![[STUDY] Can Stealthwriter Really Bypass Copyleaks? What 100 Samples Show](/static/images/stealthwriter-vs-copyleaks-featured-imagepng.webp)

When a rewriting tool promises to make AI text look human, the real test is not one lucky example. The real test is whether it can do the job again and again without making the writing sound strange, repetitive, or broken. We reviewed 100 Stealthwriter rewrites and checked their converted Copyleaks human scores. In this study, a higher number means Copyleaks saw the text as more human. The result was not a clean victory or a total collapse. It was a much messier story about inconsistency.
How This Test Was Set Up
Each row in the CSV contained an original passage, a Stealthwriter rewrite, and a human score. Because the numbers were already converted into human probability, the reading is simple: 100% means the text looked fully human to Copyleaks, while 0% means it looked fully AI.
To keep this easy to follow, two numbers matter most. The average is what you get when you add all 100 scores and divide by 100. The median is the middle score after sorting everything from lowest to highest. The average tells us the overall level. The median tells us what a “typical” result looked like.
Also Read: [STUDY] StealthWriter vs Sapling AI: Can 100 Humanized Rewrites Slip Through?
Key takeaways from the dataset
- Average human score: 67.7%
- Median human score: 91.0%
- Basic pass line: 64 out of 100 samples scored at least 50% human
- Very strong passes: 52 samples reached 90% human or higher
- Hard failures: 36 samples stayed below 50% human, and 15 of those fell under 20%
Why the average and median look so different: the median is high at 91.0%, but the average drops to 67.7%. That gap usually means the results are split into two groups: one group did well, but another group crashed badly enough to drag the average down.
The Main Pattern: Strong Highs, Serious Lows
If Stealthwriter were reliably getting past Copyleaks, the chart would look smooth, with most samples sitting in the upper bands. That is not what happened. Instead, the dataset split sharply. Sixty-one samples landed in the 80–100 range, which sounds impressive. But thirty samples also fell below 40, and fifteen of those were stuck under 20.
Also Read: [STUDY] Can Stealthwriter Outsmart GPTZero? A 100-Sample Test
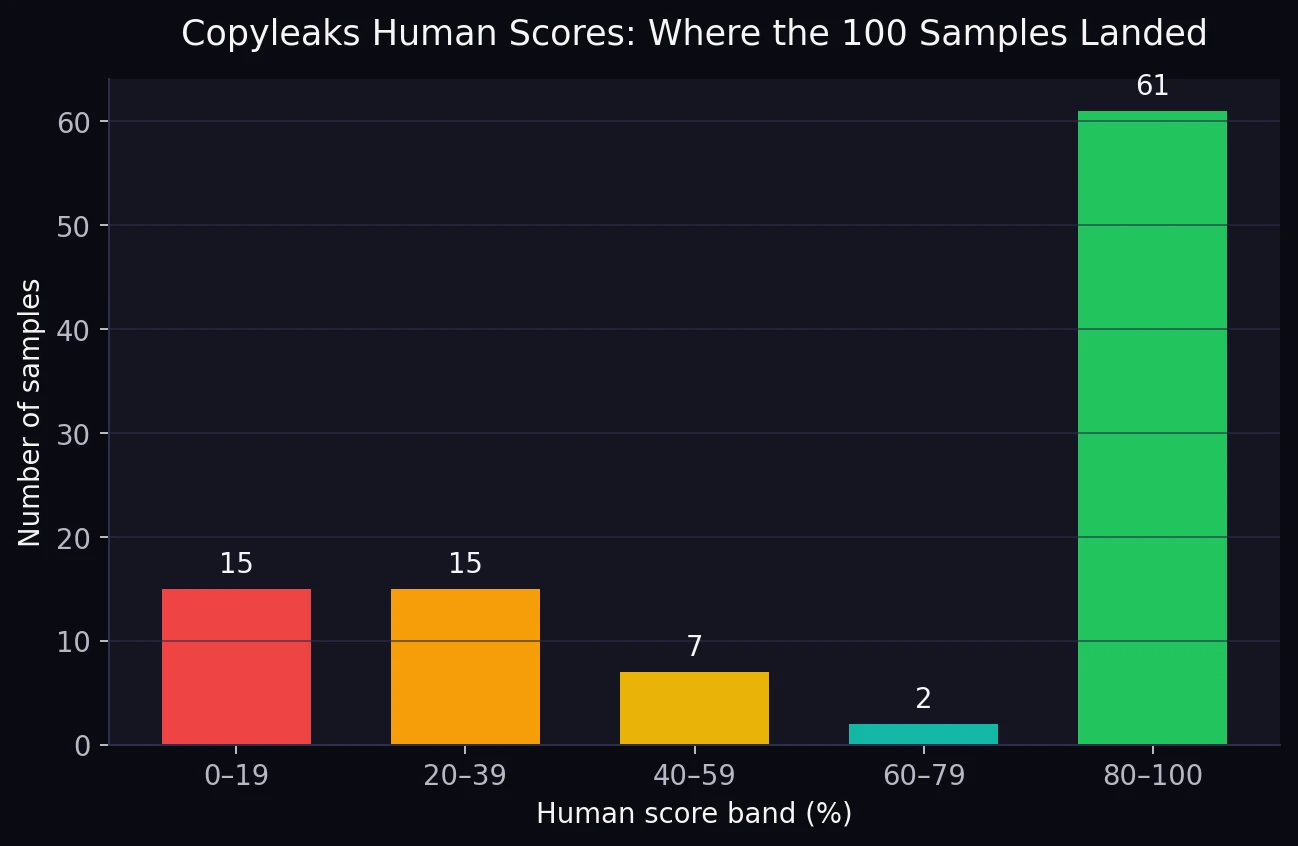
That split is why the test feels unstable. A tool does not need to fail every time to be risky. It only needs to fail often enough that you cannot predict what will happen on the next rewrite. For students, that matters a lot. A tool that passes one paragraph at 99% and the next at 18% is not dependable. It is a gamble.
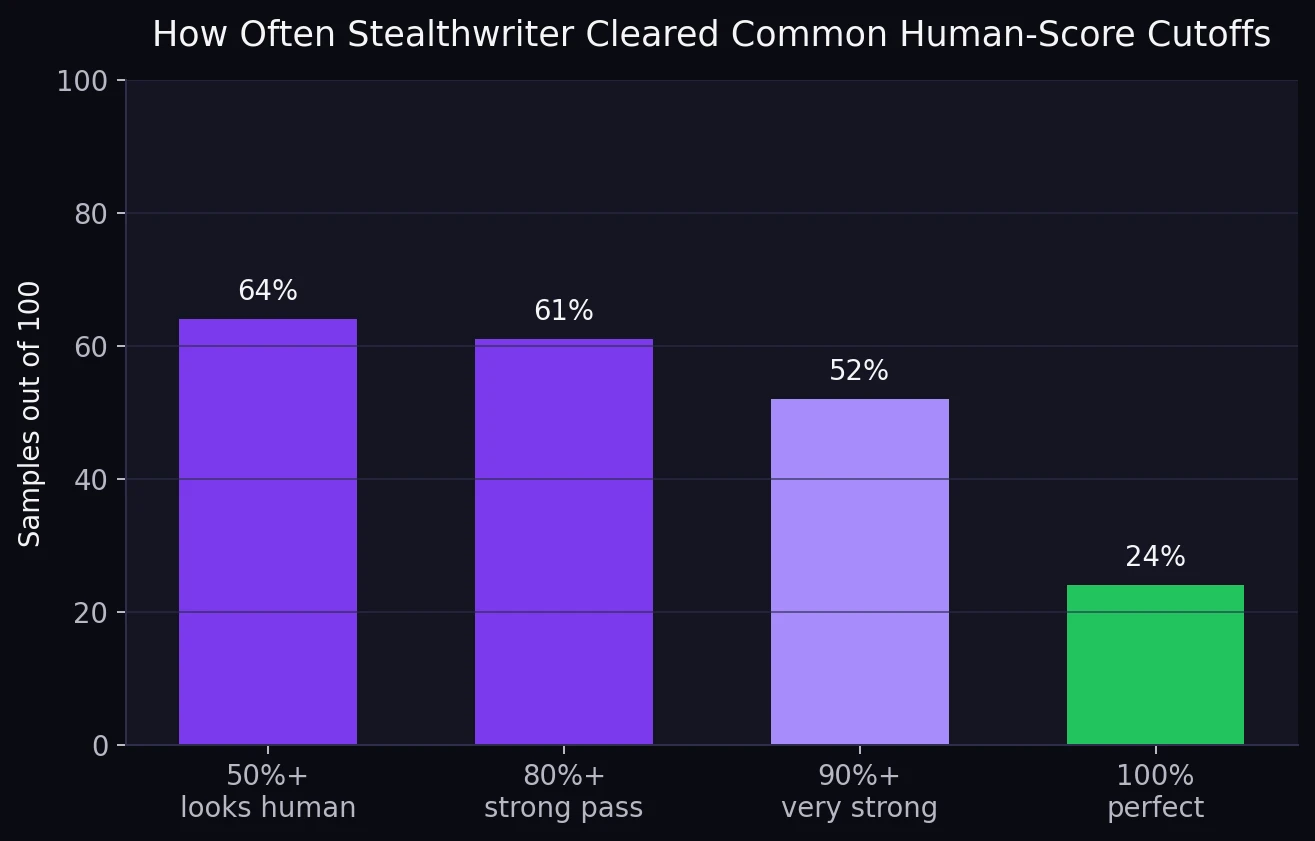
Even the threshold view tells the same story. Yes, 64% of the samples cleared the 50% mark. Yes, 52% reached 90% or better. But the other side of the picture matters just as much: 36% of the dataset did not even clear the basic human line. If the goal is reliable bypassing, that failure rate is too large to ignore.
Also Read: Stealthwriter vs ZeroGPT: I Tested 100 Rewrites, and the Results Were Complicated!
The Dashboard Can Look Great. The External Check Is Harder.
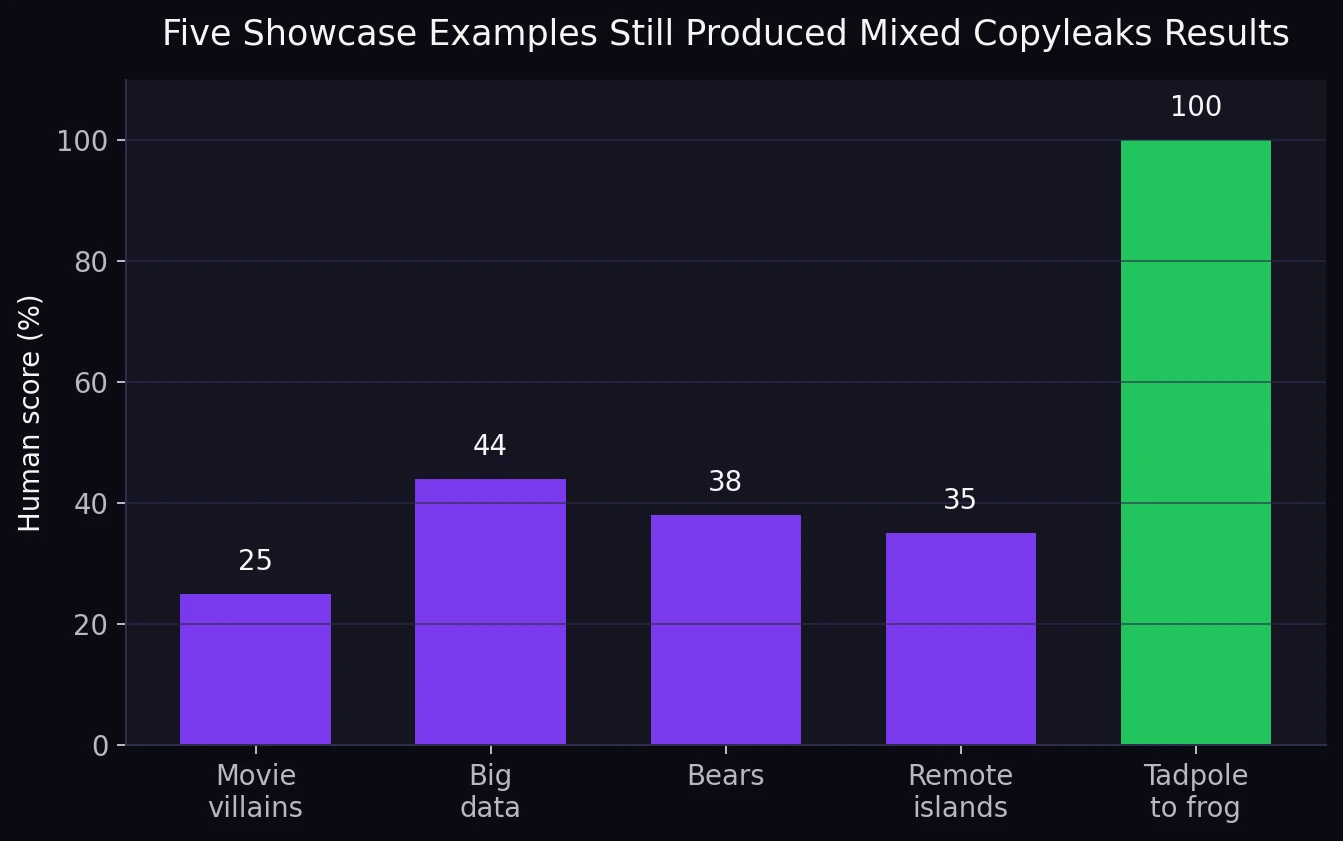
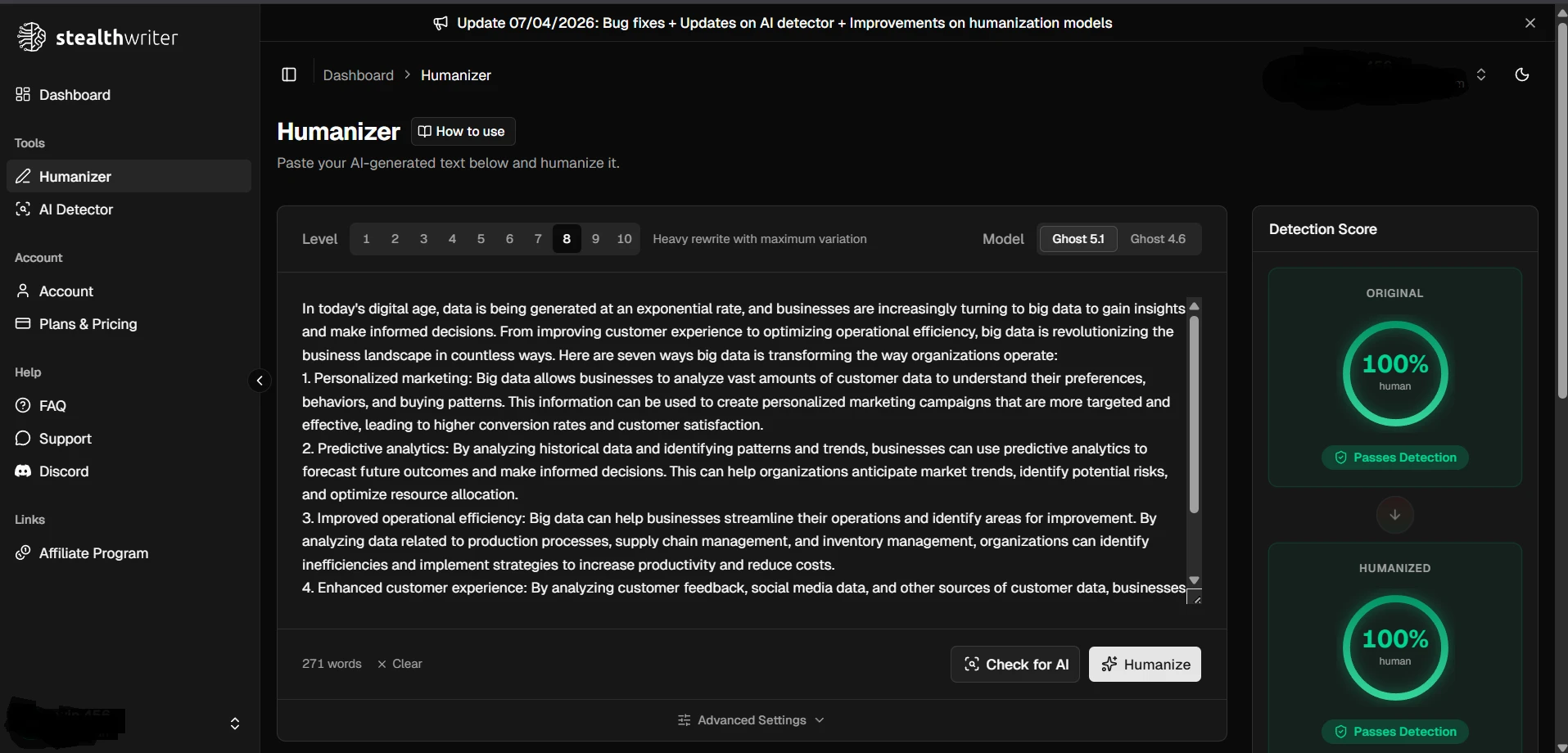
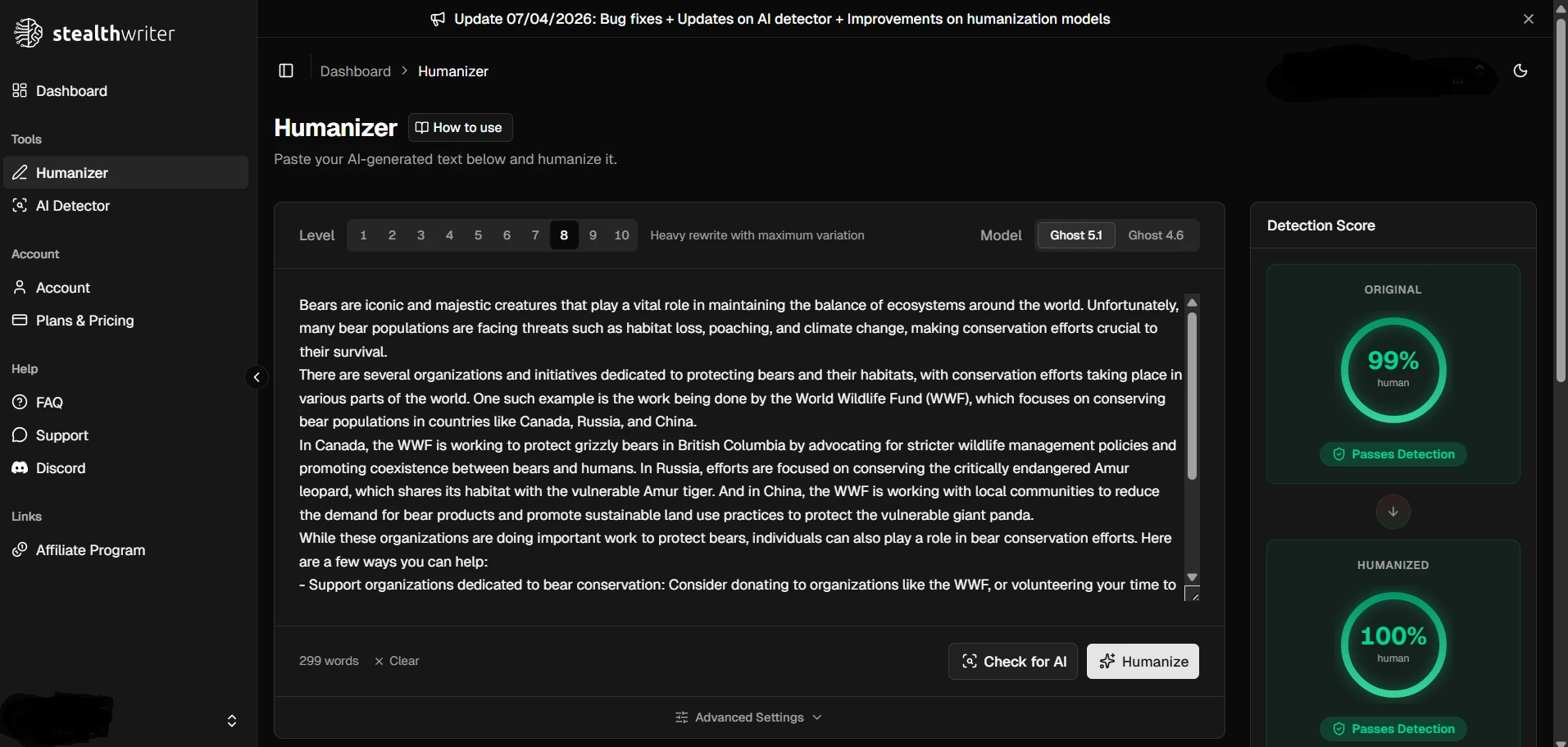
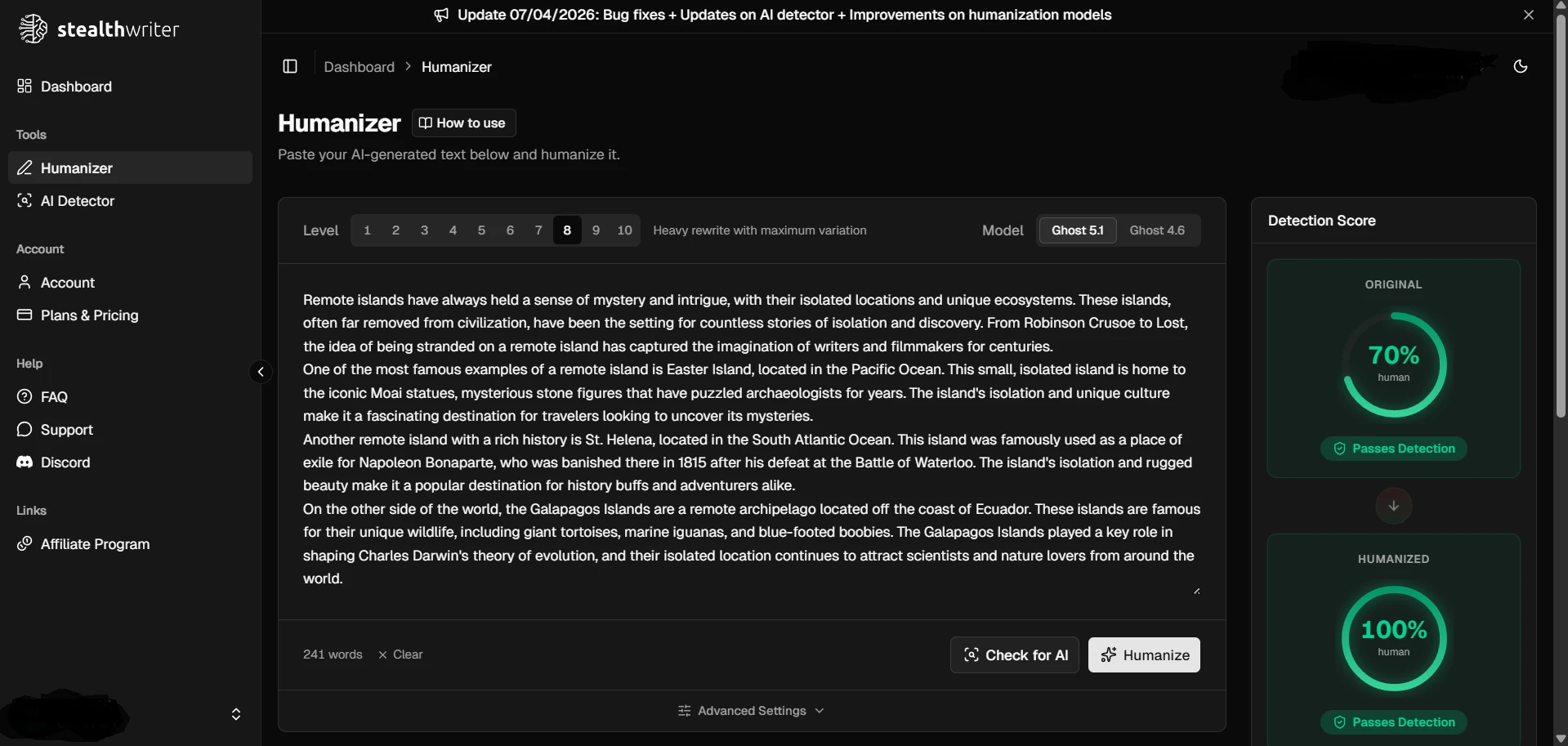
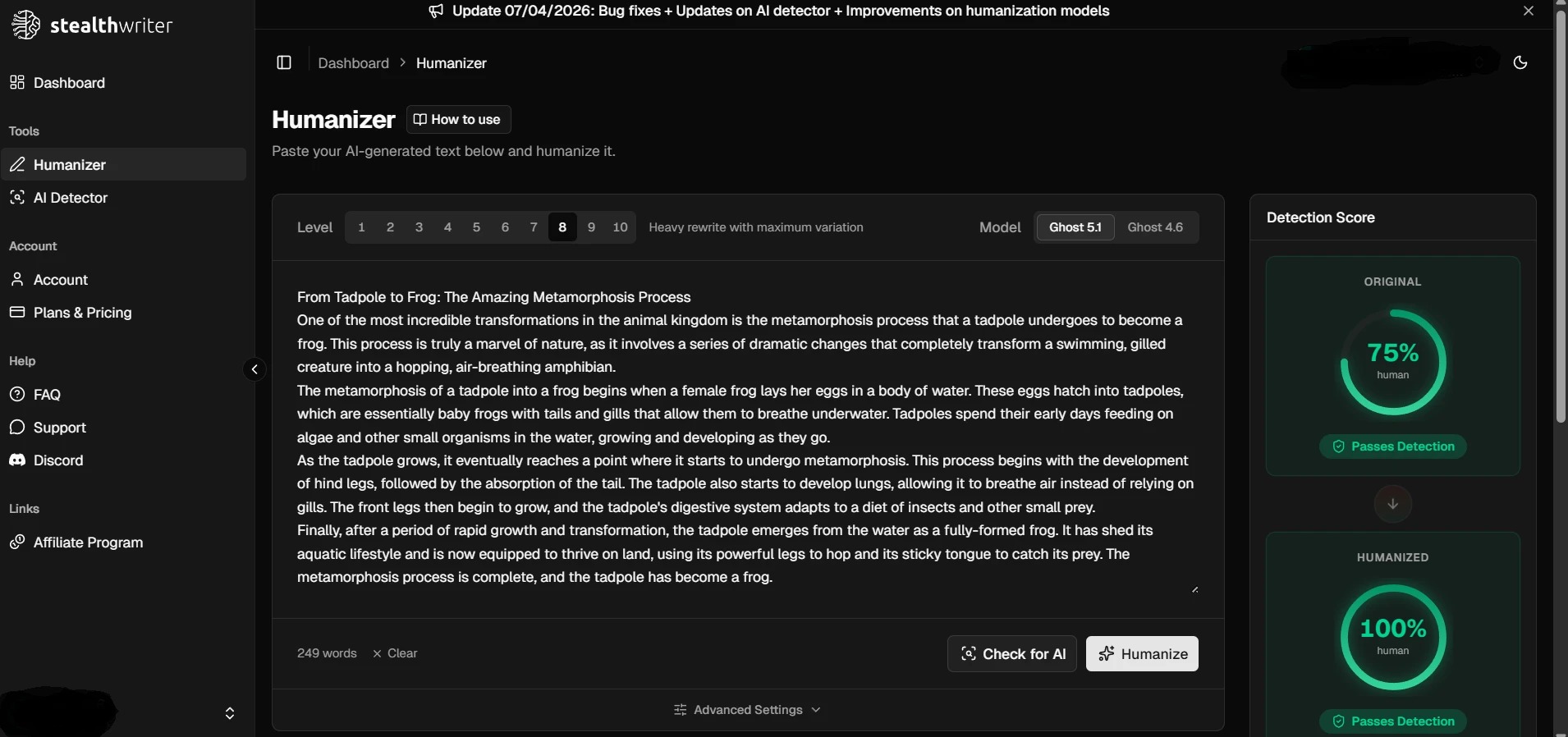
The screenshots below make Stealthwriter look convincing. In the app itself, the “humanized” versions often appear dramatically better than the originals. That is exactly why full-batch testing matters. A few polished examples can make any tool look unbeatable.
But when the same showcase topics were matched against the Copyleaks results in the CSV, the picture was mixed. The five examples landed at 25%, 44%, 38%, 35%, and 100% human. In other words, one sample was excellent, while four were weak or borderline.
The CSV Exposed Problems Beyond the Score
Detection numbers were only part of the story. Once the rewrites were read line by line, several quality issues appeared.
First, one sample was not rewritten at all. The output matched the original text word for word. That matters because a rewrite tool is supposed to rewrite. A detector miss is one problem, but a no-change output is a basic product failure.
Second, there were visible formatting slips. One rewrite turned a list item into “3. smell the vegetables” with a lowercase heading. Other samples introduced broken number styling like “17 th century” and “20 th century”. These may look small, but they make the text feel machine-produced because human editors usually clean them up immediately.
Third, a few rewrites lost their balance at the sentence level. One passage says “Fill them in adorable jars or containers and a spa-like gift experience”, which is not a complete thought. Another rewrite kept the topic but used stiff or awkward lines that read more like patched-together substitutions than natural writing. That is an important point for students: a high detector score does not automatically mean the writing is good.
Fourth, the rewrites often drifted into the same stock phrasing. That kind of repetition is easy to miss when you test one sample at a time, but it becomes obvious across a full file.
Also Read: [STUDY] Can Stealthwriter really slip past Originality.ai? I tested 100 rewrites to find out.
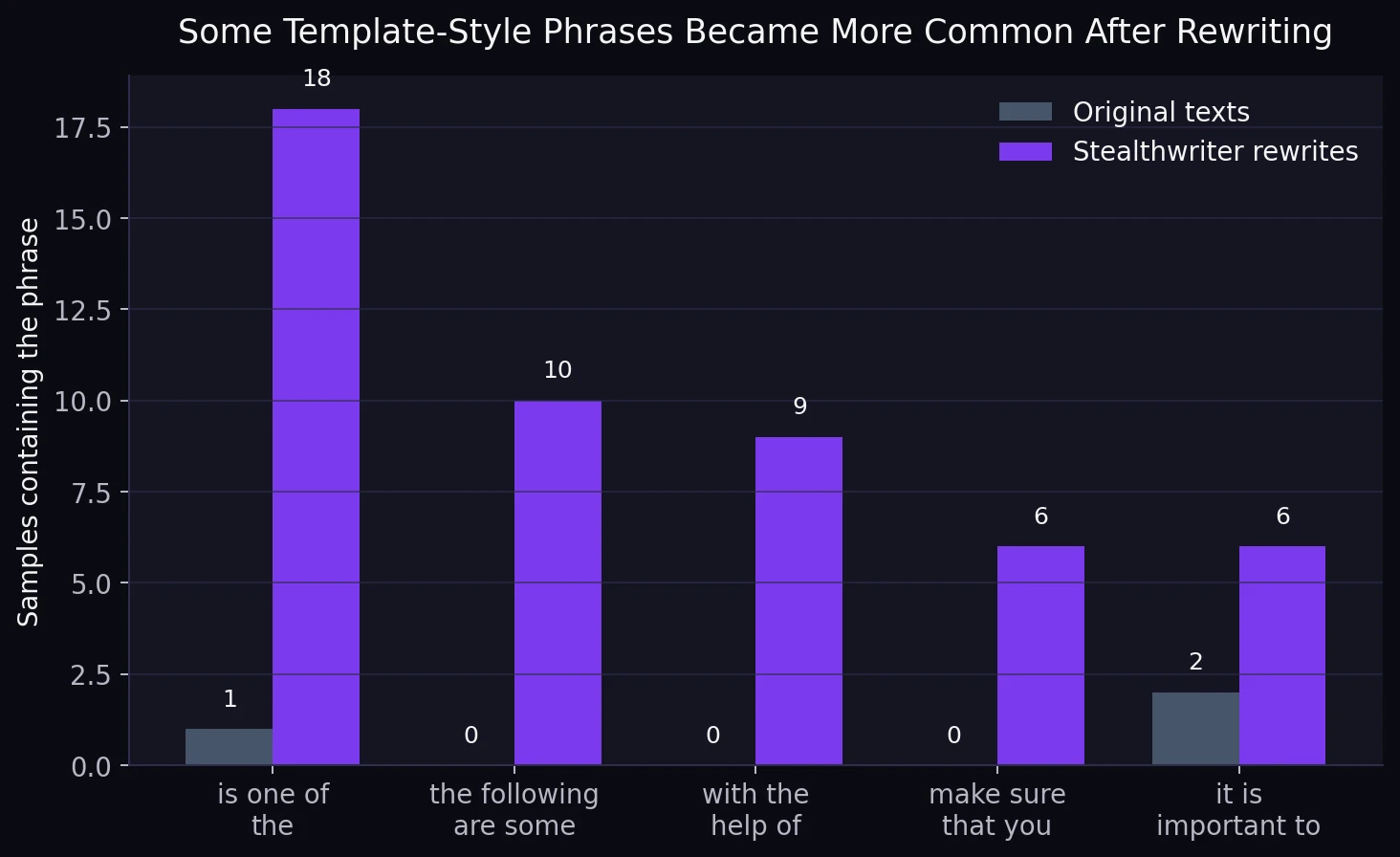
This pattern is especially telling because some of these phrases barely appeared in the originals at all. “The following are some” showed up in 10 rewrites and in none of the originals. “With the help of” appeared in 9 rewrites and again in none of the originals. “Make sure that you” appeared in 6 rewrites and in none of the originals. A human writer can certainly use these phrases, but when they keep repeating across unrelated topics, the writing starts to sound templated.
What Students Should Take From This
If the only question is whether Stealthwriter can produce a strong Copyleaks result, the answer is yes. This dataset contains plenty of strong scores, including 24 perfect 100s. But if the real question is whether it can do that consistently, the answer is much weaker.
That difference matters. Students often look at a tool’s best-case output and assume it will behave the same way every time. This dataset shows the opposite. Some rewrites came out looking very human to Copyleaks. Others were flagged heavily. Some sounded fine. Others picked up awkward wording, formulaic phrasing, or formatting scars that needed manual repair.
There is also a bigger lesson here. Passing a detector is not the same thing as producing original, thoughtful, class-ready writing. A paragraph can score well and still sound generic. It can score well and still lean on repeated templates. It can even score well while needing cleanup. That is why real writing quality still comes from the human part: choosing the angle, building the argument, adding real examples, and revising for clarity.
The Bottom Line
Across 100 samples, Stealthwriter looked less like a guaranteed Copyleaks bypass and more like a tool with uneven performance. It produced some excellent wins, but it also produced too many weak scores and too many rewrite-quality issues to call the result reliable.
The simplest verdict is this: Stealthwriter can work, but it does not work steadily enough to trust on its own. If readers care about consistency, readability, and external checking rather than just a few flashy examples, this dataset gives them a clear warning.