
A rewrite can earn a glowing 100% human badge inside one tool and still be judged almost entirely AI-written by another. That uncomfortable gap is the reason this test matters. We ran 100 StealthWriter rewrites through Pangram and then checked whether the altered text still made sense, kept its structure, and remained readable enough for a student to submit or publish.
The Test: 100 Rewrites, One Simple Question
Each CSV row contains an original passage, StealthWriter’s paraphrased version, and Pangram’s result. Pangram normally reports an AI probability, so the figures were converted into a human score: a higher number means Pangram was more likely to view the text as human-written.
For an easy comparison, we used 50% human as the dividing line. This is a cutoff—a chosen boundary between a likely failure and a likely bypass. It does not prove who wrote a passage; it only shows how the detector scored it.
Also Read: Can Stealthwriter AI Beat QuillBot's AI Detector? We Tested 100 Rewrites
The numbers at a glance
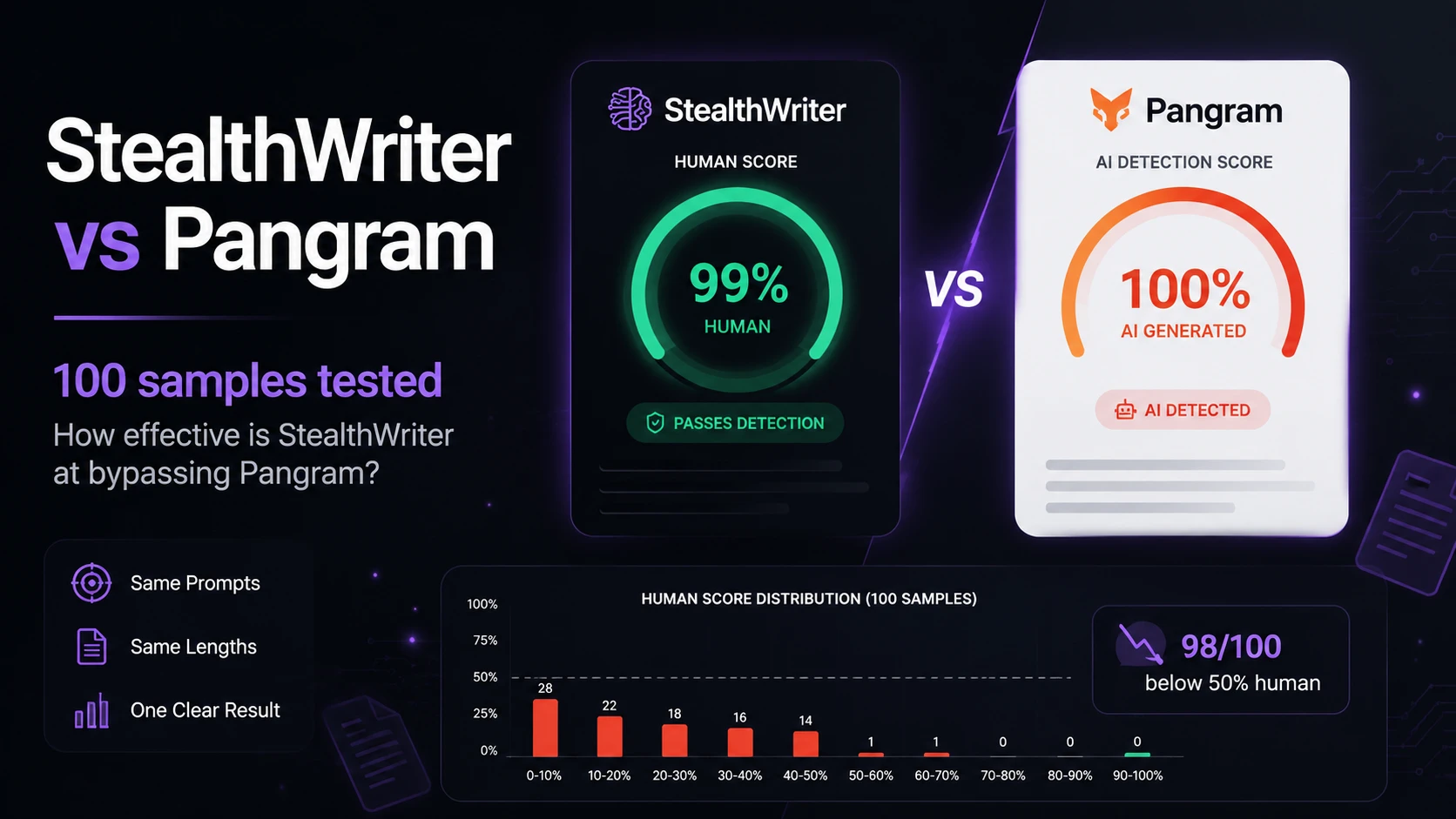
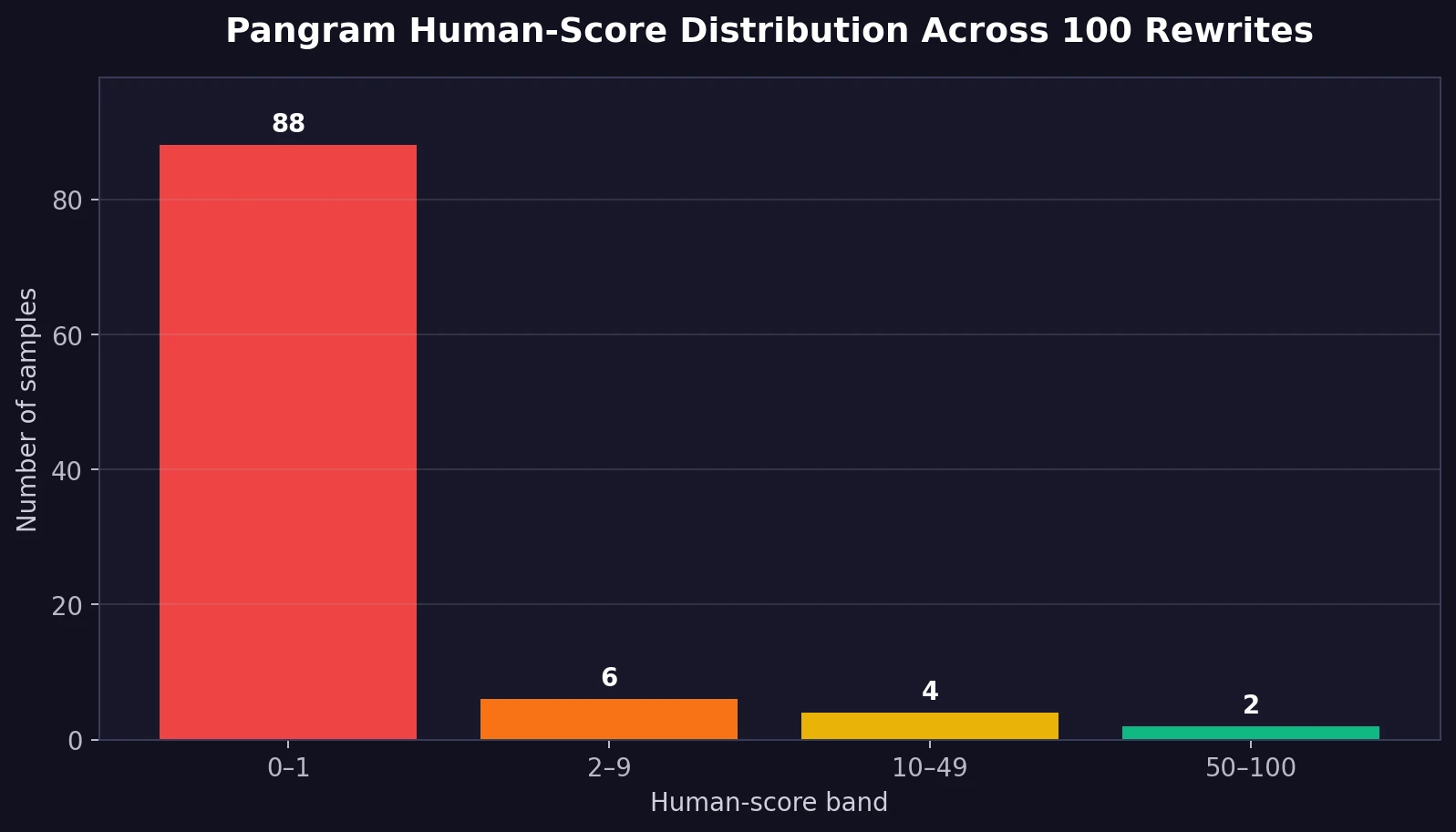
- 98 of 100 rewrites scored below 50% human.
- 94 rewrites scored below 10% human.
- 88 rewrites received only 0% or 1% human.
- The median was 1%. Median means the middle score after arranging all results from lowest to highest.
- Only two samples reached 100% human.
The Result Wasn’t Close
The distribution chart shows how heavily the results gathered at the bottom. This was not a case where StealthWriter frequently came close but narrowly missed. Most rewrites were scored as strongly AI-like by Pangram.
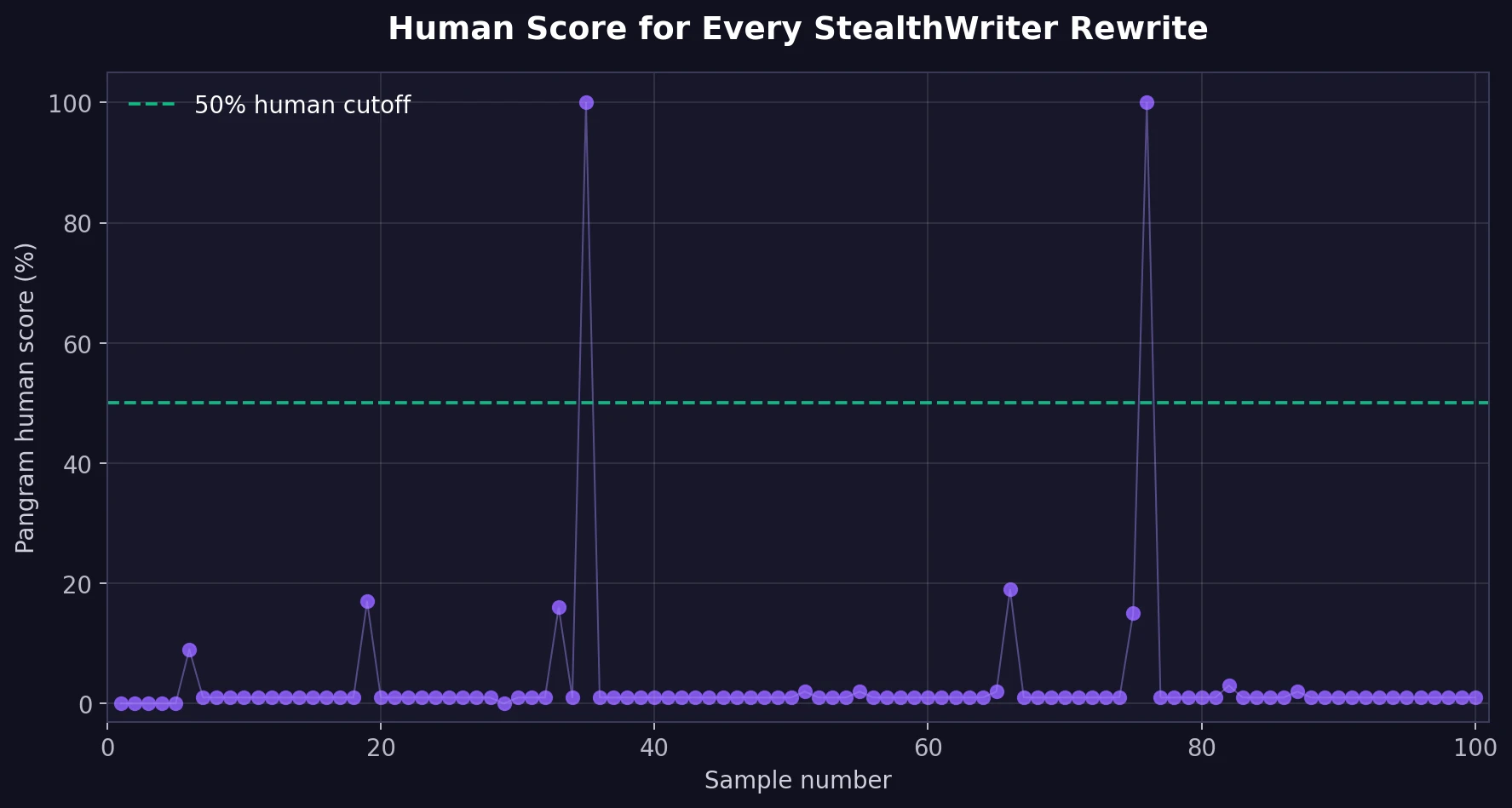
The sample-by-sample graph tells the same story more dramatically. Almost every point sits on the floor, with two isolated jumps to 100. In statistics, those unusually distant values are called outliers. They matter, but they should not be mistaken for the normal result.
Also Read: [STUDY] StealthWriter vs Sapling AI: Can 100 Humanized Rewrites Slip Through?
Why the Average Hides the Real Story
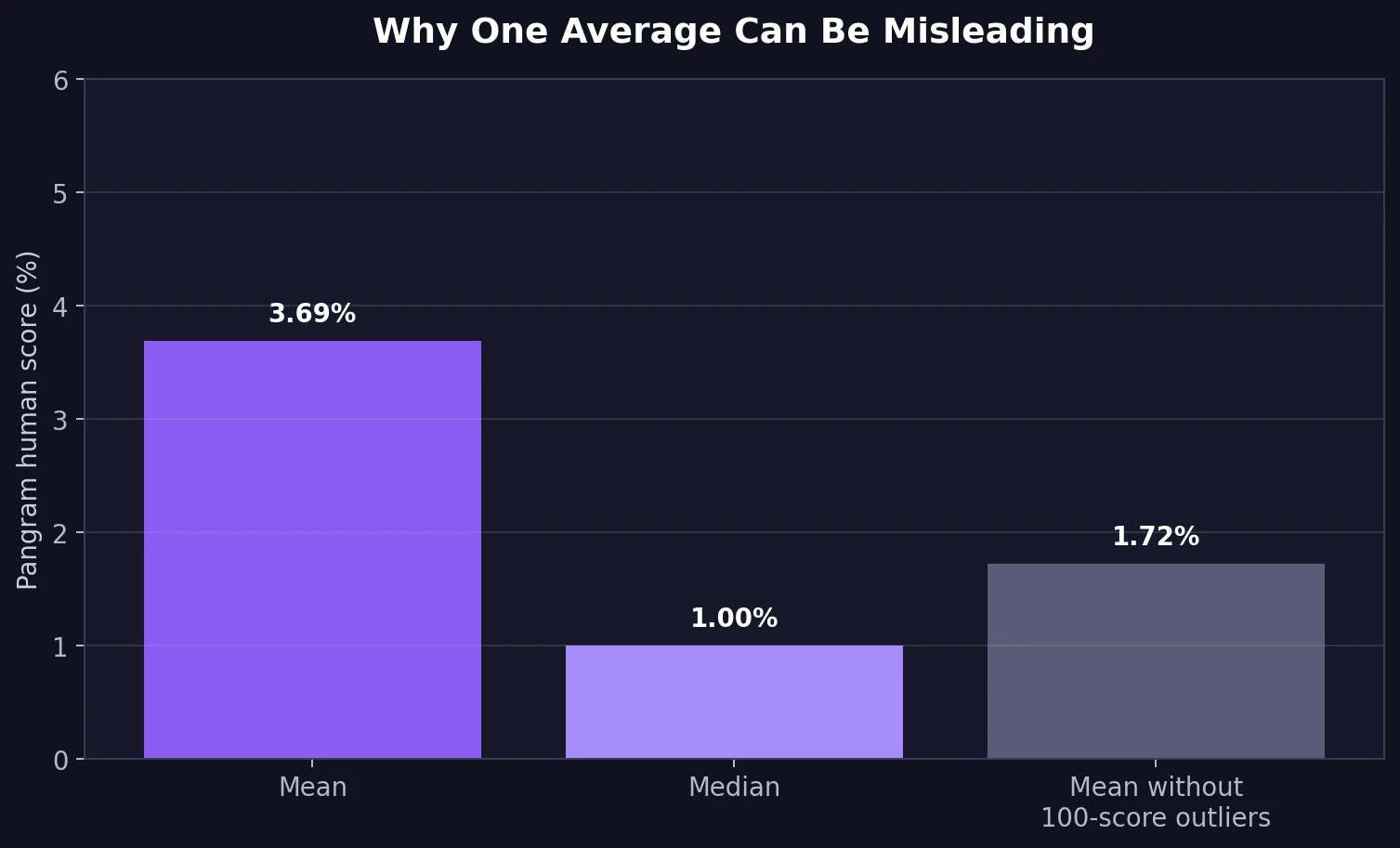
The overall average human score was 3.69%, which already looks poor. Yet even that figure is inflated by the two perfect scores. Remove those two outliers and the average falls to 1.72%. The median stays at just 1%, and 82 samples received exactly that score.
A Higher Detector Score Did Not Guarantee Better Writing
Detection is only half of the test. A rewrite that changes the intended meaning, damages a list, or introduces broken grammar is not a useful success. The two 100% human samples make this especially clear. One changed “18th dynasty” to “18 th dynasty”, misspelled Tutankhamun as “Tutancamun”, and used awkward phrases such as “the history of the ancient Egypt.” The other included sentences such as “Fossil fuel has been a crucial part of human civilization thousands of years.”
In other words, Pangram occasionally accepted a rewrite that still needed a careful human edit. Beating a score and producing dependable writing are not the same achievement.
Also Read: [STUDY] Can Stealthwriter Really Bypass Copyleaks? What 100 Samples Show
What Broke Inside the Rewrites?
Recurring problems found in the CSV
- Contradictions: An Amazon Prime passage originally said the service grew beyond two-day shipping. The rewrite said it “no longer offer[s] two-day shipping,” changing the claim.
- Damaged formatting: A five-item breakfast list became numbered 2, 2, 3, 4, 5. Another heading appeared as lowercase “3. smell the vegetables.”
- Grammar breakdown: One cloud-server rewrite said, “enables you to be able to adapts … and be able to scale.”
- Meaning drift: Editing photos became creating “spectacular paintings,” while “clear bins” became generic bins, weakening the original advice.
- Technical distortion: A sonar passage changed sounds already present in the water into sounds “already reflected” in the water.
- Odd or gibberish wording: Examples included “rumble amongst a great stack of junk,” “a novice manual,” and vegetables being “out of shape.”
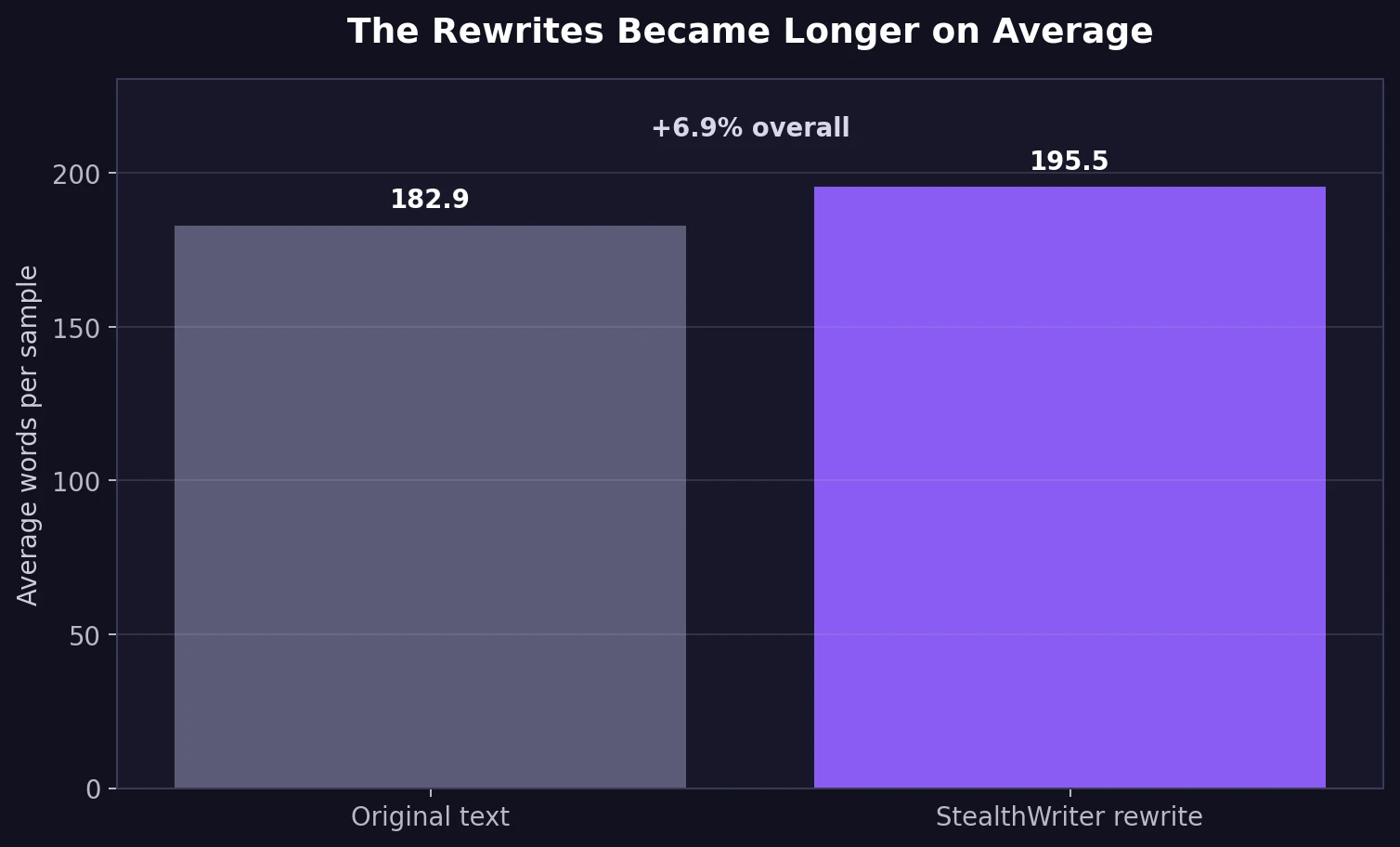
The rewrites also became longer. The average passage grew from 182.9 to 195.5 words, an increase of about 6.9%. Twenty-seven samples expanded by more than 10%, and nine expanded by more than 15%. Extra words are not automatically bad, but here they often arrived as repetition, filler, or less natural phrasing.
Also Read: [STUDY] Can Stealthwriter Outsmart GPTZero? A 100-Sample Test
Two Tools, Two Very Different Stories
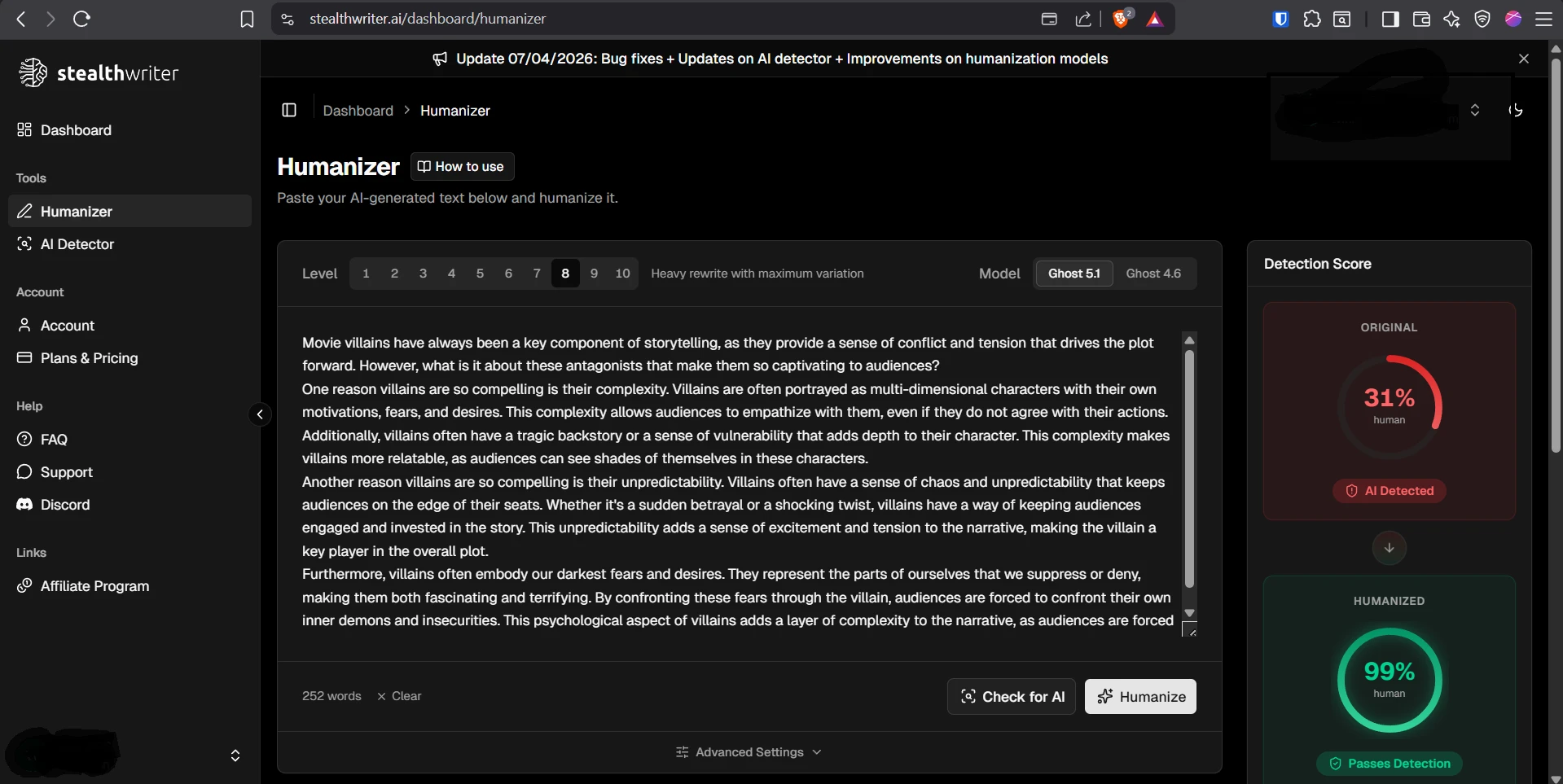
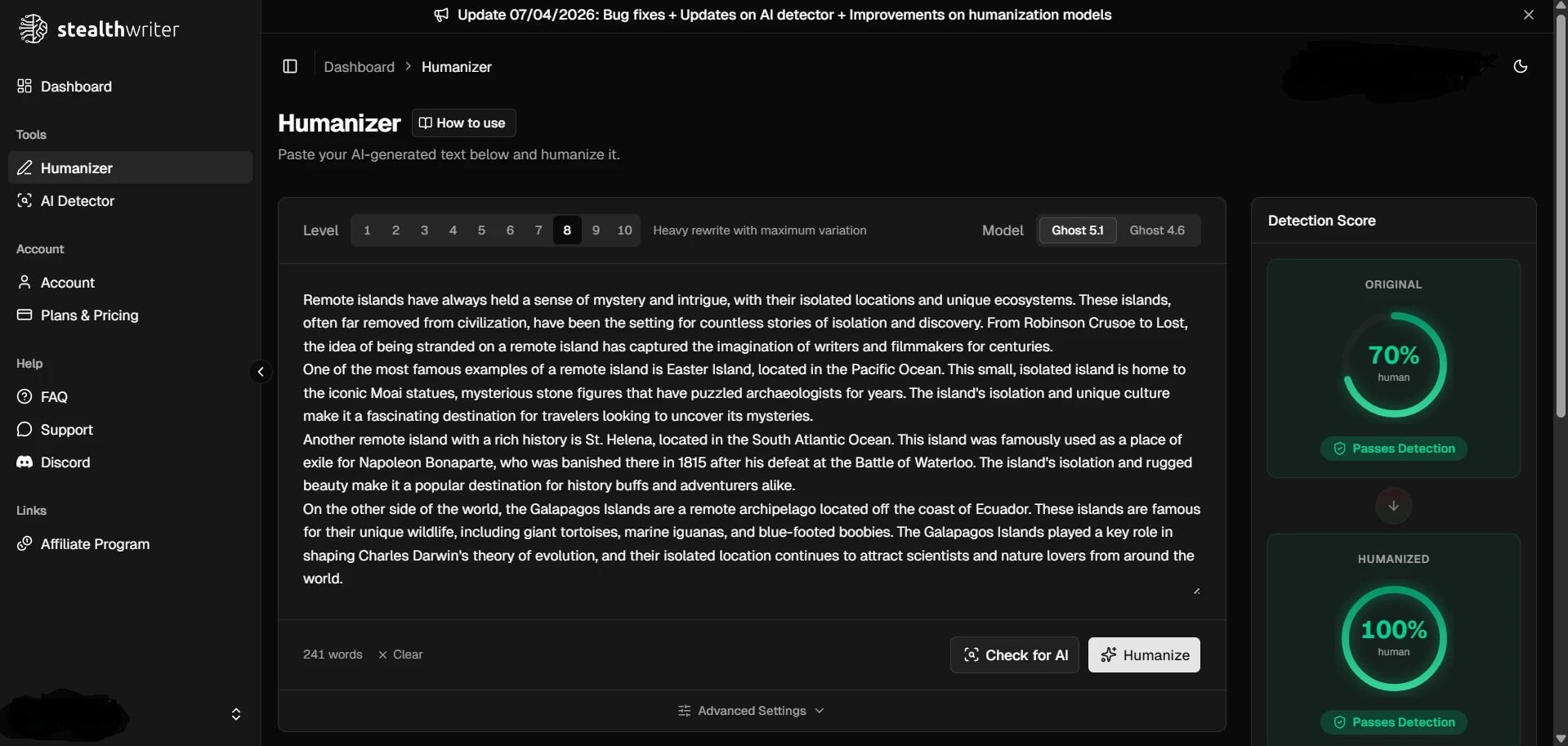
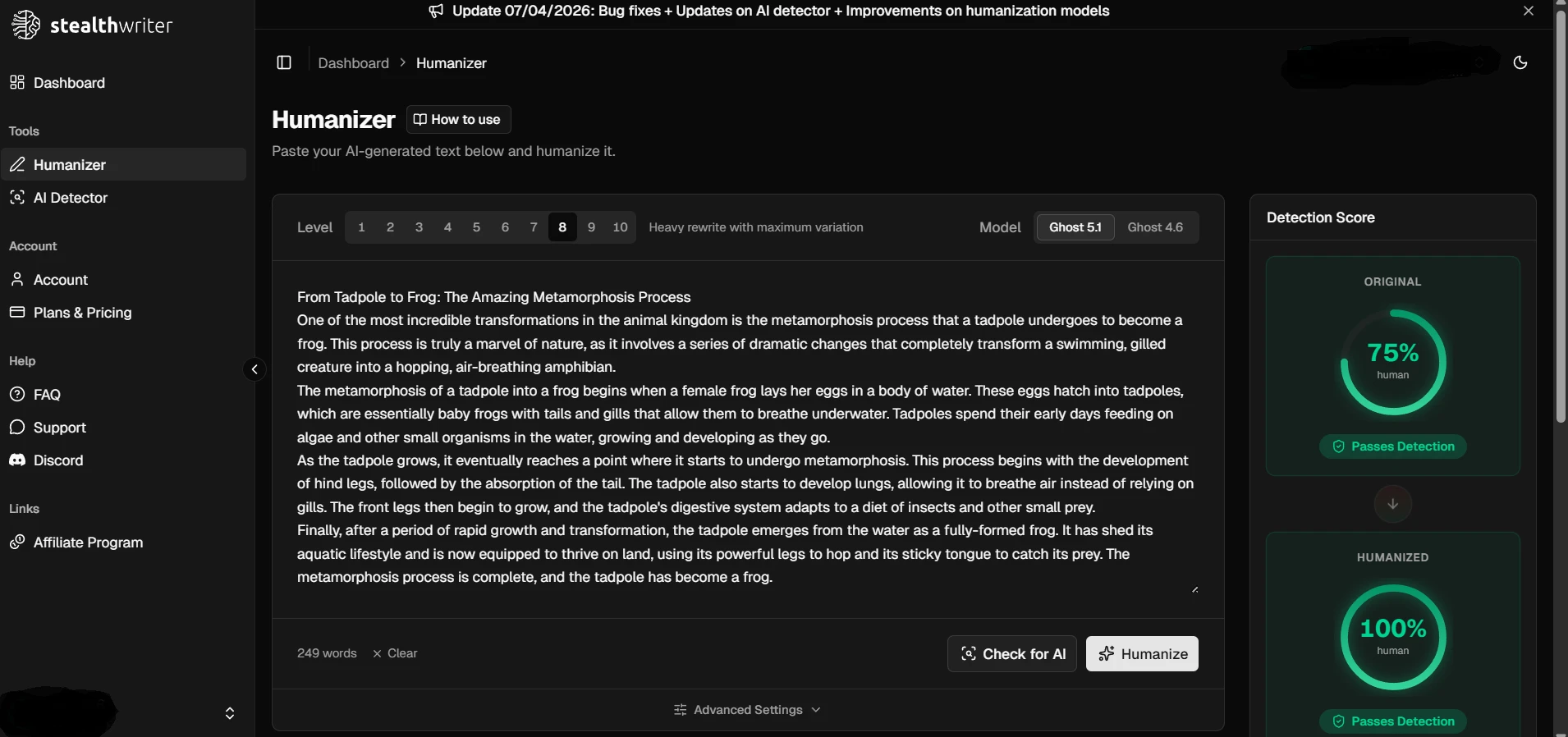
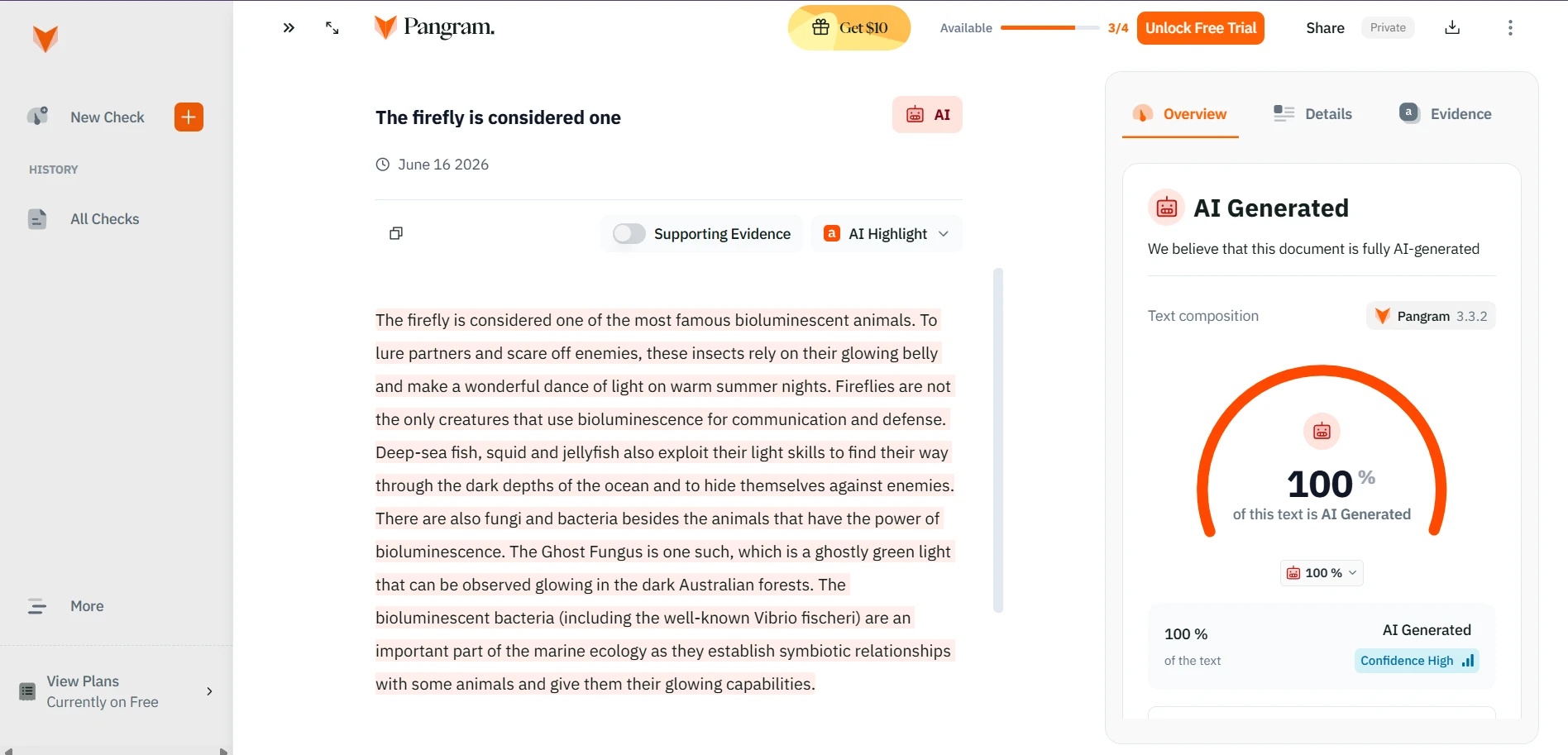
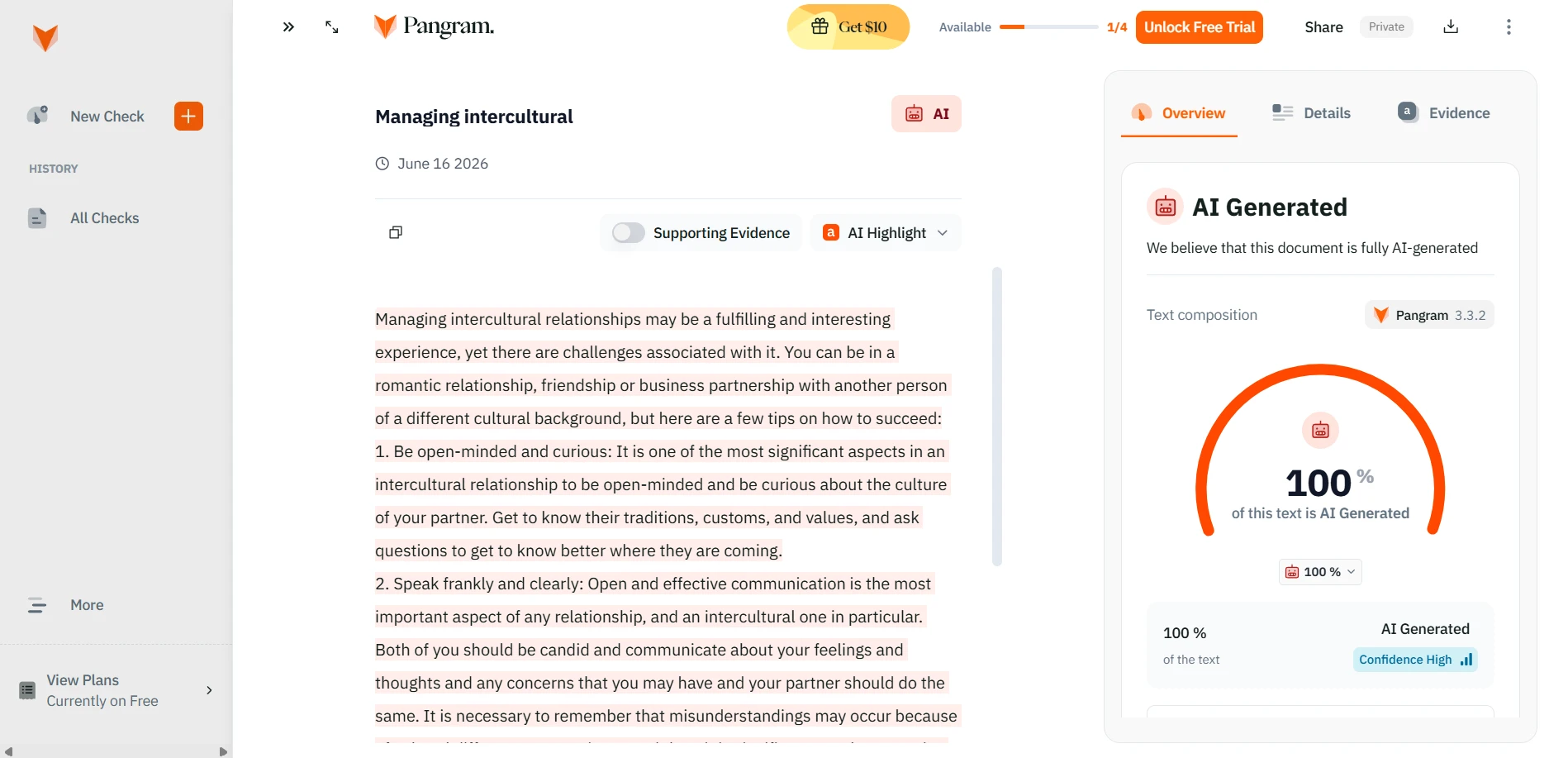
The supplied screenshots show StealthWriter reporting its humanized outputs as roughly 99–100% human, while the Pangram checks shown below classify the tested passages as 100% AI-generated. Detector disagreement is normal, but a gap this large is a warning against trusting a tool’s own success badge as independent proof.
StealthWriter’s dashboard results
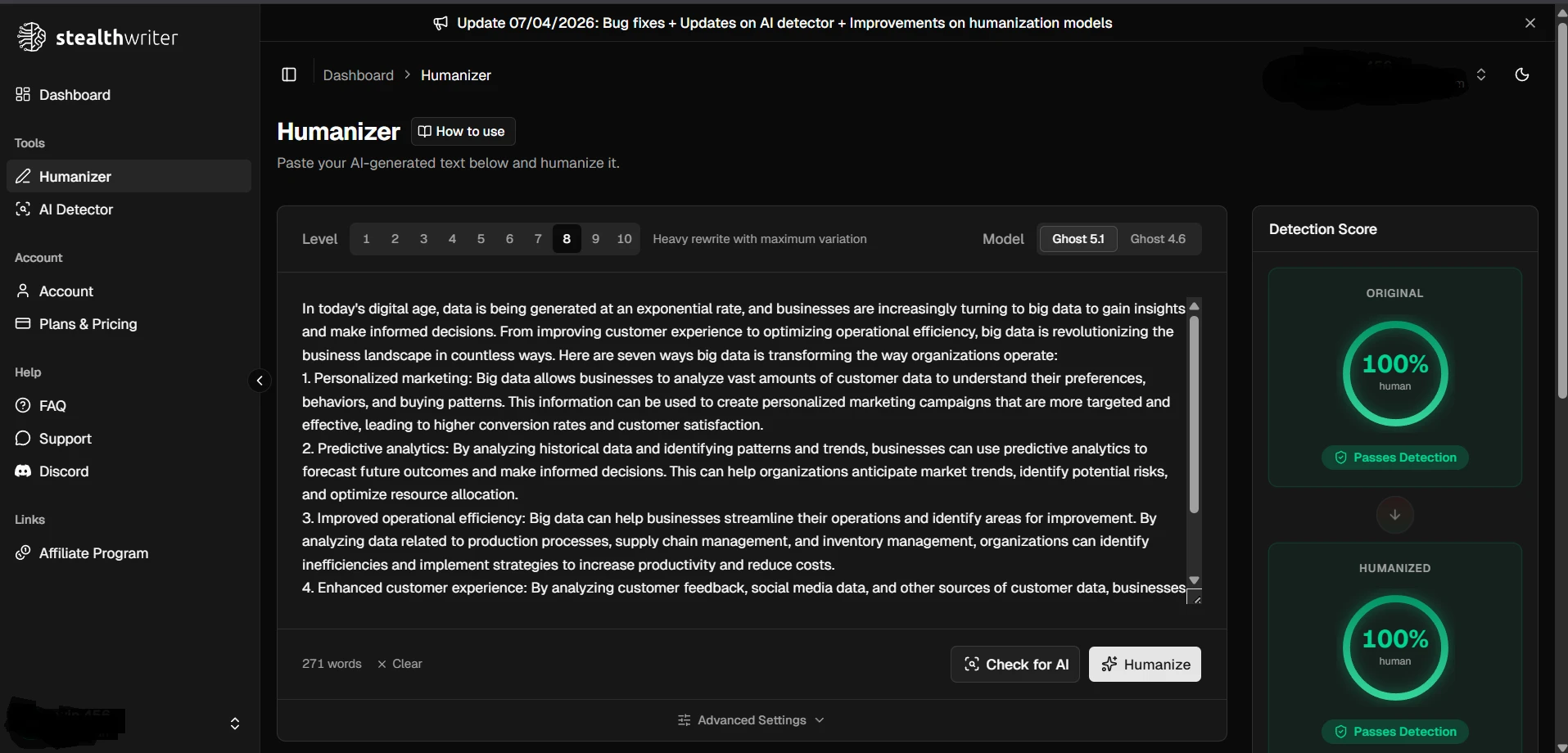
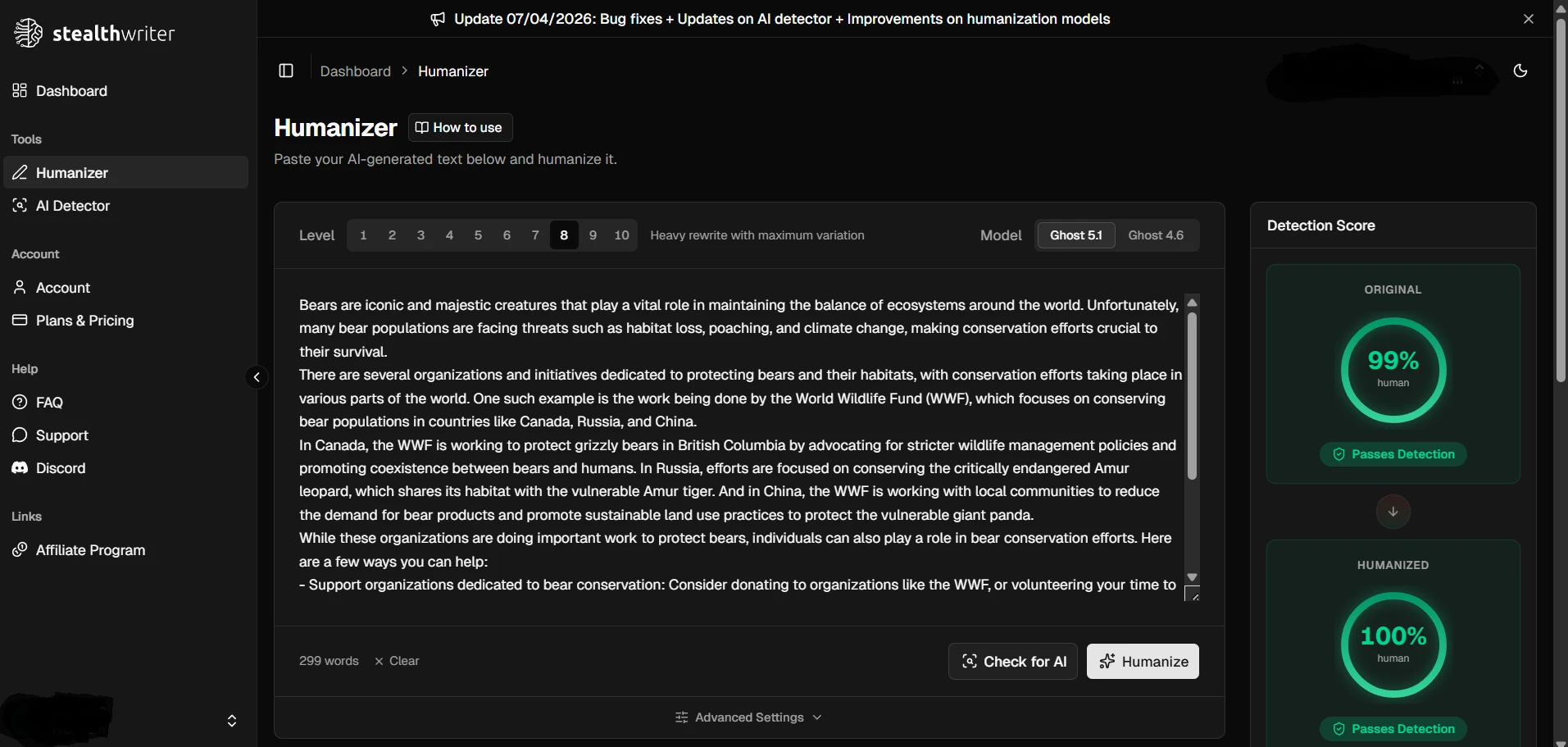
Pangram’s results on tested rewrites
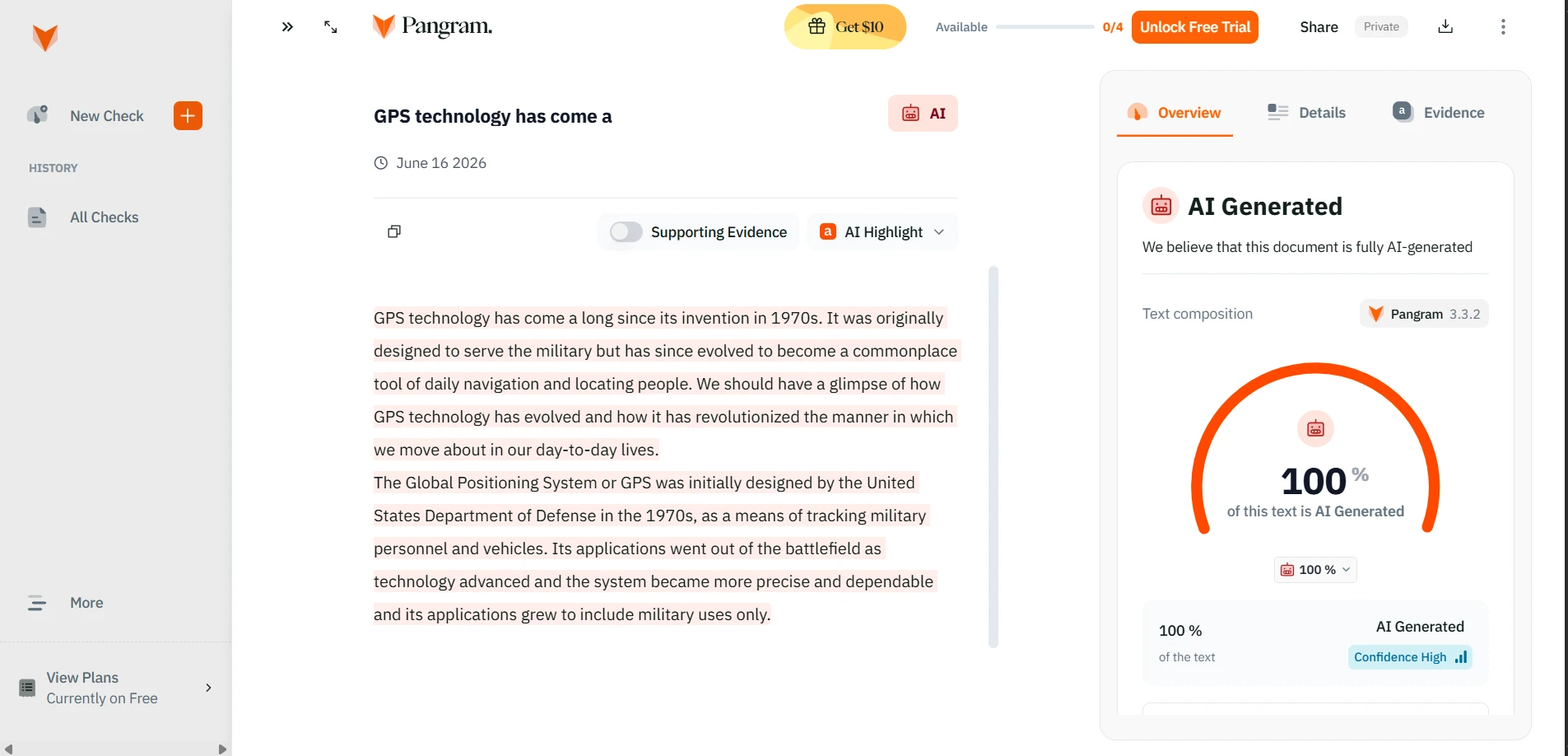
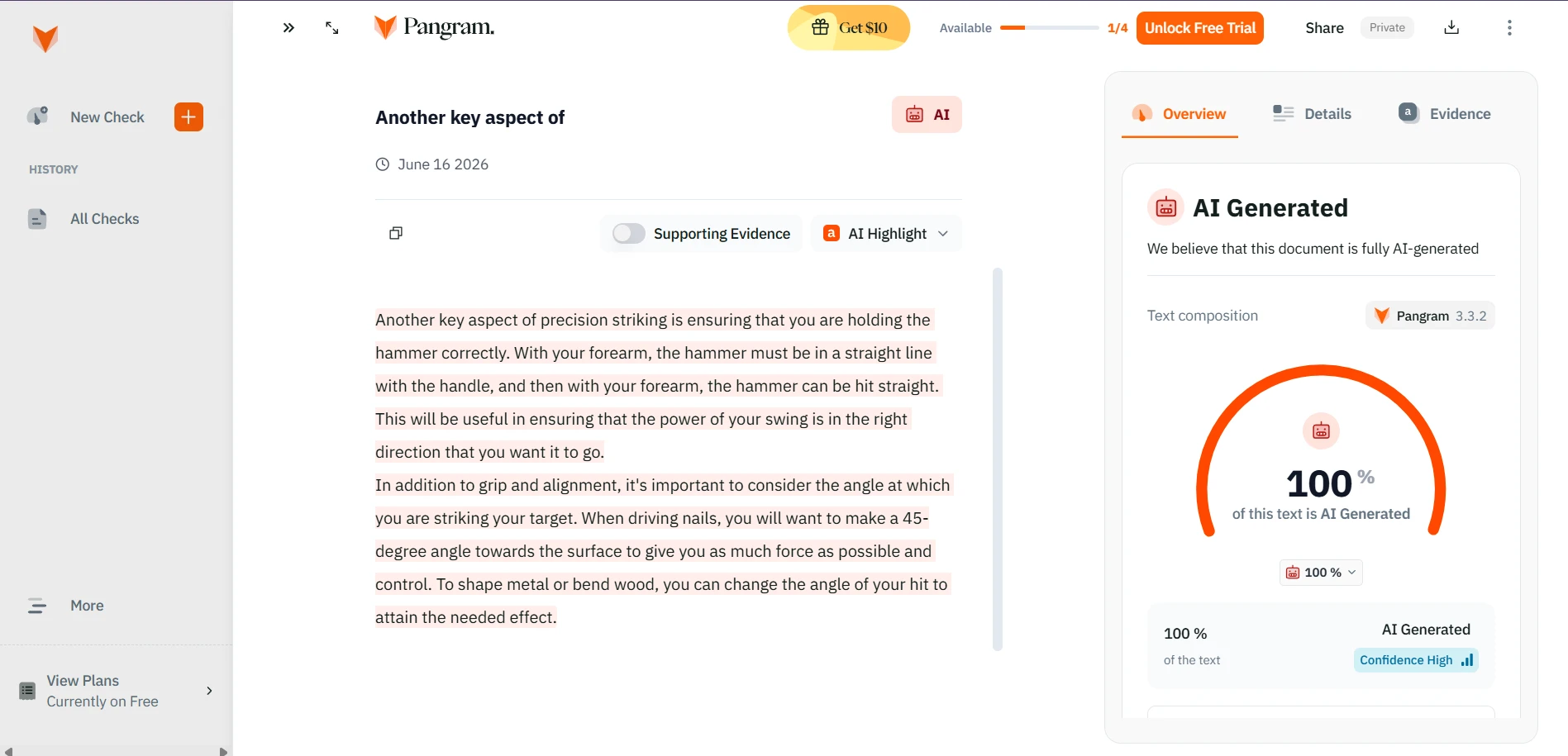
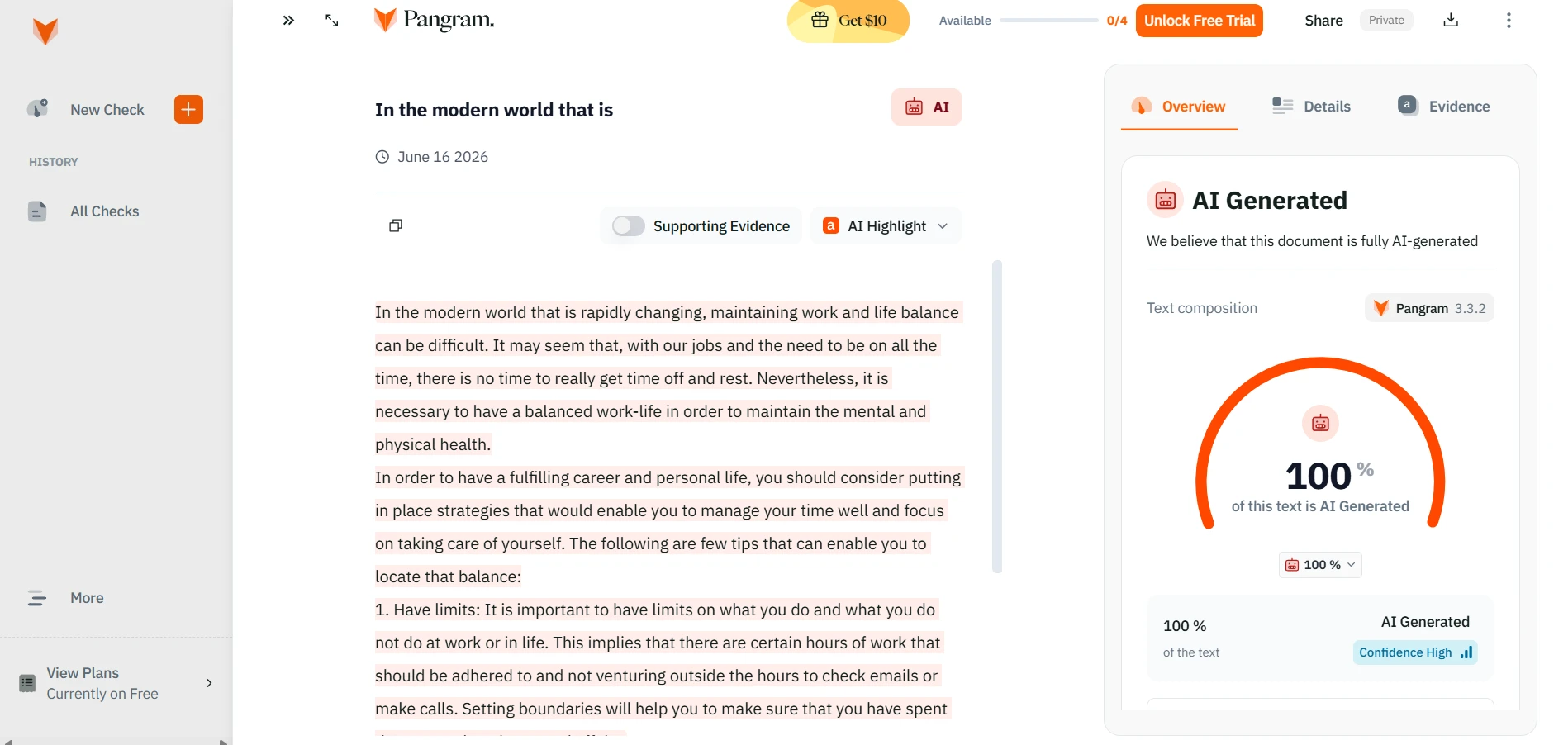
The Verdict: Rare Bypasses, Frequent Trade-Offs
On this 100-sample dataset, StealthWriter was not consistently effective against Pangram. Using a 50% human cutoff, its apparent bypass rate was only 2%. More importantly, even the strongest detector results contained spelling, grammar, and clarity problems.
For students, the lesson is bigger than any single product: a “human” score is not a quality certificate. Detector outputs can disagree, and automated rewriting can quietly alter facts or weaken your argument. Read every sentence, verify every claim, and treat detection percentages as uncertain signals—not as proof that a piece of writing is accurate, natural, or ready to submit.