

AI detectors are often sold as quick truth machines. Paste in a paragraph, get a label, and move on. But anyone who has spent time with these tools knows the reality is messier. A detector can look impressive when it catches obviously machine-written text, yet still cause real problems if it wrongly flags human work. That is why the right question is not simply whether the tool catches AI. The better question is whether it does so reliably enough to be trusted.
How this Sapling test was set up
To test Sapling, I analyzed a CSV file containing 160 samples. The dataset includes 78 texts actually written by humans and 82 texts actually written by AI. The Written By column is the ground truth. Sapling gives two outputs: a final label in Sapling Detected it as and a score in Sapling Score, where 1 means the text looks human and 0 means it looks AI-written.
Also Read: Can Undetectable.ai Really Slip Past Sapling AI? We Tested 100 Rewrites to Find Out.
The short answer
The headline result is simple: Sapling was much better at catching AI than at clearing human writing. Across the full dataset, it reached an overall accuracy of 63.1%. That sounds decent at first glance, but the split behind that number matters more than the average.
| Metric | Result |
|---|---|
| Overall accuracy | 63.1% |
| AI recall (how often real AI was caught) | 91.5% |
| Human recall (how often real human writing was cleared) | 33.3% |
| False positive rate on human writing | 66.7% |
| Balanced accuracy | 62.4% |
| ROC AUC from the score alone | 0.716 |
Also Read: [STUDY] StealthWriter vs Sapling AI: Can 100 Humanized Rewrites Slip Through?
Confusion matrix: where Sapling got it right and wrong
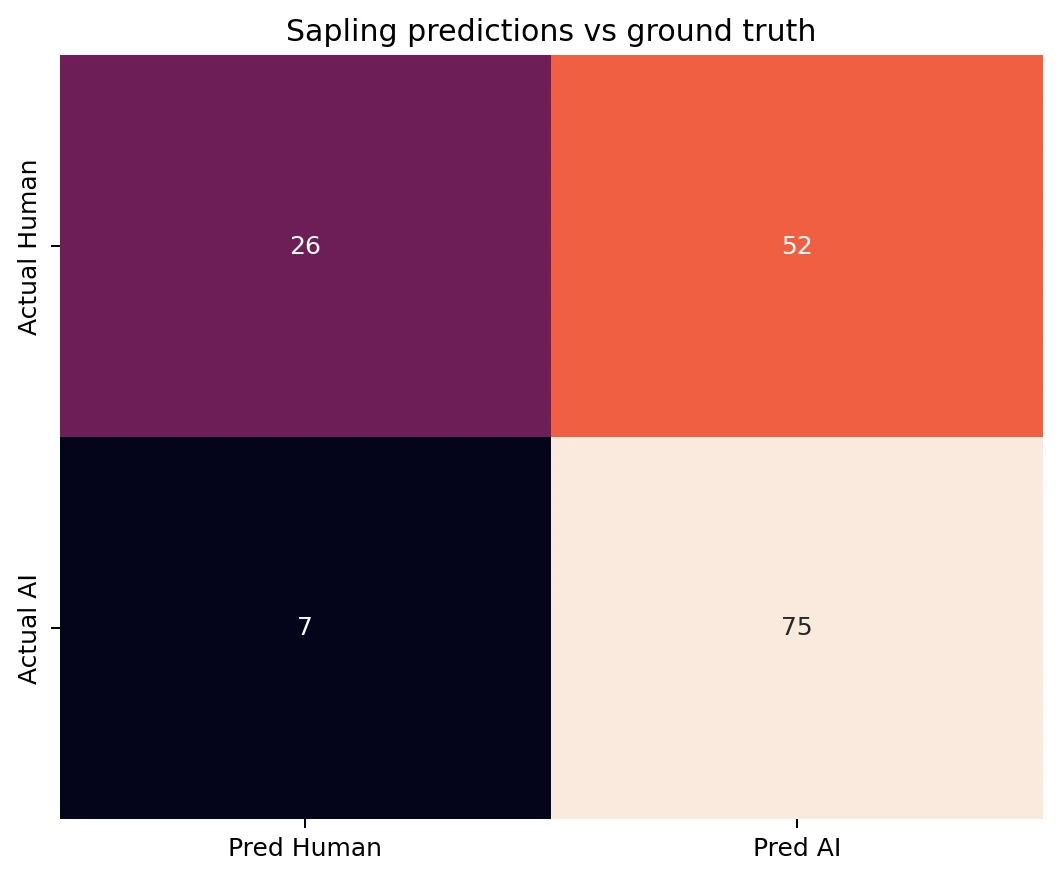
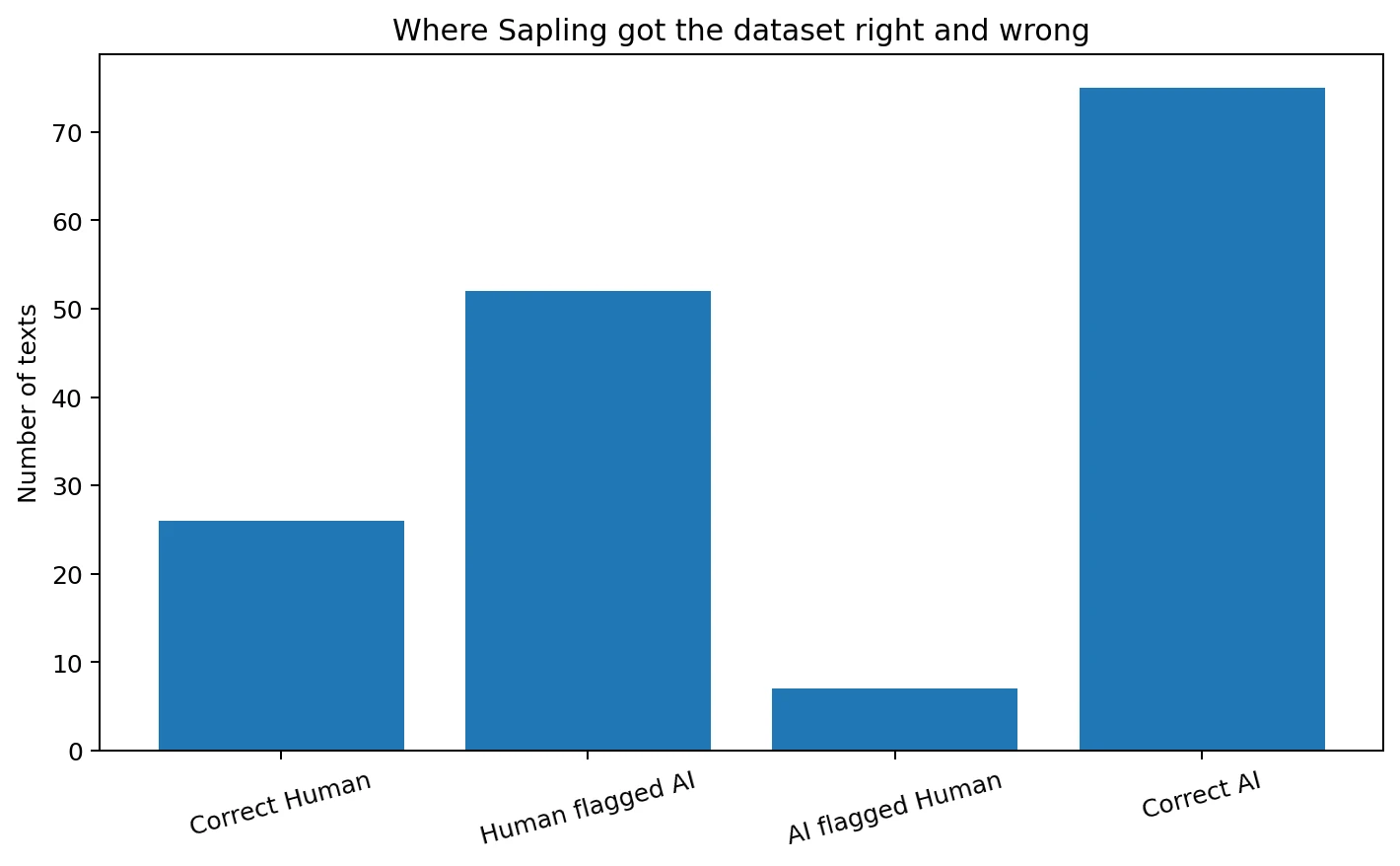
The confusion matrix reveals the core issue. Out of 78 human-written texts, Sapling correctly marked only 26 as human. It wrongly labeled 52 human texts as AI. That means about 66.7% of the real human samples were false alarms. By contrast, Sapling correctly caught 75 of 82 AI texts and missed only 7. In plain language, Sapling behaves like an aggressive filter. It prefers to accuse rather than let suspicious text pass.
Also Read: I Tested 100 BypassGPT Rewrites Against Sapling.ai. The Result Wasn’t What the Hype Suggests.
Why the false positives matter
Whether that feels acceptable depends on the use case. If someone is screening large amounts of text and wants a detector that rarely misses AI, Sapling may look useful because its AI recall is high. But if the tool is being used in classrooms, hiring, publishing, or moderation, a false accusation rate this high is a serious weakness. A detector that flags two out of every three human texts as AI is not behaving like a dependable judge. It is behaving like a very nervous alarm.
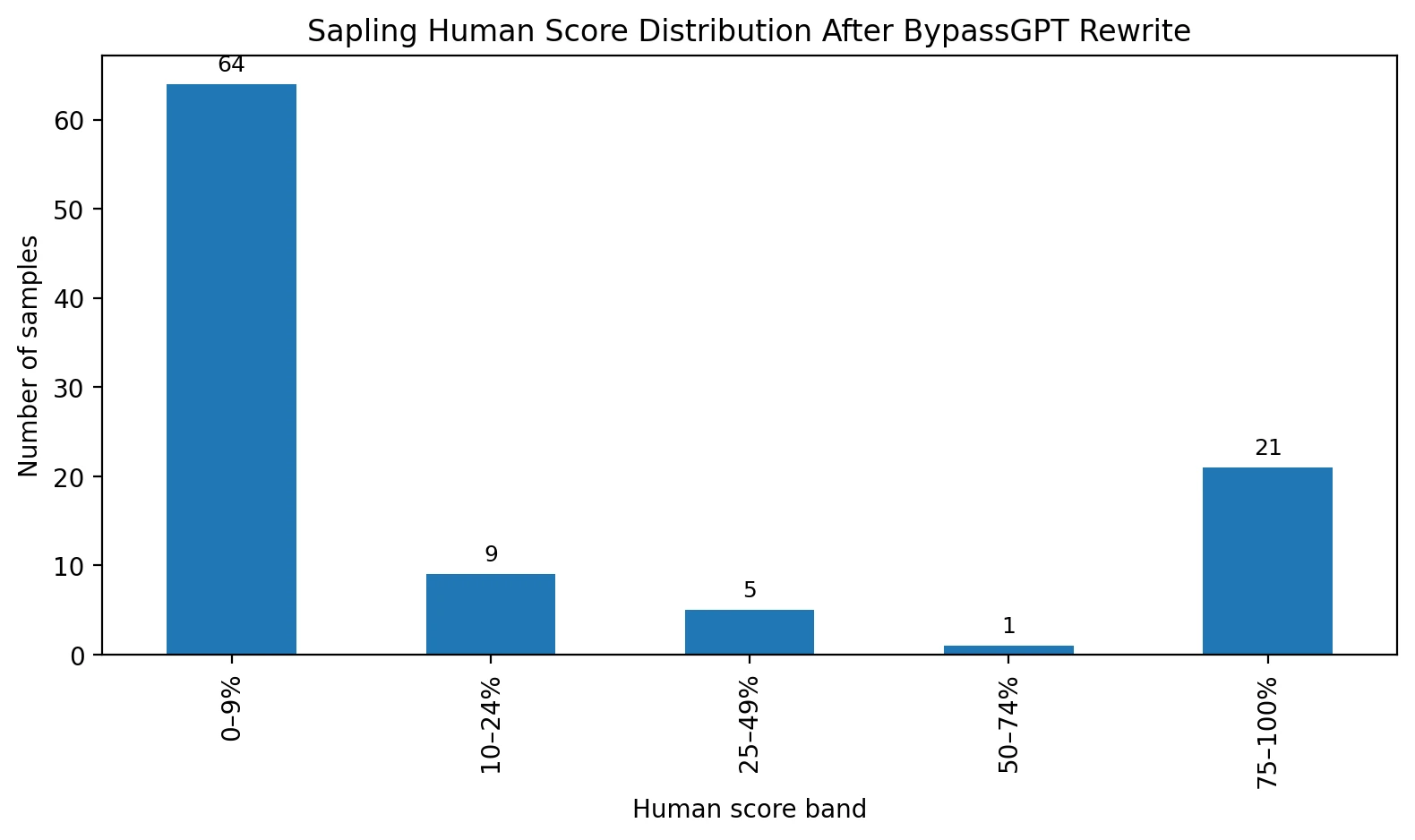
What the Sapling score actually tells us
The score distribution makes the problem even clearer. On average, human-written texts received a score of 0.339, while AI texts averaged 0.102. So the score does contain some signal: human writing tends to score higher, and AI writing tends to score lower. However, the two groups overlap a lot. Many human samples sit close to zero, which means Sapling treats them as strongly AI-like. That overlap is exactly why the final label struggles.
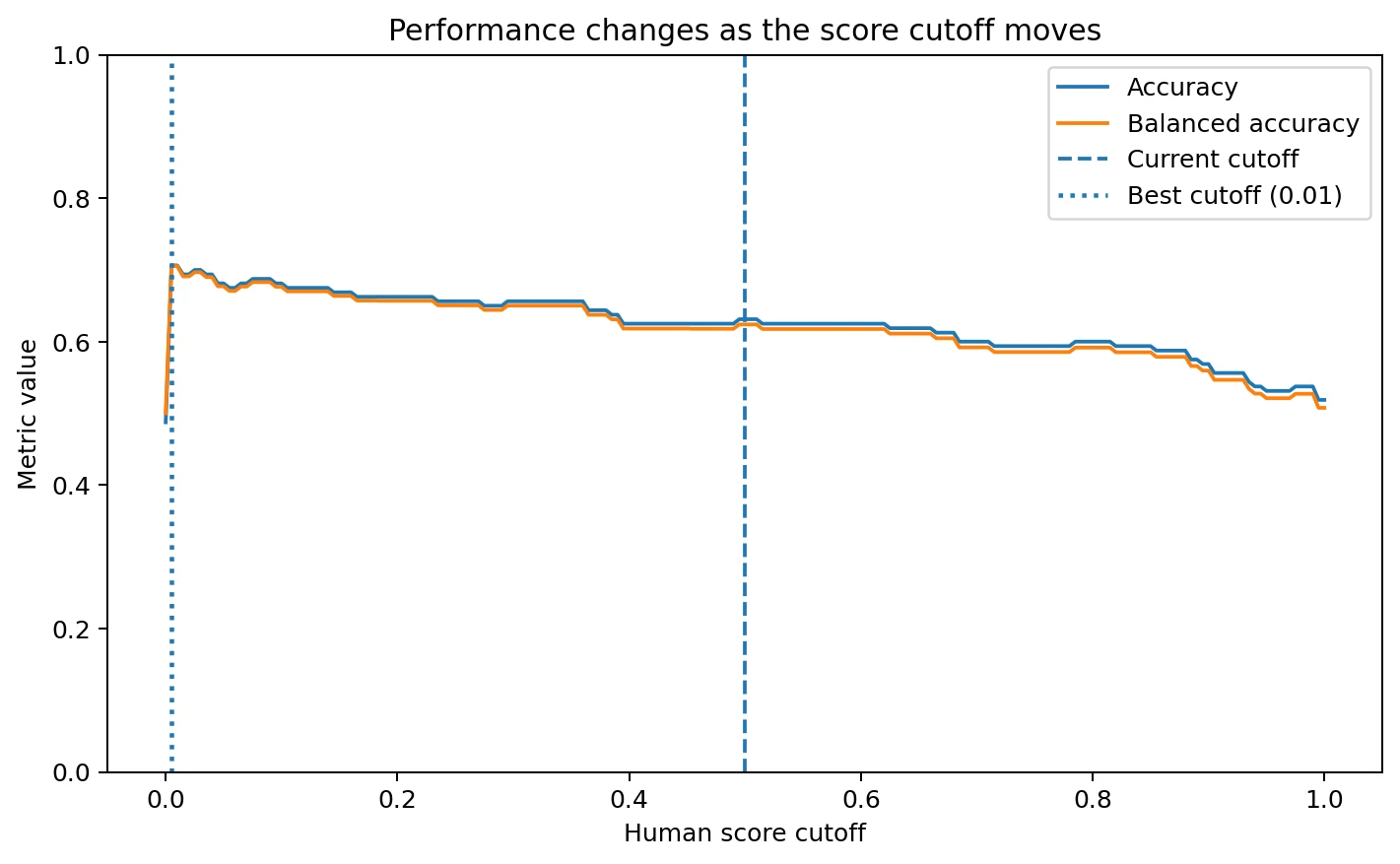
Threshold analysis: the built-in cutoff looks too harsh
Another important detail is Sapling’s built-in cutoff. In this file, its final label behaves like a simple rule: scores of 0.50 or above are labeled human, and scores below that are labeled AI. That threshold appears too strict for this dataset. When I tested different cutoffs using the same score, the best overall accuracy came from a threshold around 0.01, which increased accuracy to 70.6%. Balanced accuracy also improved to 70.5%.
This does not mean the detector suddenly becomes excellent. It simply shows that the raw score is a bit more informative than the final label suggests. In other words, Sapling’s score contains moderate ranking power, but its default decision rule is too harsh on human writing in this sample. That is why the ROC AUC lands at 0.716: better than random, but far from strong enough to treat as proof.
Why accuracy alone is not enough
There is a broader lesson here. Accuracy by itself can hide a bad user experience. Imagine two detectors that both score around 63%. One detector makes balanced mistakes. The other catches almost all AI but wrongly accuses most human writers. Those two systems are not equally useful, even if the headline percentage looks similar. In practice, the second one can create more damage because people feel the false positives directly. Students, job applicants, and writers do not care that a detector is “pretty accurate on average” if it keeps labeling their original work as machine-generated.
Final verdict: is Sapling AI detector accurate?
So, is Sapling accurate? The fairest answer is partly, but not reliably enough. It is reasonably strong at identifying AI-written text in this dataset, but it is weak at recognizing genuine human writing. That imbalance matters because real-world trust depends on both sides. A detector should not only catch AI. It should also avoid turning normal human prose into a false accusation.
If you are using Sapling, the safest way to read its output is as a warning signal, not a verdict. A low score may justify a closer review, but it should not be treated as proof that the text is AI-written. Based on this dataset, the tool is too trigger-happy to deserve that level of confidence. The score has some value for ranking suspicion, yet the final label on its own is not accurate enough to be treated as a reliable decision-maker.
The bottom line is clear: Sapling is better at catching AI than it is at protecting human writers from false flags. That makes it useful as a rough screening tool, but a poor choice as a final judge of authorship.