![[STUDY] Can Stealthwriter Outsmart GPTZero? A 100-Sample Test](/static/images/stealthwriter-vs-gptzero-featured-imagepng.webp)

Students are constantly sold a tempting shortcut: run AI text through a humanizer, press a button, and watch it glide past AI detection. That promise sounds simple. The data here does not. I tested 100 Stealthwriter rewrites against GPTZero and converted GPTZero’s AI score into a human score, where a higher number means the text looked more human. What emerged was not a clean win, and not a total collapse either. It was a split result with one big lesson: detector scores and writing quality are not the same thing.
How this test was set up
The dataset used in this analysis contains 100 pairs of texts: an original passage and a Stealthwriter rewrite. Each rewrite was then scored by GPTZero. Because detectors usually report the chance that a text is AI-written, I flipped that logic into a human score. In this article, 100% means GPTZero thought the text looked fully human, while 0% means GPTZero treated it as fully AI-like.
This matters because averages alone can be misleading. A tool can look decent on paper if a few strong wins hide a large number of complete failures. That is exactly why the full distribution matters more than a single headline number.
Also Read: [STUDY] Can Stealthwriter really slip past Originality.ai? I tested 100 rewrites to find out.
Quick takeaways from the 100-sample dataset
- The average human score was 47.2%, but the median was only 37%.
- 35 samples landed below 10% human, including 33 that hit a flat 0%.
- Only 47 out of 100 rewrites crossed the 50% human mark.
- Just 32 reached 90% human or better, and only 26 cleared 95%.
The average score hides the real story
At first glance, an average of 47.2% human might sound passable. But the shape of the results tells a more dramatic story. The dataset is bimodal—a statistics word that simply means the scores pile up near both ends instead of clustering in the middle. In plain English, Stealthwriter was often either doing very well or failing very obviously, with not much stable middle ground.
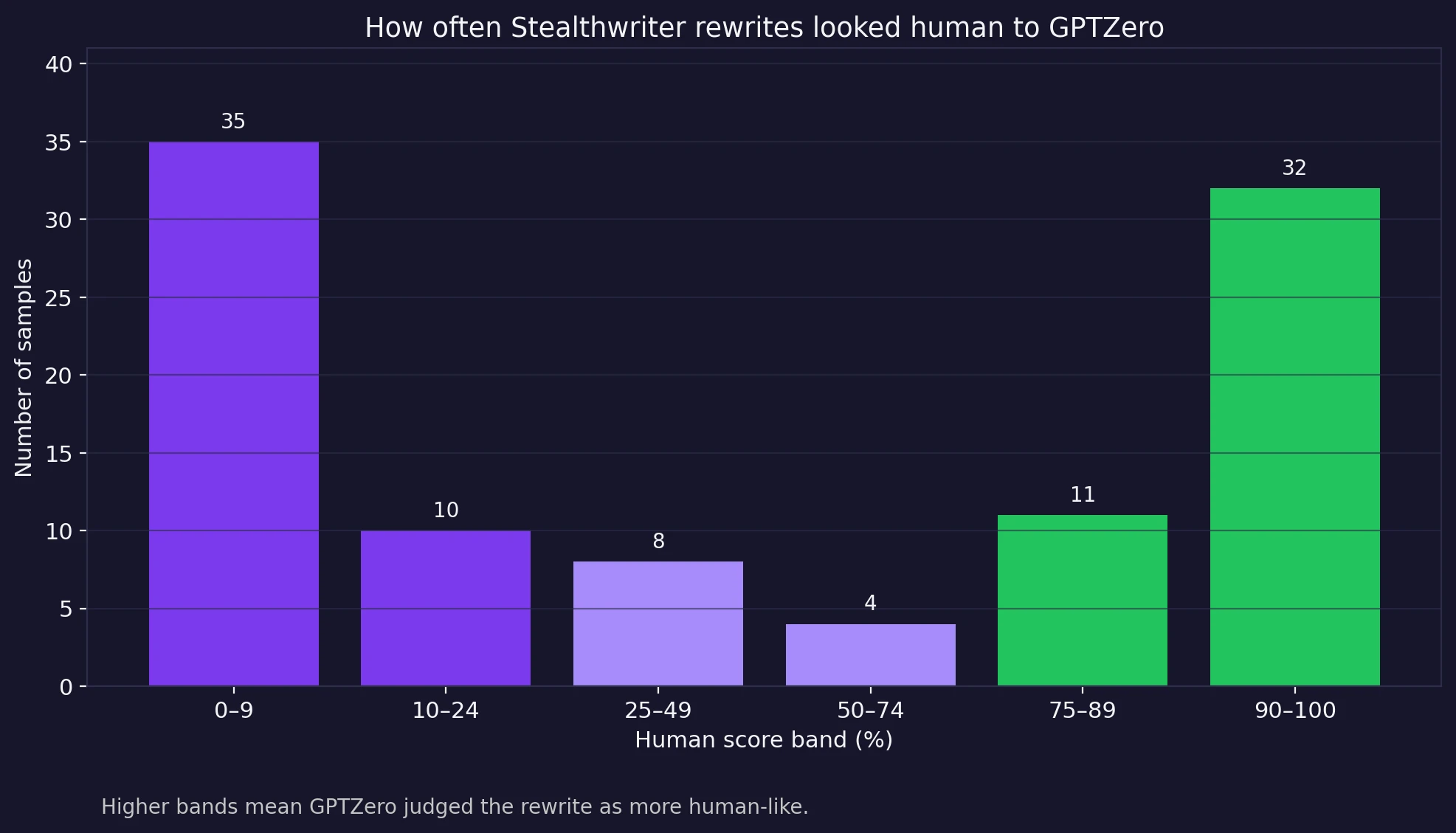
That split matters for students because consistency is the whole point of using a humanizer. If you submit ten rewritten passages, you do not want three or four of them sounding fine while the rest collapse under a detector. A tool that works brilliantly some of the time but crashes hard the rest of the time is not dependable. It is a gamble.
Also Read: Stealthwriter vs ZeroGPT: I Tested 100 Rewrites, and the Results Were Complicated!
Raise the bar, and the pass rate drops fast
The next chart shows something even more practical. I looked at how many samples would “pass” depending on how strict you want to be. If your standard is merely scraping above 50% human, Stealthwriter gets 47% of the samples there. But the moment you ask for a truly convincing result, the picture changes. At a 90% human threshold, the pass rate drops to 32%. At 95%, it falls again to 26%.
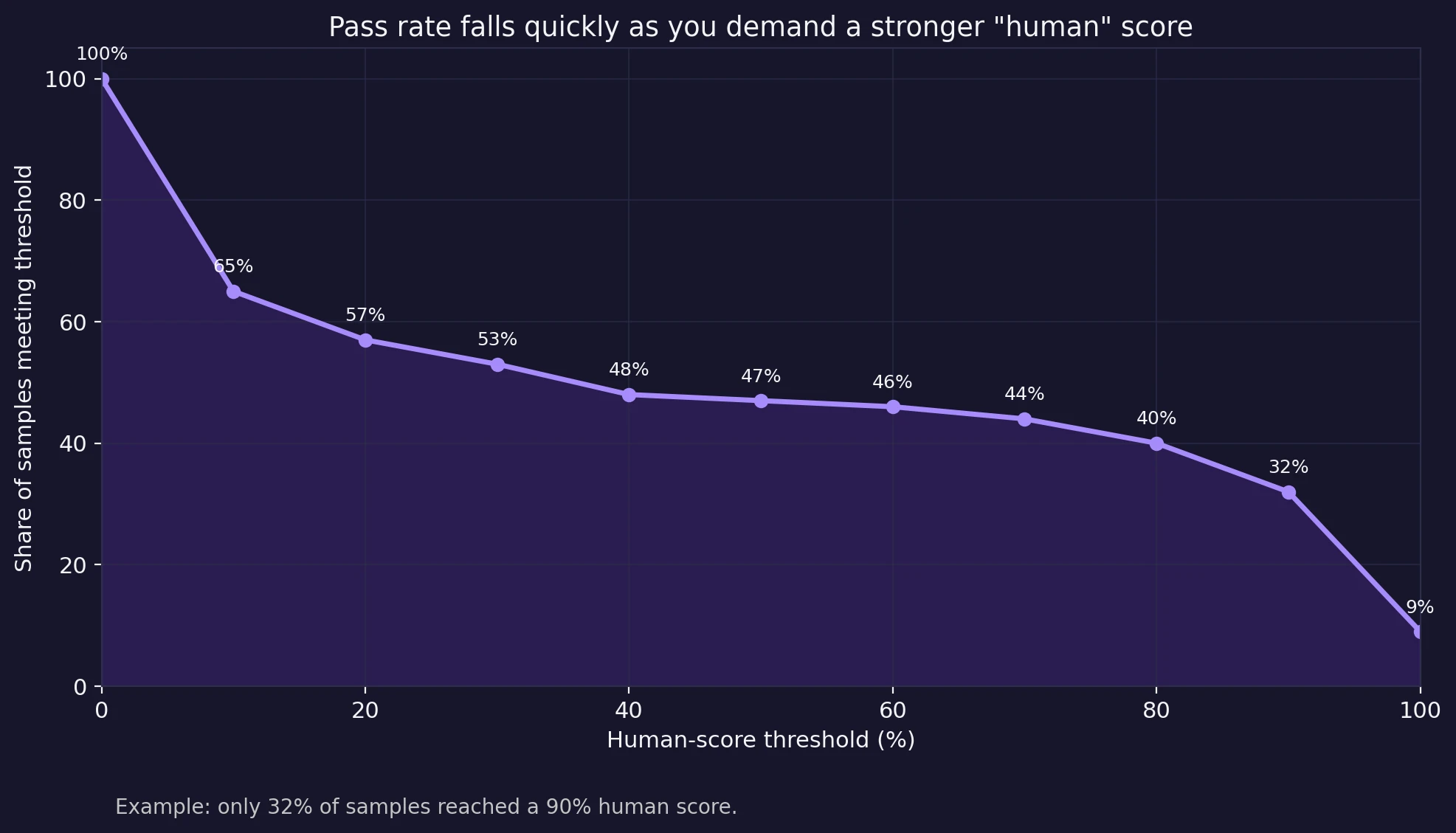
That is the difference between occasionally fooling a detector and reliably looking human. For a student trying to lower risk, that gap is huge. A weak pass is not the same as a strong pass, especially when an instructor might also notice awkward wording on top of whatever the detector says.
Longer rewrites were harder to sell
One more pattern stood out in the CSV: length. When I grouped the rewrites by word count, the shorter half of the dataset performed much better than the longer half. The shortest quartile averaged about 55.6% human. The next quartile did even better at 59.3%. But the longer half dropped sharply to 38.0% and 35.7%.
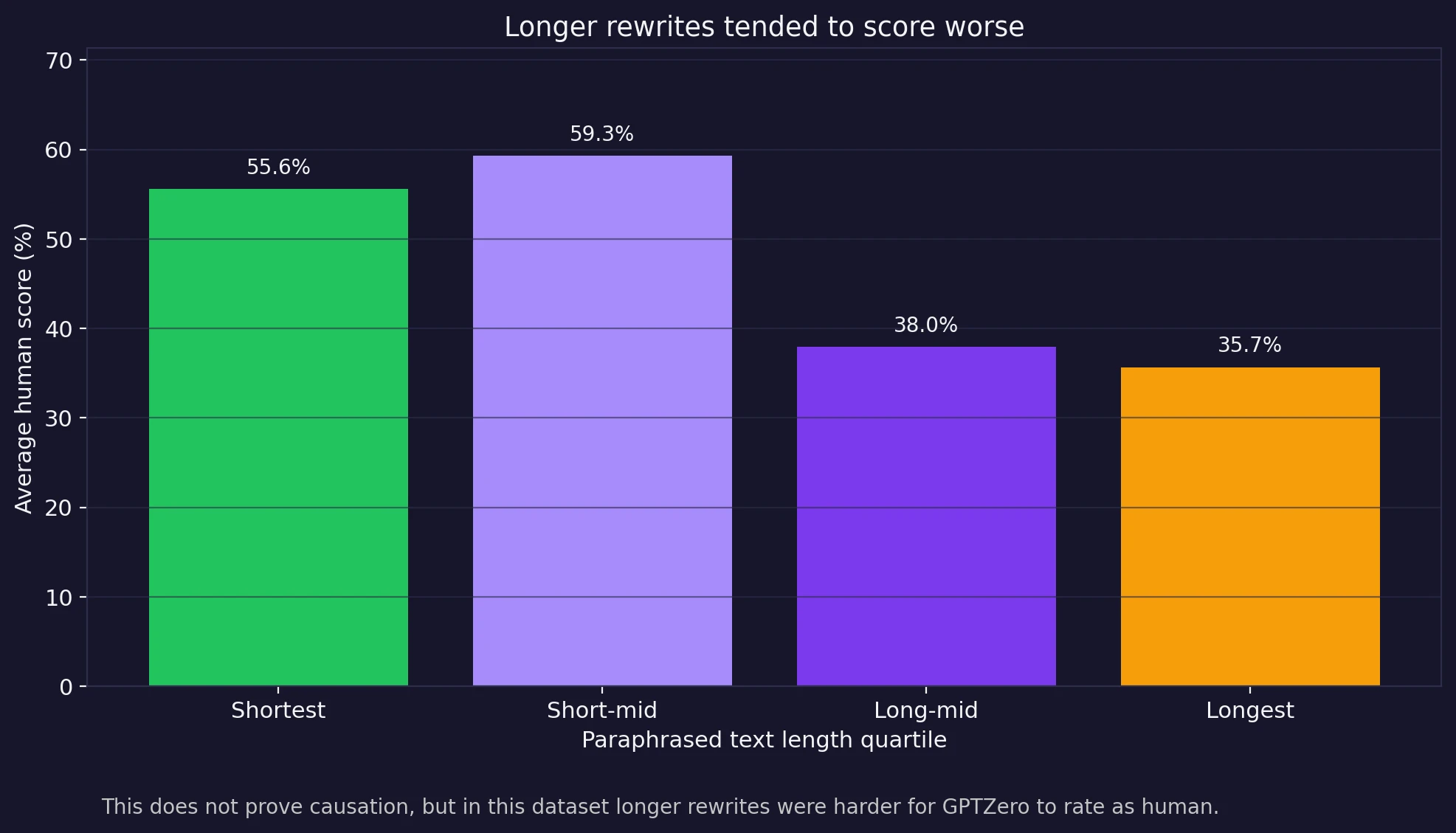
This does not prove that length itself causes failure. But it does suggest that as Stealthwriter has more text to rewrite, it also has more chances to leave behind strange phrasing, robotic rhythm, or formatting mistakes. In other words, a longer passage gives the system more room to slip.
The screenshots tell an even sharper story
The screenshots included with this test are especially revealing. In several case studies, Stealthwriter’s own interface marked the rewritten version as highly human, while GPTZero still treated the same kind of output as AI-like. In the CSV, the visible examples on movie villains, big data, bear conservation, remote islands, and frog metamorphosis all landed at 0% human after conversion. That gap is hard to ignore.
Stealthwriter’s own self-confidence
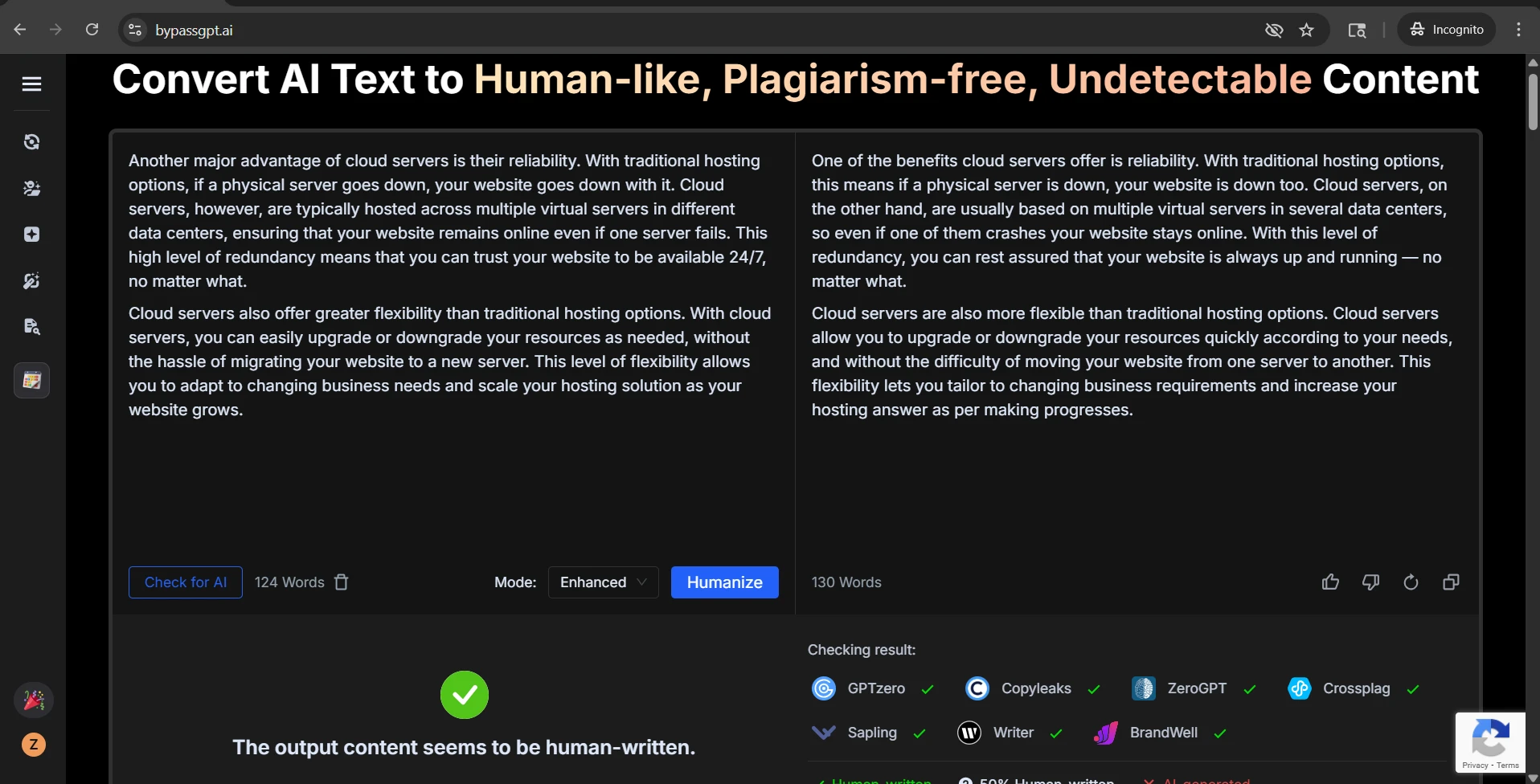
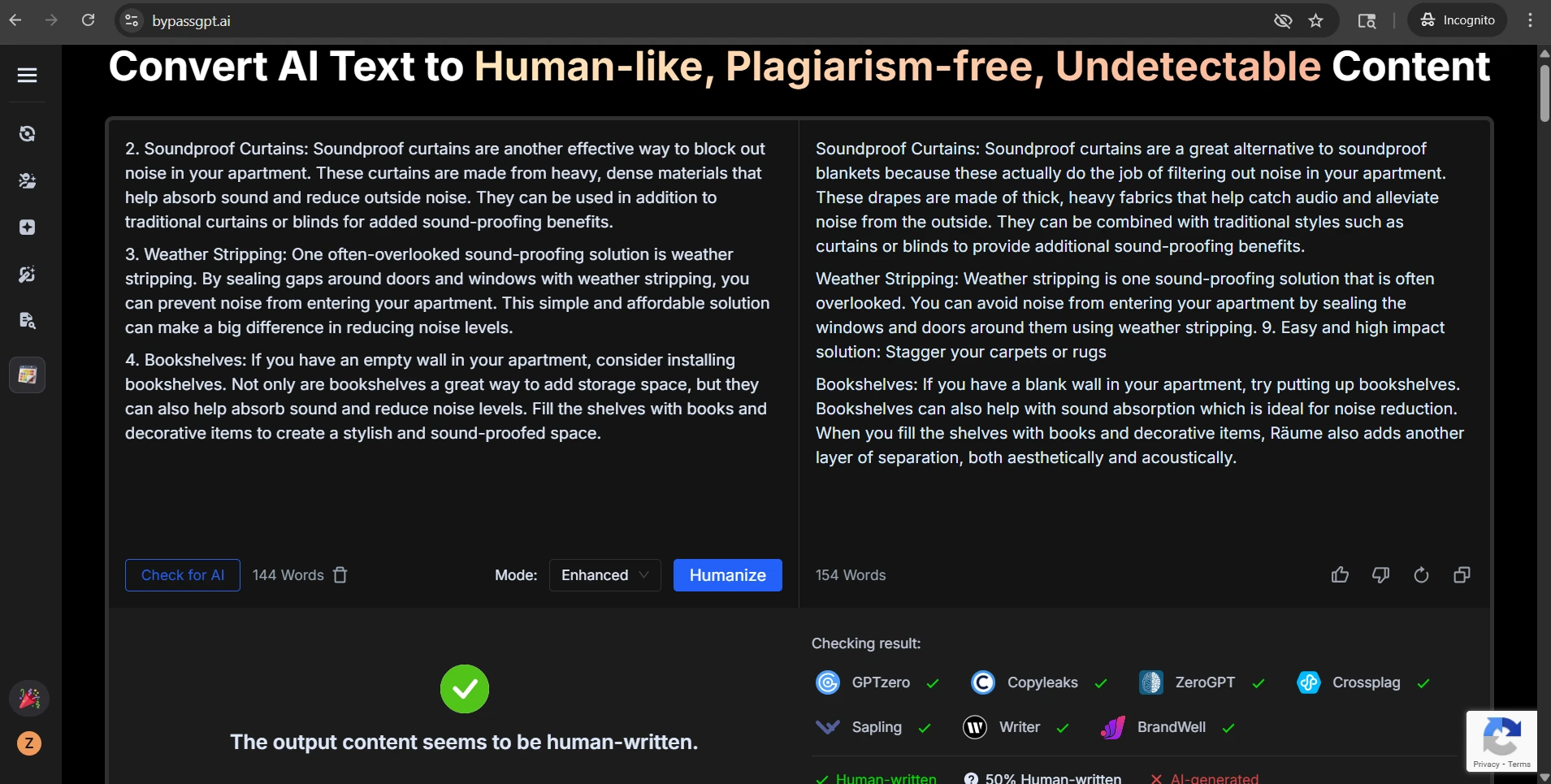
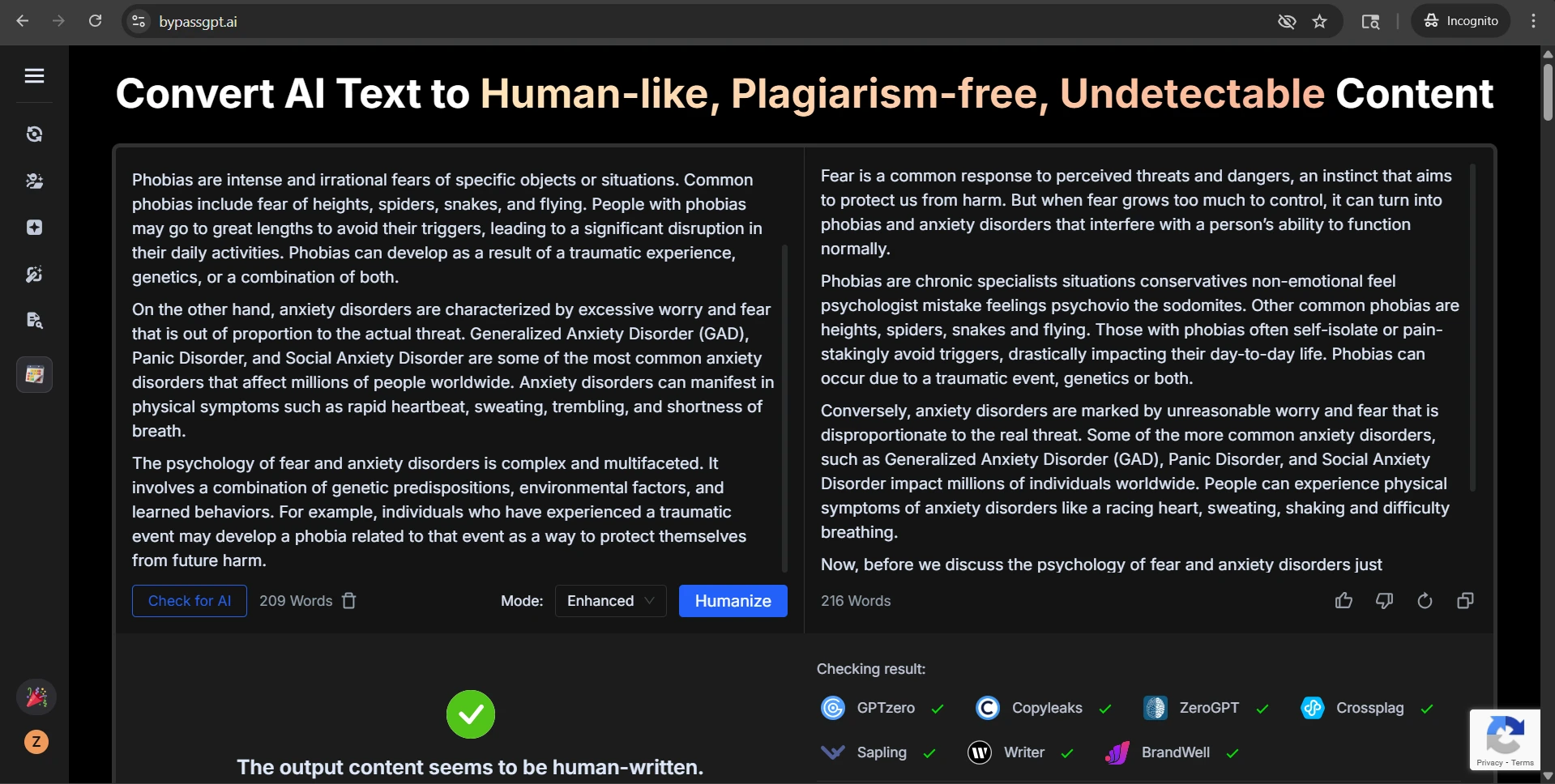
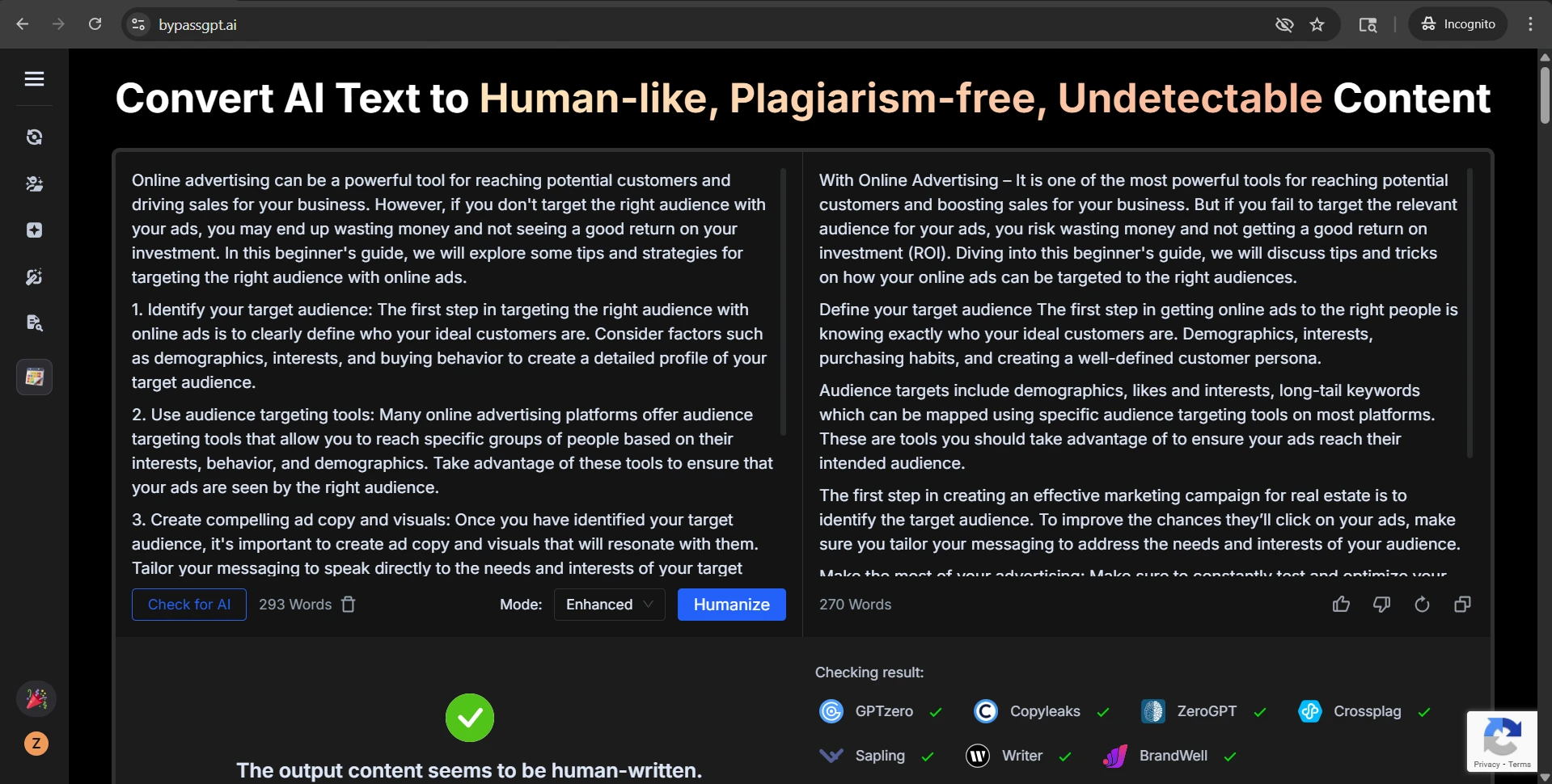
GPTZero’s reaction to the same kind of output
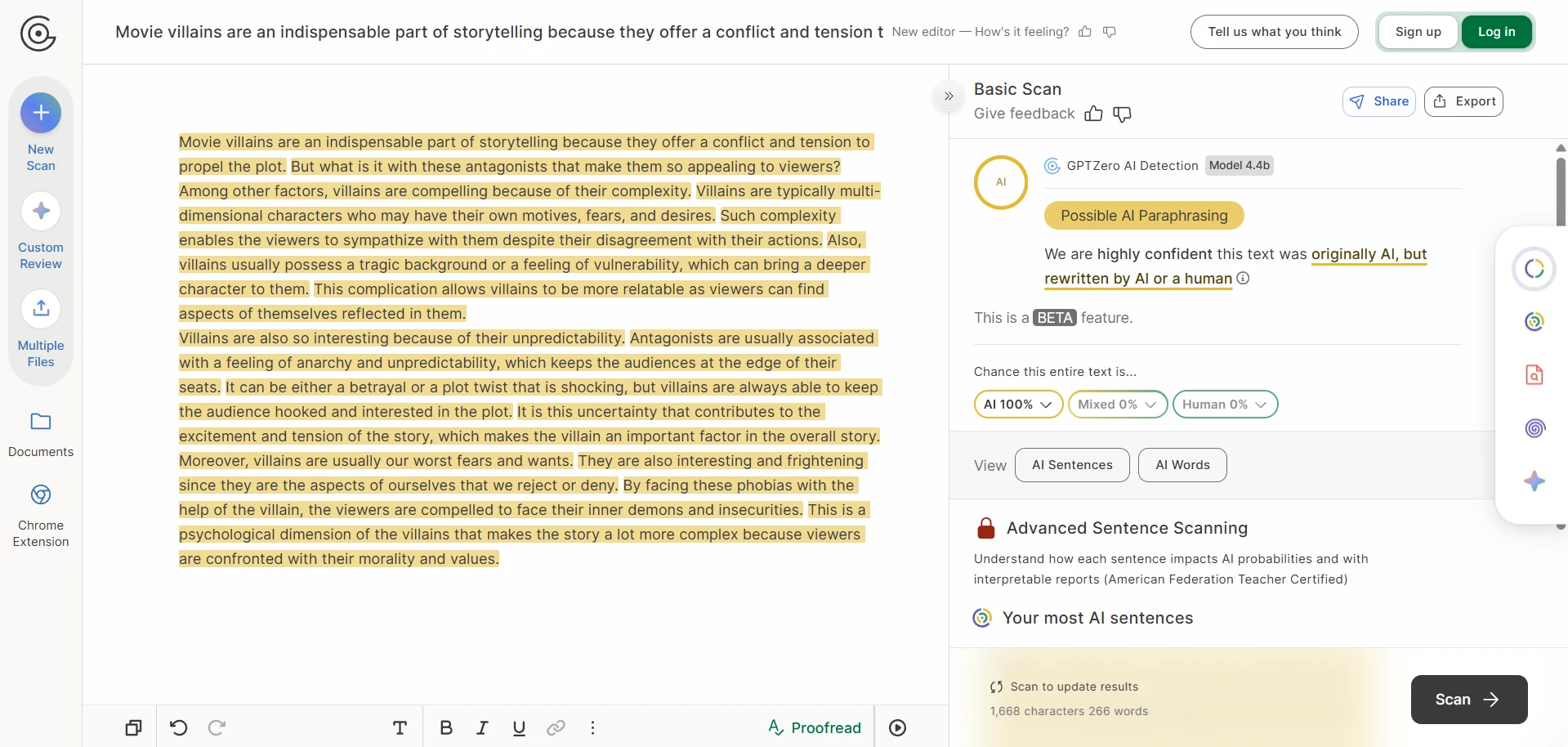
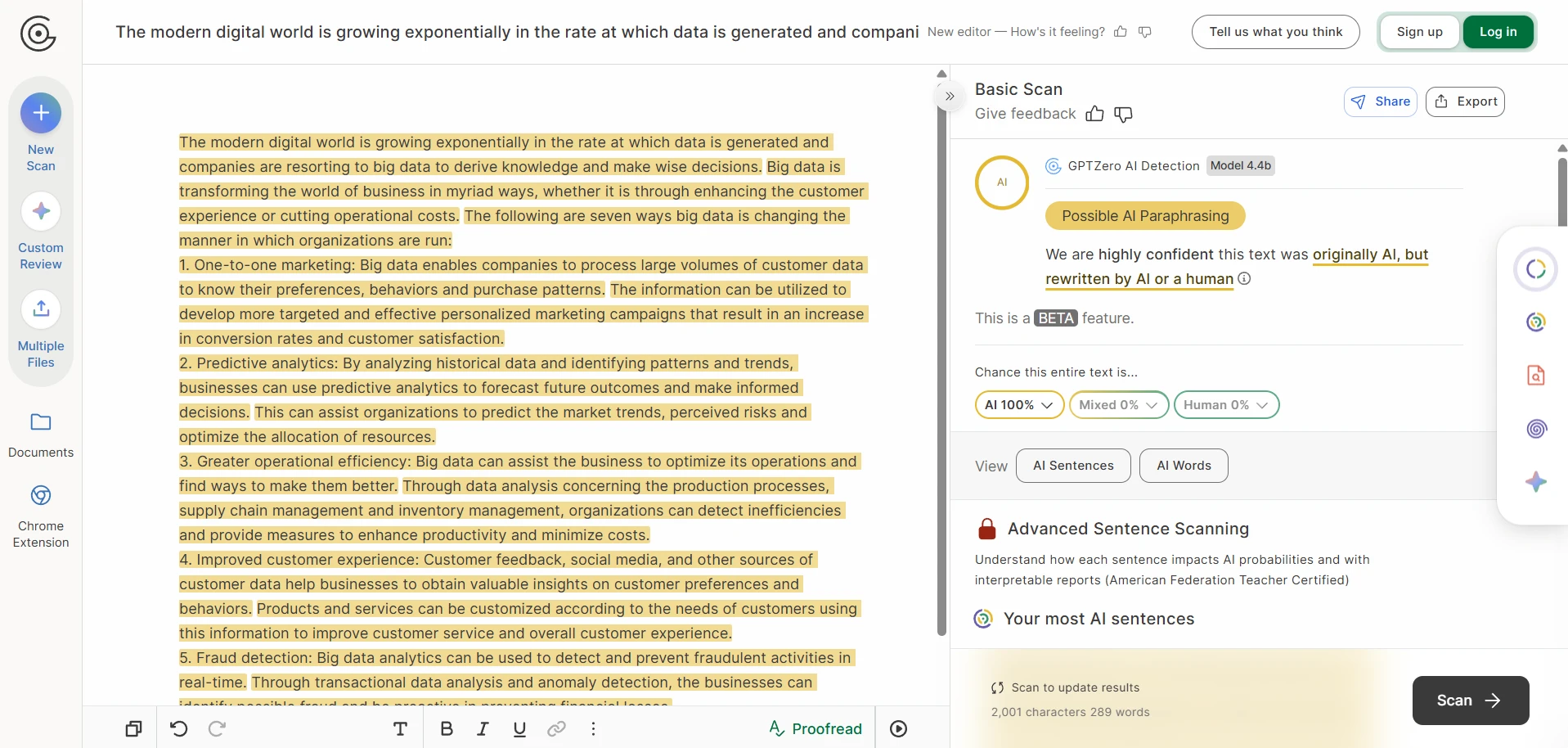
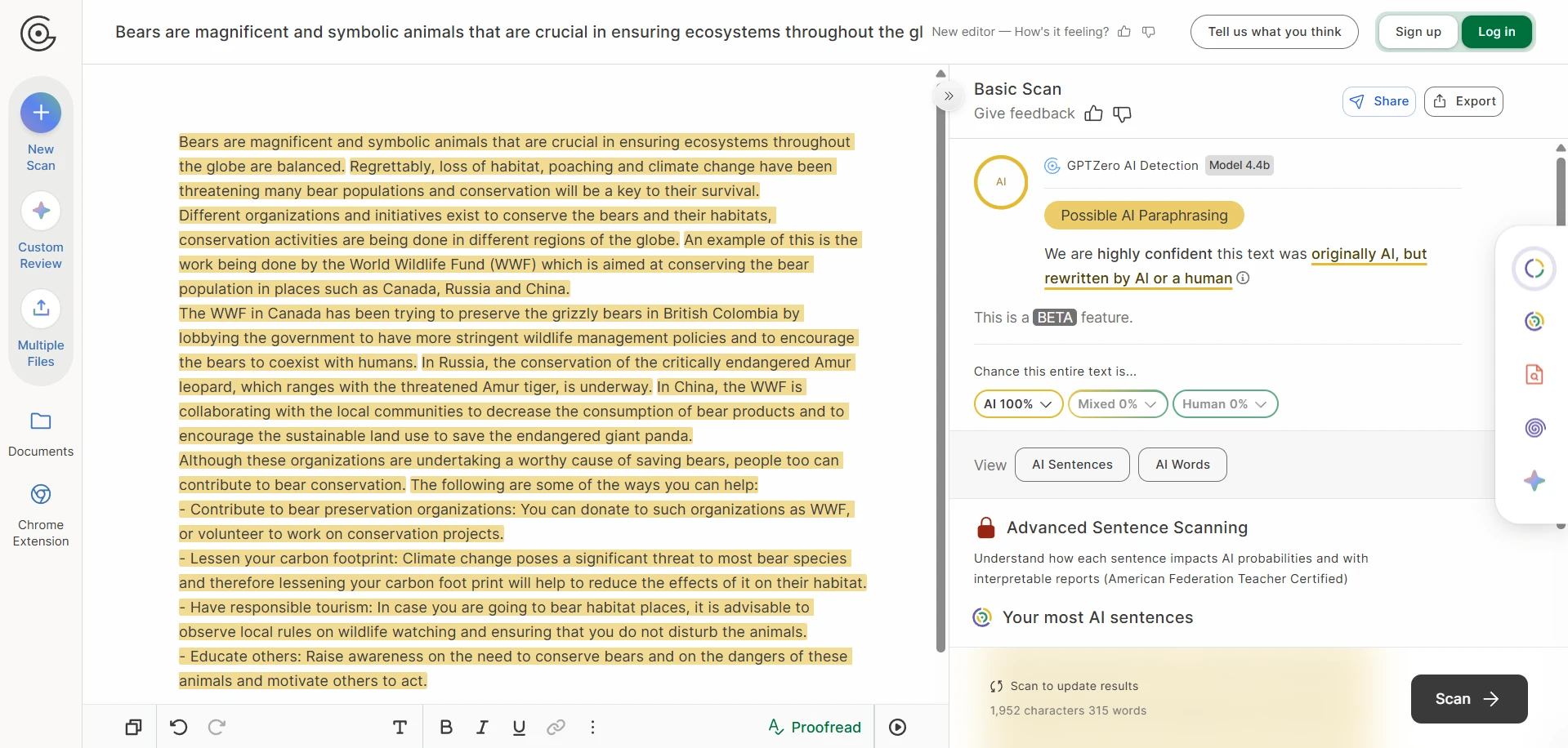
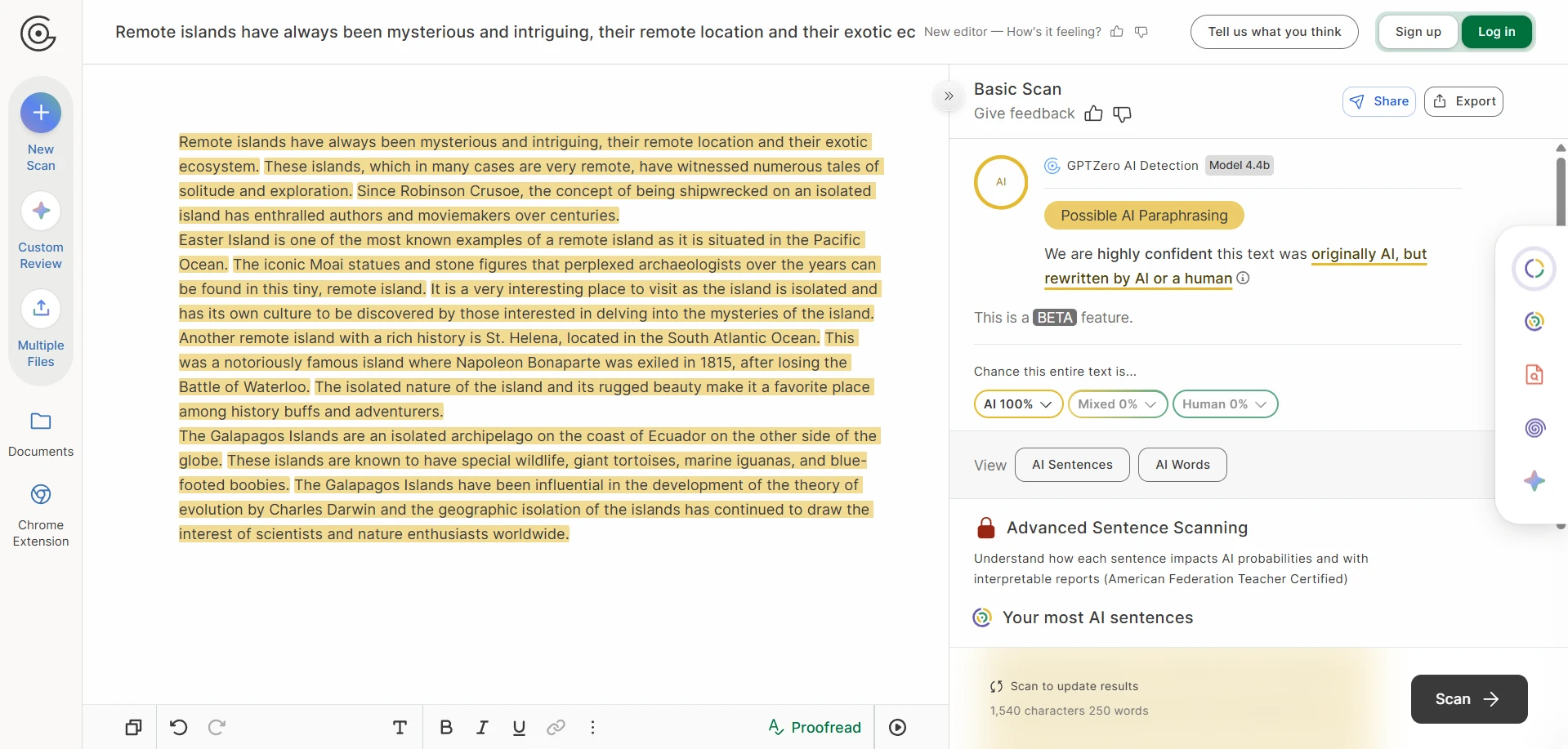
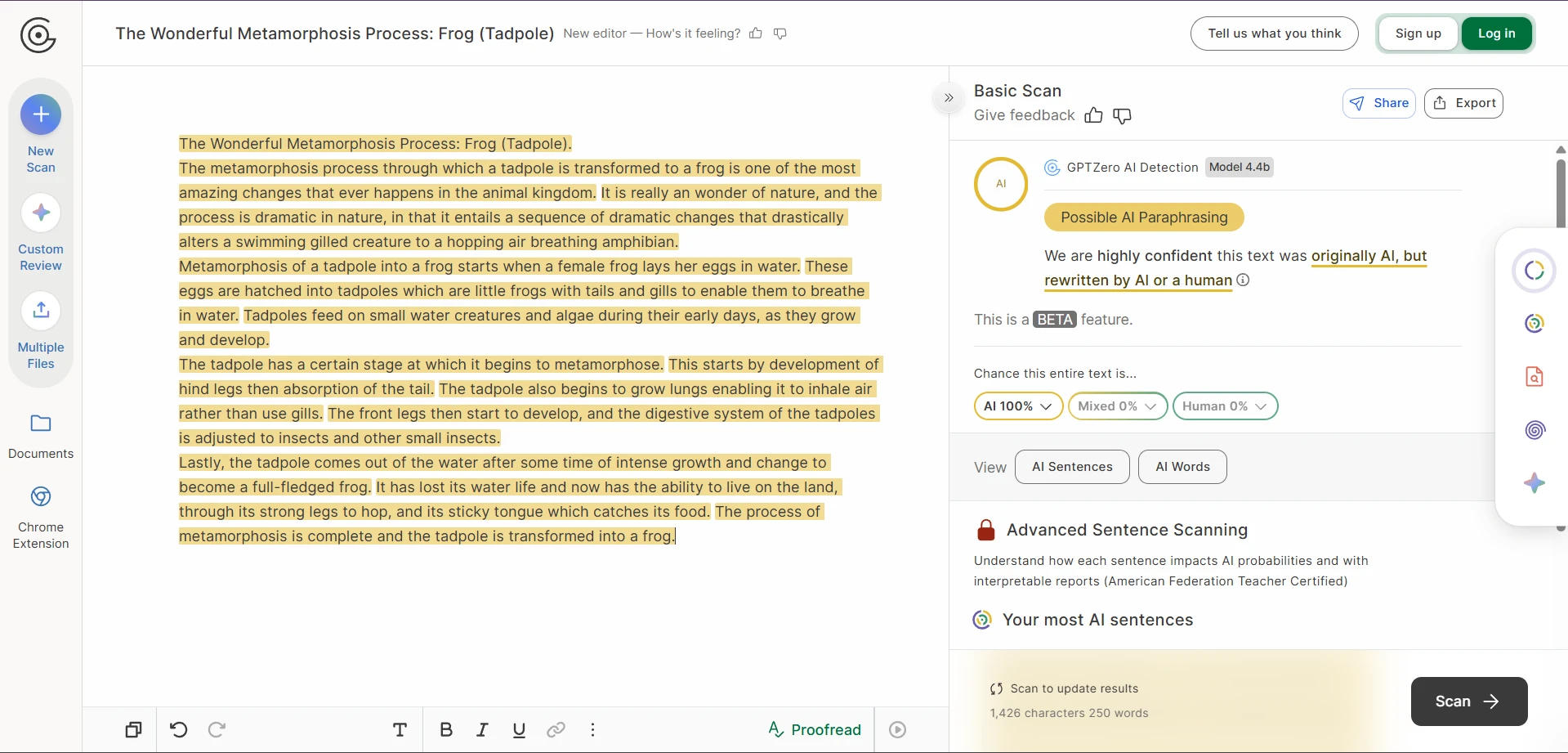
Passing GPTZero is not the same as writing well
A manual review of the rewrites in the CSV surfaced another important issue: some passages that scored well still had obvious writing problems. A high detector score did not always mean the prose sounded natural, polished, or trustworthy.
Examples from the dataset: one rewrite produced a heading that read “3. smell the vegetables” with broken capitalization; another used the phrase “be able to adapts”; another ended with the unfinished line “enjoy the.” I also found clumsy repetition such as “in case it is lost in case of any disaster”, spacing glitches like “20 th” and “21 st”, and name handling issues such as “Tutancamun” for Tutankhamun.
Those are not tiny cosmetic flaws. They matter because they break the illusion of natural writing. Even if a detector gives the passage a high human score, awkward grammar, strange formatting, and sloppy wording can still make the rewrite look suspicious to an actual reader. For students, that means a rewritten essay can pass one screen and still raise eyebrows in class.
I also noticed mild meaning drift in some rewrites. Sometimes the tool swapped in wording that was technically close but less precise, less natural, or slightly off in tone. That kind of drift is dangerous in academic writing. Once terminology becomes fuzzy, the writing may sound less credible, and in some subjects it can even blur the original meaning.
Final verdict
Stealthwriter is not a total failure, but this 100-sample test does not support the idea that it is a dependable GPTZero bypass tool. The core problem is instability. A minority of rewrites looked strongly human, but a very large share looked strongly AI-like, and the success rate dropped fast once the standard became stricter.
Just as important, detector wins did not always produce clean writing. Some rewrites still contained grammar errors, formatting slips, repetition, awkward phrasing, and occasional meaning drift. For students, that makes the tool risky in two ways at once: it may fail the detector, and it may also leave behind sentences that sound off to a human reader.
If the goal is reliable, readable, low-risk writing, the data points in a clear direction: Stealthwriter can sometimes help, but it does not consistently deliver detector-safe or classroom-ready prose.