

Students are constantly sold a simple promise: run AI-written text through a “humanizer” and the detector will stop noticing. My 100-sample dataset tells a much messier story. BypassGPT sometimes produces rewrites that Turnitin reads as highly human, but it is far from dependable. Just as importantly, the rewrite process often damages the writing itself by stripping structure, flattening lists, and introducing awkward phrasing.
How This Test Worked
I analyzed 100 paired samples from a CSV file. Each row contained an original passage, a BypassGPT rewrite, and a Turnitin-based score that I converted into a human score. In this article, 1.0 means the rewrite looked fully human, while 0.0 means it looked fully AI-generated.
That lets us judge two things at once: how often the rewrites seemed human to Turnitin, and what BypassGPT did to the original text while chasing that result.
The headline numbers
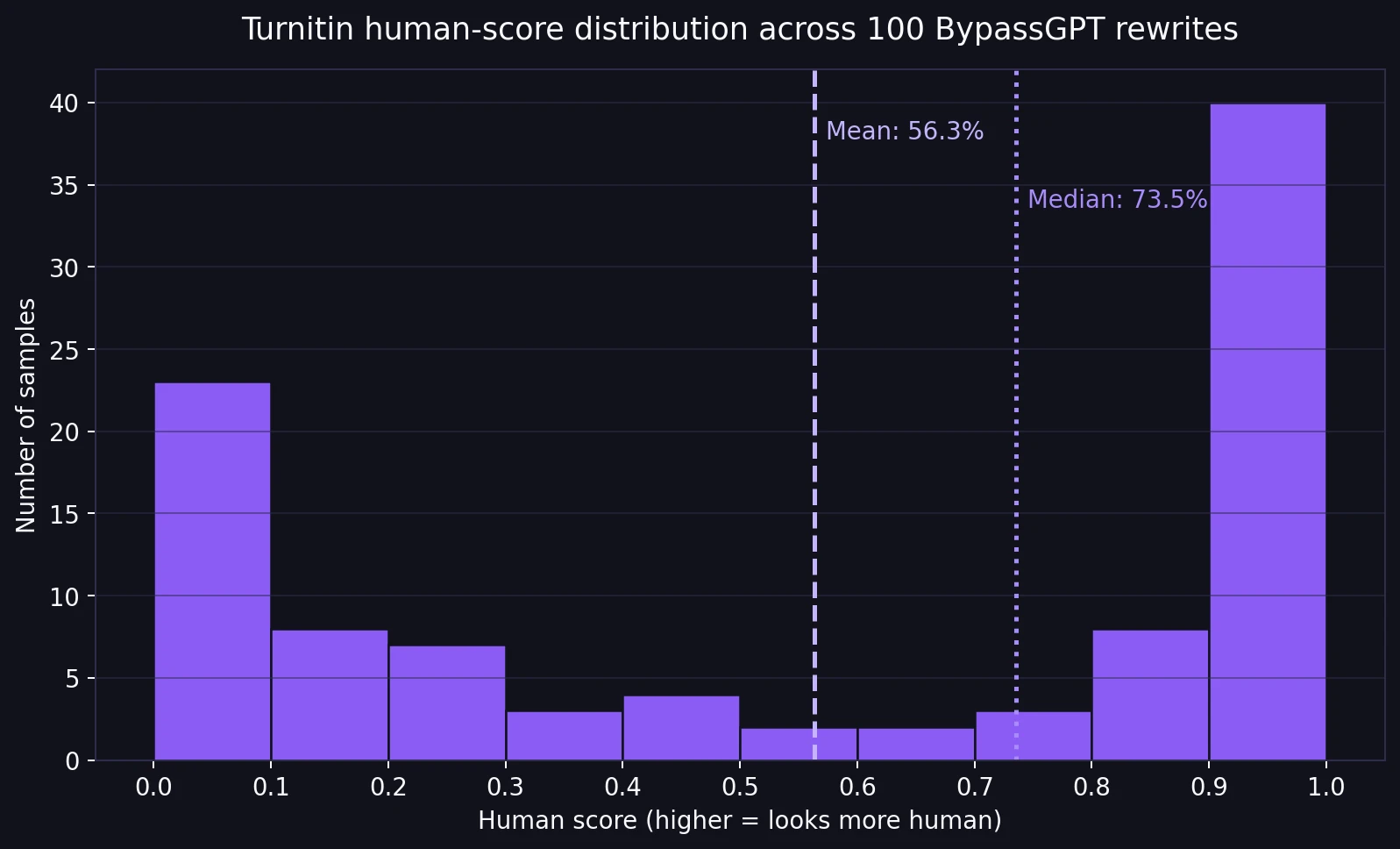
- Average human score: 56.3%
- Median human score: 73.5% (the middle score when all 100 results are lined up)
- Strong passes: 48 of 100 rewrites scored at least 80% human
- Still risky: 45 of 100 rewrites stayed below 50% human
The Core Result: BypassGPT Was Not Consistent
The distribution chart tells the story better than any marketing claim could. The scores were not clustered around a safe middle. They were split into extremes. 19 samples scored a perfect 100% human, but 21 samples scored 0%. That means this tool did not behave like a reliable upgrade. It behaved like a high-variance bet.
For students, inconsistency is the real problem. A tool that works on one paragraph and collapses on the next is hard to trust, especially when the stakes involve a classroom, plagiarism checks, or academic suspicion.
Also Read: Can Bypassgpt AI bypass Quillbot's AI detector?
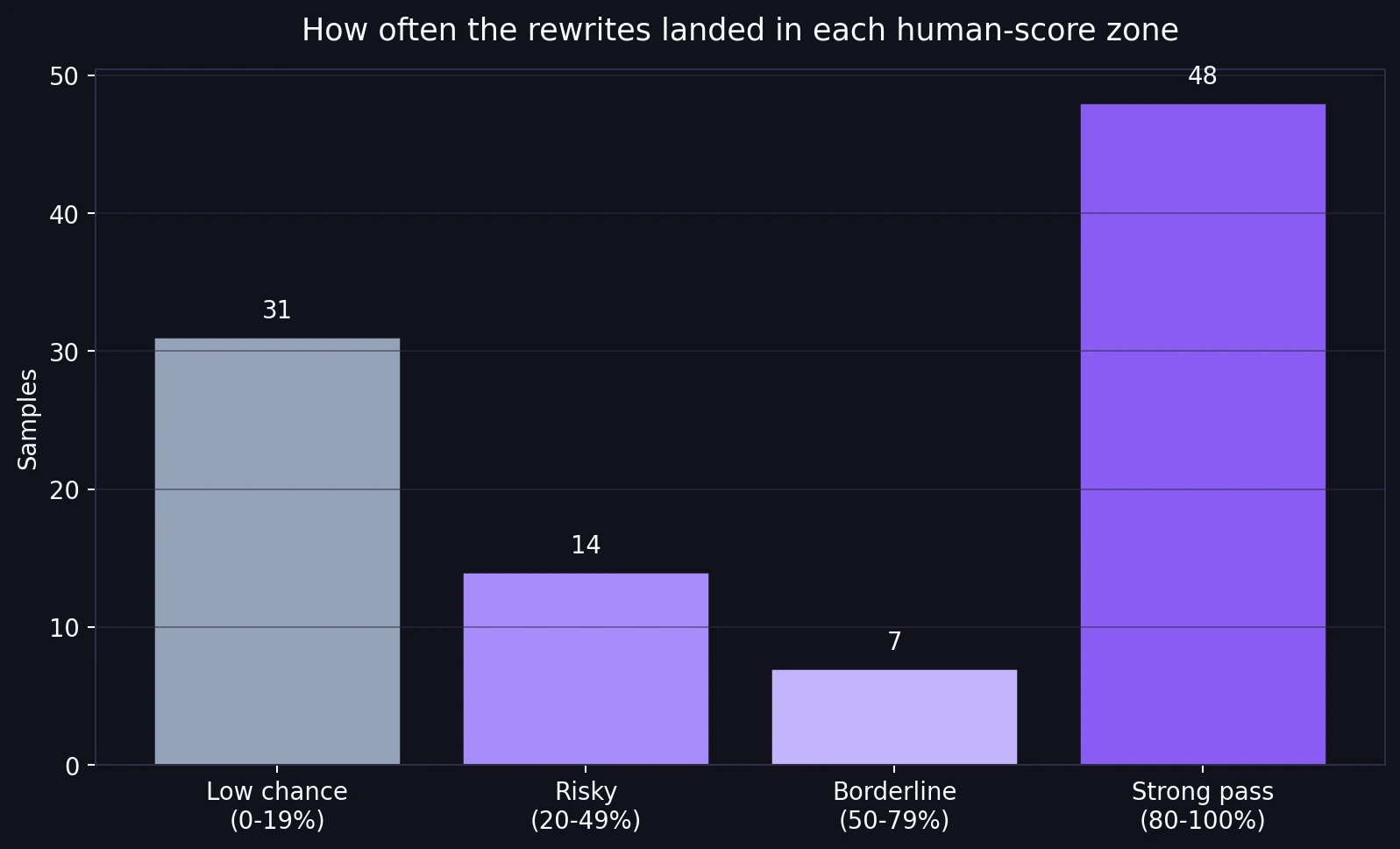
The score buckets make that split even clearer. 48% of the rewrites landed in the strong zone at 80% human or above. That sounds impressive until you place it next to the other side of the chart: 45% of samples still stayed below 50% human, including 31% below 20%. In plain language, BypassGPT was not solving the problem across the board. It was producing wins and failures side by side.
Also Read: Can BypassGPT Outsmart Grammarly’s AI Detector?
The Bigger Problem: The Rewrites Often Broke the Structure
Detector scores are only half the story. Once I read through the original and rewritten passages, I found a pattern that matters just as much for students: BypassGPT often damaged formatting and organization.
Whenever the original used list structure, the rewrite removed it. In this dataset, 38 samples contained bullet points or numbered items, and all 38 lost that list formatting in the rewritten version. More specifically, every one of the 36 samples with numbered sections lost the numbering entirely. The section text might stay, but the order and visual hierarchy were gone.
That is not a minor cosmetic issue. Lists are how students present steps, comparisons, revision notes, procedures, and explanations. If a rewrite turns “1, 2, 3” into loose prose, it changes how readable the work is. I also found heading damage. Out of 39 samples that used heading-like markers with colons, 17 came back with fewer of those markers, making the text harder to scan.
Also Read: BypassGPT.ai vs GPTZero.me: 100 Rewrite Tests Reveal What Really Happens

The wording itself could also wobble. A few low-scoring rewrites introduced broken or oddly specific phrases. One sample narrowed “smartphones” into “iPhones.” Others inserted strange wording like “most MMORP” or “I did look this up:” inside otherwise normal passages. Those moments make the output feel less like careful editing and more like unstable rewriting.
Longer Texts Had a Much Harder Time Passing
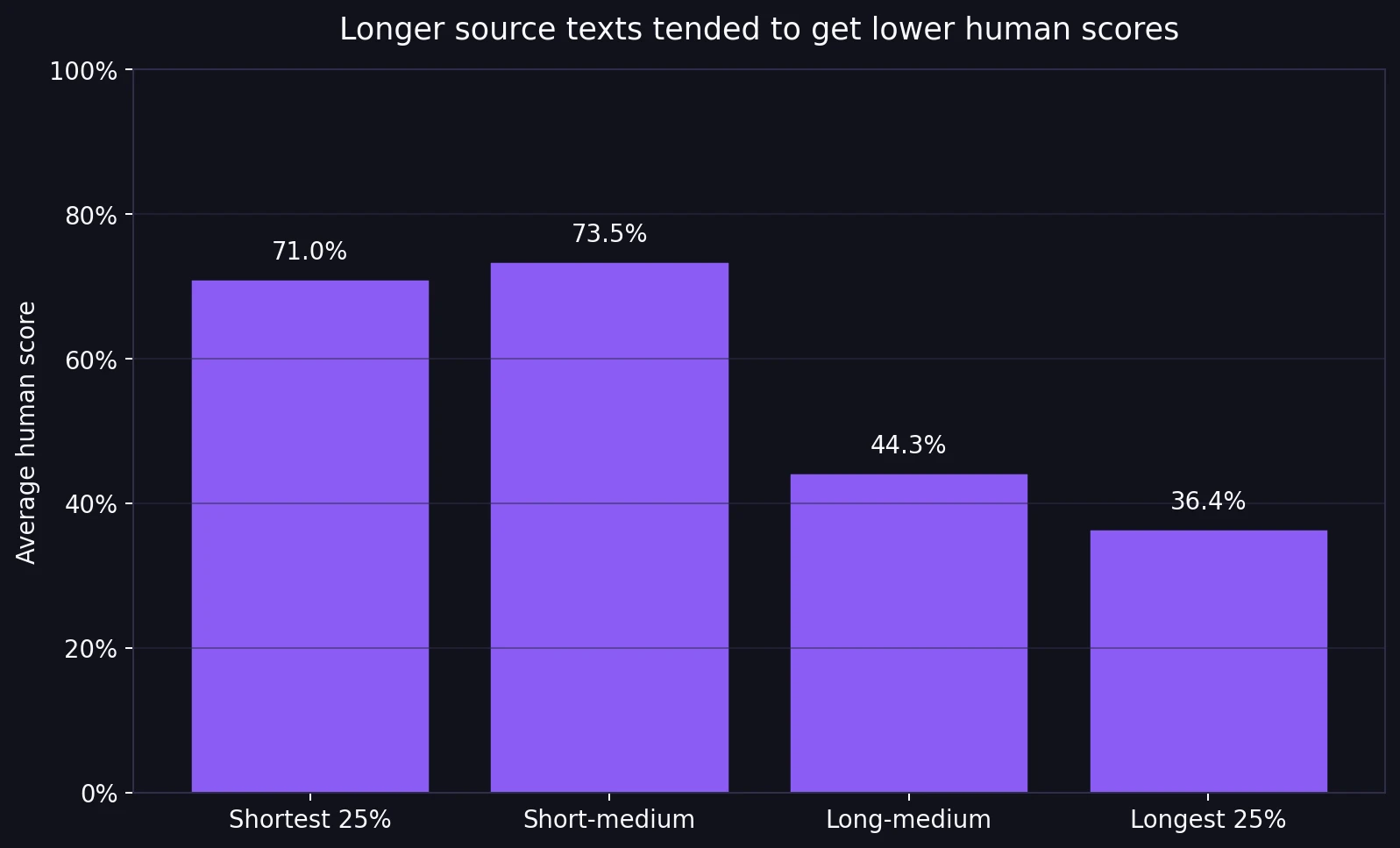
Length turned out to matter. When I sorted the dataset by original passage length, the shortest 25% of samples averaged a 71.0% human score. The longest 25% averaged only 36.4%. That is a steep drop.
This does not prove that length alone causes failure, but it does show a strong pattern in the data: the longer the source passage, the harder it was for BypassGPT to keep the rewrite convincingly human. Short passages are easier to smooth out. Longer passages have more opportunities for repetition, awkward transitions, structural damage, or unnatural phrasing to show up.
Also Read: [100 Samples Test] Can BypassGPT Really Bypass Originality.ai?
One last clue supports that reading: the overall word count barely changed on average. That suggests BypassGPT was usually swapping phrases rather than rebuilding the text from the ground up. In other words, it often changed the surface while leaving deeper structure problems behind.
Final Verdict
This dataset does not show a dependable Turnitin bypass. It shows a tool with mixed outcomes, a high failure rate, and visible side effects. Yes, some rewrites scored very well. But nearly as many still looked suspicious, and a noticeable share of the “humanized” outputs came back with weaker structure than the originals.
For students, that is the real takeaway. The question is not only whether a rewrite can raise a detector score. It is whether the rewritten text still sounds clear, keeps its structure, and holds up under real reading. Based on these 100 samples, BypassGPT.ai was too inconsistent to trust, especially on longer or more structured writing.