

A rewrite that fools an AI detector is not automatically a good rewrite. That is the tension at the center of this test. In a dataset of 100 BypassGPT.ai rewrites, GPTZero often labeled the output as human, sometimes with very high confidence. But the full dataset tells a more complicated story: the wins were real, the failures were harsh, and the cost of those wins was often a drop in structure, clarity, and polish.
How this test was set up
Each sample started as an original passage, then went through BypassGPT.ai, and the rewritten result was checked in GPTZero.me. To make the results easier to read, the detector score was converted into a human score. That means a higher number is better for the rewriter. A score of 1.0 means GPTZero treated the text as fully human, while 0.0 means it was treated as fully AI.
This matters because detector screenshots can be misleading on their own. A few successful scans can make a tool look unbeatable. A larger sample shows whether the tool is dependable or just capable of producing occasional wins. For students especially, that difference matters. A tool that works only some of the time is not really a shortcut; it is a gamble.
Also Read: [100 Samples Test] Can BypassGPT Really Bypass Originality.ai?
What jumped out from the data
- Average human score: 66.0%. On the surface, that looks solid.
- Median human score: 92.5%. The median is the middle score after lining all 100 results up from lowest to highest, and it was much higher than the average.
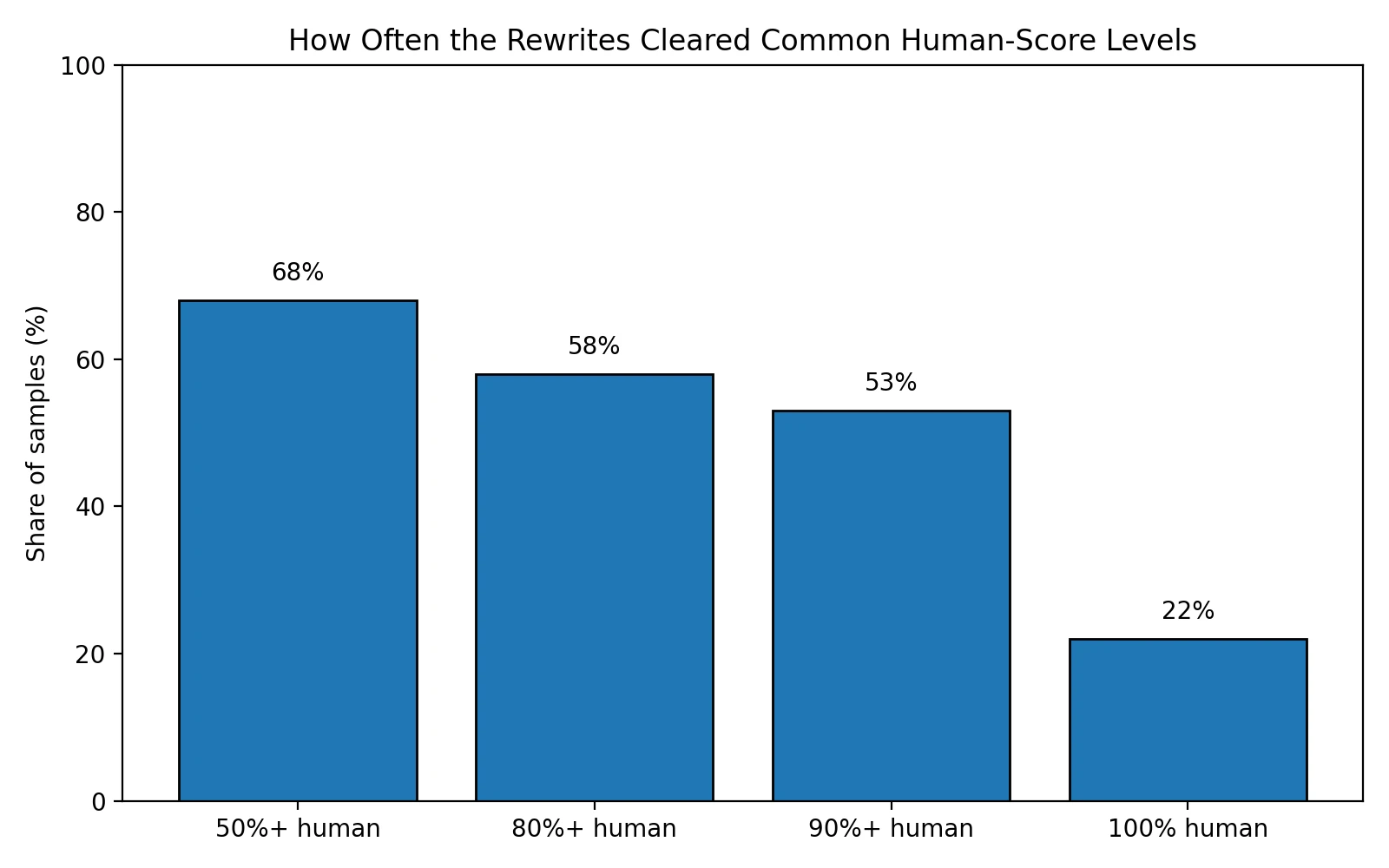
- High scores were common, but not universal: 68 of 100 rewrites cleared 50% human, and 53 reached 90% human or better.
- Hard failures were not rare: 32 samples stayed below 50% human, 19 landed at 0% human, and only 22 got a perfect 100% human score.
The main finding: BypassGPT can beat GPTZero, but not reliably
The histogram below explains the story better than a single average ever could. Most scores did not gather in the middle. Instead, they split into two camps: one group of rewrites looked strongly human to GPTZero, while another group failed badly. That kind of spread is a warning sign. It suggests the tool is not producing one stable level of quality. It is producing a mix of convincing escapes and obvious misses.
Also Read: [STUDY] Can BypassGPT Really Slip Past ZeroGPT? I Tested 100 Rewrites to Find Out.
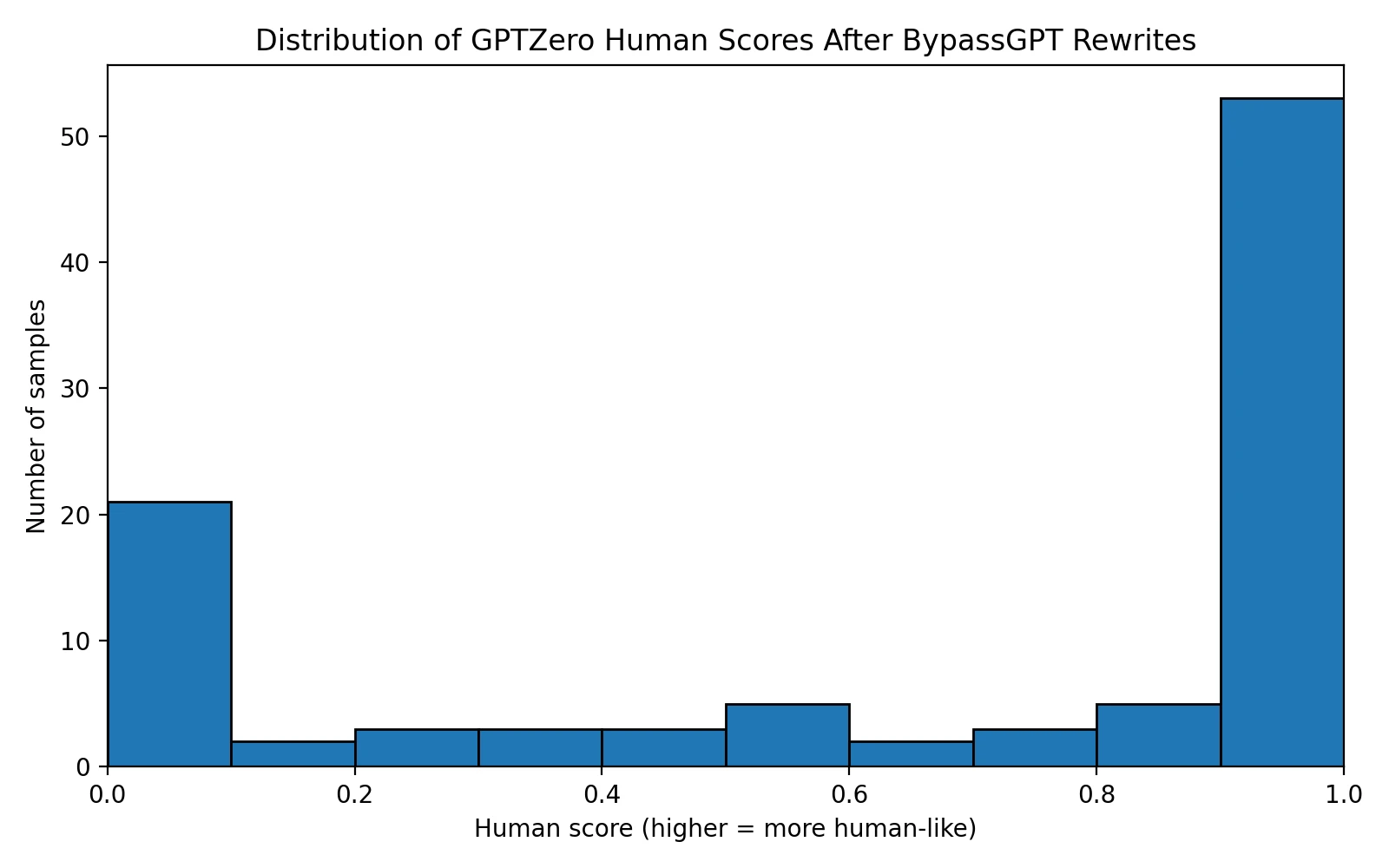
The average score was 66.0%, which sounds impressive until it is placed beside the 92.5% median. That gap tells us the weaker results dragged the average down hard. Put plainly: BypassGPT produced enough excellent-looking outputs to keep the middle of the dataset high, but it also produced enough bad ones to make the overall performance feel unstable.
The threshold chart sharpens that point. About two-thirds of the rewritten samples cleared the basic 50% human line, and more than half reached 90% human or better. Those are meaningful wins. At the same time, nearly one-third of the dataset did not even reach 50% human. For a tool built around bypassing a detector, that failure rate is too large to ignore.
Also Read: I Tested 100 BypassGPT Rewrites Against Sapling.ai. The Result Wasn’t What the Hype Suggests.
The hidden cost: the rewrites often damaged the original structure
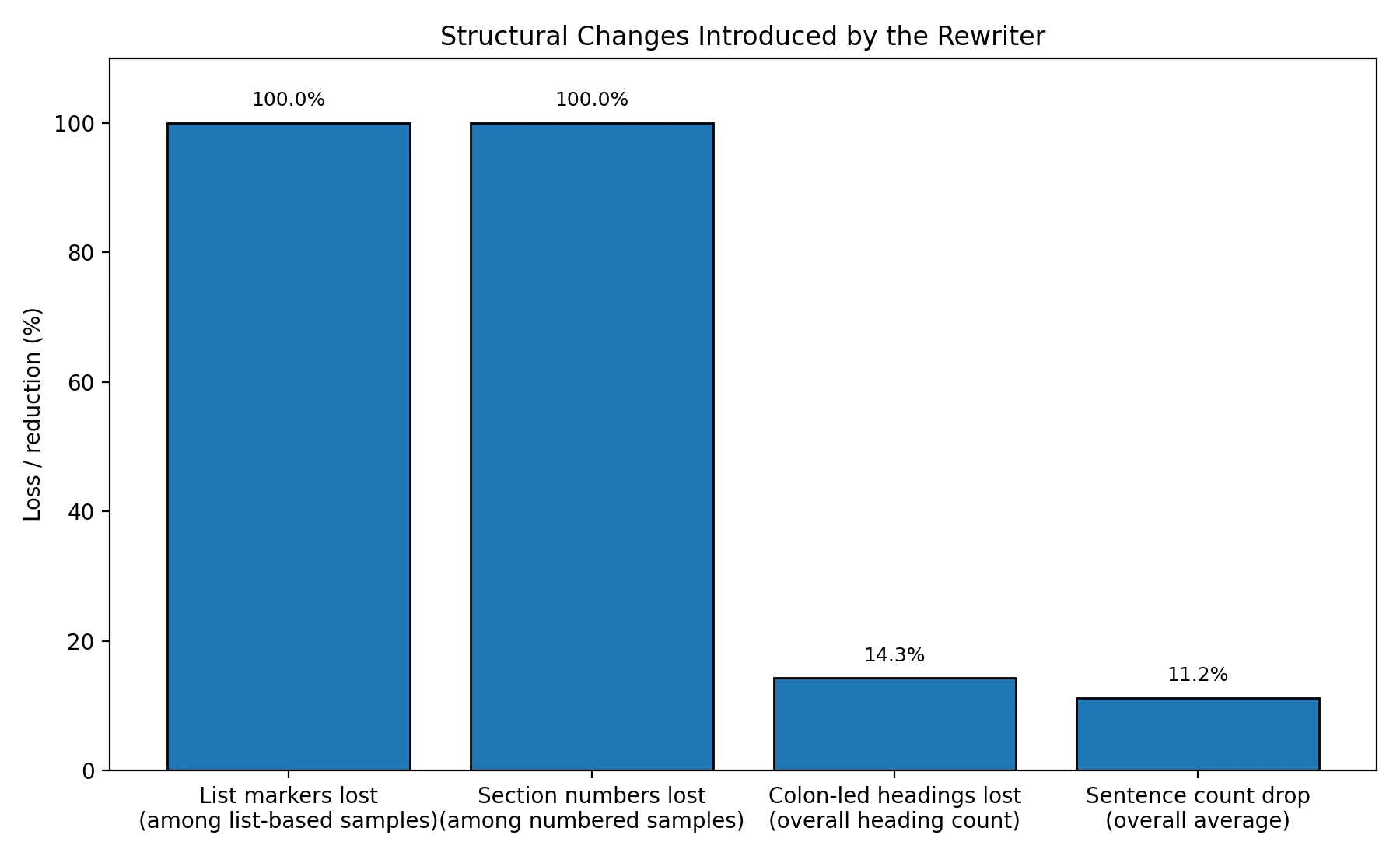
The score is only half the story. The CSV also shows that the rewrites frequently changed the shape of the writing itself. In structured content, that matters a lot. Guides, notes, explainers, and student blog posts often rely on headings, numbered steps, and short list items to stay readable. When that structure is stripped away, the output may still look human to a detector, but it can become worse for actual human readers.
That pattern was not a one-off. In all 38 samples that started with list markers, the rewritten version removed those markers. In all 36 samples that used numbered section labels, the numbering disappeared. Even short colon-led subheads — lines such as “Check for firmness:” — dropped from 119 in the originals to 102 in the rewrites. Across the full dataset, sentence count also fell by about 11.2%, which points to simplification and flattening.
Also Read: BypassGPT.ai vs Turnitin: My 100-Sample Test Shows Why “Humanized” Text Is Still a Gamble
Some of these changes were cosmetic, but others affected quality. Clear labels such as “Increase your intensity” were turned into looser versions like “Amp your intensity.” Neutral instructional wording sometimes became chatty or odd. In one vegetable sample, a spoilage warning became the word “ratty,” which feels out of place. In weaker outputs, the damage was more serious: a few rewrites inserted broken phrasing that read less like natural paraphrasing and more like autocomplete gone wrong.
That is the key trade-off in this dataset. BypassGPT is not simply polishing text into a more human voice. It is often rewriting by force, and that force can erase formatting, bend tone, and occasionally break meaning.
Also Read: Can BypassGPT Outsmart QuillBot’s AI Detector? I Tested 100 Rewrites to Find Out
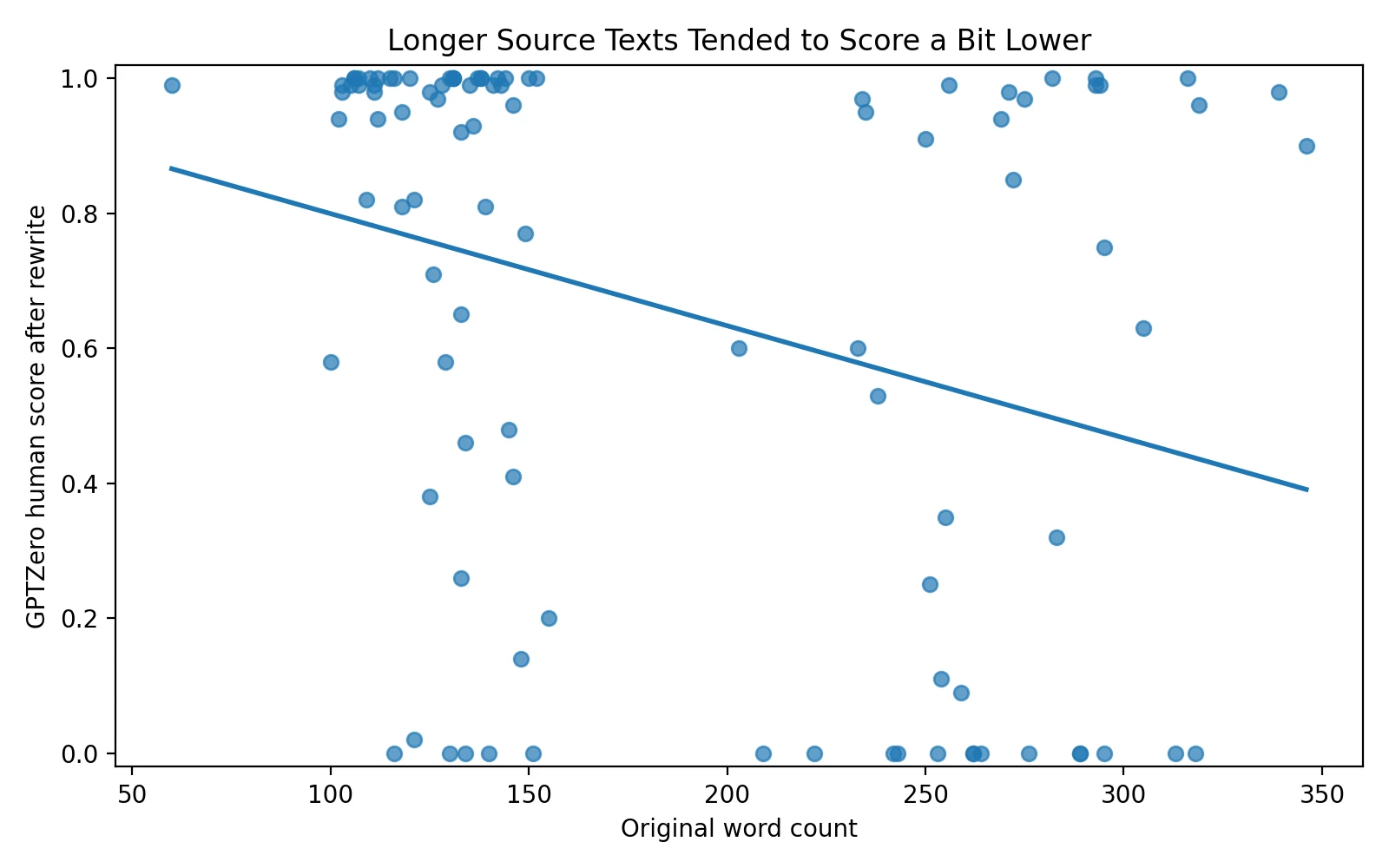
Longer passages looked a little riskier
The scatter plot below compares source length with the final human score. The downward trend is not dramatic, but it is there. Longer pieces tended to score a bit lower. In simple terms, the tool seemed more comfortable handling shorter or medium passages than longer ones.
This is only a weak relationship, meaning it is a tendency rather than a rule. Some long passages still did well. But if the goal is consistency, the direction still matters. The more text the system had to rework, the more chances it had to flatten structure, make awkward substitutions, or produce a low-confidence result in GPTZero.
What the screenshots show at a glance
The screenshots below help explain why this topic is easy to oversell. Several examples came back with strong GPTZero results, including high-confidence human scores. On a landing page, those examples would look persuasive. They are not fake wins. They really happened.
Also Read: [STUDY] Can BypassGPT Outsmart Grammarly’s AI Detector?
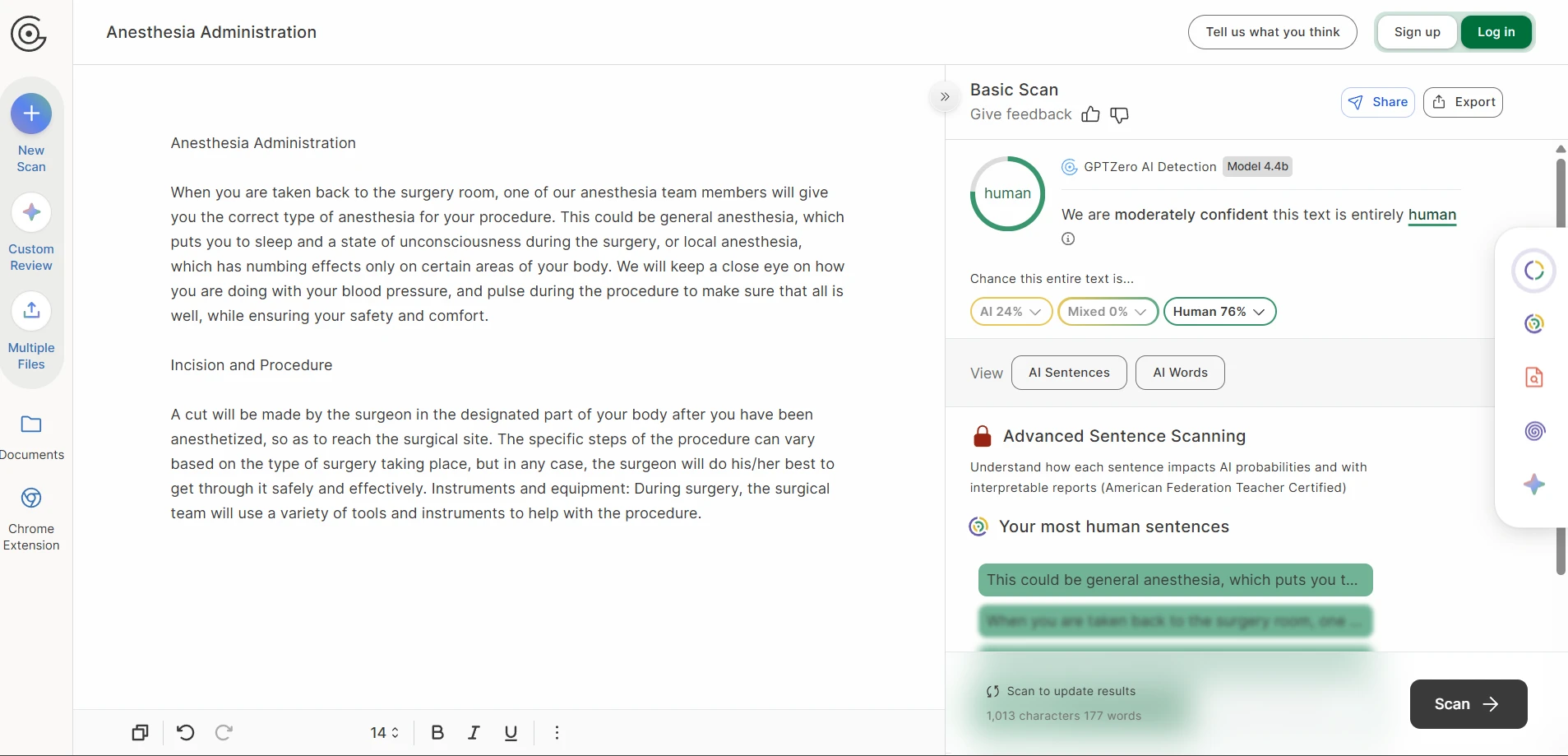
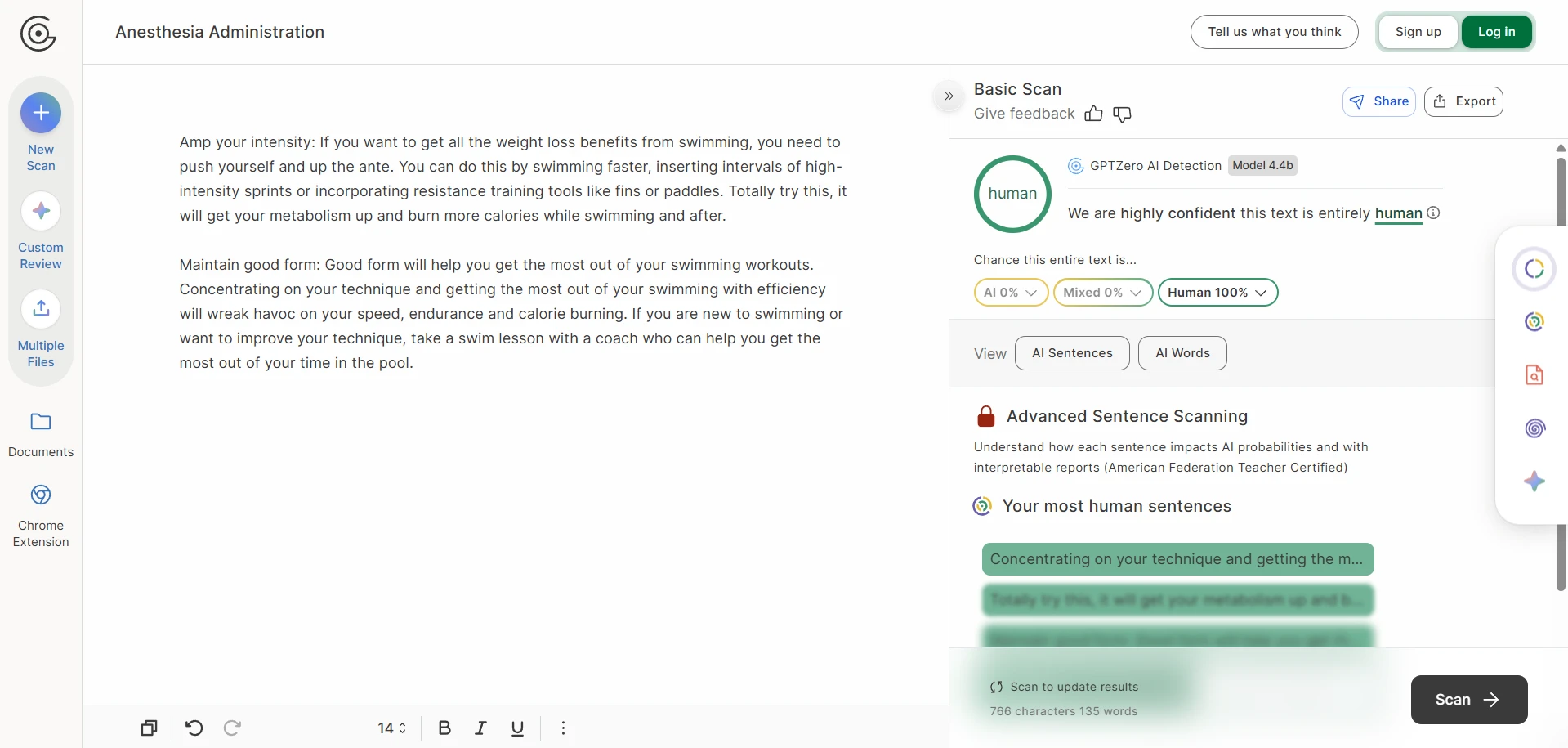
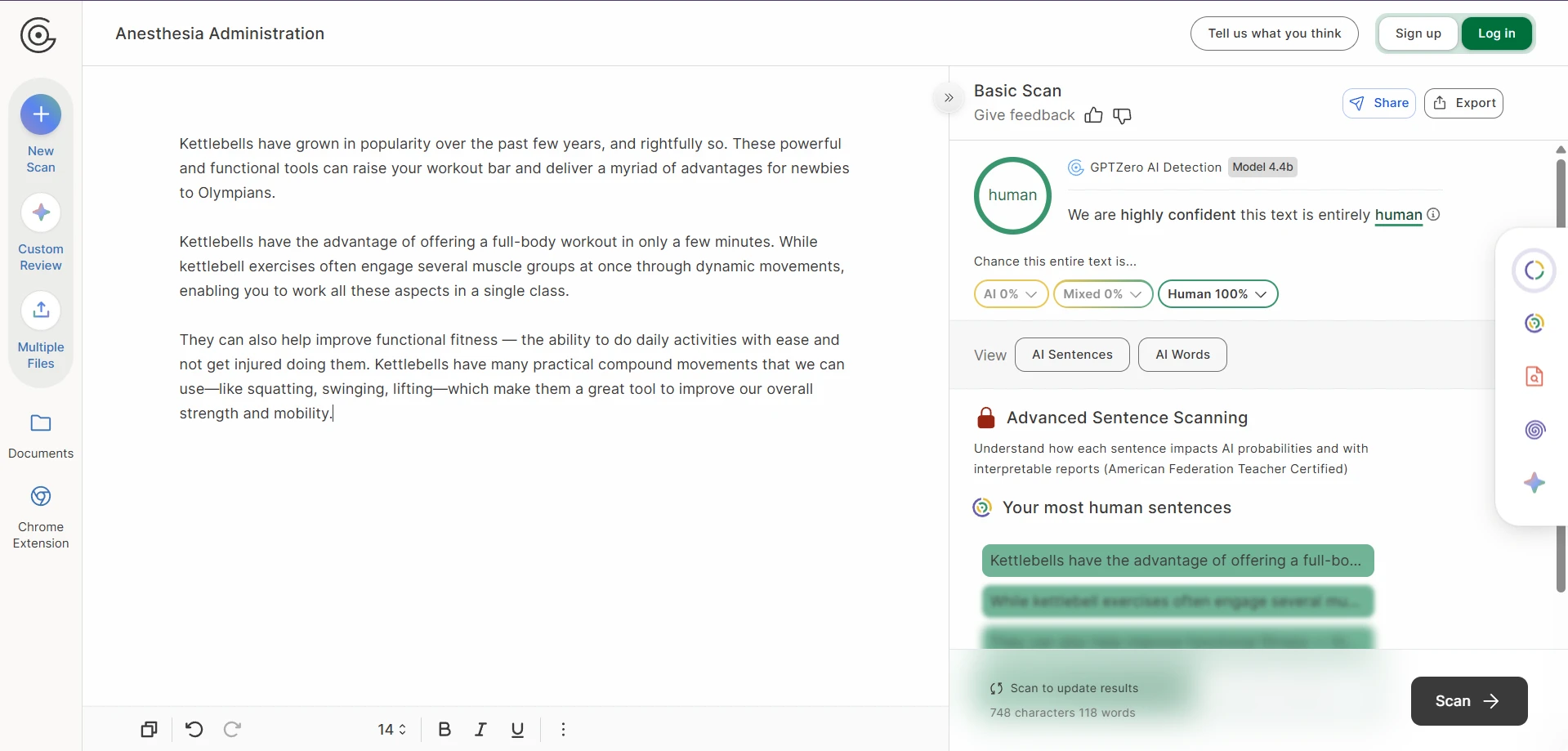
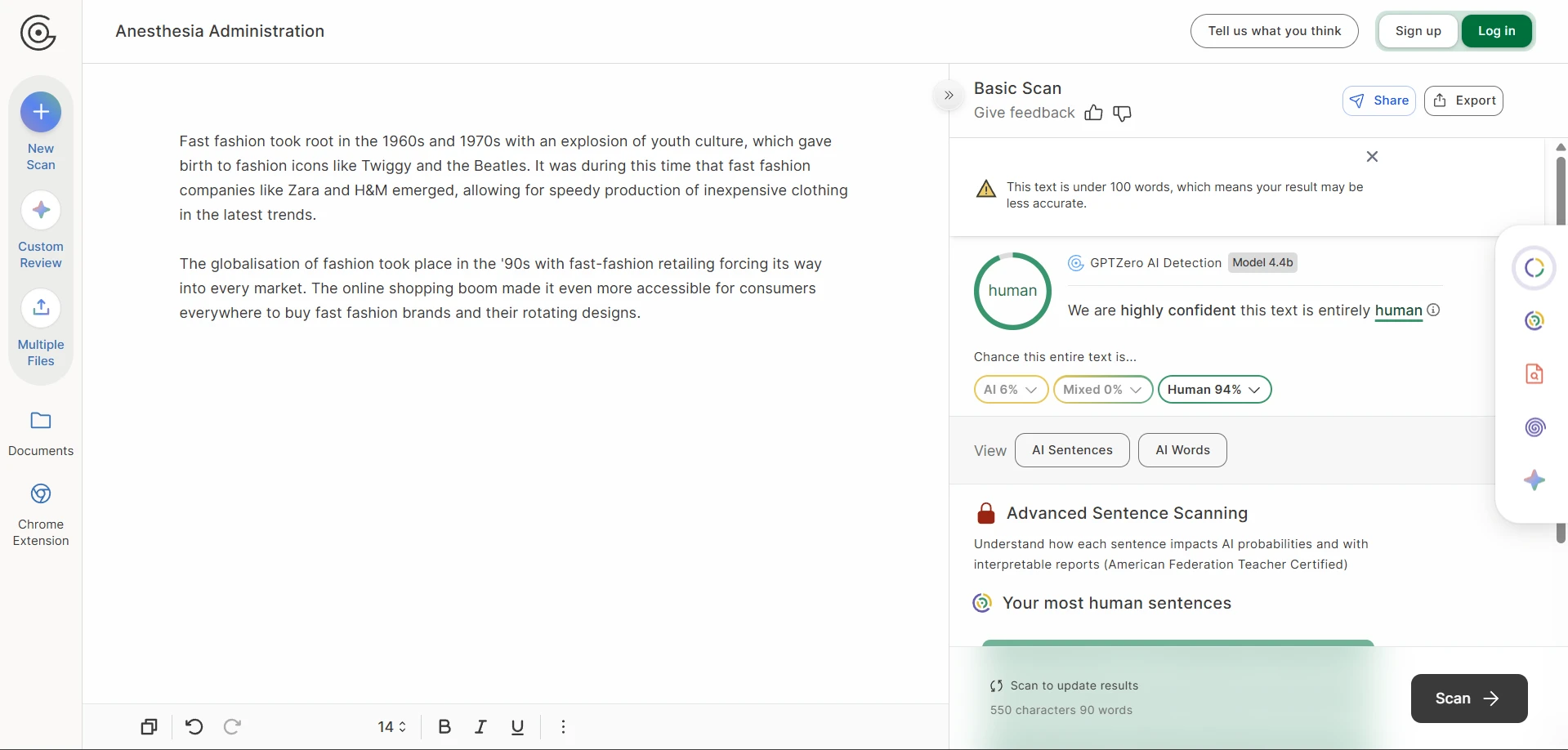
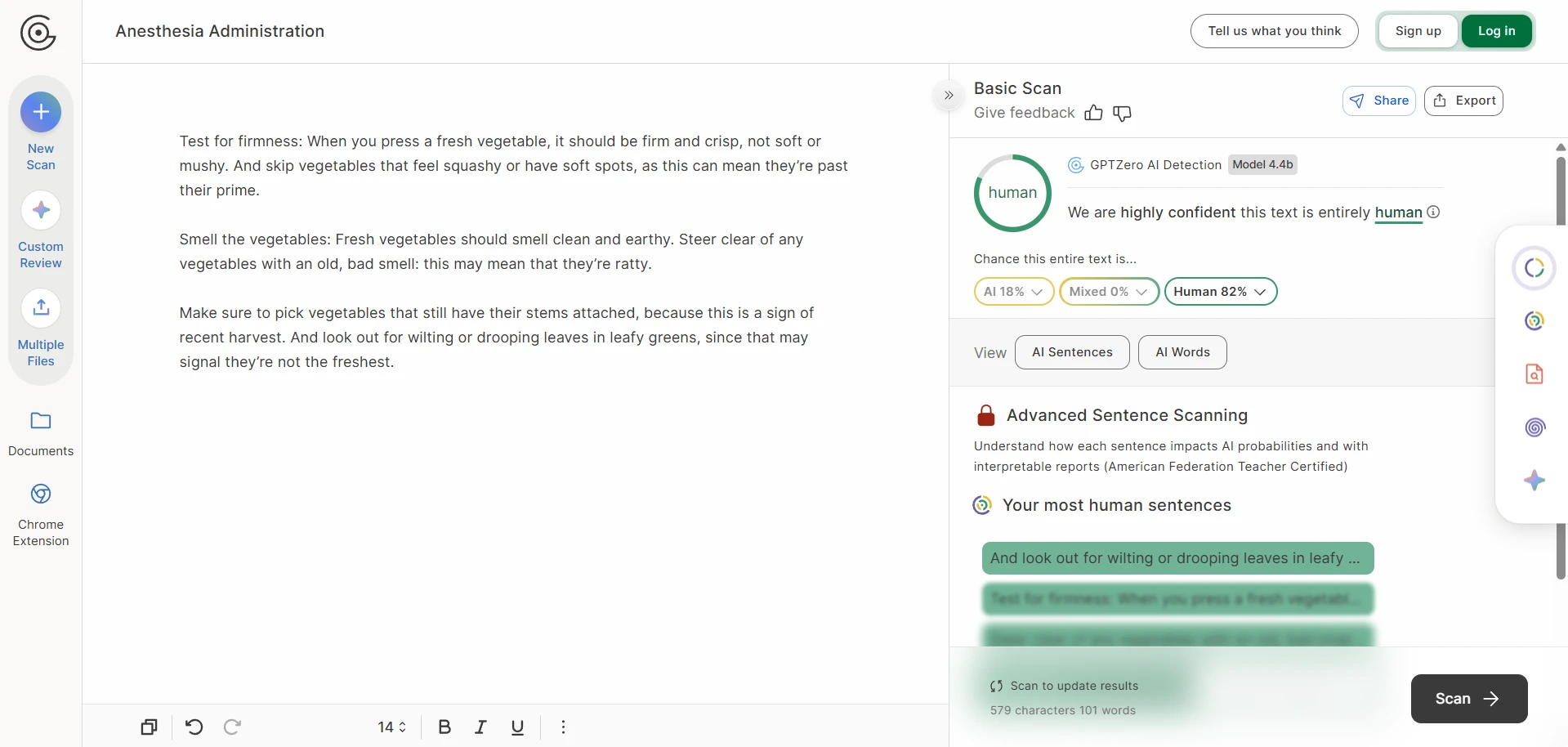
The rewrite-side screenshots tell the other half of the story. The output often preserved the broad idea of the original, yet the writing itself could drift. Numbered steps became plain paragraphs. Headings were softened, renamed, or detached from their original role. In the roughest cases, the wording became strange enough that a reader would notice before any detector did.
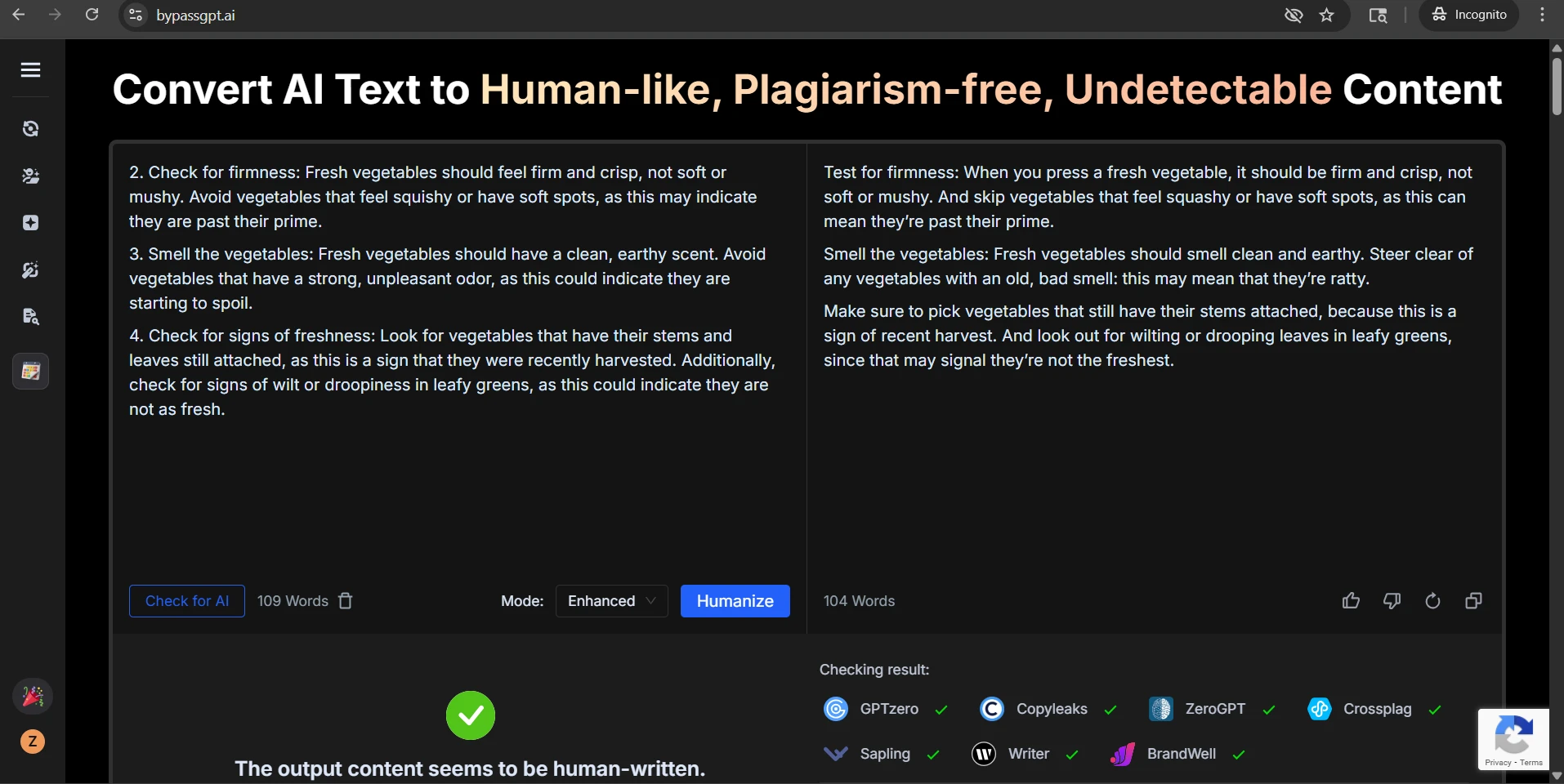
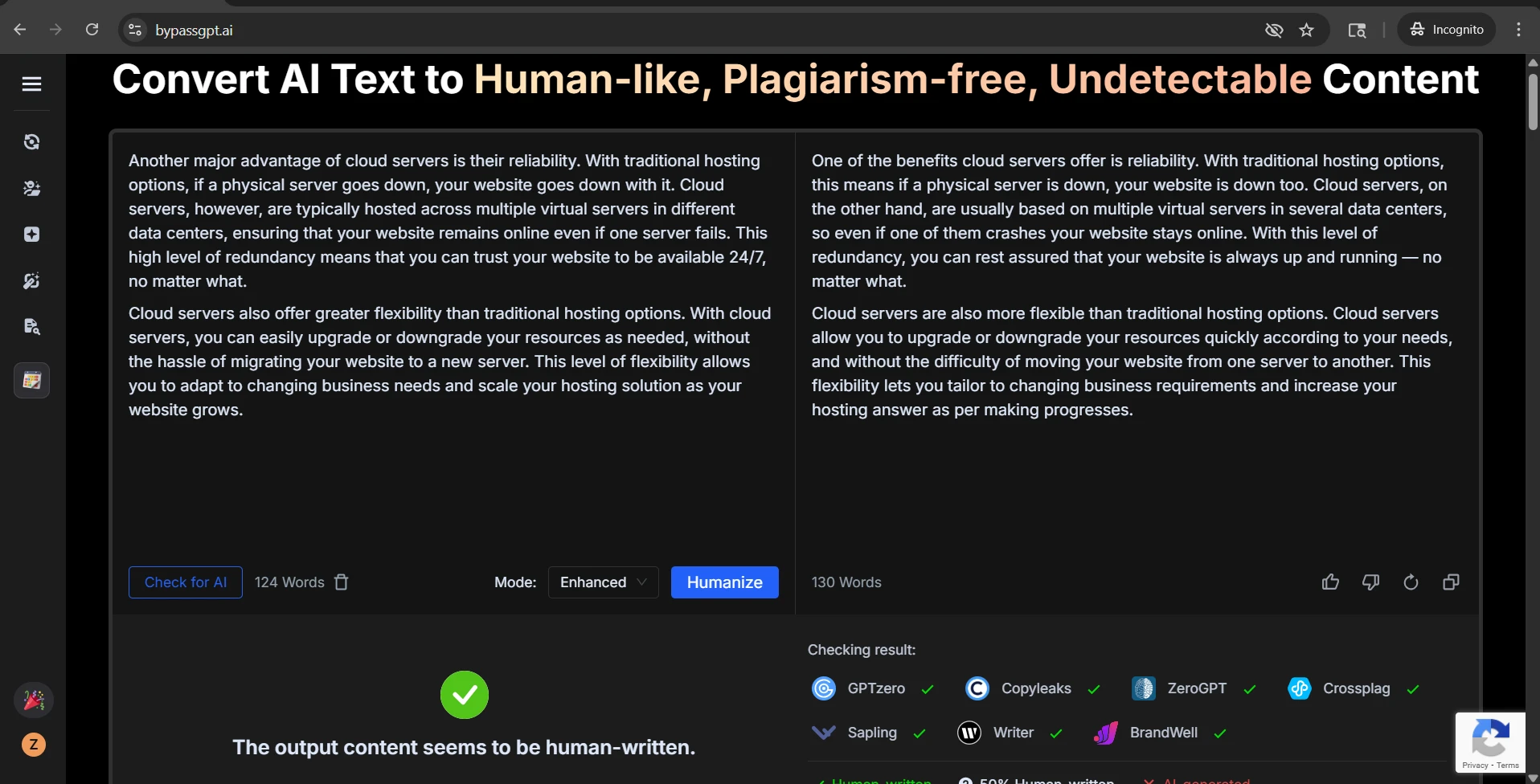
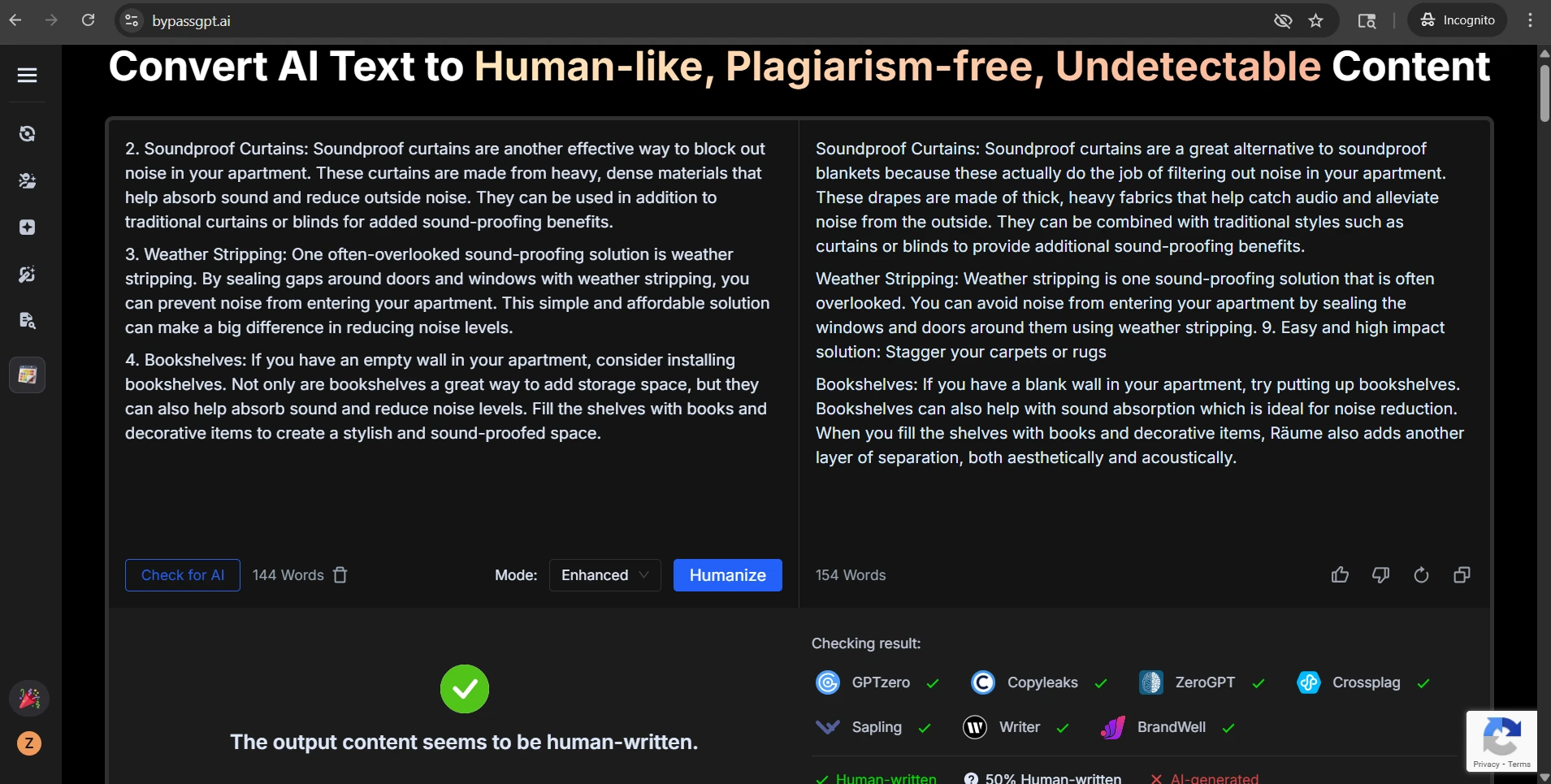
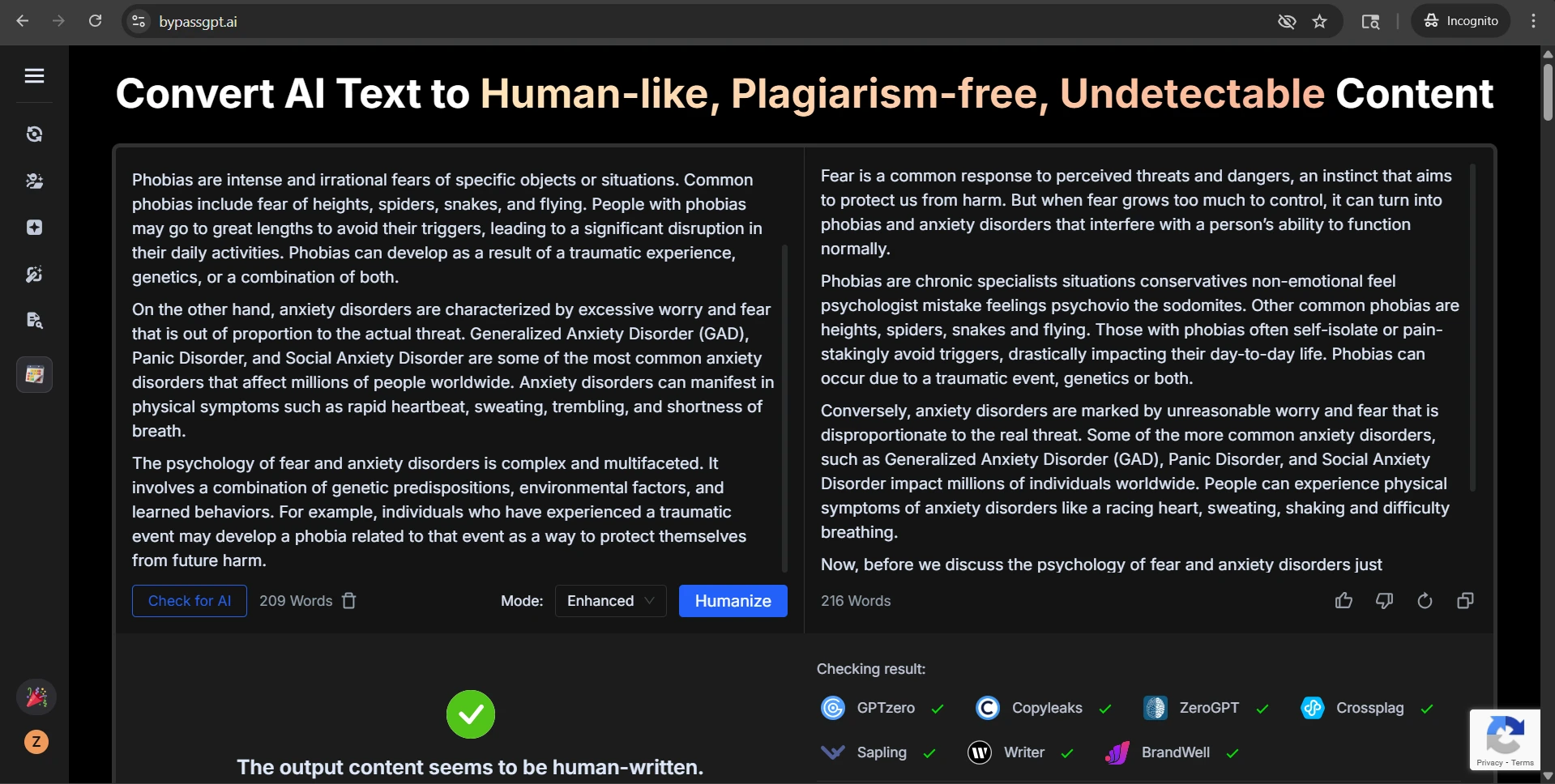
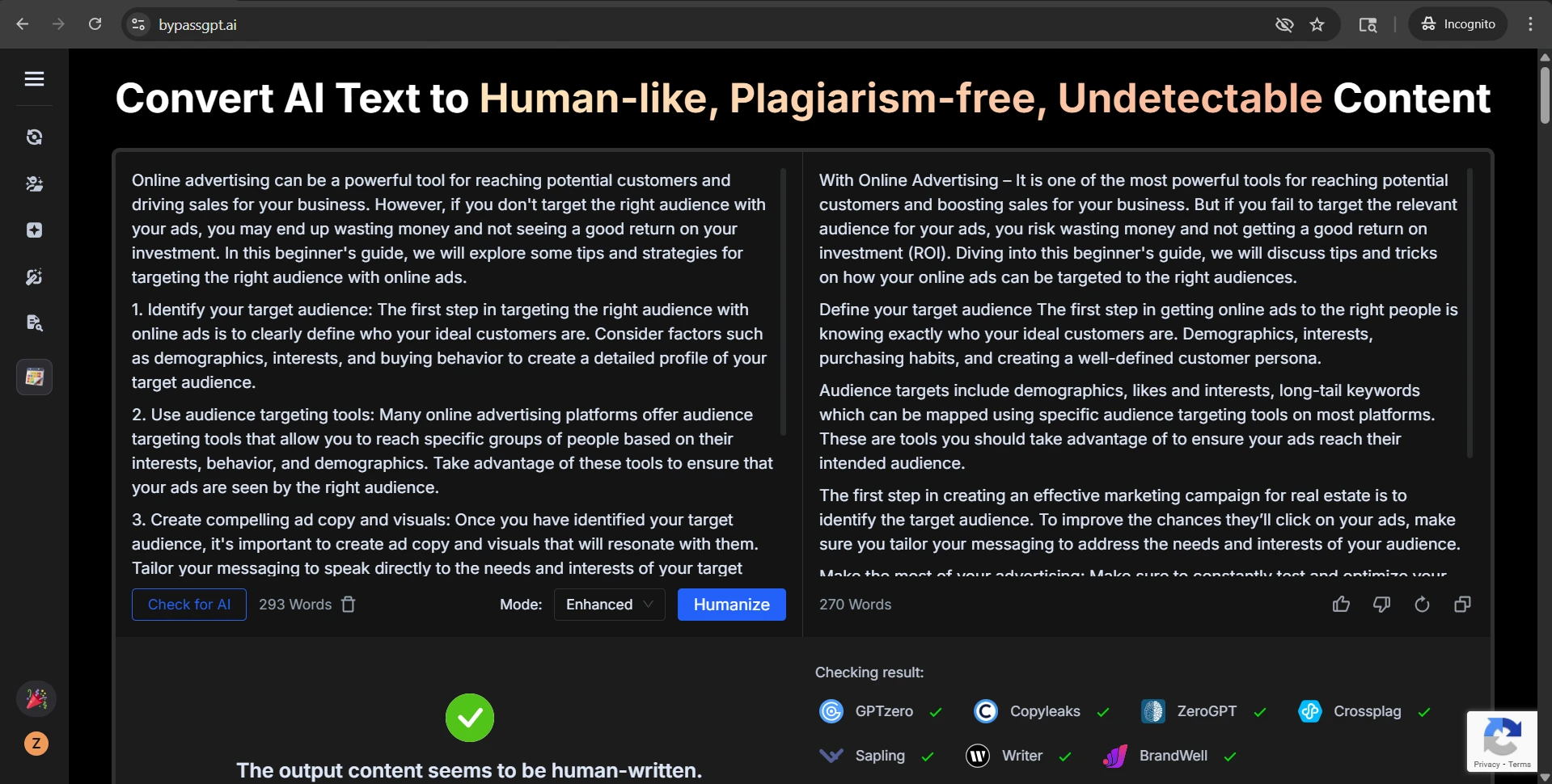
Final takeaway
So, how effective is BypassGPT.ai at bypassing GPTZero.me? Based on this 100-sample test, the honest answer is effective, but unreliable. It produced many strong wins and more than a few perfect-looking passes. But it also produced enough low scores, zero-score failures, and structural problems to make blind trust a mistake.
For readers, students, and publishers, the bigger lesson is this: detector evasion is not the same thing as writing quality. A rewrite can look human to a scanner while becoming worse on the page. If a tool removes numbering, muddies headings, swaps precise words for slang, or introduces broken phrasing, the detector score stops being the whole story. This dataset suggests that BypassGPT can beat GPTZero often enough to be interesting, but not consistently enough to be called dependable.