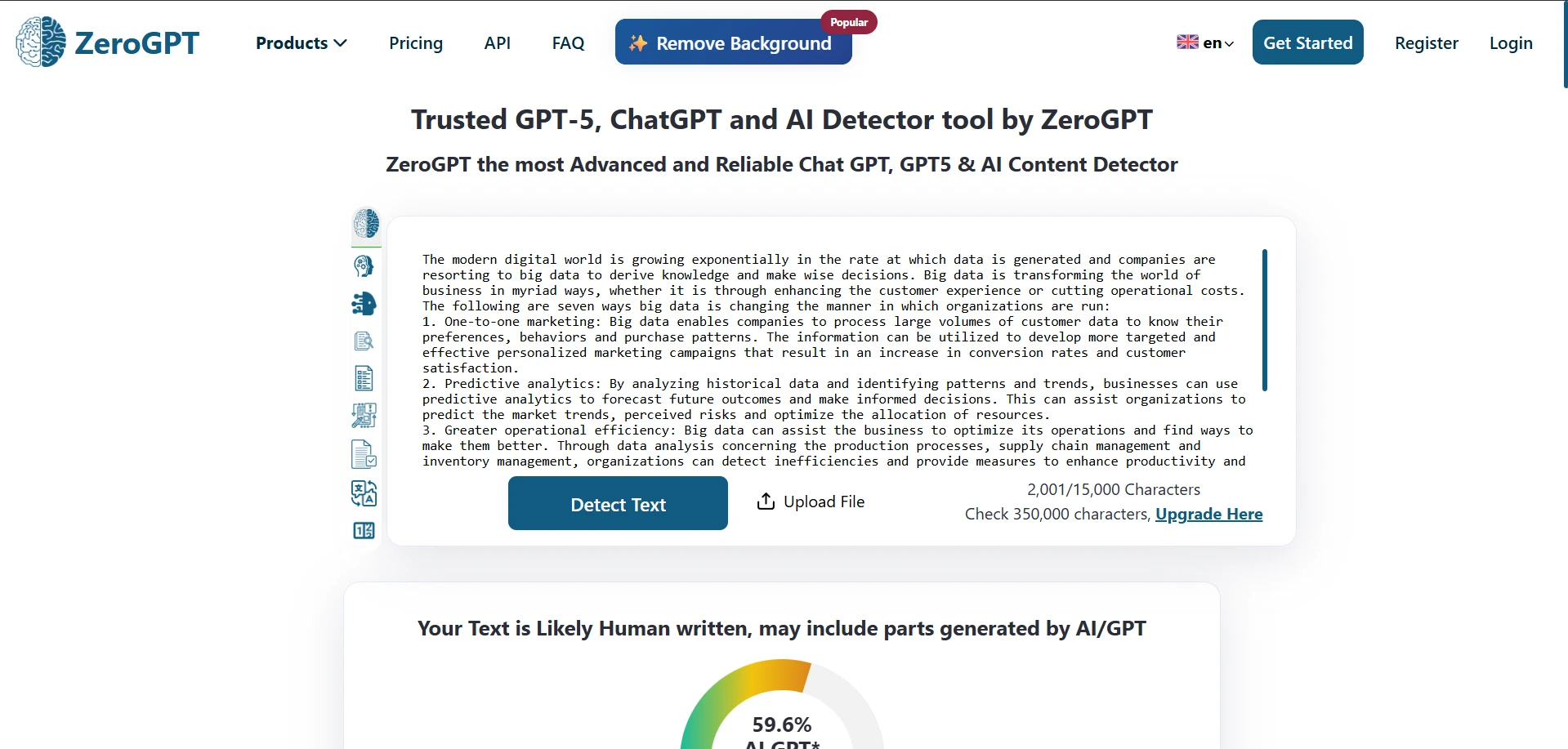
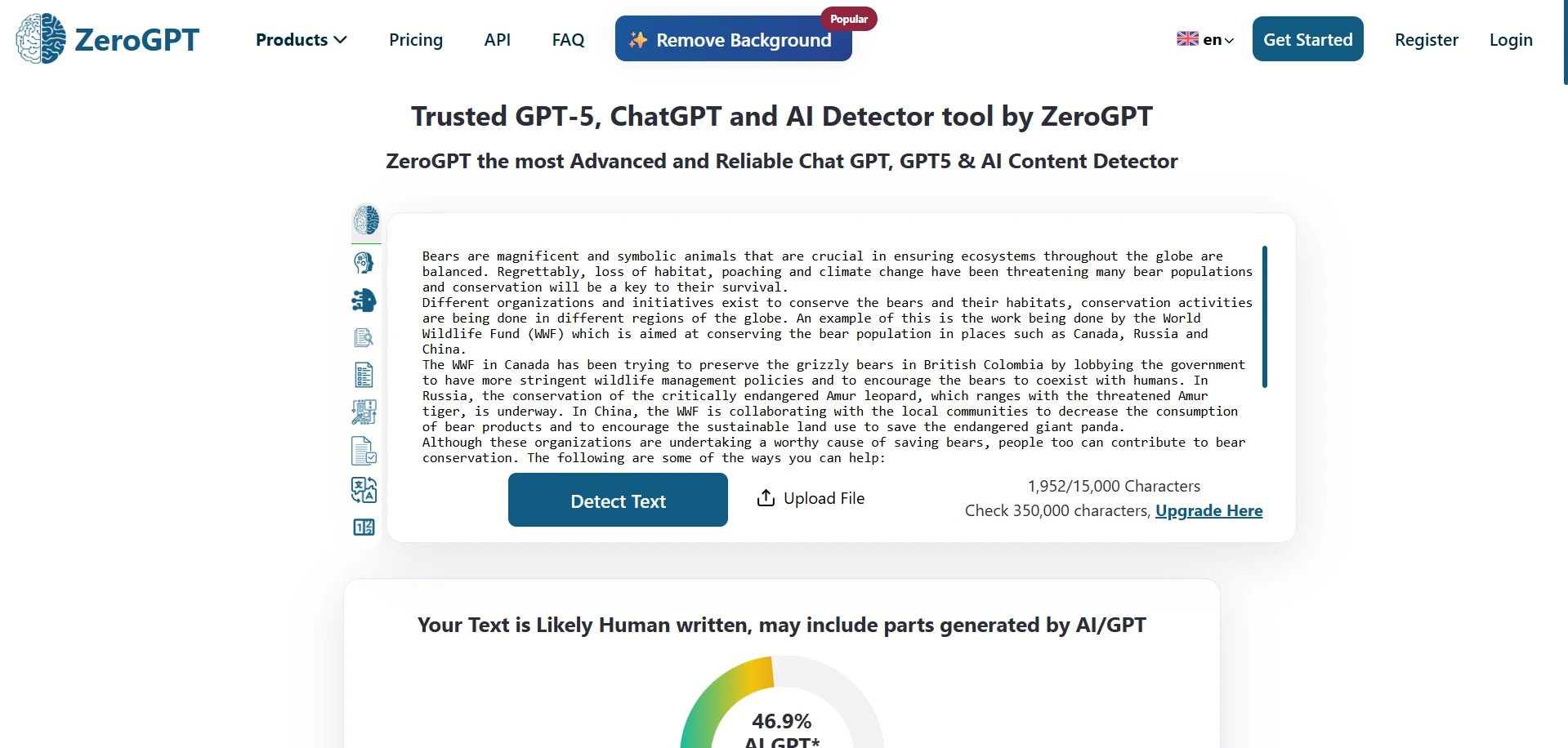
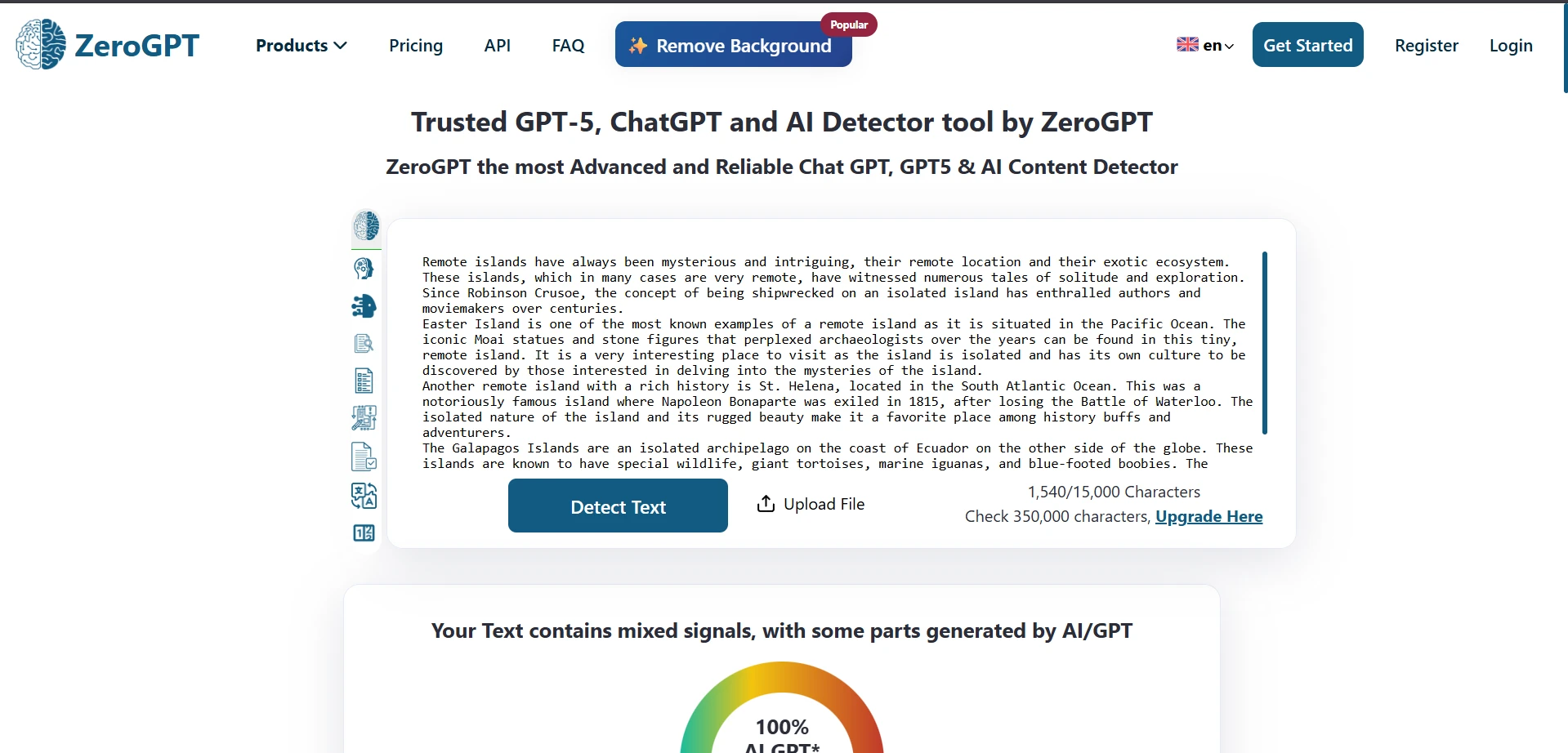
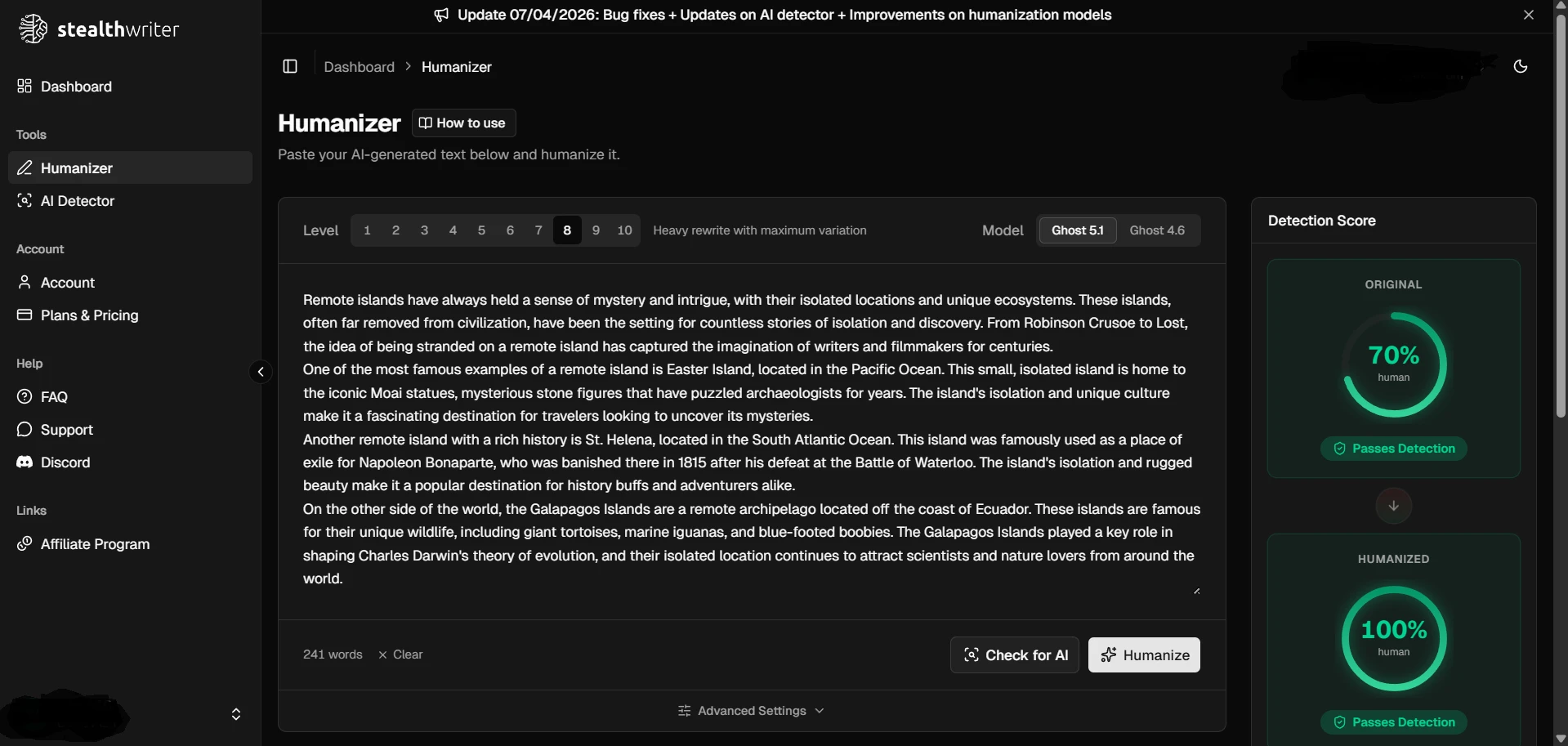
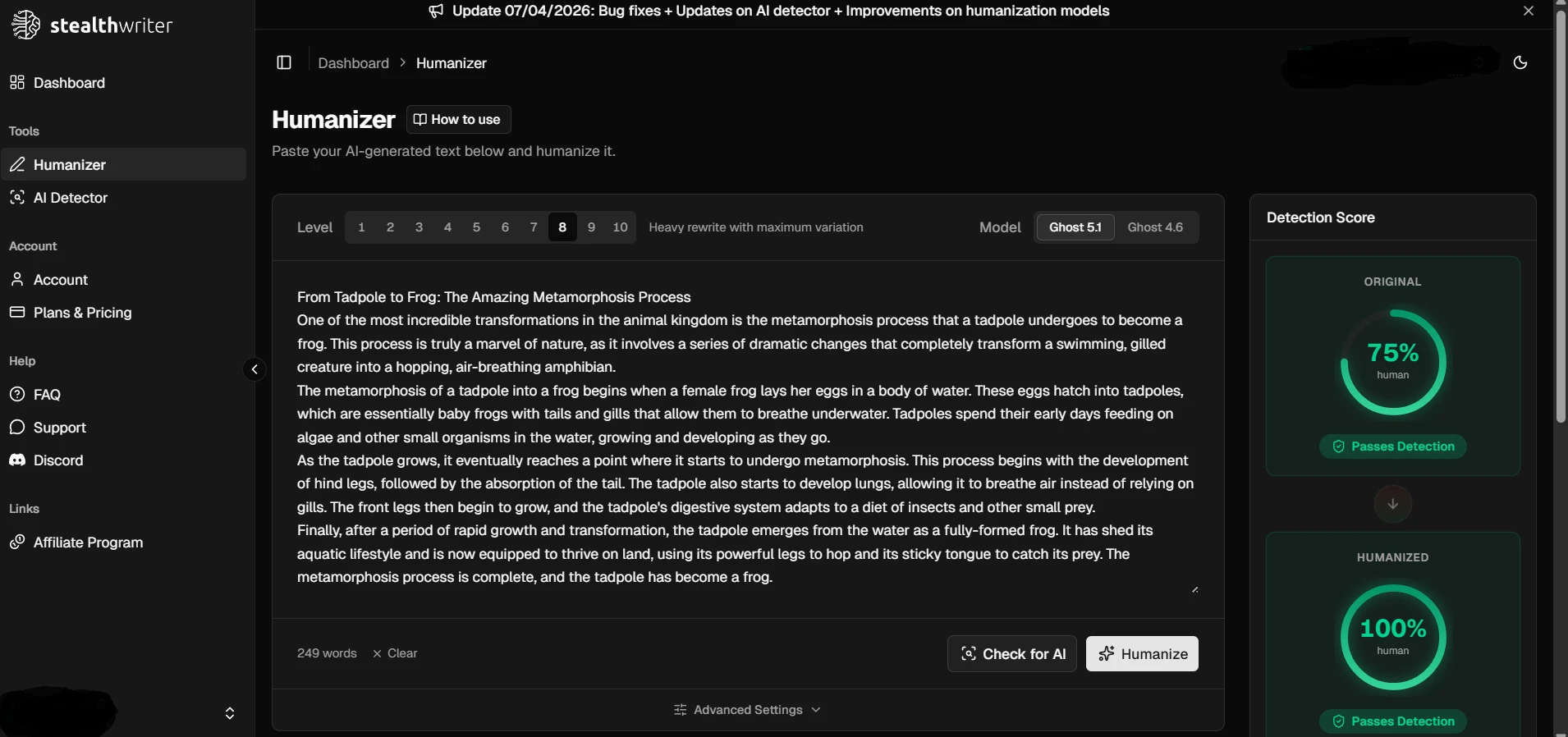
The final takeaway
Stealthwriter can bypass ZeroGPT sometimes. The 100-sample dataset makes that clear. But it does not do so in a smooth, dependable way. The average result was only moderate, the spread was huge, and the strongest scores were mixed with complete failures.
For students, the bigger lesson is even more important: passing detection is not the same as producing good writing. Some outputs in this test looked more human to ZeroGPT while still carrying broken formatting, strange wording, or small factual slips. That means the tool may lower one kind of risk while raising another.
If your goal is a clean, believable piece of writing, the safest approach is still the least glamorous one: use tools carefully, then revise like a human. Detector-friendly text without clarity, accuracy, and flow is not really a win. It is just a different kind of problem.