![[100 Samples Test] Can BypassGPT Really Bypass Originality.ai?](/static/images/bypassgptai_vs_originalityai_featured_imagepng.webp)

Everyone loves the idea of a one-click rewrite that turns obvious AI text into something that feels natural, safe, and human. But once you stop looking at marketing claims and start looking at real outputs, the question becomes sharper: does the tool work consistently, or does it only work often enough to seem convincing? To answer that, we reviewed 100 BypassGPT rewrites and checked how those rewrites scored in Originality.ai. The detector score was converted into a human score, so a higher number means the rewritten text looked more human to the detector.
What This Test Actually Measured
This was not a one-off anecdote built around a single lucky example. The dataset contained 100 original passages, their BypassGPT rewrites, and the final human score assigned after checking the rewritten version. That matters because a tool can look impressive when one sample passes. What matters to students, writers, and anyone publishing online is whether it keeps passing across many different topics.
There is one more detail worth keeping in mind. The average tells us the overall center of the scores, while the median is simply the middle score once all 100 samples are sorted from low to high. Using both helps avoid being misled by a few outliers.
Also Read: Can Sapling AI Detect BypassGPT AI?
Key findings from the 100-sample dataset
- Average human score: 49.0%
- Median human score: 49.5%
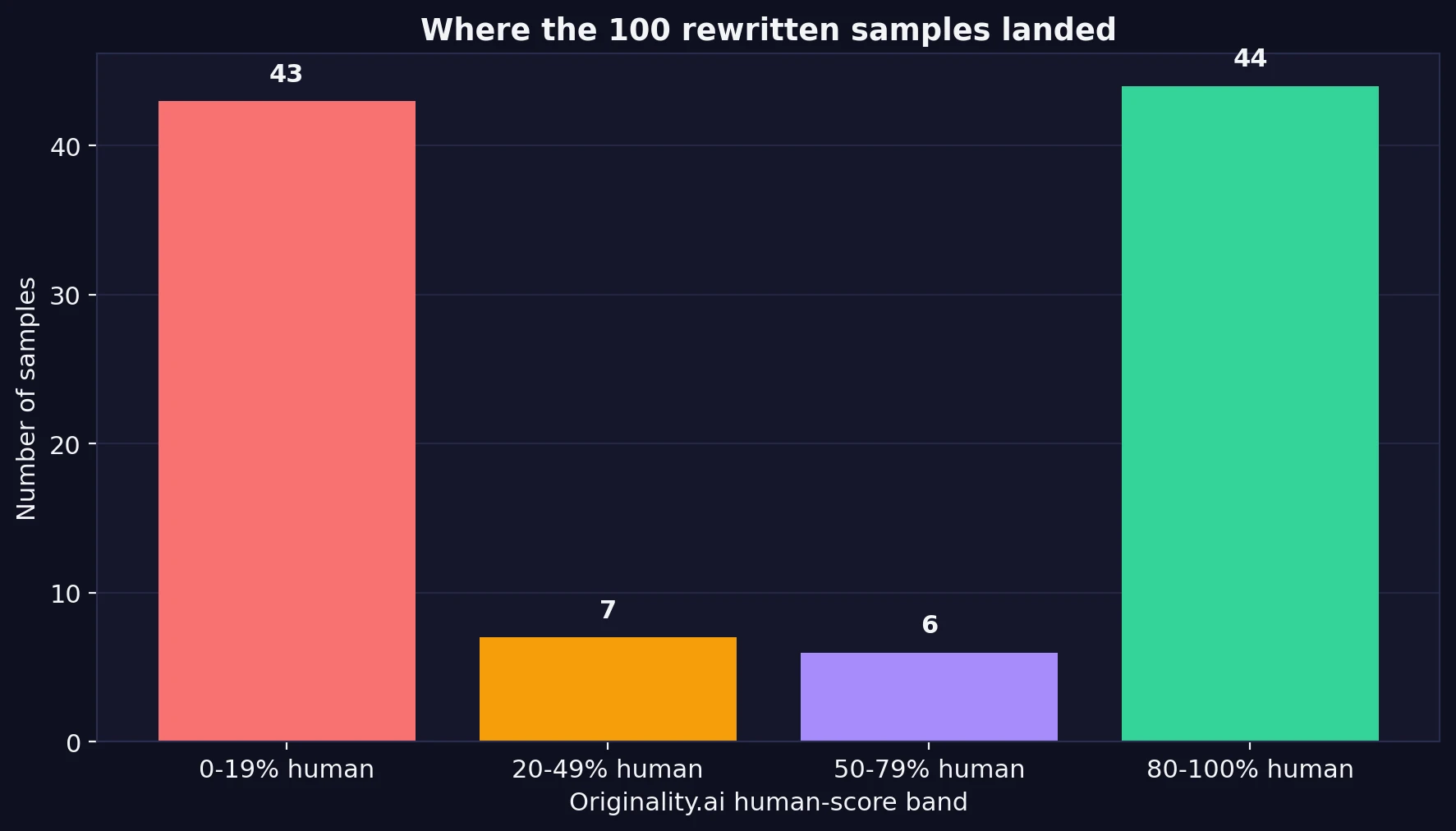
- Samples scoring 80%+ human: 44 out of 100
- Samples scoring below 20% human: 43 out of 100
- Samples clearing the 50% mark: 50 out of 100
- Structured list-style samples that lost their bullets or numbering: 38 out of 38
The First Big Surprise: The Results Split Into Two Camps
If BypassGPT were steadily reliable, most samples would gather somewhere in the middle-to-high range. That is not what happened. Instead, the test results were sharply divided. Almost half of the samples landed in the 80% to 100% human range, which sounds strong. But almost the exact same number landed in the 0% to 19% human range, which is the opposite of what users want.
That means the tool did not behave like a dependable shield. It behaved more like a gamble. In practical terms, a student using it would not be choosing between “good” and “great” outcomes. They would be taking a coin-flip risk between a convincing pass and a very obvious failure.
Also Read: Can BypassGPT Really Slip Past ZeroGPT?
Passing Sometimes Is Not the Same as Being Dependable
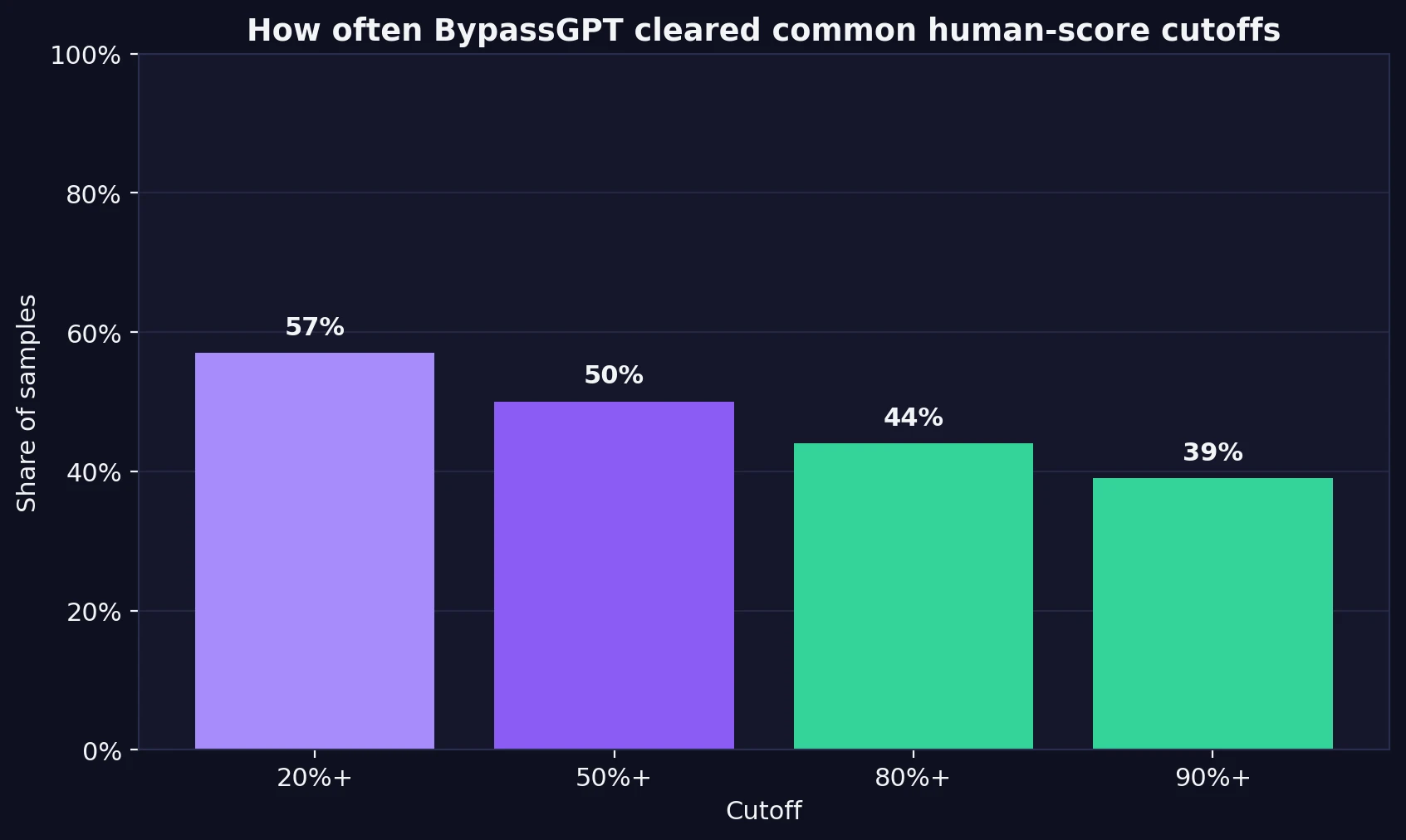
A lot of promotional pages rely on a handful of success screenshots, but success is only useful when it repeats. In this dataset, 57% of samples reached at least a 20% human score, 50% reached 50% or more, 44% reached 80% or more, and just 39% reached 90% or more.
That may sound decent at first glance, until you think about how people actually use these tools. If you are submitting coursework, publishing a blog post, or sending writing to a client, “works on four out of ten tries” is not reassuring. It means failure is common enough that every single output still needs to be checked carefully.
Also Read: [STUDY] Can BypassGPT.ai Really Bypass Copyleaks?
Shorter Text Had a Better Chance. Longer Text Often Fell Apart.
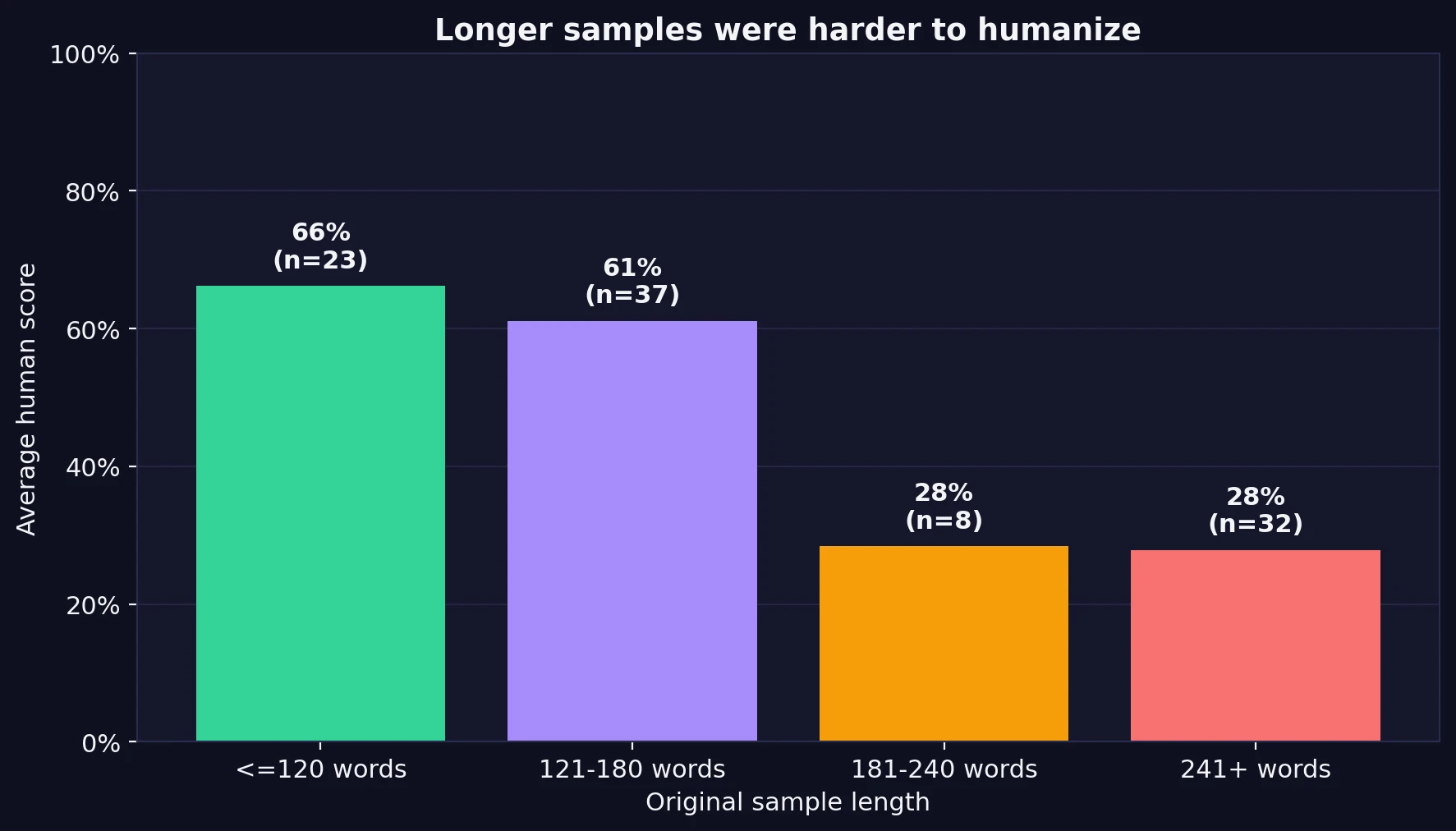
This was one of the clearest patterns in the data. Rewrites based on shorter passages did much better than rewrites based on longer ones. Samples with 120 words or fewer averaged a 66% human score. Samples between 121 and 180 words still held up reasonably well at 61%. But once the original text moved past 180 words, the average human score dropped hard to around 28%.
That drop matters because many real assignments, blog sections, and article introductions are longer than a short paragraph. A tool that works mainly on short chunks may still be useful for isolated lines, but it becomes much less convincing when asked to rewrite bigger blocks of text while preserving natural flow.
Also Read: BypassGPT.ai vs Turnitin: My 100-Sample Test Shows Why “Humanized” Text Is Still a Gamble
The Detector Score Is Only Half the Story
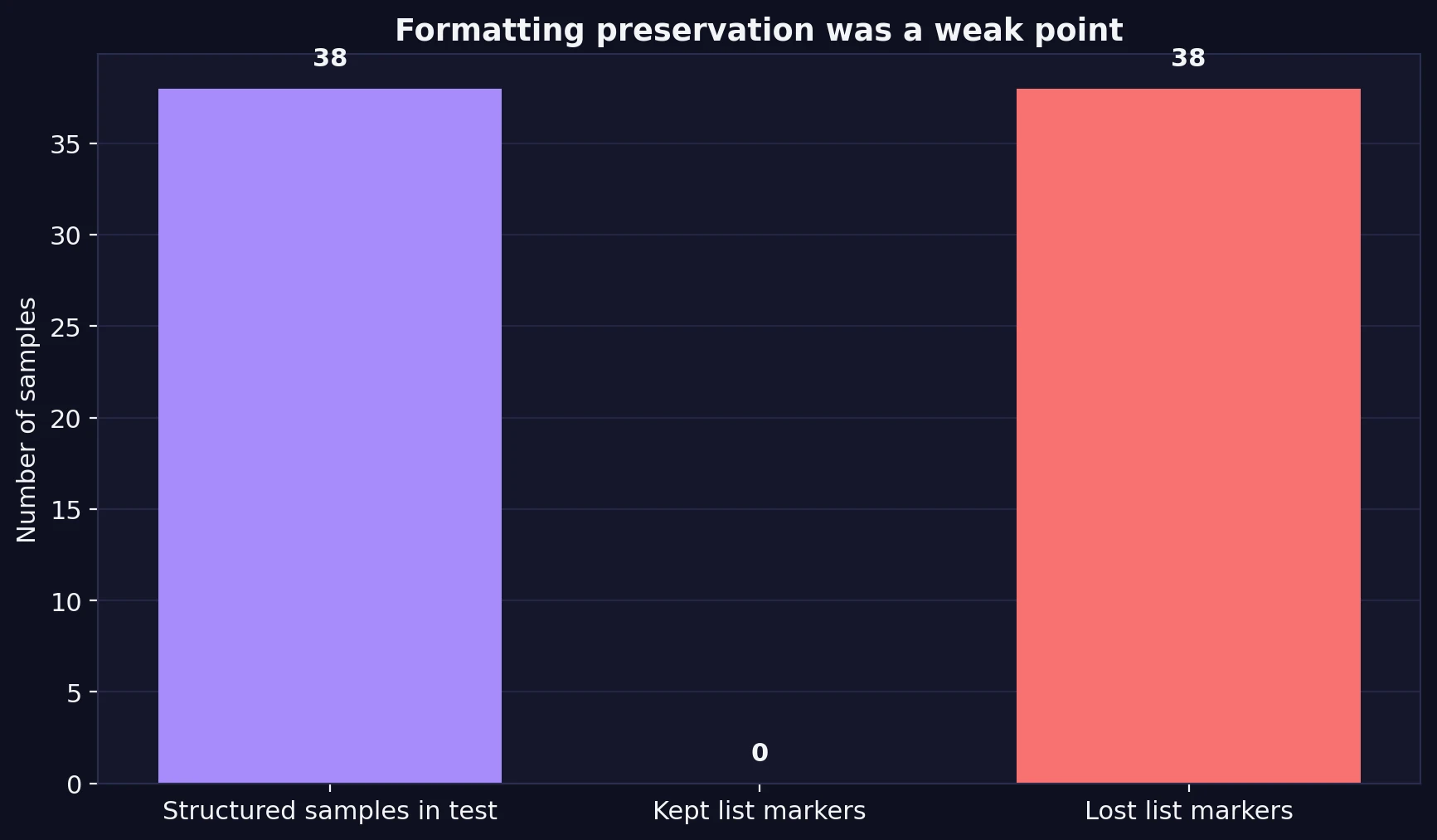
Even when a rewrite scored well, the rewritten text was not always clean. The CSV review showed a second problem that pure scoring misses: format and structure often got damaged in the rewrite process.
In the dataset, 38 samples used a clear list structure, such as numbered tips or bulleted points. In every one of those cases, the rewrite stripped away the original list markers. Sometimes the order was still somewhat visible, but the visual structure was gone. That is a bigger issue than it sounds. In how-to content, study notes, and step-by-step explanations, numbering does real work. It shows sequence, importance, and hierarchy. Once that disappears, the text can feel flatter and harder to follow.
Manual review also uncovered recurring quality problems that a simple score cannot fully capture. Some rewrites weakened headings, turning clean section labels into plain text. Some inserted awkward or broken phrases that were never in the source. A few drifted away from the original meaning by introducing extra ideas, changing emphasis, or creating sentences that sounded unnatural rather than human. In other words, a higher detector score did not always equal a better rewrite.
Also Read: Can BypassGPT Outsmart QuillBot’s AI Detector? I Tested 100 Rewrites to Find Out
What kind of rewrite problems showed up during review? The most common issues were easy to spot once the outputs were compared side by side: list numbers disappearing, headings being softened or flattened, random wording shifts, occasional sentence fragments, and phrases that felt oddly stitched together. That means a rewrite can look “more human” to a detector while still becoming less useful for an actual reader.
What the Screenshots Reveal
The screenshots make the split behavior easy to see. Some BypassGPT outputs were smooth enough to earn strong human scores from Originality.ai. Others still triggered confident AI judgments. Looking at the rewrites themselves, the weaker examples often sounded strained, dropped clean formatting, or introduced wording that no careful human writer would choose.
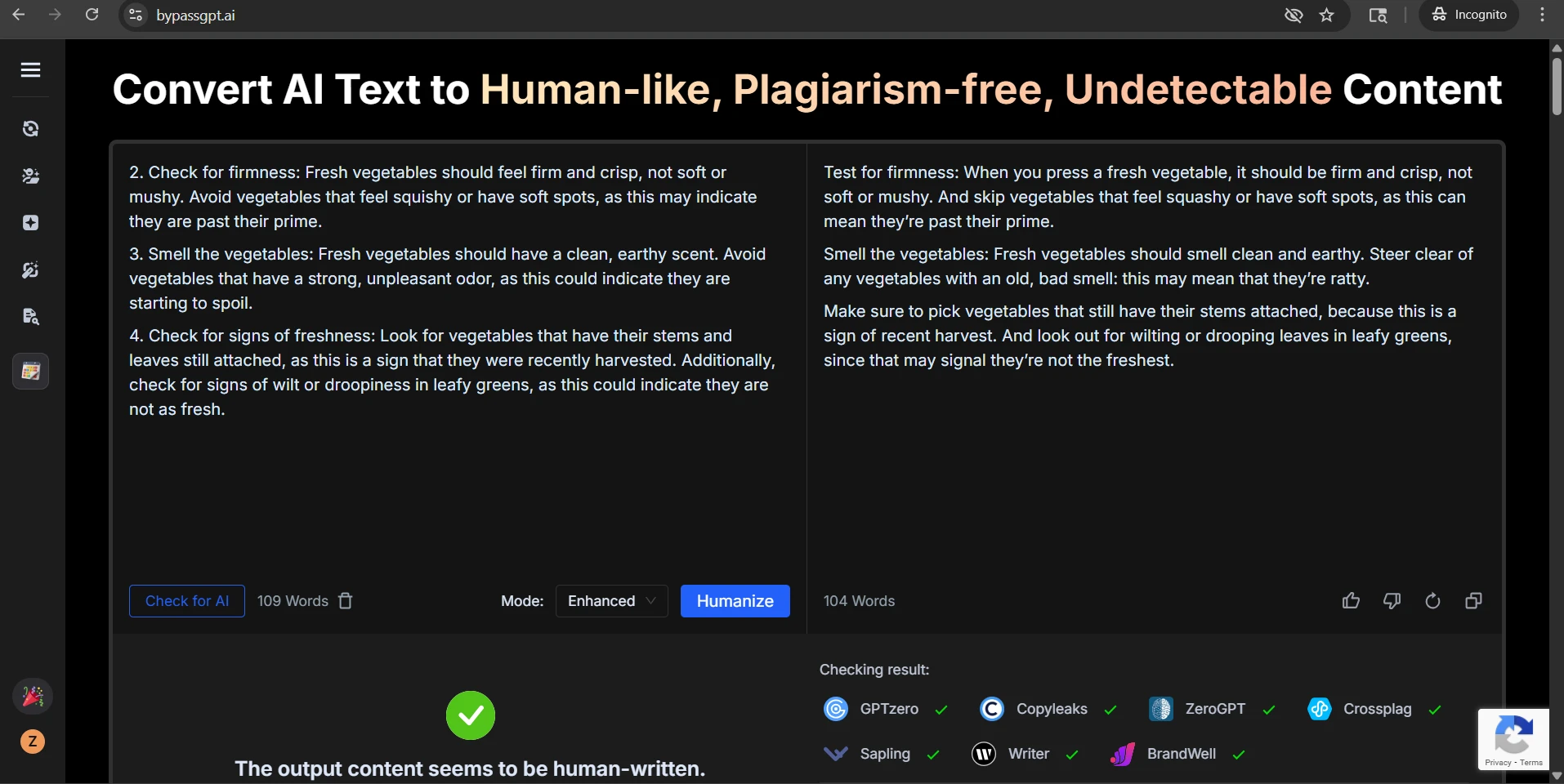
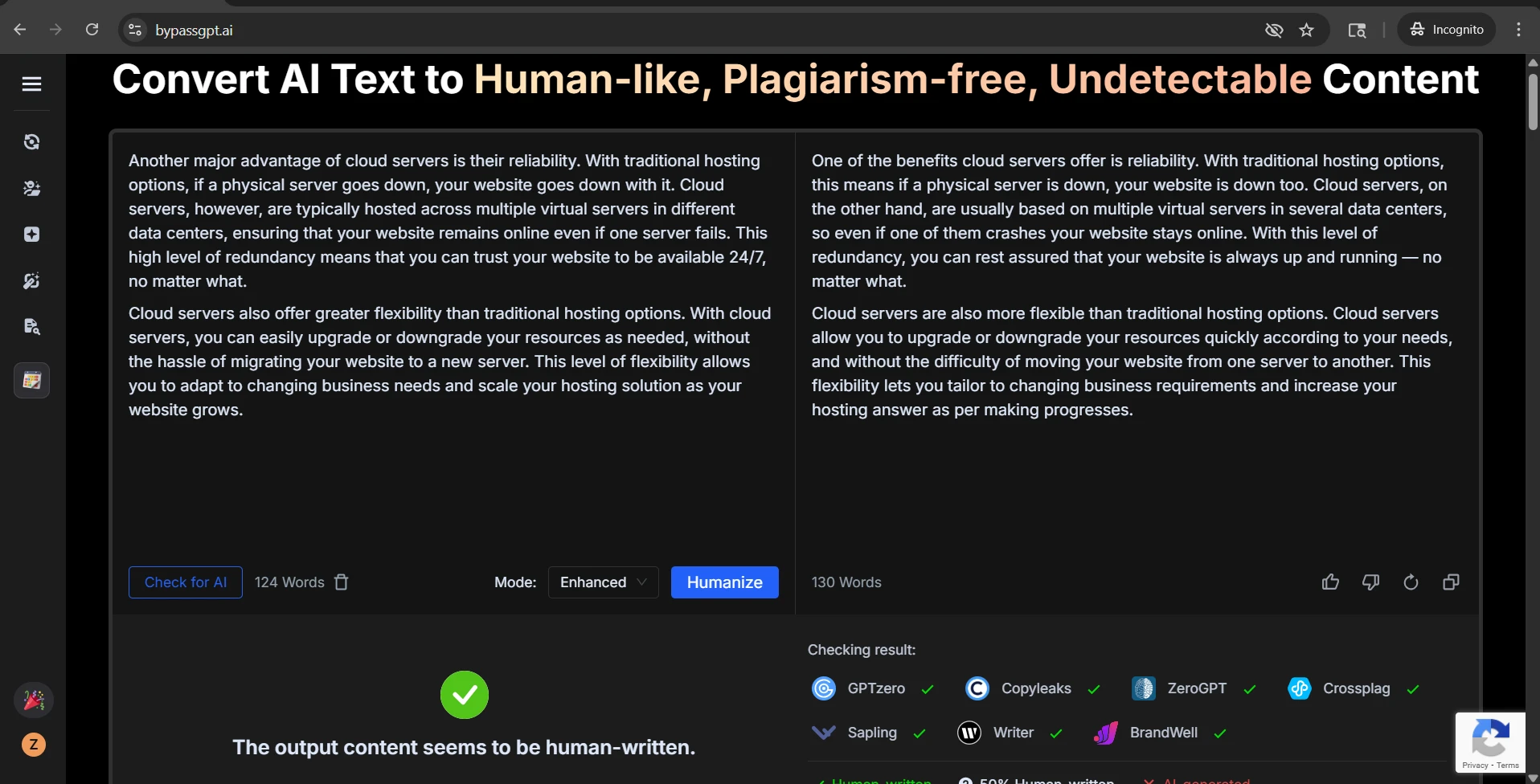
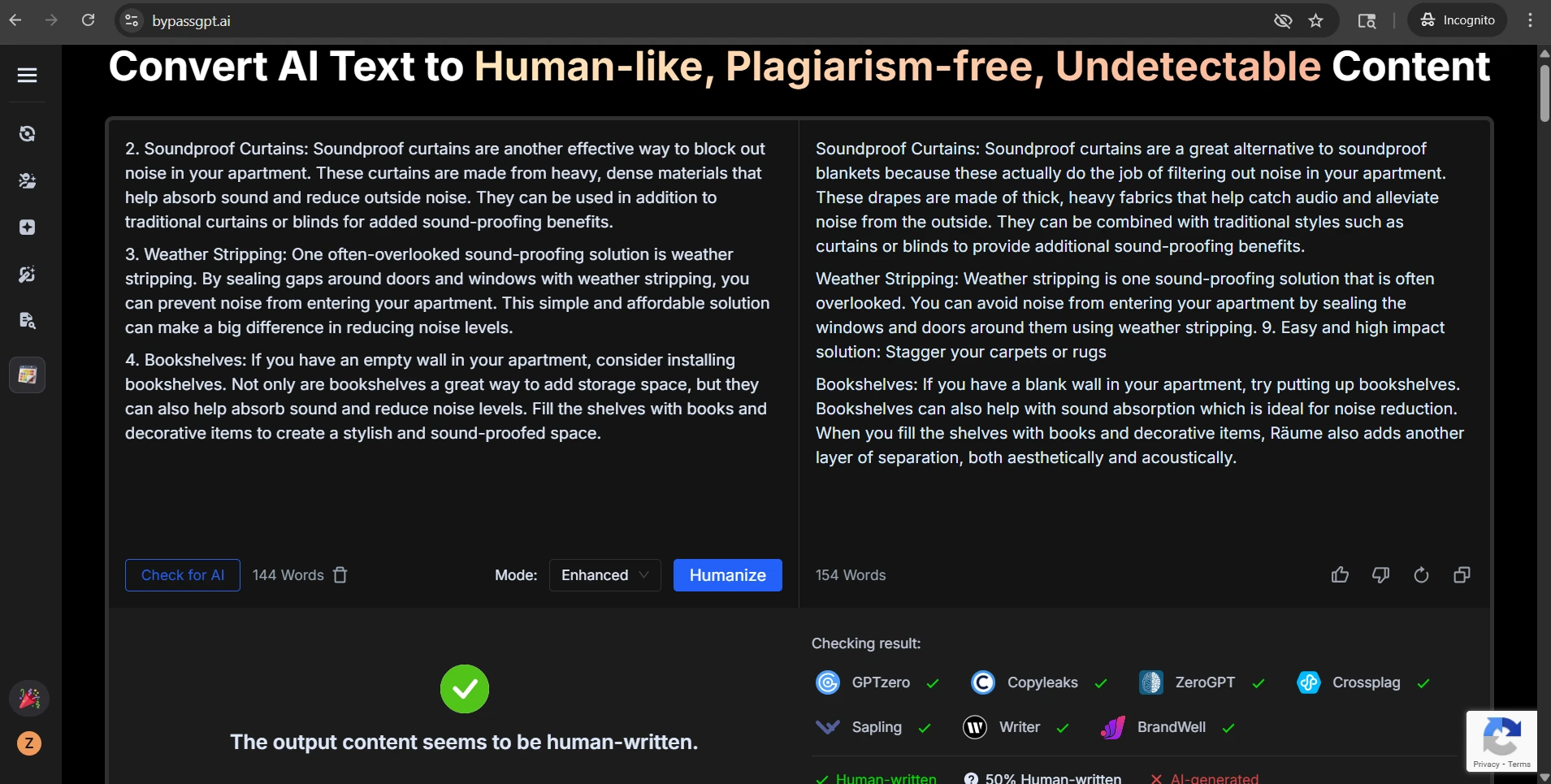
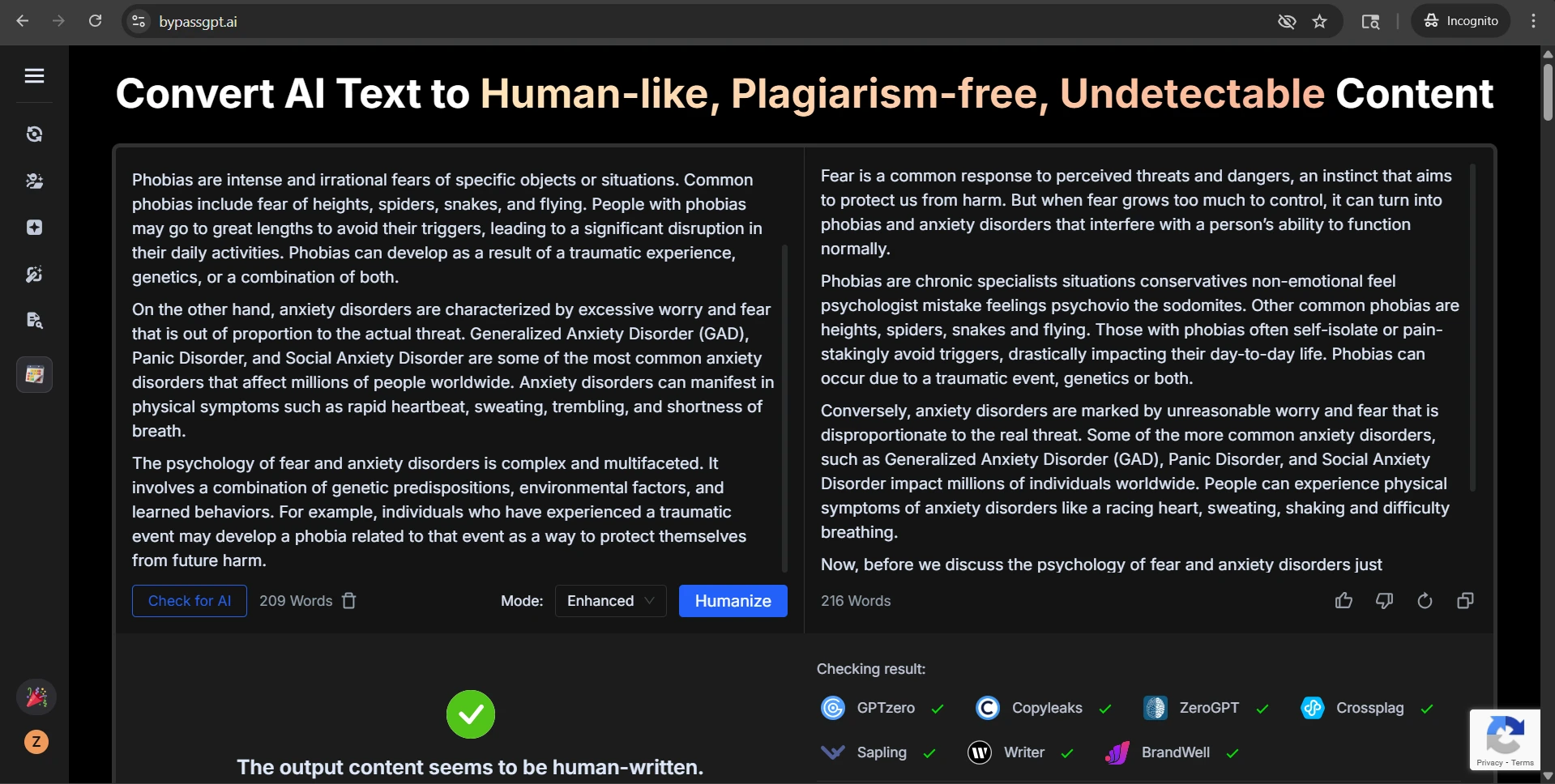
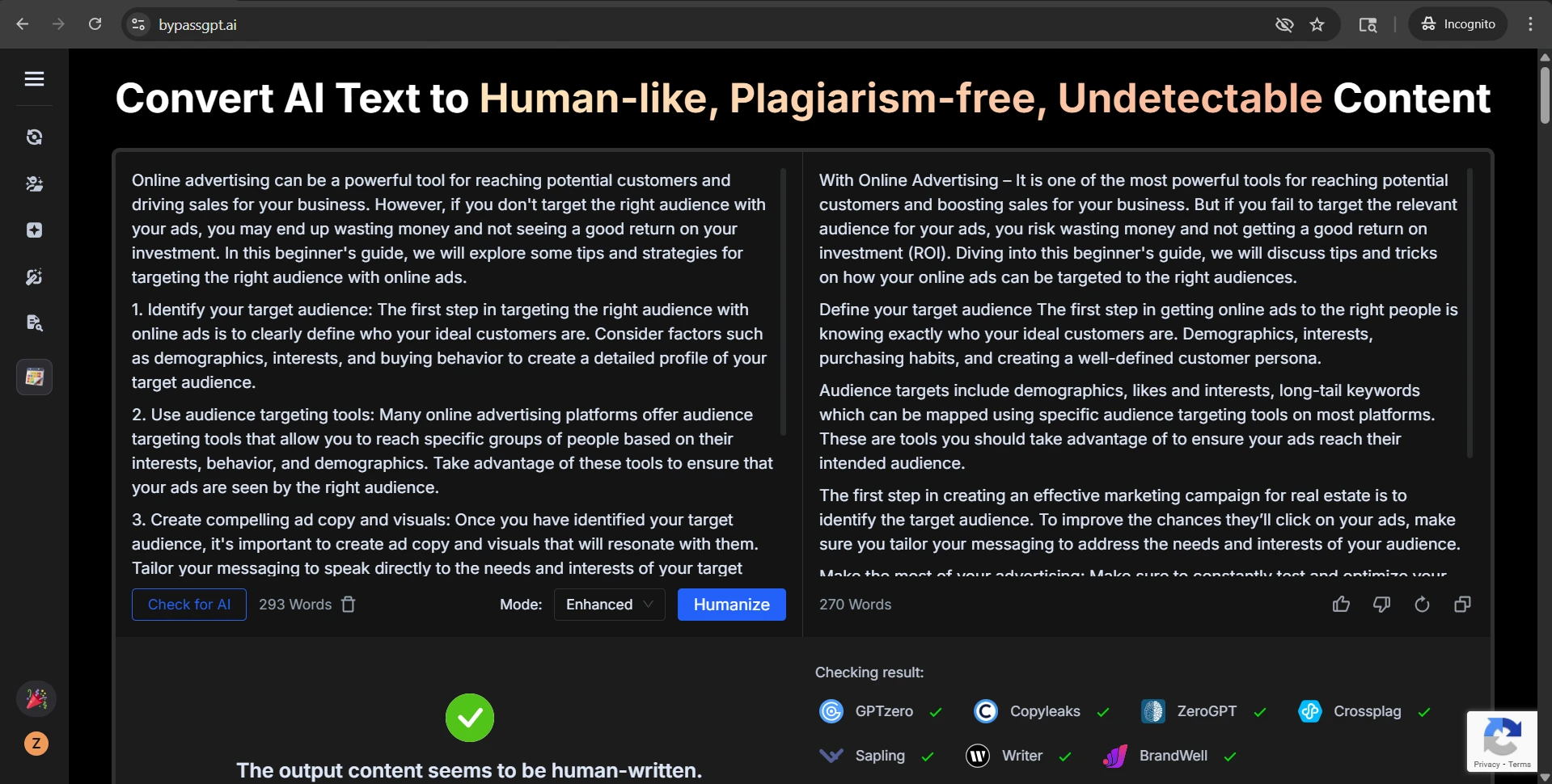
The Originality.ai screenshots tell the same story from the detector side. Some outputs were treated as highly human. Others were flagged with very high confidence as AI. That kind of swing is exactly why consistency matters more than a few handpicked wins.
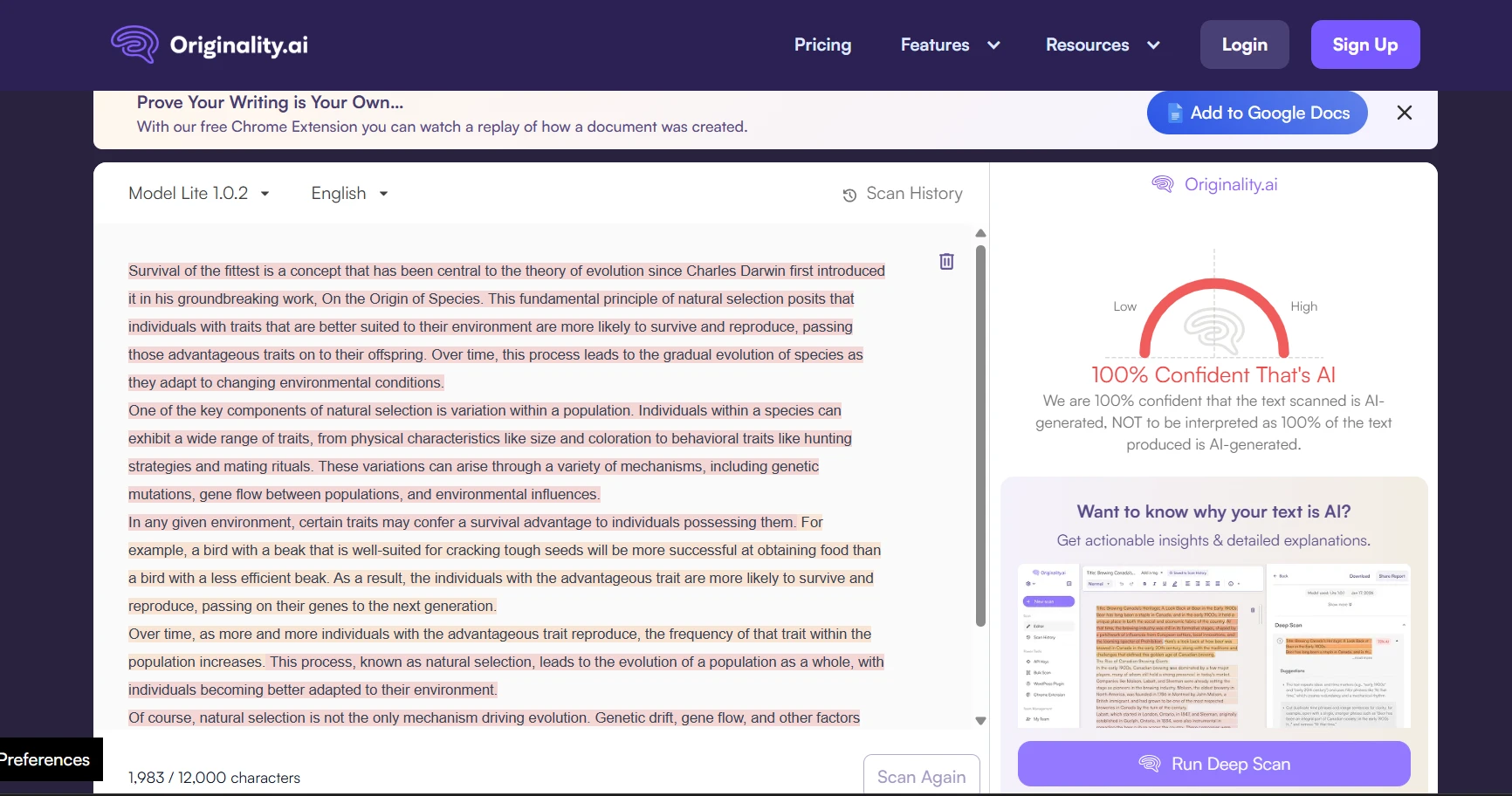
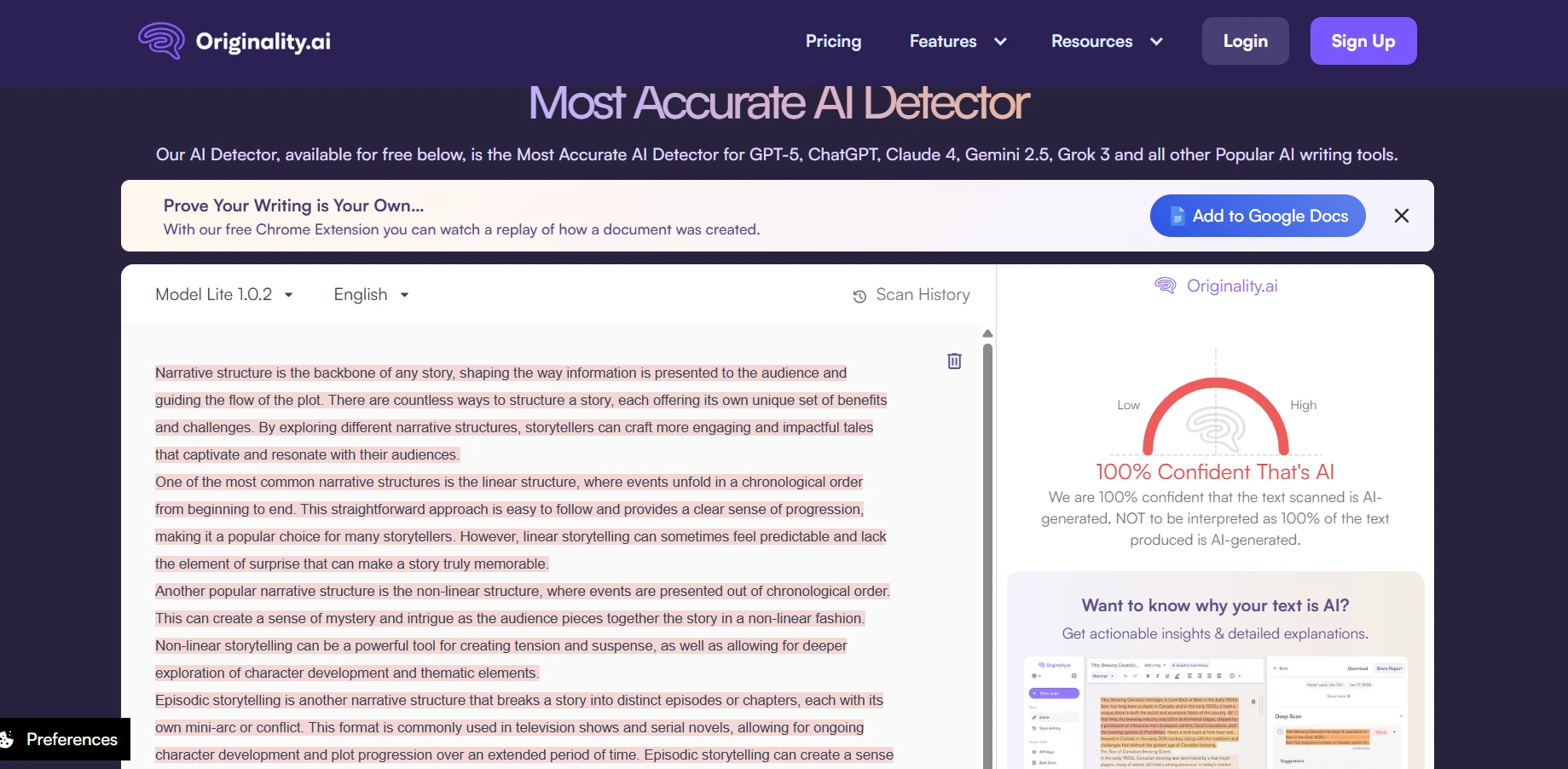
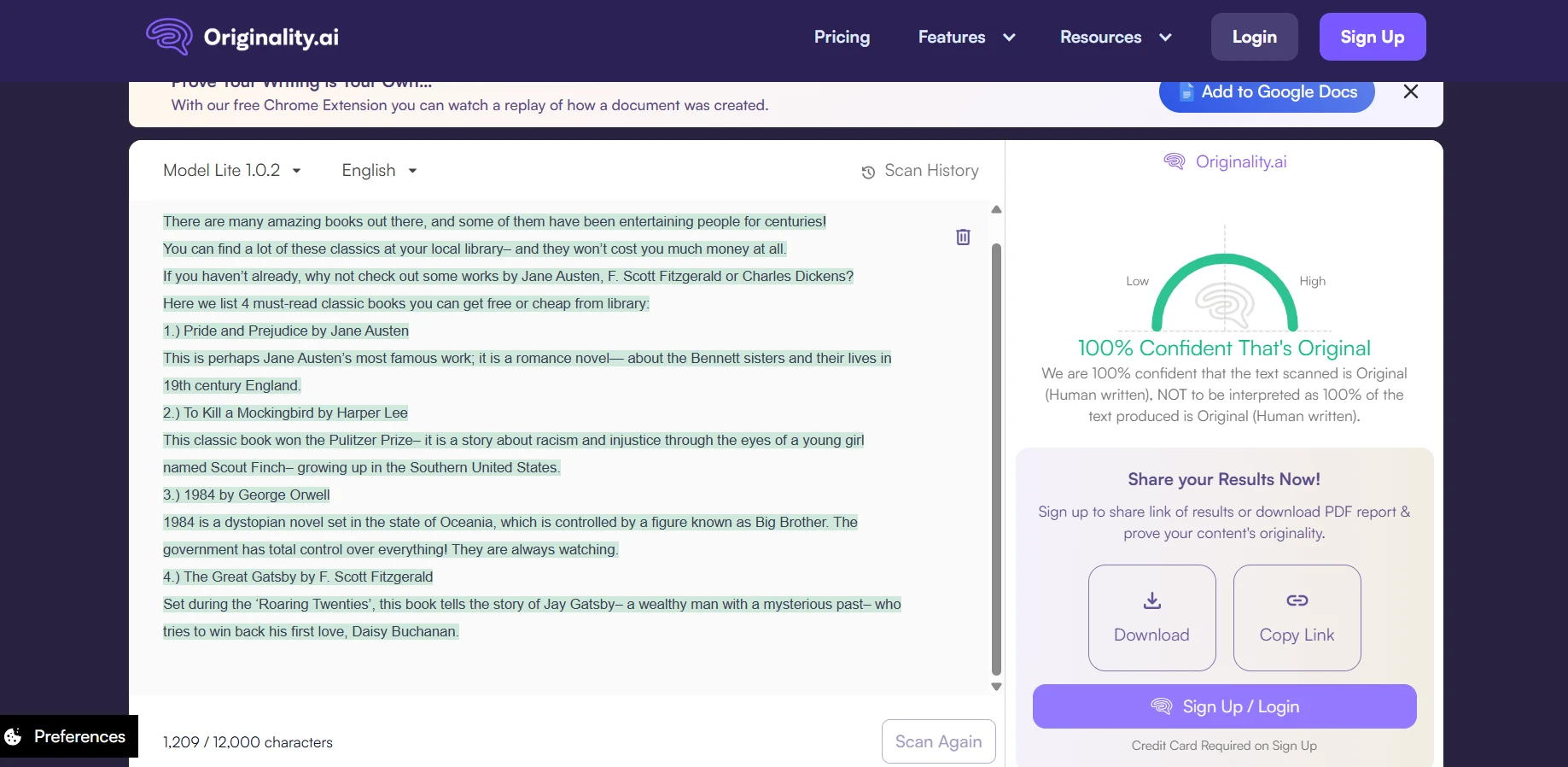
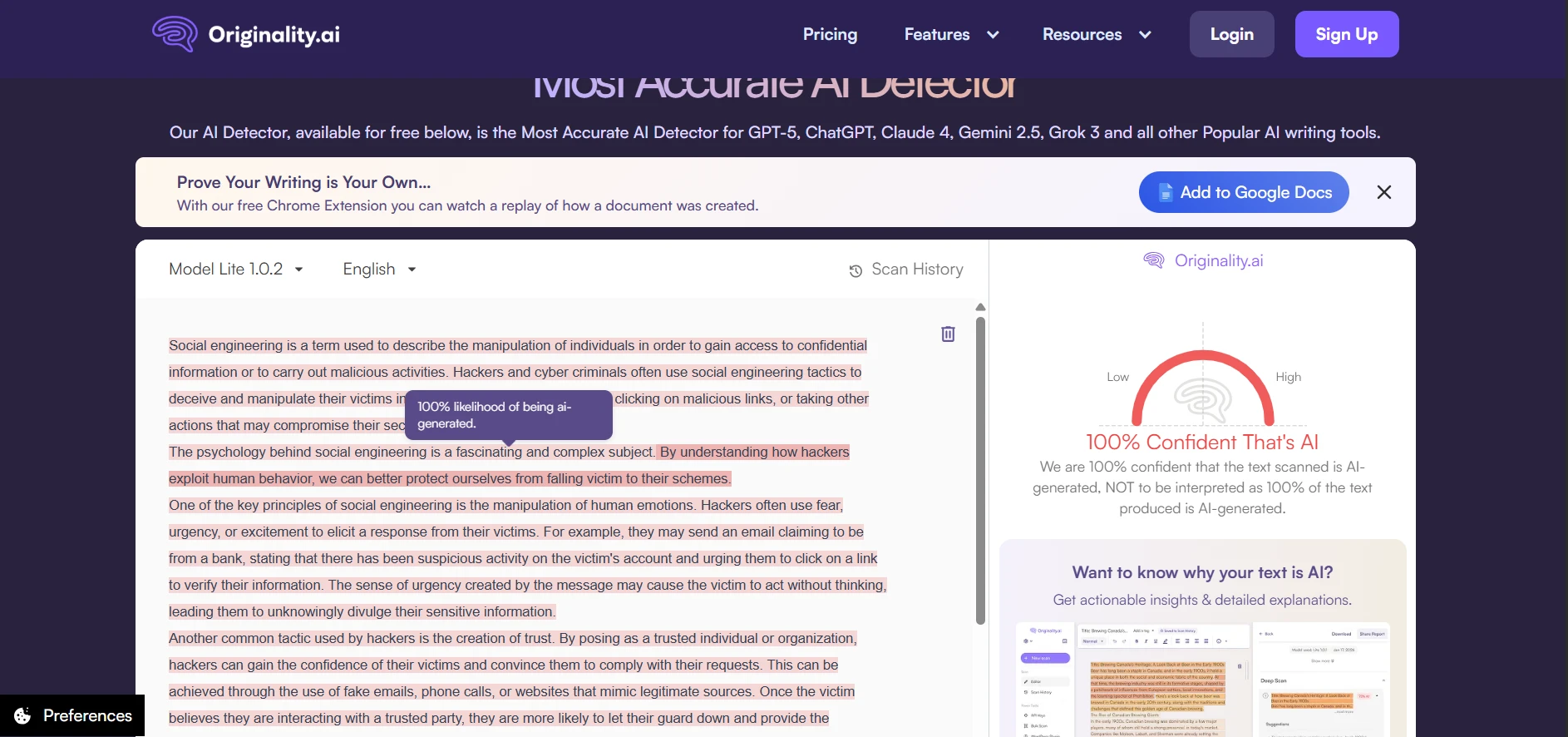
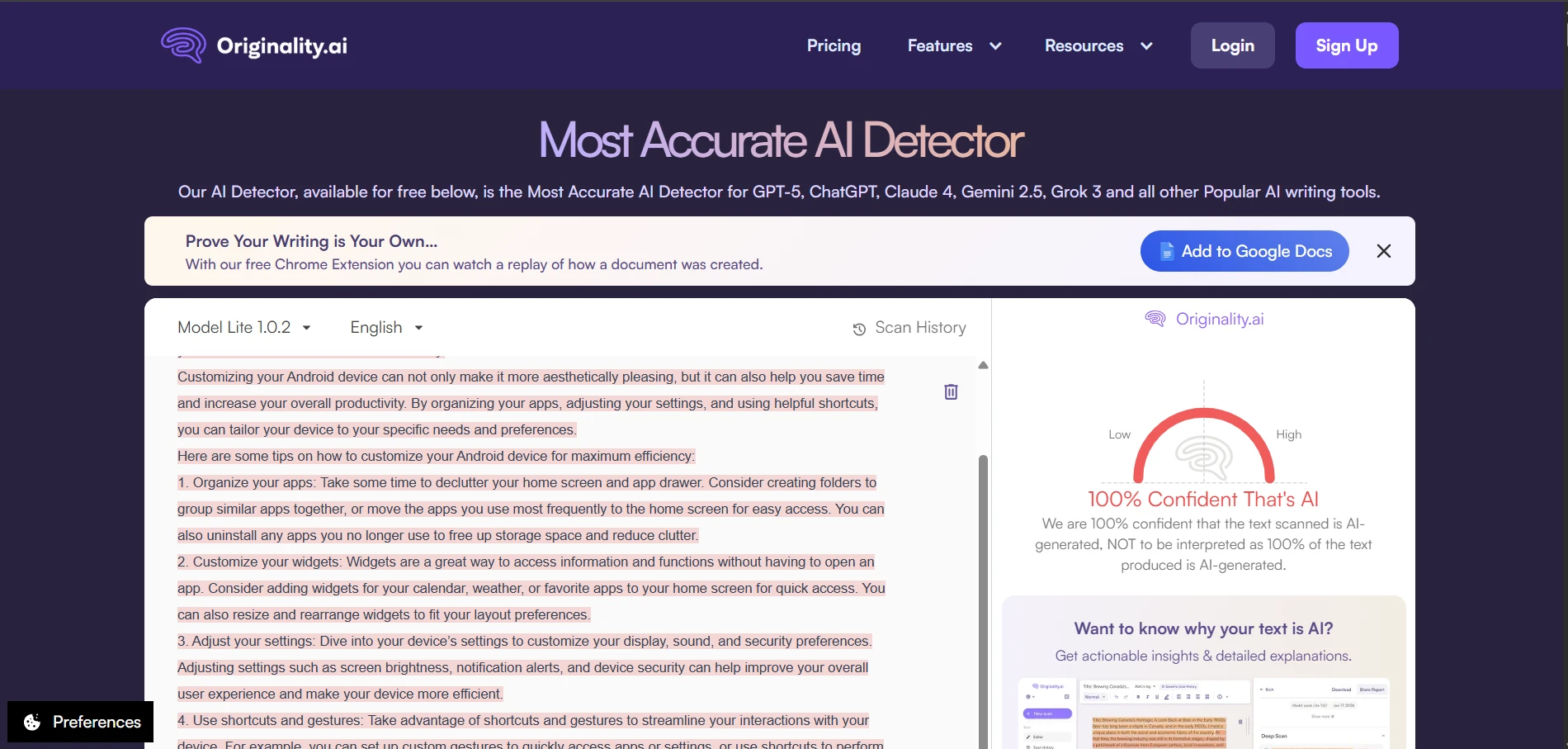
The Real Takeaway
BypassGPT is not a complete failure. It clearly produced some rewrites that looked human enough to score very well in Originality.ai. But this test also shows that those wins were not stable enough to treat the tool as reliable. With an average human score of just 49%, a clean pass rate of only 44% at the 80% mark, and a sharp drop on longer samples, the overall picture is mixed at best.
For students especially, that creates two separate risks. The first is obvious: the text may still get flagged. The second is quieter but just as important: the rewrite may damage structure, tone, and clarity even when the score looks better. A tool that removes numbering, weakens headings, and occasionally introduces awkward phrasing is not simply “humanizing” the text. In some cases, it is trading one problem for another.
Bottom line: BypassGPT can sometimes bypass Originality.ai, but the 100-sample dataset suggests it does so inconsistently. It works more like a gamble than a guarantee, and the quality cost of the rewrite itself should not be ignored.