

Students hear the word undetectable all the time now. But that word only matters if a tool can deliver consistent results, not just one lucky pass. To test that, I reviewed 100 samples rewritten by BypassGPT.ai and then checked those rewrites using Sapling.ai. I converted Sapling’s detector output into a human score, which means a higher number is better. A score of 100% means Sapling thought the text looked strongly human. What I found was simple: BypassGPT can win sometimes, but as a dependable bypass tool, it was far less effective than its marketing implies.
How I ran the test
The setup was straightforward. I took the 100 rewritten samples from our dataset, looked at the Sapling result for each one, and treated that result as a human-likeness score on a 0 to 1 scale. I also compared the original text with the rewritten version to look for side effects that raw scores miss, such as broken headings, list formatting getting flattened, and odd wording choices.
Quick translation of the scoring: if a rewrite gets 0.90, that means Sapling treated it as about 90% human. If it gets 0.01, Sapling saw almost no human signal in it.
Also Read: Can BypassGPT really slip past ZeroGPT?
What stood out immediately
- Average human score: 23.7%
- Median human score: 1% (the median is the middle result, so this shows what a typical sample looked like)
- Cleared 50% human: 22 out of 100 samples
- Cleared 90% human: 14 out of 100 samples
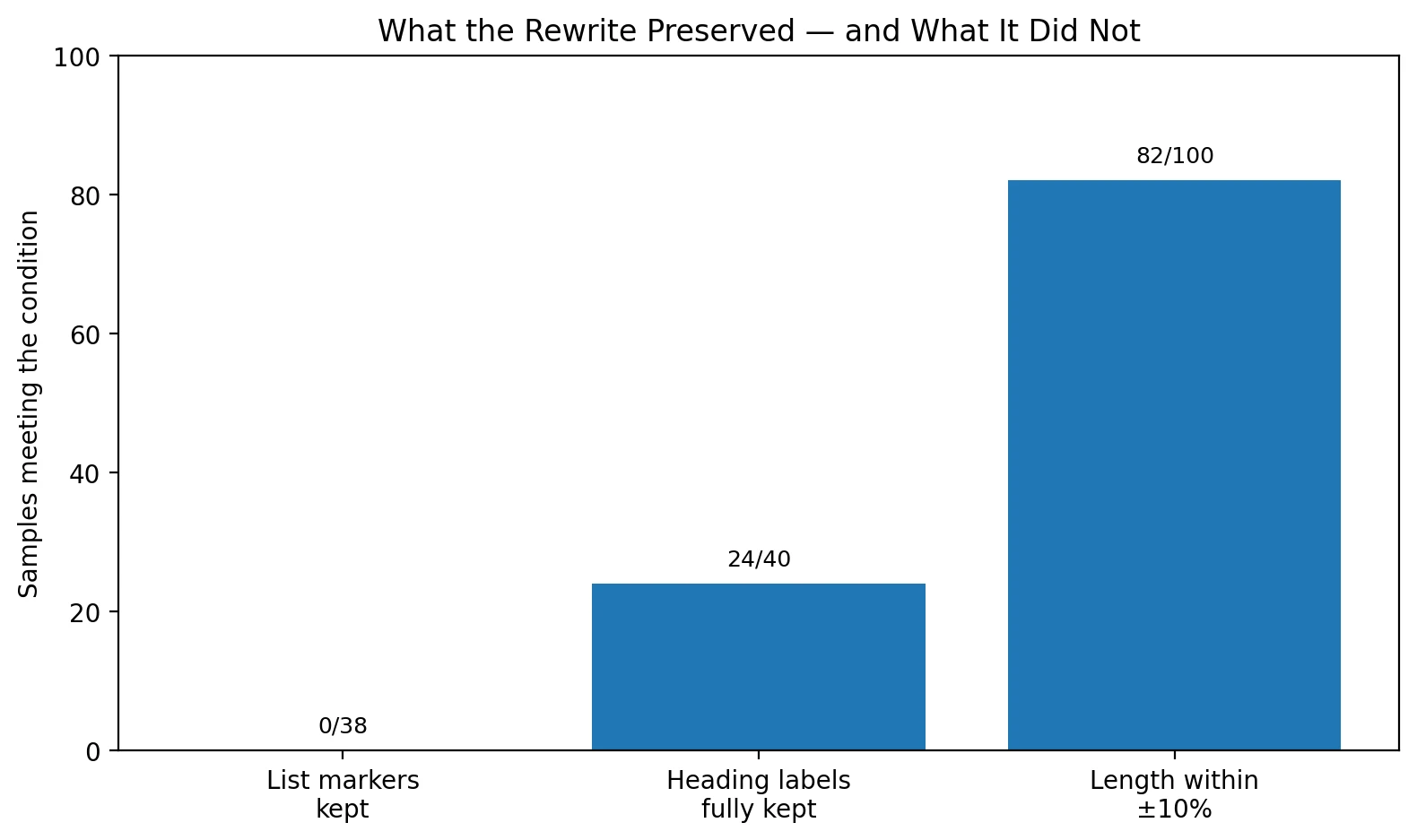
- List formatting preserved: 0 out of 38 list-based originals kept their bullet or number markers
- Length preserved: 82 out of 100 stayed within 10% of the original word count, but that did not guarantee a good score
The big picture: most rewrites still looked AI-like to Sapling
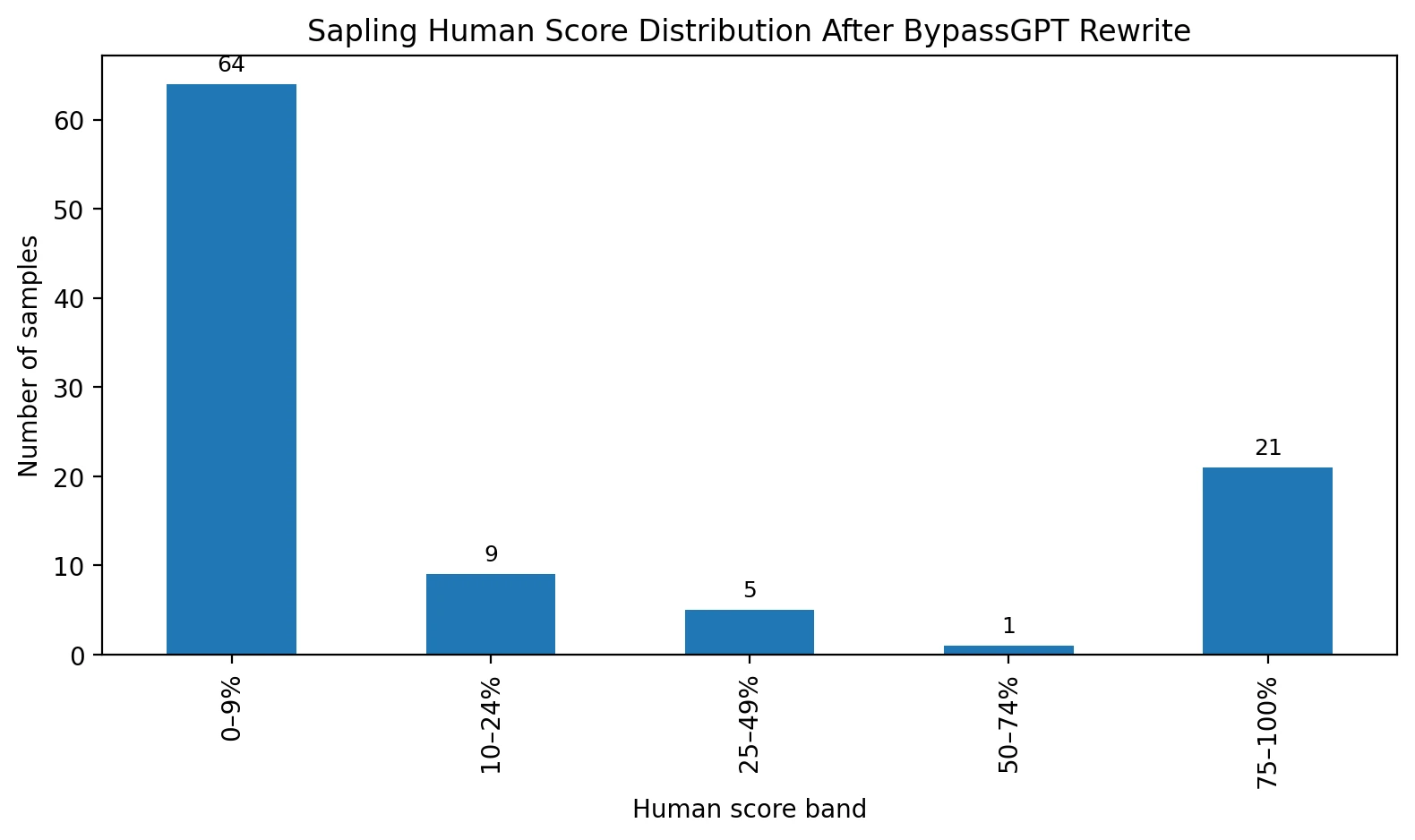
The first chart makes the core point better than any slogan can. Sixty-four of the 100 samples landed in the 0% to 9% human range. That is not a close call. That is Sapling rejecting the rewrite almost immediately. At the other end, 21 samples scored in the 75% to 100% range, which proves BypassGPT can work in some cases. The problem is consistency. A tool that succeeds one-fifth of the time but crashes the rest of the time is hard to trust if the stakes are a grade, scholarship review, or academic warning.
Also Read: [100 Samples Test] Can BypassGPT Really Bypass Originality.ai?
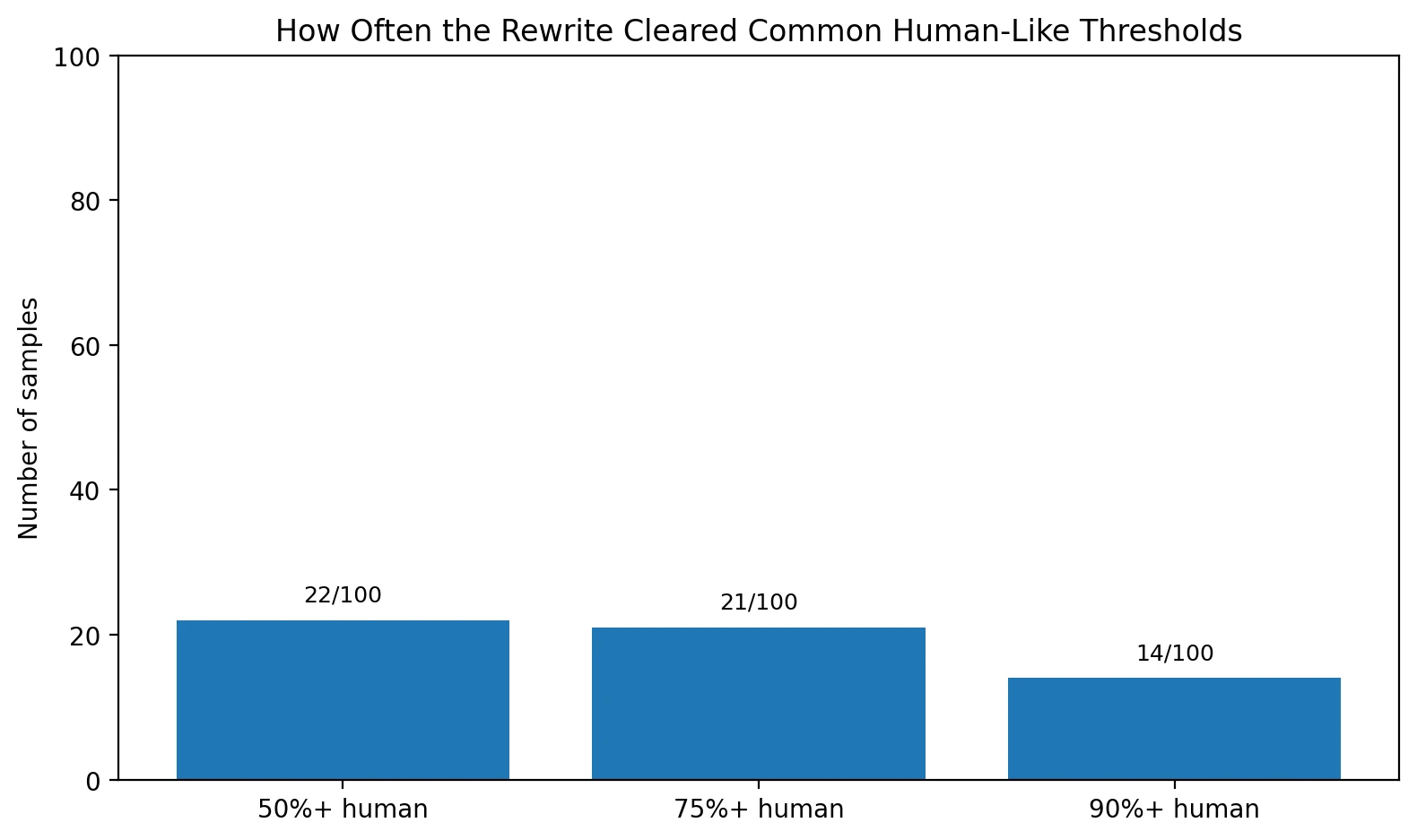
The threshold chart tells the same story in a more practical way. If you use a simple checkpoint like 50% human, only 22 rewrites get over that line. If you want something more convincing, like 90% human, the number drops to just 14. For students, that matters because one or two strong screenshots can create a false sense of confidence. The dataset as a whole says the tool is hit-or-miss, not reliable.
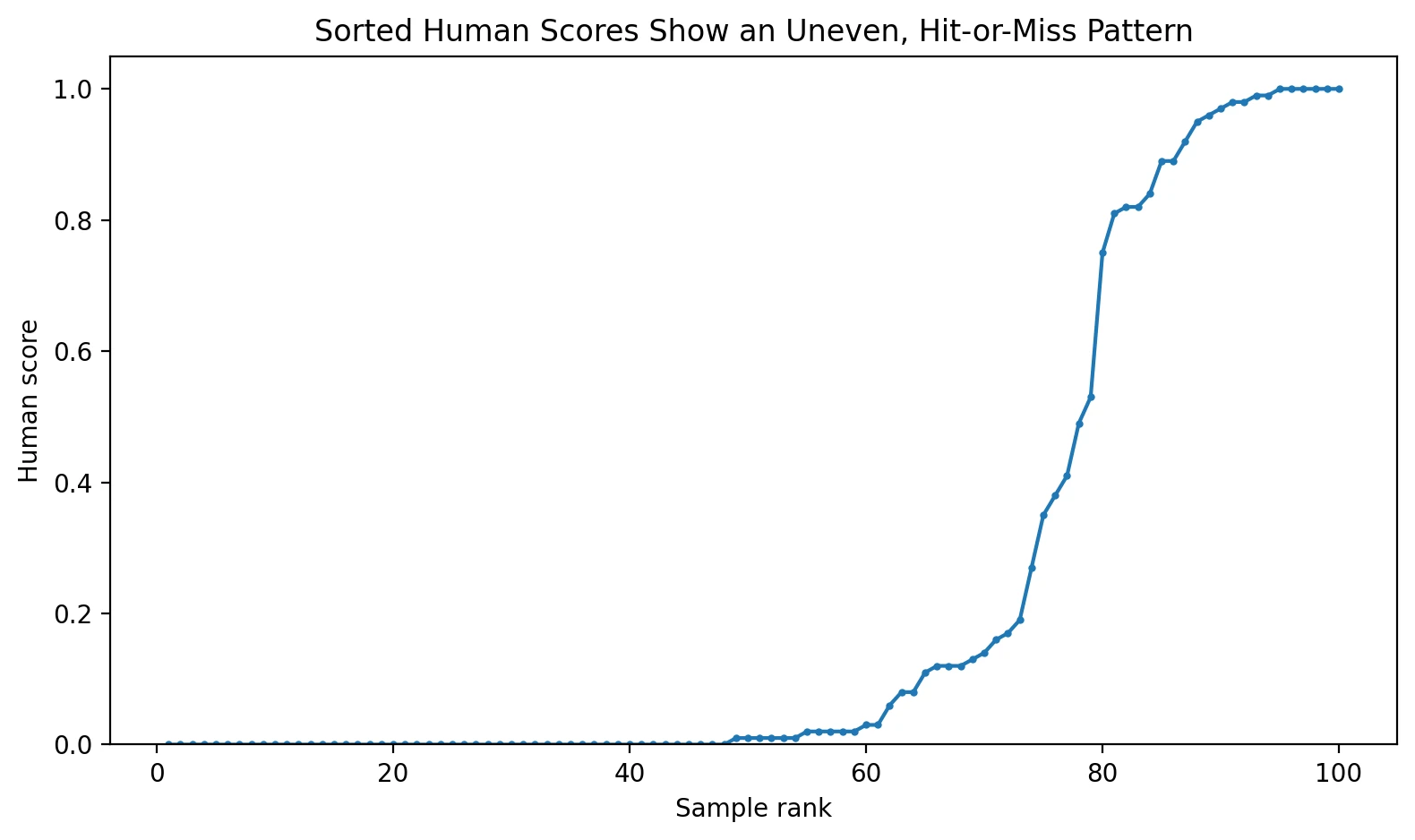
The hidden problem: the rewrite often damages structure
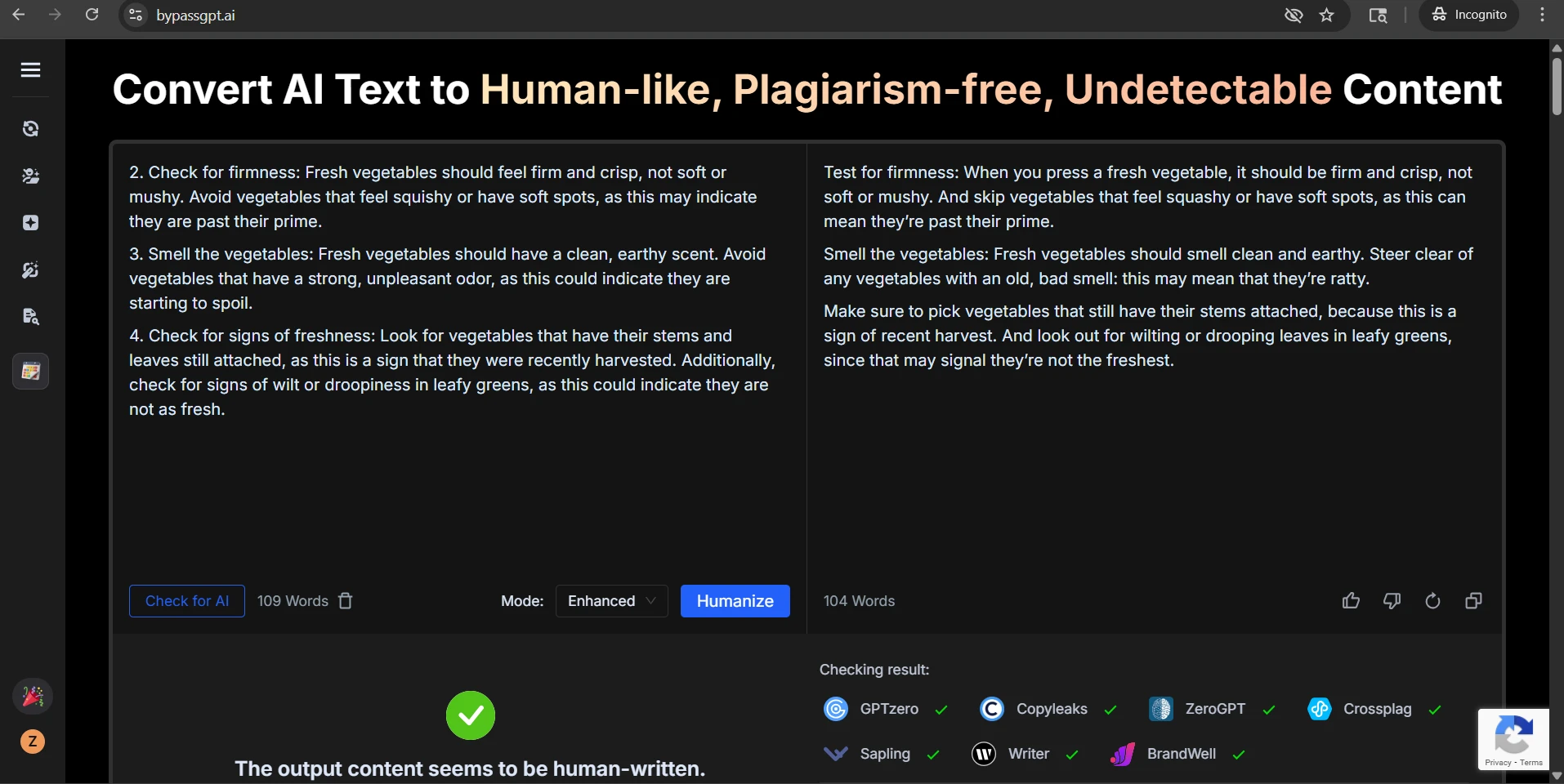
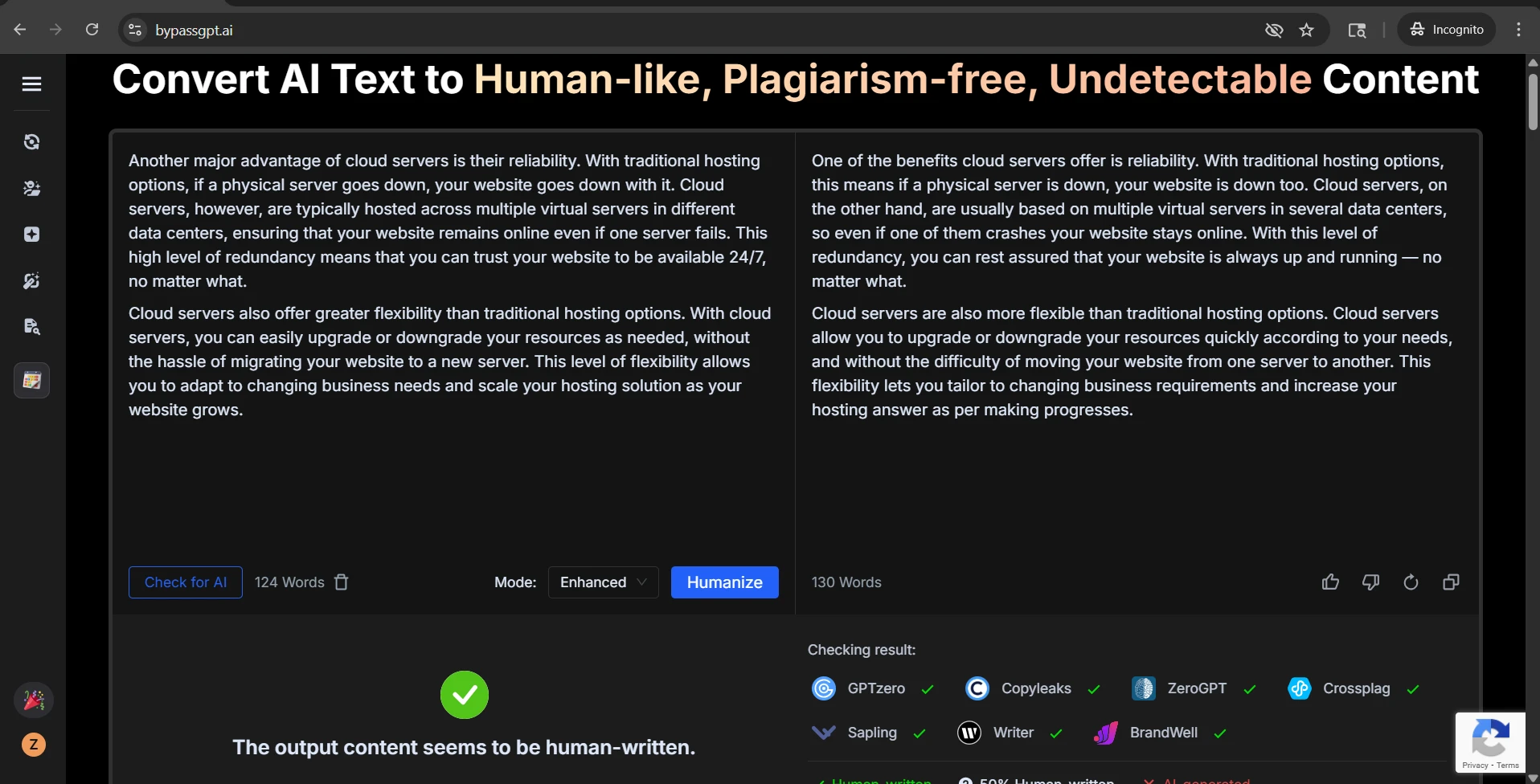
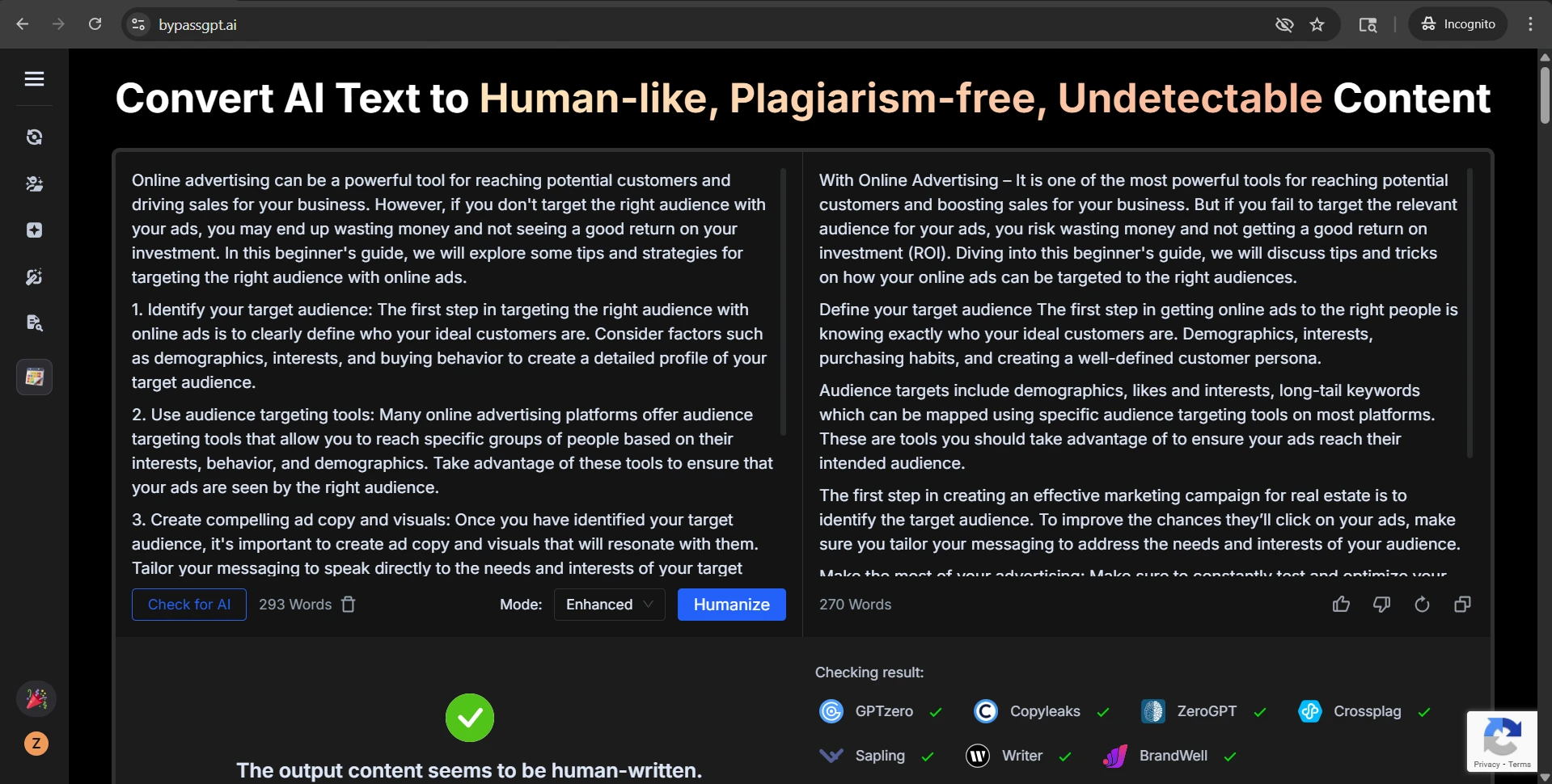
Detector scores are only half the story. Students do not submit raw probability charts; they submit writing. And that is where the rewrite shows a second weakness. In the CSV, I found that all 38 originals that used numbered or bulleted formatting lost those markers in the rewrite. Some still kept the idea of a heading, but the clean structure was gone. That matters in study guides, blog posts, explainers, and assignment answers where sequence and clarity matter just as much as the wording.
There was a similar issue with section labels. In samples that used heading-like labels such as “Check for firmness:” or “Identify your target audience:”, the rewrite frequently weakened them or blended them into the next sentence. That kind of flattening makes writing feel less organized, even when the word count stays close to the source.
Also Read: BypassGPT.ai vs GPTZero.me: 100 Rewrite Tests Reveal What Really Happens
Problems I found inside the rewrites
Once I moved past the chart level and read the text itself, several recurring quality problems showed up. The first was formatting loss. Numbered steps turned into plain paragraphs. List items lost their visual order. In educational writing, that is more than a cosmetic issue. It can make instructions harder to follow and weaken the logic of the piece.
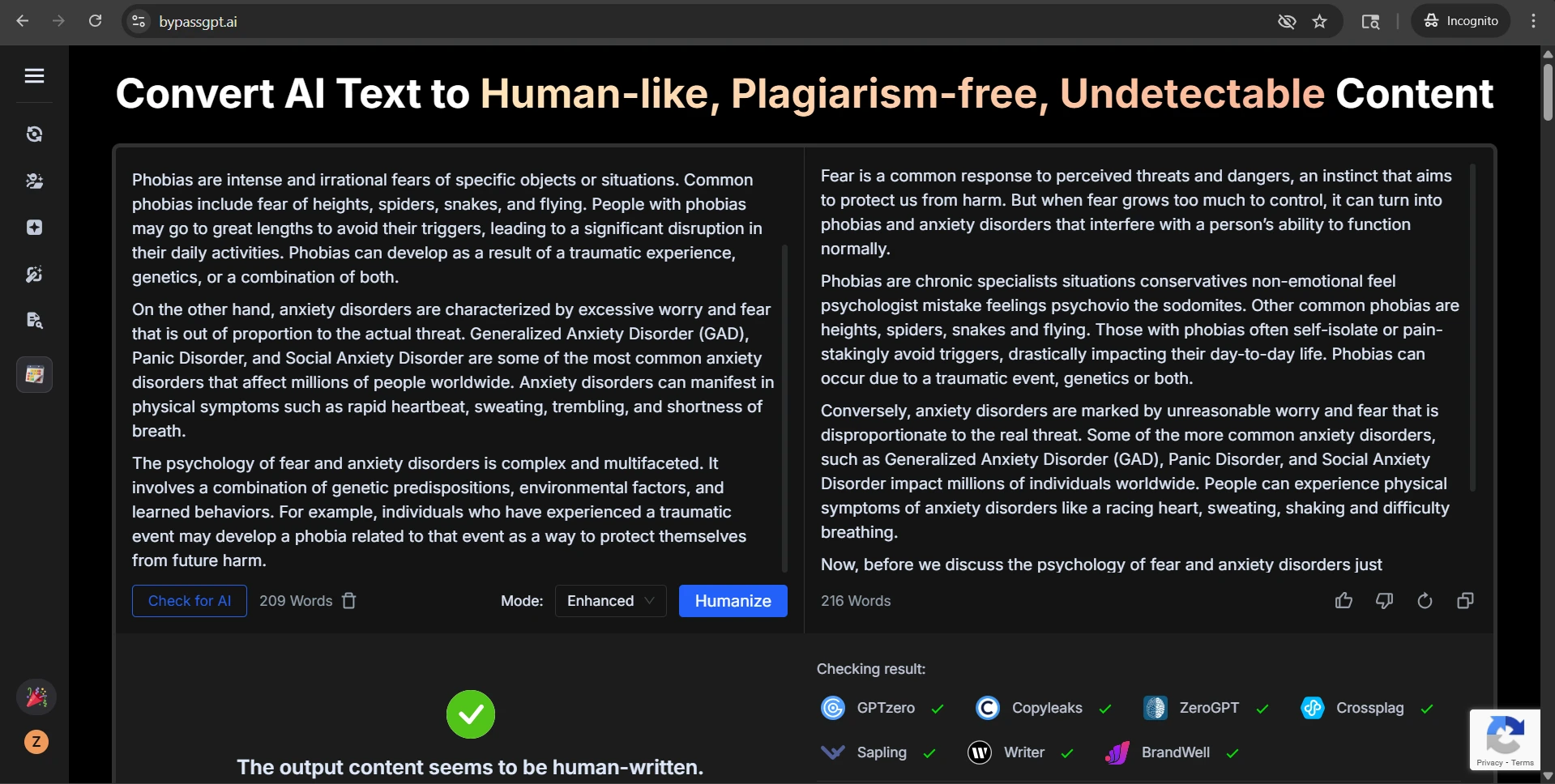
The second issue was heading damage. One rewrite turned a neat label like “Define your target audience:” into a line that effectively read “Define your target audience The first step…” with the separator missing. Another example kept a heading phrase but removed the numbering that originally helped the reader track the sequence. So even when the rewrite passed, it could still make the content messier.
The third issue was awkward phrasing. Some outputs swapped in words that felt unnatural or careless. In one example, vegetables that were no longer fresh became “ratty.” In another, the rewrite added chatty phrasing like “Totally try this”, which might be fine in a casual post but sounds weak in academic or informative writing. A few passages also looked grammatically strained, especially when the tool tried too hard to sound different from the original.
What makes this more interesting is that these problems did not only happen in low-scoring samples. Even some of the high-scoring rewrites still removed numbering or made small style choices that reduced clarity. That means beating the detector and producing clean, polished writing are not the same achievement.
Also Read: [STUDY] Can BypassGPT Outsmart Grammarly’s AI Detector?
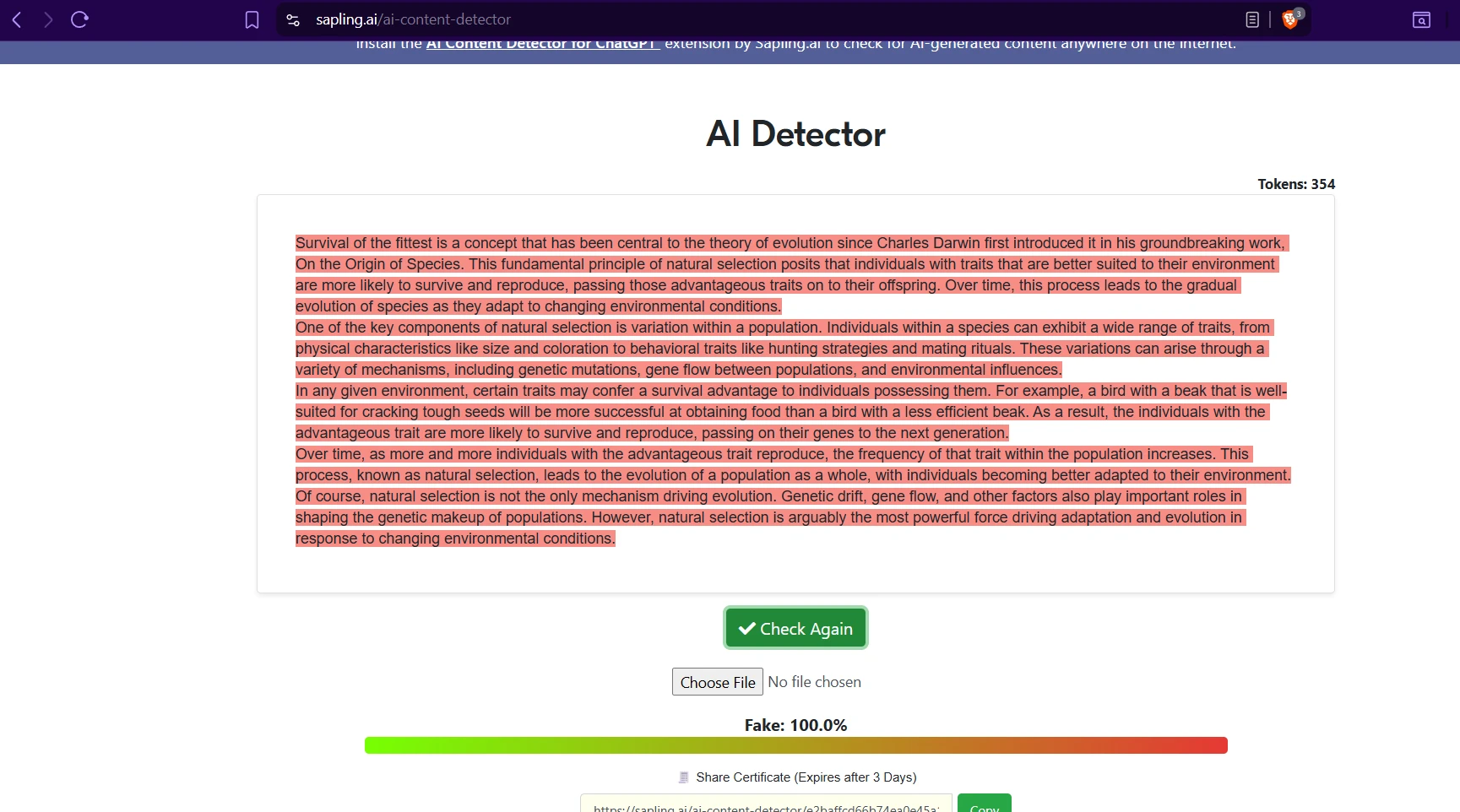
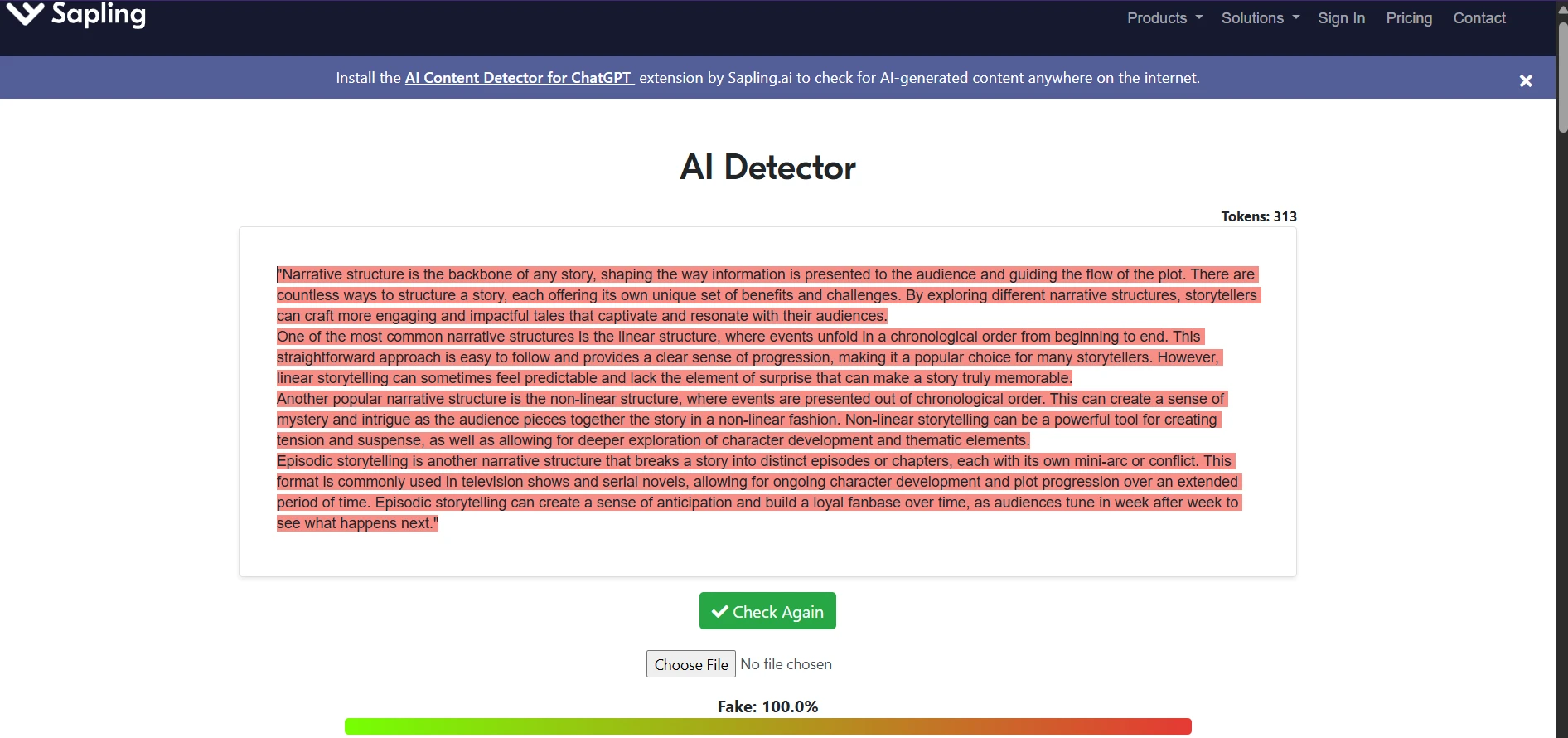
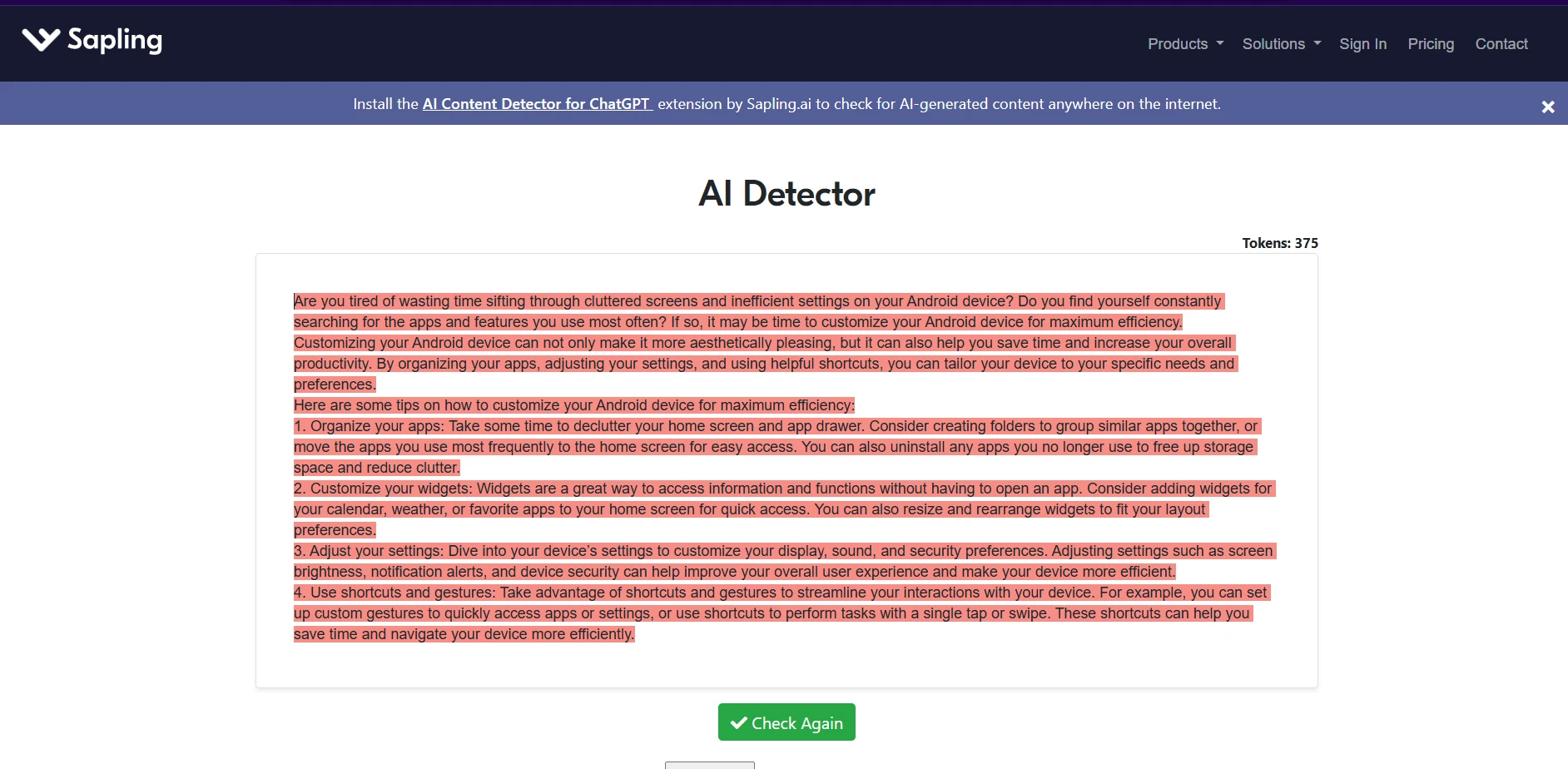
What the screenshots suggest
The screenshots tell a useful before-and-after story. The BypassGPT examples show the tool presenting itself as a way to make content sound more human. But the Sapling screenshots reveal that this promise does not hold up consistently. Some outputs are still flagged heavily, and several of the visible rewrites show the same formatting and wording issues found in the CSV analysis.
Final take
BypassGPT.ai is not consistently effective at bypassing Sapling.ai. Across 100 samples, the average human score was pulled up by a small group of strong results, but the typical rewrite still performed poorly. That is why the median matters so much here: the middle result was only 1% human.
Just as important, the tool often introduced new problems while trying to fix the detector problem. It removed list markers, weakened headings, and sometimes replaced clear wording with awkward or overly casual phrasing. For students, that means the risk is not only getting caught by a detector. The risk is also ending up with writing that looks less organized and less credible.
If the question is whether BypassGPT can ever fool Sapling, the answer is yes, sometimes. If the question is whether it does so reliably enough to depend on, this 100-sample test points to a much clearer answer: no, not reliably.