

A tool that promises to make AI writing look human is making a bold claim. For students, that claim matters because a “human-looking” rewrite is not useful if it still gets flagged, wrecks the formatting, or quietly changes the meaning. To see what actually happens, I tested 100 BypassGPT rewrites against QuillBot’s AI detector and tracked the results using a converted human score. In this article, a higher score means QuillBot judged the text as more human.
This test was not just about passing
It is easy to focus on one headline number and stop there. But a serious test has to ask two questions at the same time. First, does the rewrite get through the detector? Second, what does the rewrite do to the original writing? A pass is not very impressive if the tool strips list formatting, breaks headings, adds strange details, or turns a clean explanation into awkward filler.
So I looked at the 100 scores in the CSV and also reviewed the rewrites themselves. That second step matters because detector scores only tell one part of the story. They do not tell you whether the output is still clear, accurate, and usable.
Also Read: Can BypassGPT outsmart Grammarly's AI Detector?
What the dataset says at a glance
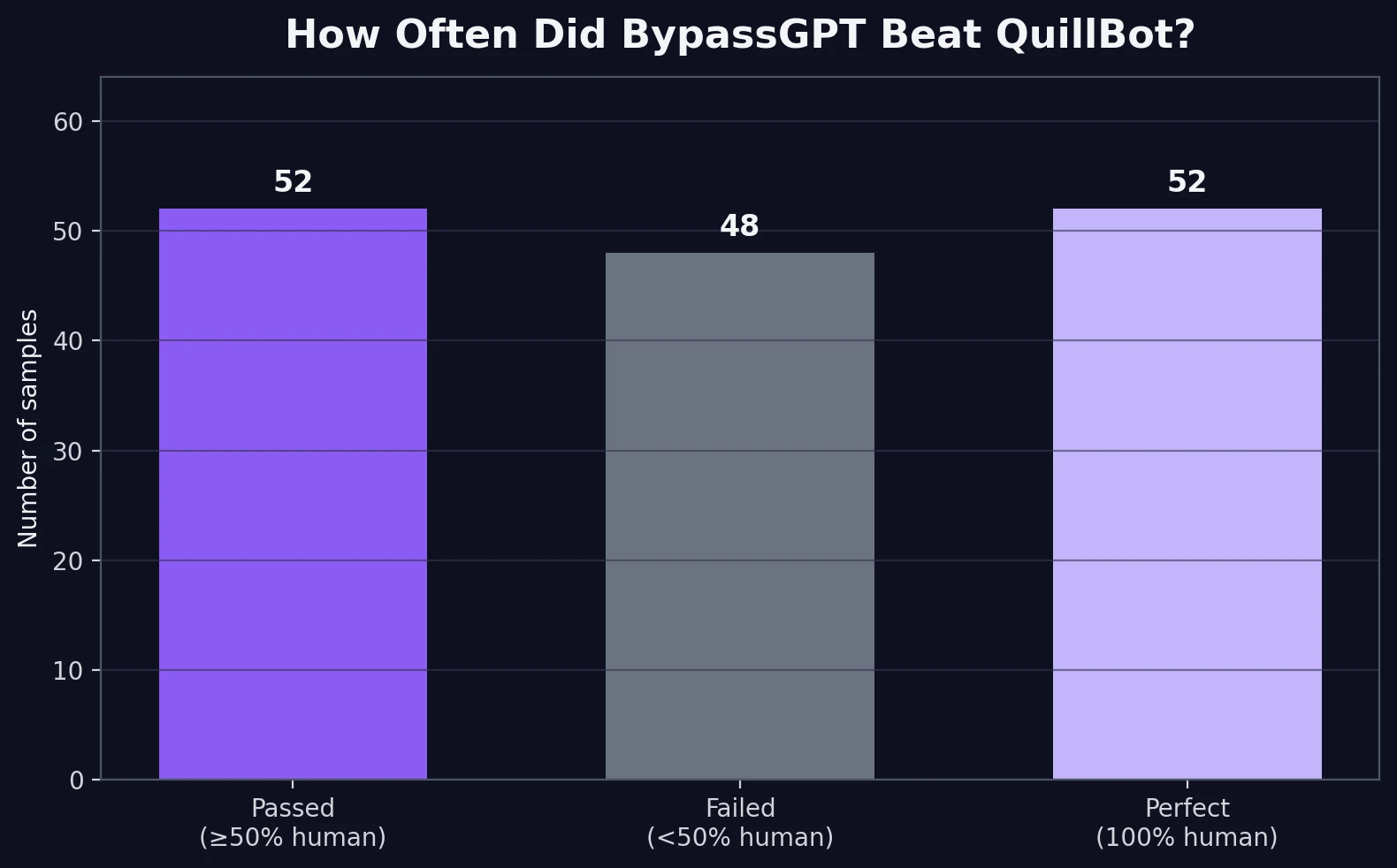
52 out of 100 rewrites earned a 100% human score from QuillBot. That is the best-case result for BypassGPT.
48 out of 100 still landed below 50% human, so nearly half of the samples did not really “bypass” the detector in a practical sense.
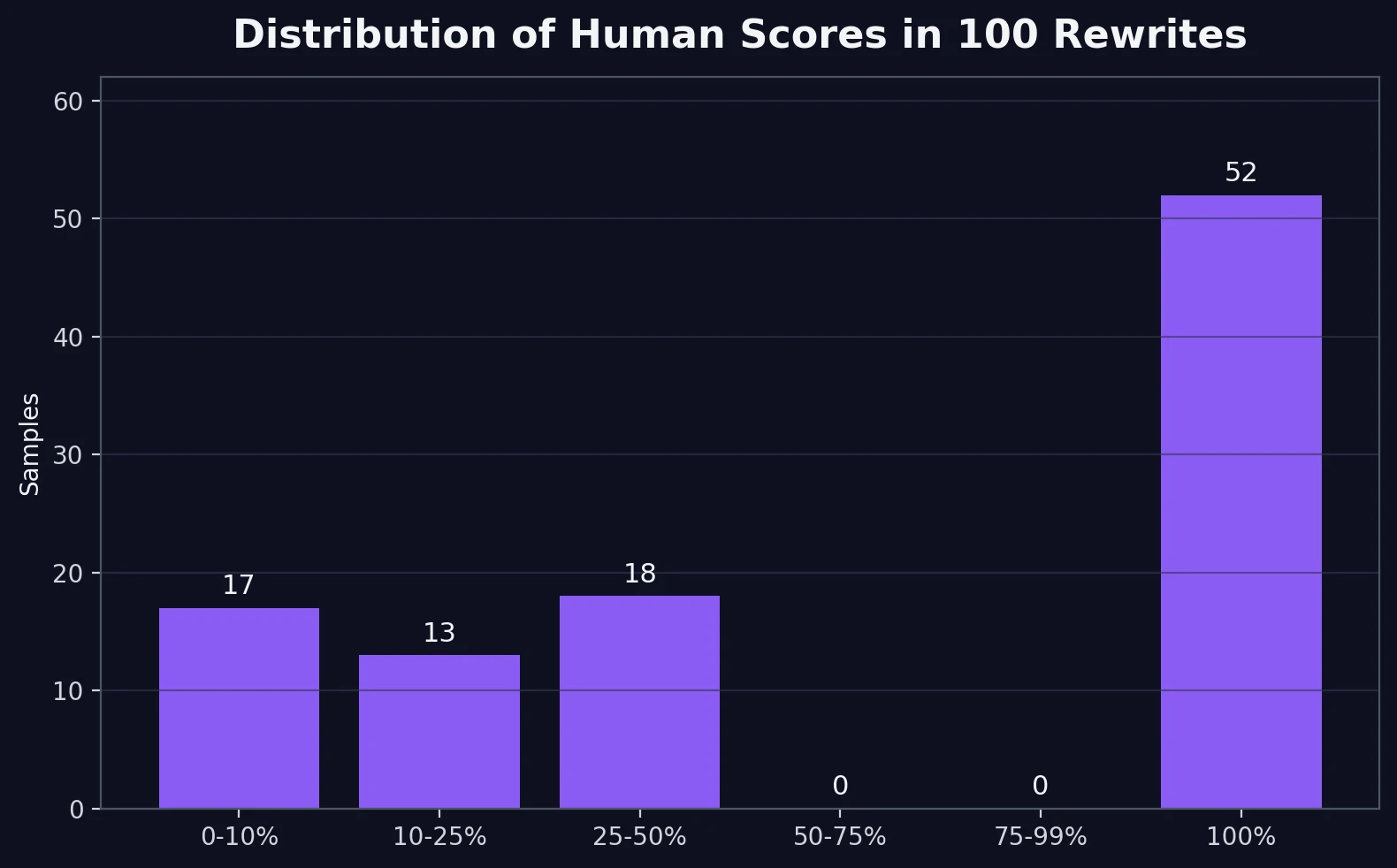
The average human score was 60.5%, but the median was 100%. Median simply means the middle result. That big gap tells us the scores were split into two camps instead of clustering in the middle.
17 samples fell below 10% human, which means QuillBot rejected a noticeable chunk of the rewrites very hard.
The first big pattern: BypassGPT is hit-or-miss, not consistently reliable
The bar chart below gives the simplest view of the experiment. If we treat 50% human or higher as a practical pass, BypassGPT passed 52 samples and failed 48. That is close enough to a coin flip that it would be hard to call the tool dependable if your only goal is avoiding detection.
Also Read: BypassGPT.ai vs GPTZero.me
The next chart explains why the average score can be misleading. QuillBot did not gradually reward the rewrites. Instead, it behaved in a mostly bimodal way. That word sounds technical, but the idea is simple: the scores formed two piles. One pile sat at 100% human. The other pile stayed under 50%. There was almost nothing in between.
Also Read: Can BypassGPT really bypass Originality.ai?
That matters because it changes how students should think about the tool. This is not a system that gently improves your odds each time. It behaves more like a gamble. Some outputs slide through completely. Others still look obviously machine-like to QuillBot.
The second big pattern: getting a pass often comes with trade-offs
When I moved past the scores and checked the actual rewrites, another story appeared. BypassGPT often preserved rough word count, but it did not reliably preserve structure. The original texts averaged 182.9 words. The rewrites averaged 180.4 words. In other words, the tool was not simply shrinking everything to game the detector.
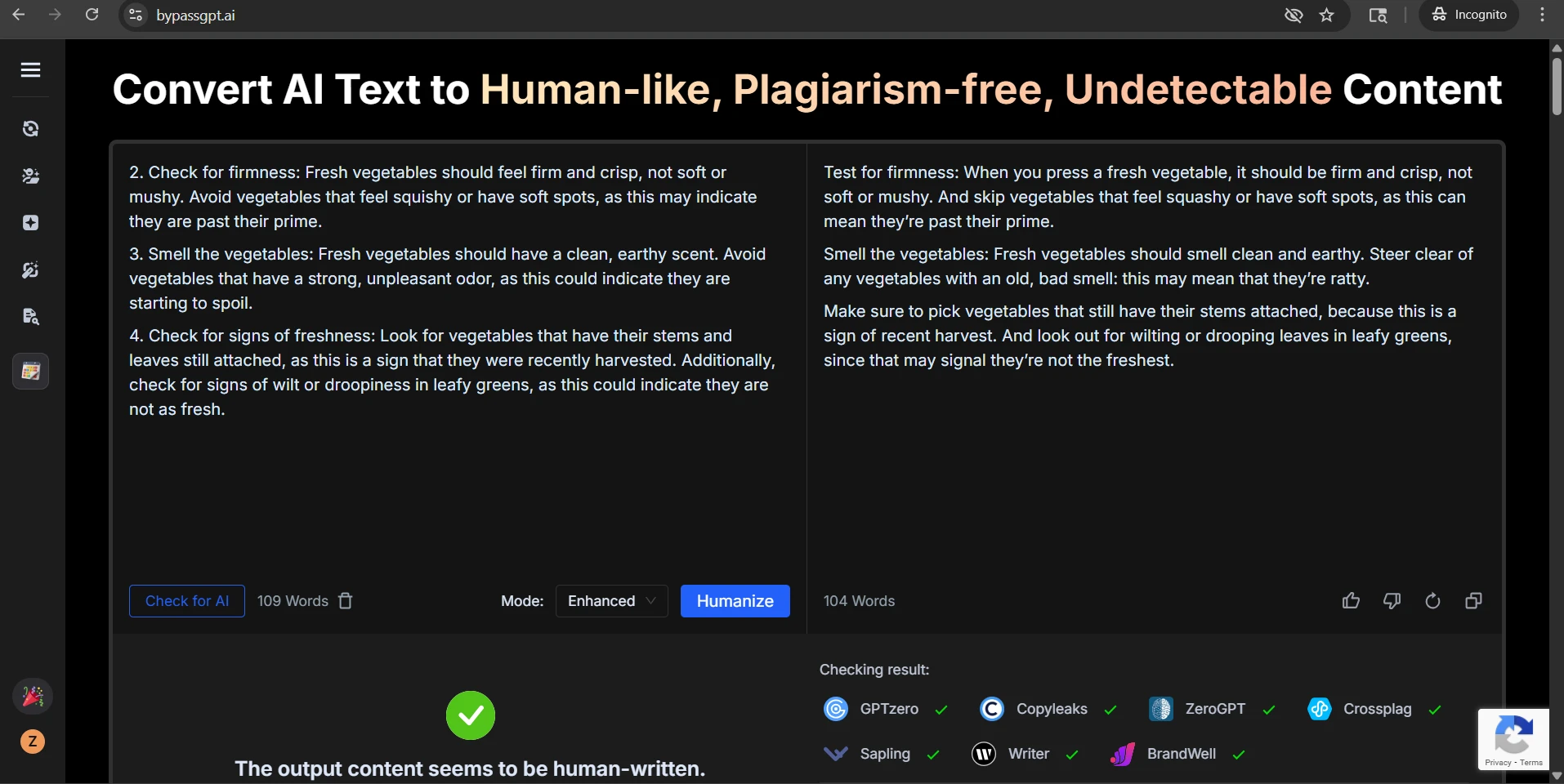
But while the length stayed nearly the same, the formatting did not. Every sample in the CSV that began with a numbered list lost that numbering after the rewrite. Every bullet-list sample lost its bullets too. In a student context, that is not a small issue. Steps, outlines, and study notes rely on structure. If that structure disappears, readability drops fast.
Also Read: Can Sapling.ai also detect BypassGPT?
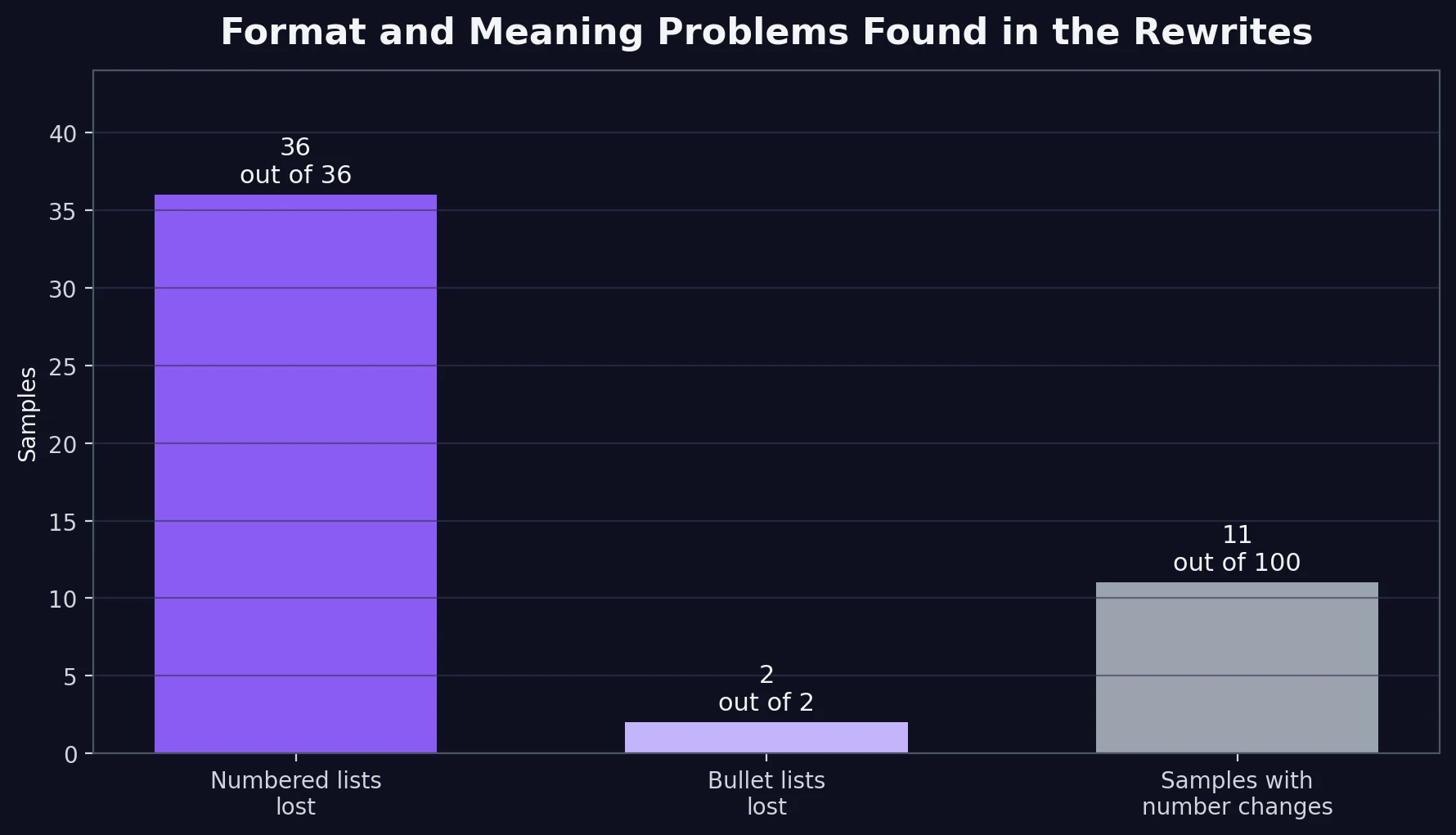
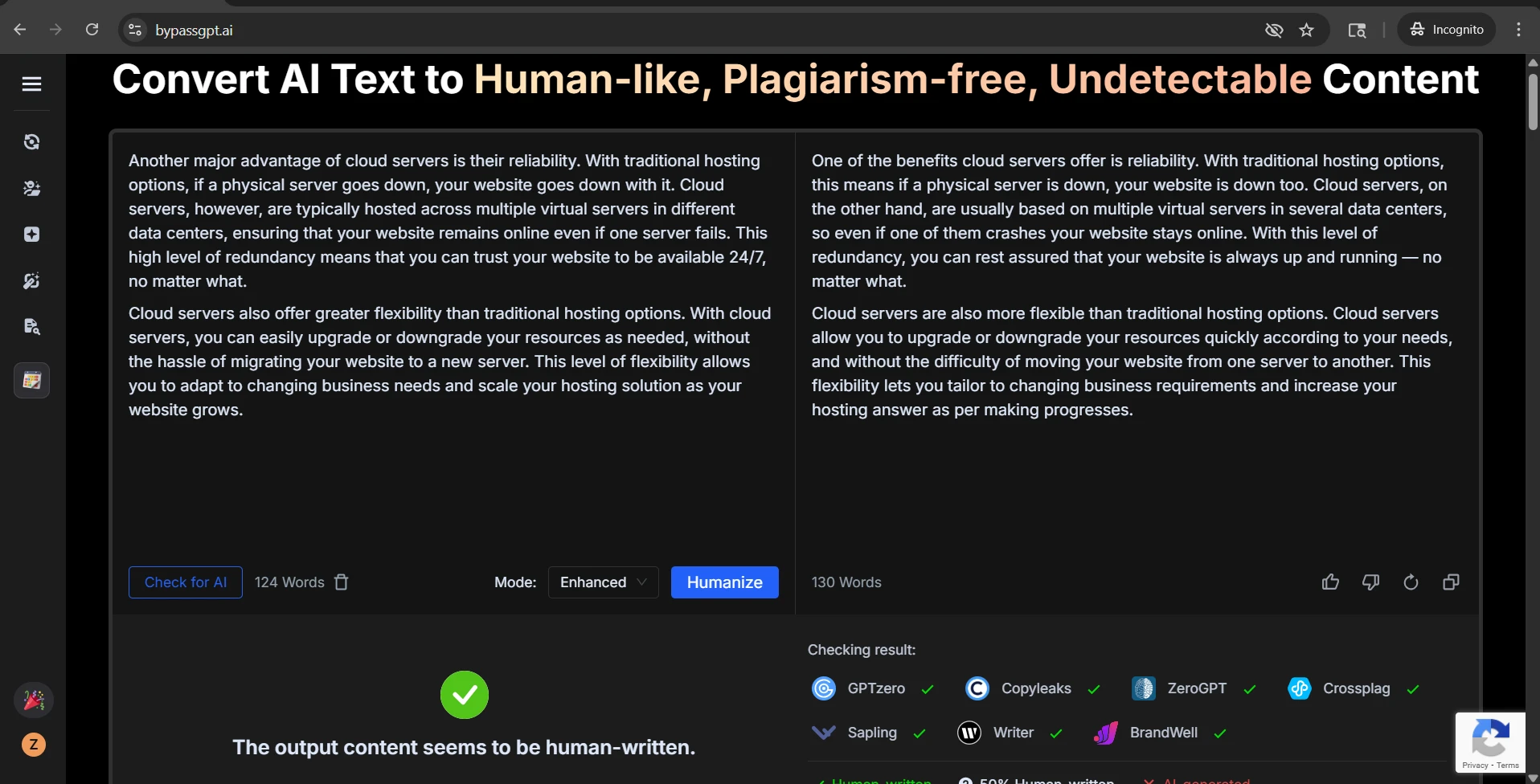
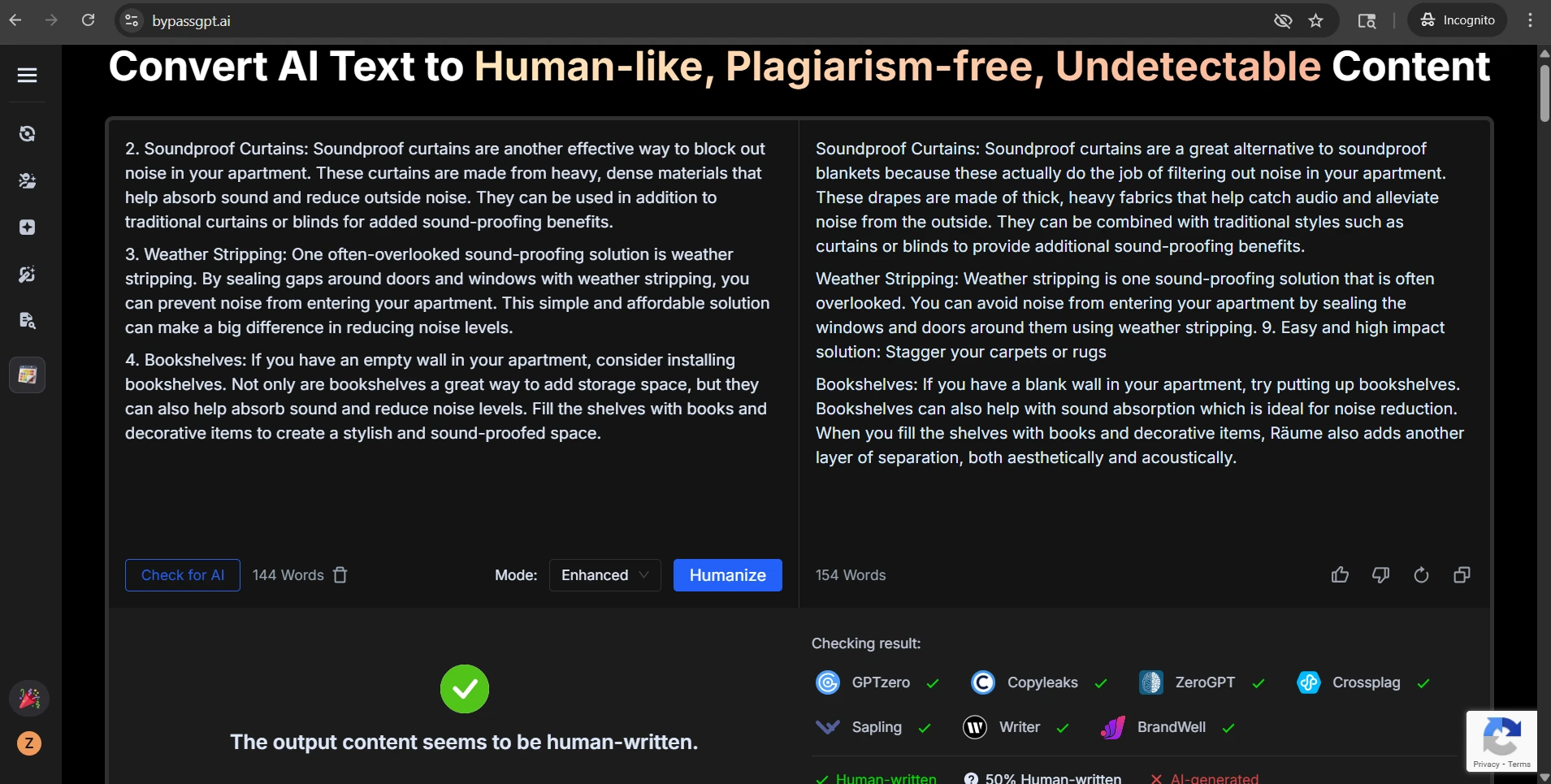
I also found 11 samples where the rewrite changed, inserted, or dropped numerical information. Sometimes the added number was harmless. Sometimes it was not. In one case, a heading about everyday credit card purchases became advice about small recurring bills, which is a narrower point than the original. In another, a DIY flower crown guide suddenly leaned harder into Coachella, even though the original was broader. Those are small shifts, but they show how paraphrasing can quietly distort meaning.
Also Read: BypassGPT.ai vs Turnitin: My 100-Sample Test Shows Why “Humanized” Text Is Still a Gamble
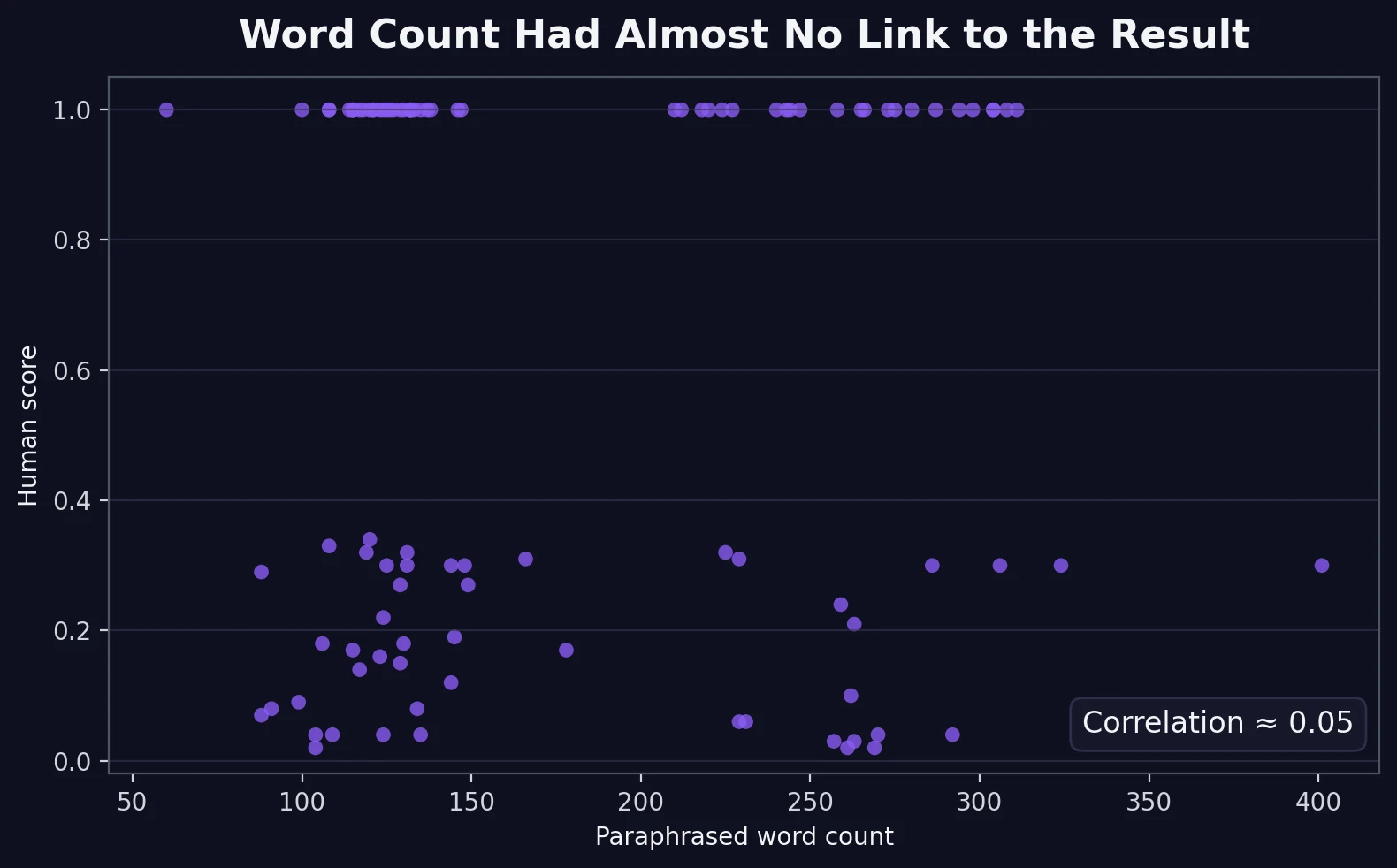
A quick plain-English explanation: I also checked whether word count and detector score moved together. The correlation was about 0.05. Correlation is just a way of measuring whether two things rise and fall together. A number this close to zero means there was basically no meaningful link.
Where the rewrites started to break down
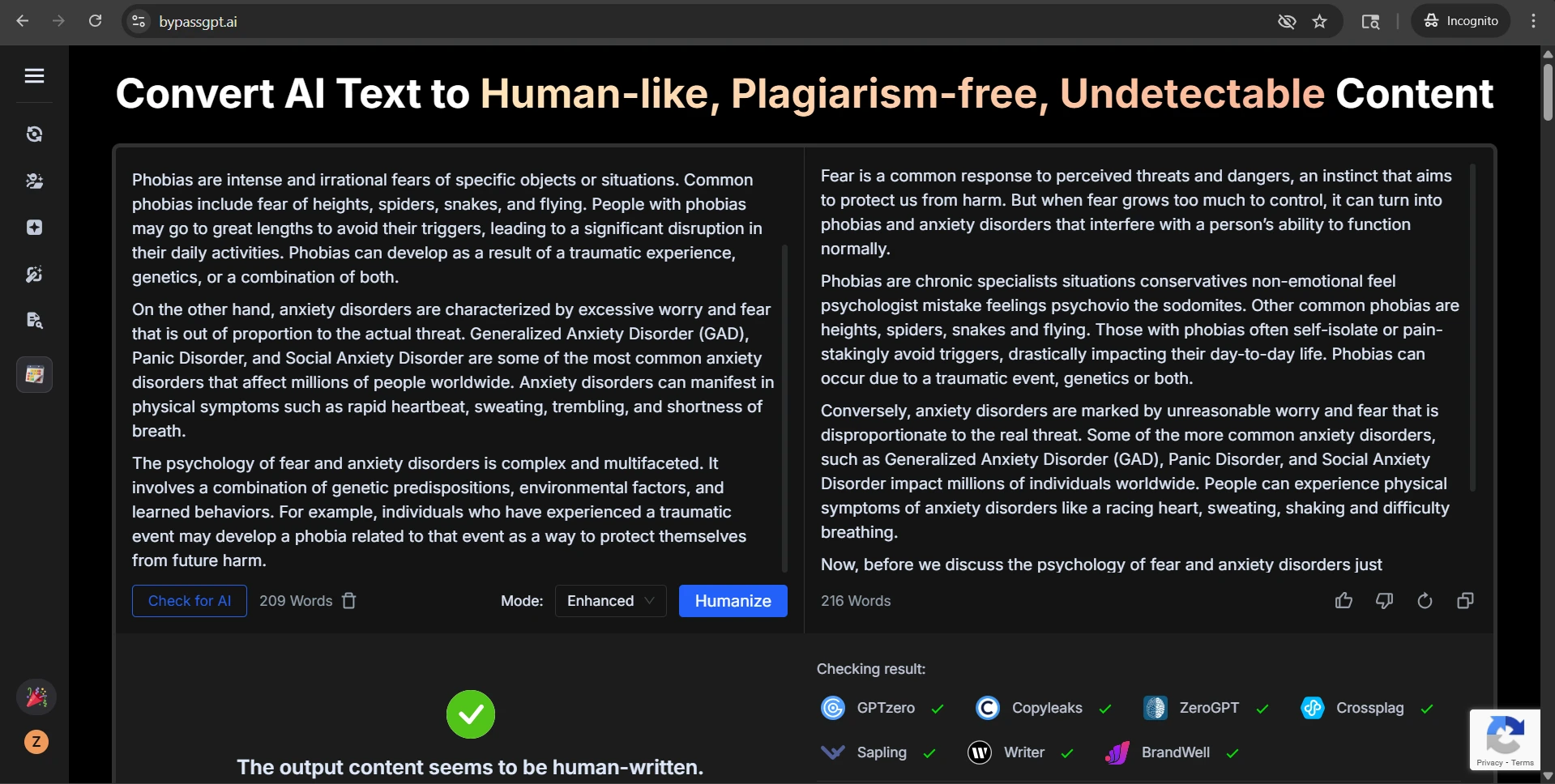
Some problems were easy to measure. Others showed up during manual review. A clean heading like “Step 2: Learn the Basics of Adjusting Images” became “Step 2Adjust the Image Settings”, which is the kind of formatting bug a reader notices immediately. Another rewrite inserted wording that felt half-finished or simply odd. One of the screenshot examples even contains obvious gibberish in the middle of a sentence. That is a serious warning sign, because a detector pass does not help much if the paragraph starts sounding broken.
This is the main weakness in BypassGPT’s promise. The tool sometimes pushes the language away from the clean, natural rhythm of human writing and into something more unstable: extra filler, clunky phrasing, sudden tone shifts, or details the original never asked for. For a classroom blog, an essay draft, or study notes, that instability can be as risky as detection itself.
Also Read: BypassGPT.ai vs GPTZero.me: 100 Rewrite Tests Reveal What Really Happens
Examples from the test set
The screenshots below show that mixed pattern clearly. Some BypassGPT outputs look polished enough to pass. Some QuillBot checks reject the rewritten text completely. That contrast is exactly what the data showed: strong wins in some cases, but very weak performance in others.
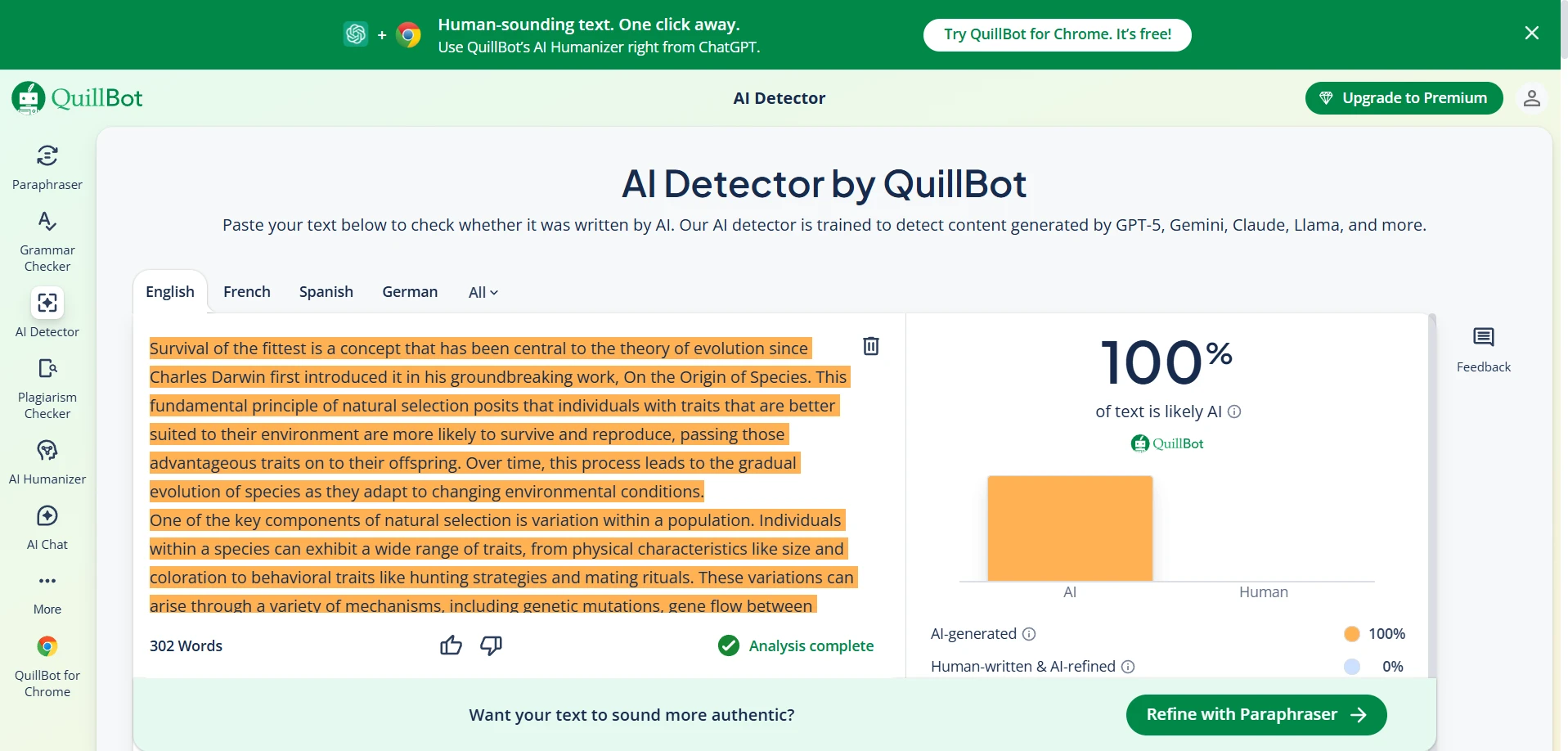
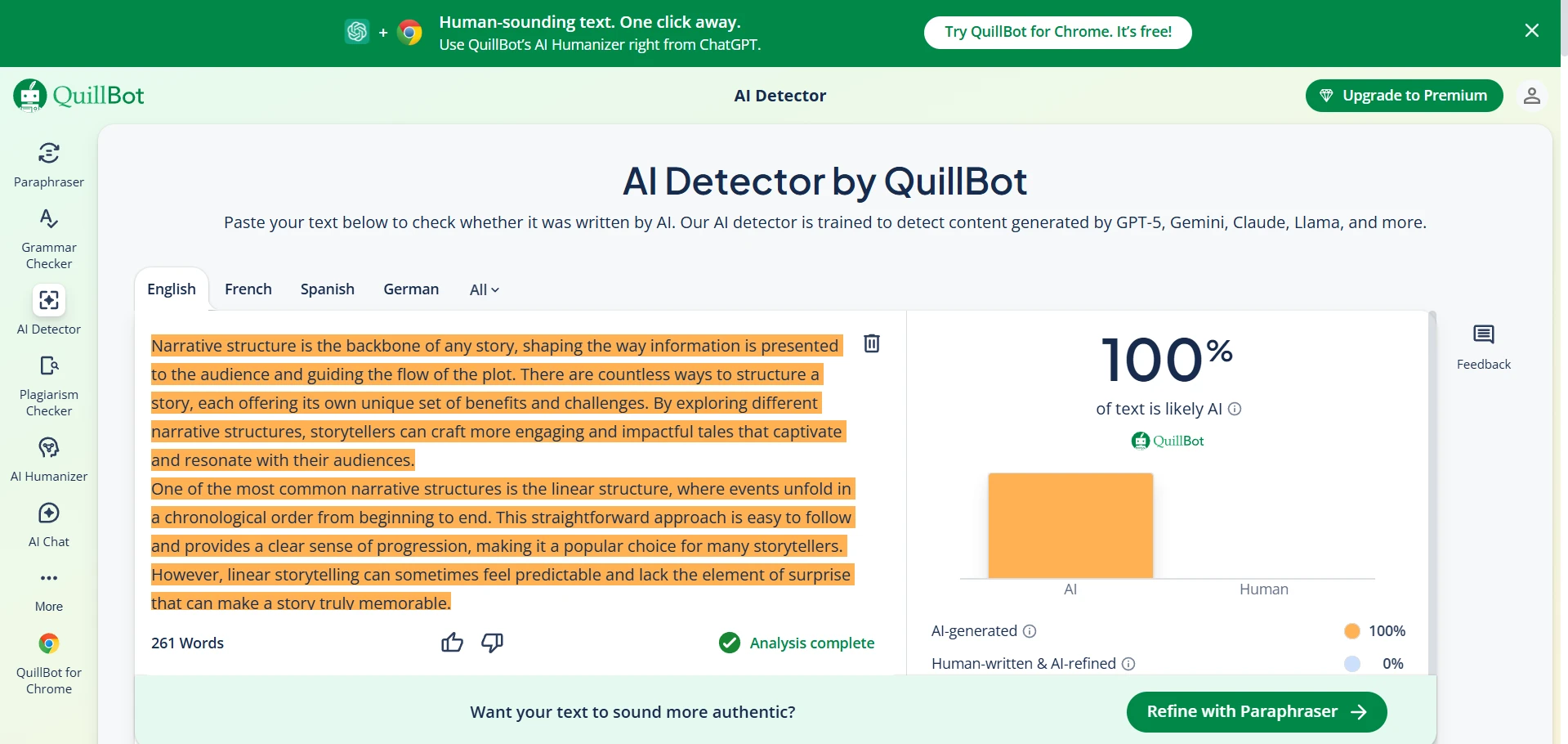
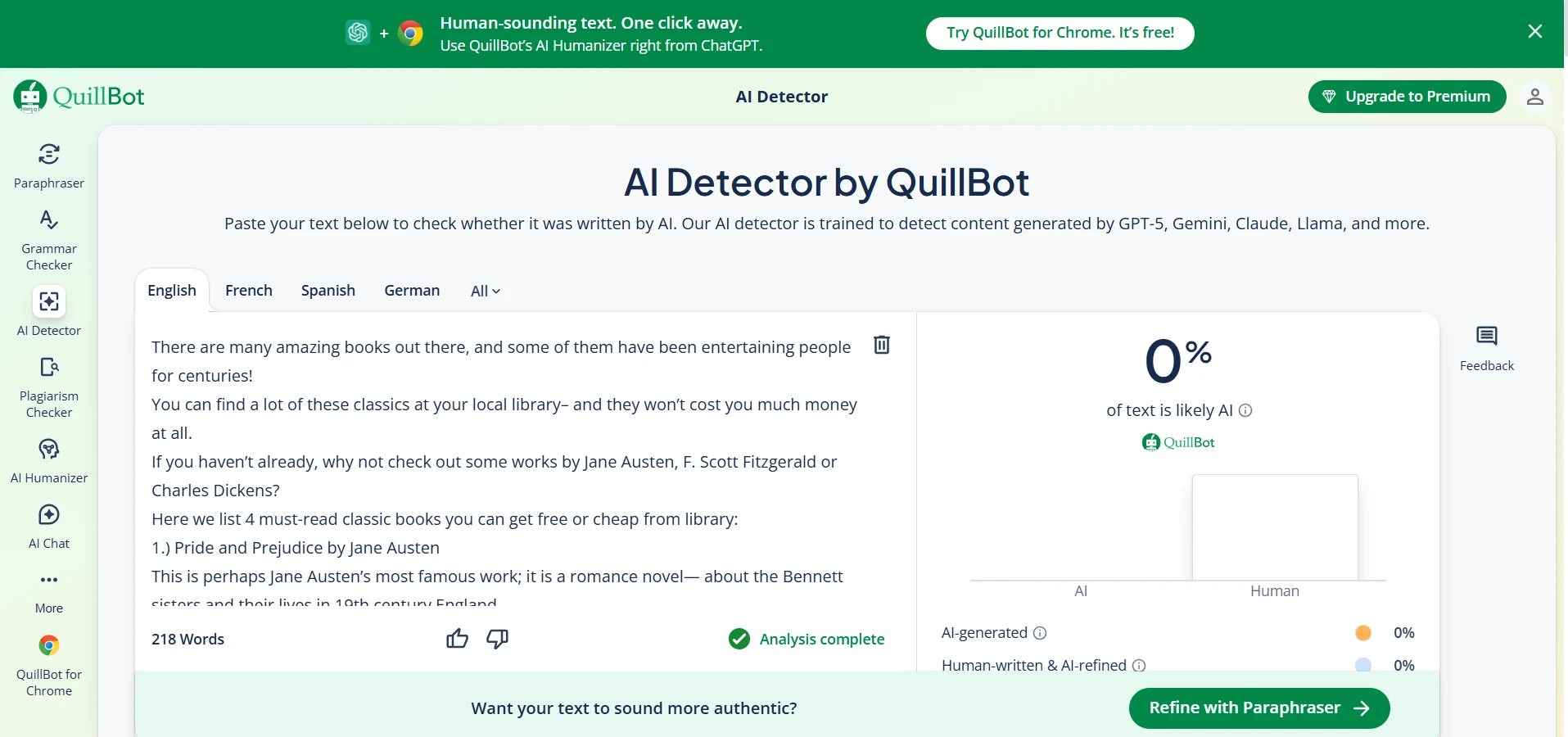
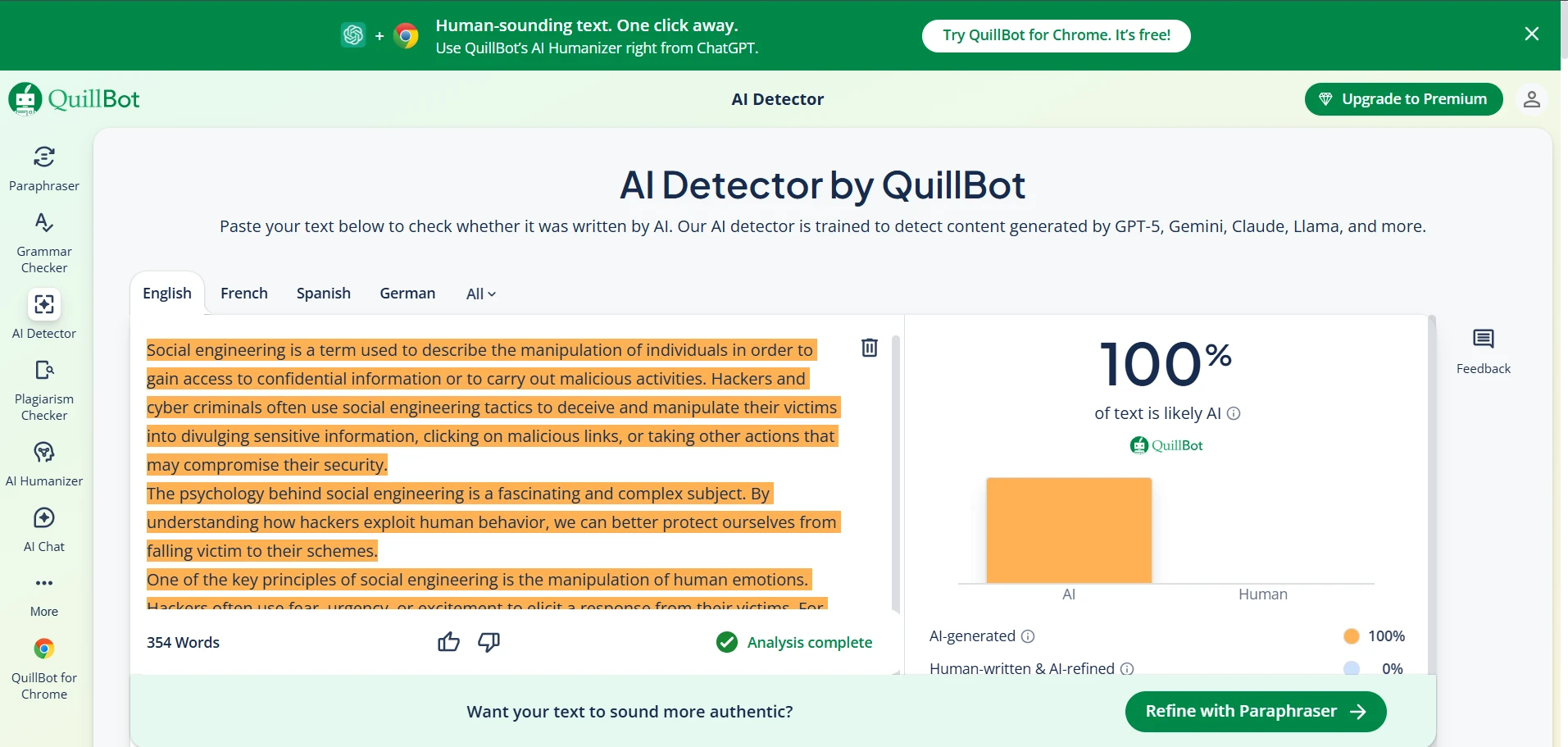
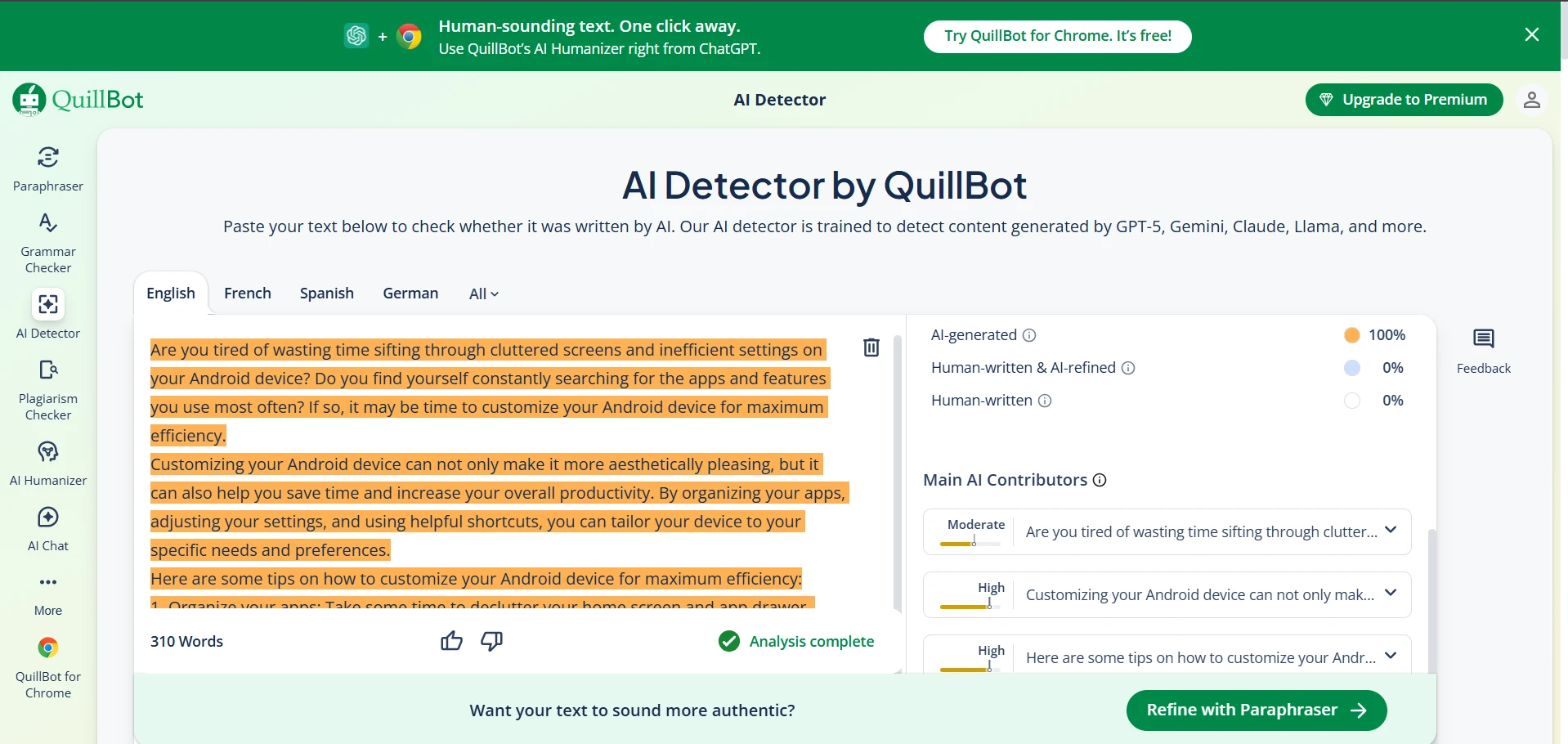
The bottom line
After 100 samples, the clearest conclusion is this: BypassGPT can beat QuillBot, but it does not do so consistently enough to call it reliable. A 52% full-pass rate is not trivial, yet it is also not strong enough to trust blindly. Nearly half the rewrites still failed.
Even more important, the tool often pays for those passes by damaging the text itself. Numbered steps disappear. Bullets vanish. Headings get mangled. A few rewrites add or change details that were not there before. So the real question is not just, “Can it bypass the detector?” The better question is, what kind of writing is left after it tries?
For students, that is the lesson worth remembering. A detector workaround is only useful if the final writing still sounds clear, keeps its structure, and stays faithful to the original meaning. In this test, BypassGPT managed that some of the time, but not often enough to escape the trade-offs.