

AI detectors are showing up everywhere—from classroom policies to online publishing. But if you're a student, the main question is simple: which detector is more trustworthy, and which one is more likely to falsely accuse you? I tested 160 samples (a mix of human and AI writing) and compared ZeroGPT.com vs QuillBot's AI Detector using their "human score" outputs (higher = more human).
The Testing Methodology
I collected 160 text samples: 78 human-written and 82 AI-generated. Each sample was pasted into both detectors, and I recorded the "Human Score" each tool reported.
How to read the scores: both tools give a number from 0 to 1. Think of it like a confidence meter. A score close to 1.00 means "very confident a human wrote it," while a score close to 0.00 means "very confident it is AI."
Also Read: Originality.ai vs Quillbot AI Detector
Key Statistical Findings:
- On human-written text (higher is better): ZeroGPT averaged 89.3% human. QuillBot averaged 100.0% human.
- On AI-generated text (lower is better): ZeroGPT averaged 23.1% human. QuillBot averaged 45.2% human.
- How often AI looked "fully human": QuillBot gave a perfect 1.00 to 27 / 82 AI samples (32.9%).
Visualizing the Data: Average Scores
The chart below compares the average human score each detector assigned to human-written vs AI-written text. (An average is the total divided by the number of samples.)
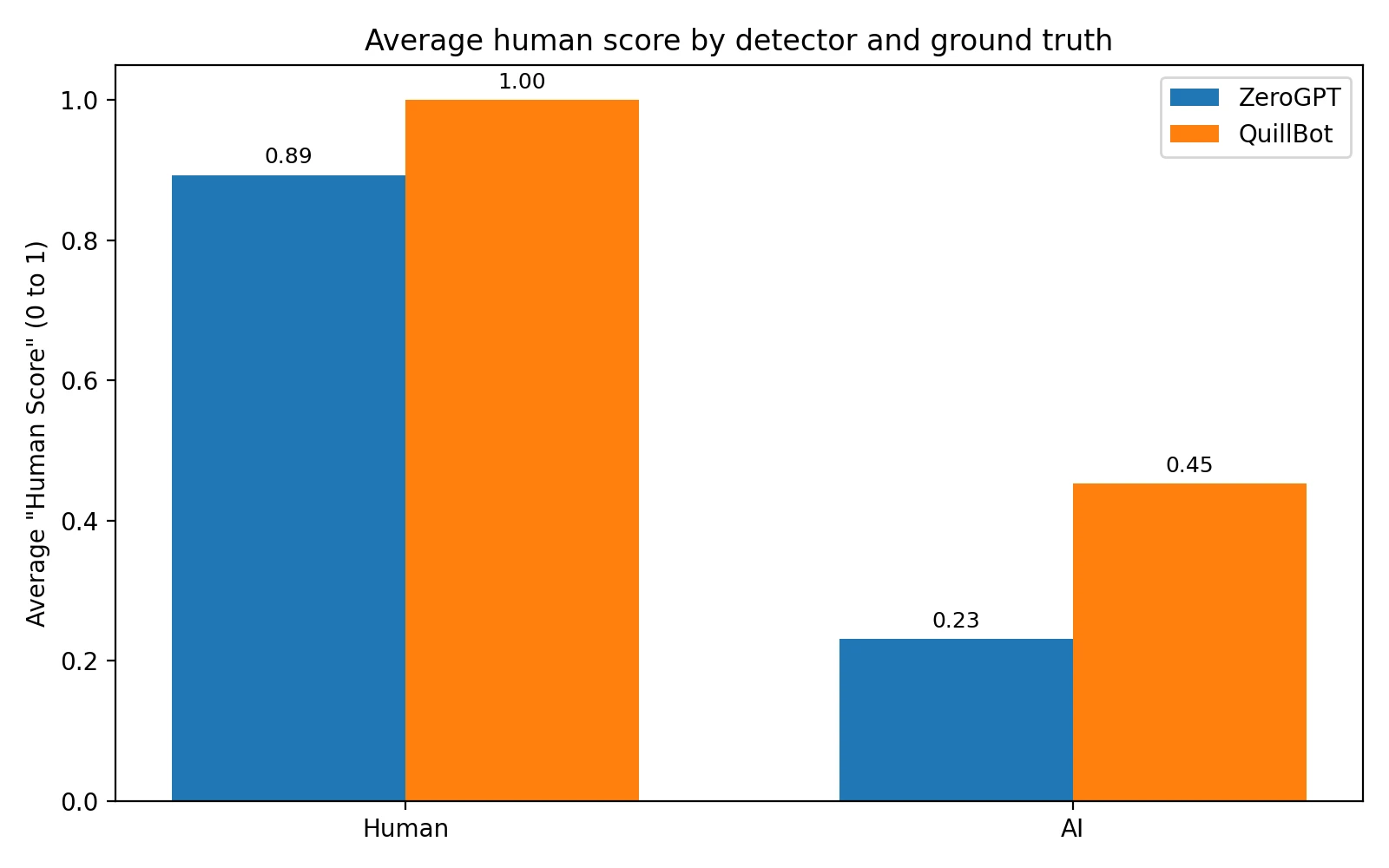
What stands out: QuillBot scores human writing extremely high (1.00 in every human sample I tested). That's comforting if you're worried about being accused. The tradeoff is that AI writing also gets fairly high "human" scores on QuillBot, making it easier for AI text to pass.
ZeroGPT, on the other hand, shows a bigger gap between human and AI averages, which is what you want if the goal is actually telling the two apart.
Also Read: Originality.ai vs Grammarly
Visualizing the Data: The False Positive Problem
The biggest fear with AI detectors is the false positive—accusing a human writer of using AI when they didn't. The opposite mistake is also important:
False positive: human text labeled as AI.
False negative: AI text labeled as human.
To compare apples-to-apples, I used a simple cutoff: if the human score is 0.50 or higher, I count it as "human". Otherwise I count it as "AI." (0.50 is a common midpoint.)
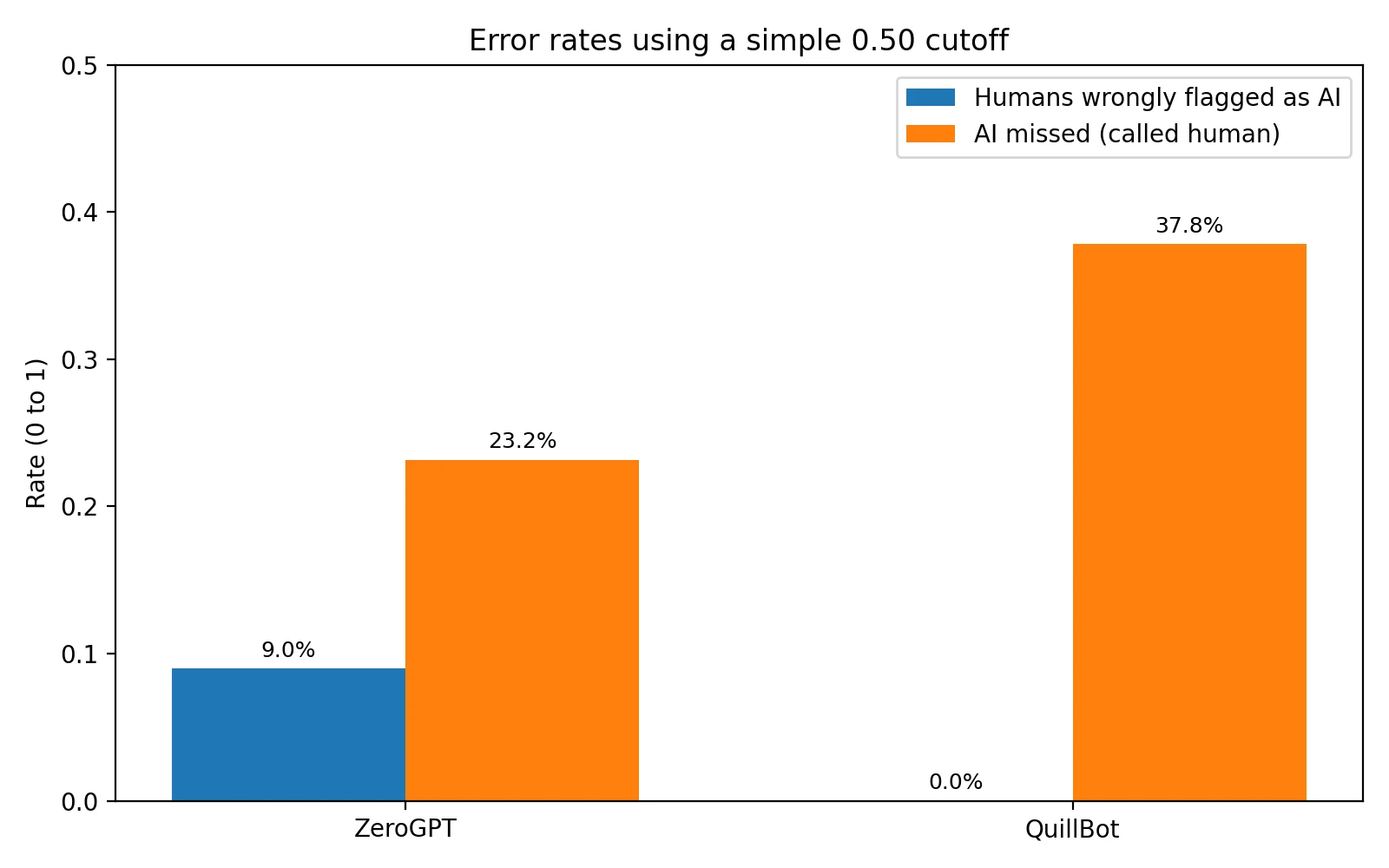
At the 0.50 cutoff:
- ZeroGPT falsely flagged 7 / 78 human samples as AI (9.0%) and missed 19 / 82 AI samples (23.2%).
- QuillBot falsely flagged 0 / 78 human samples as AI (0.0%) and missed 31 / 82 AI samples (37.8%).
Plain-English takeaway: QuillBot was safer for humans in this dataset (no false positives), but ZeroGPT was better at catching AI (fewer false negatives).
Deep Dive: Looking Beyond Averages
Averages can hide what happens on individual samples. This box plot shows the spread of scores.
How to read it: the line in the box is the median (the middle value). The box covers the middle 50% of scores. Smaller boxes mean the tool is more consistent.
Also Read: Originality.ai vs Sapling.ai Detector
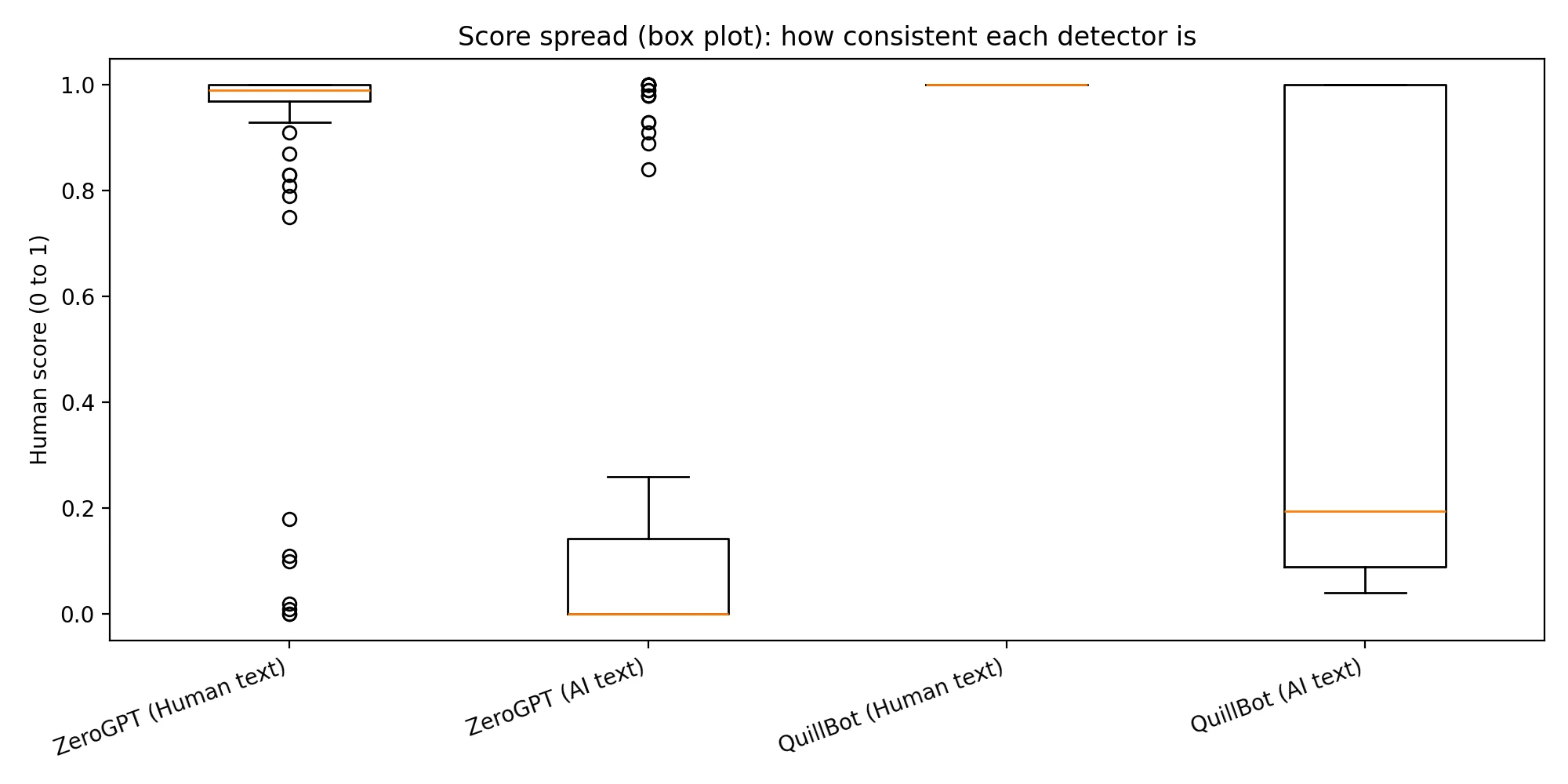
QuillBot's human-text box is basically a flat line at 1.00—it never showed doubt on the human samples I tested. ZeroGPT showed a small number of human samples scoring low (where a false accusation could happen), but it also pushed many AI scores much closer to 0.00 than QuillBot did.
Why Cutoffs Matter (and why results can change)
Detectors output a score, but schools and teachers decide what score counts as "AI." The chart below shows how overall accuracy changes as you move that cutoff.
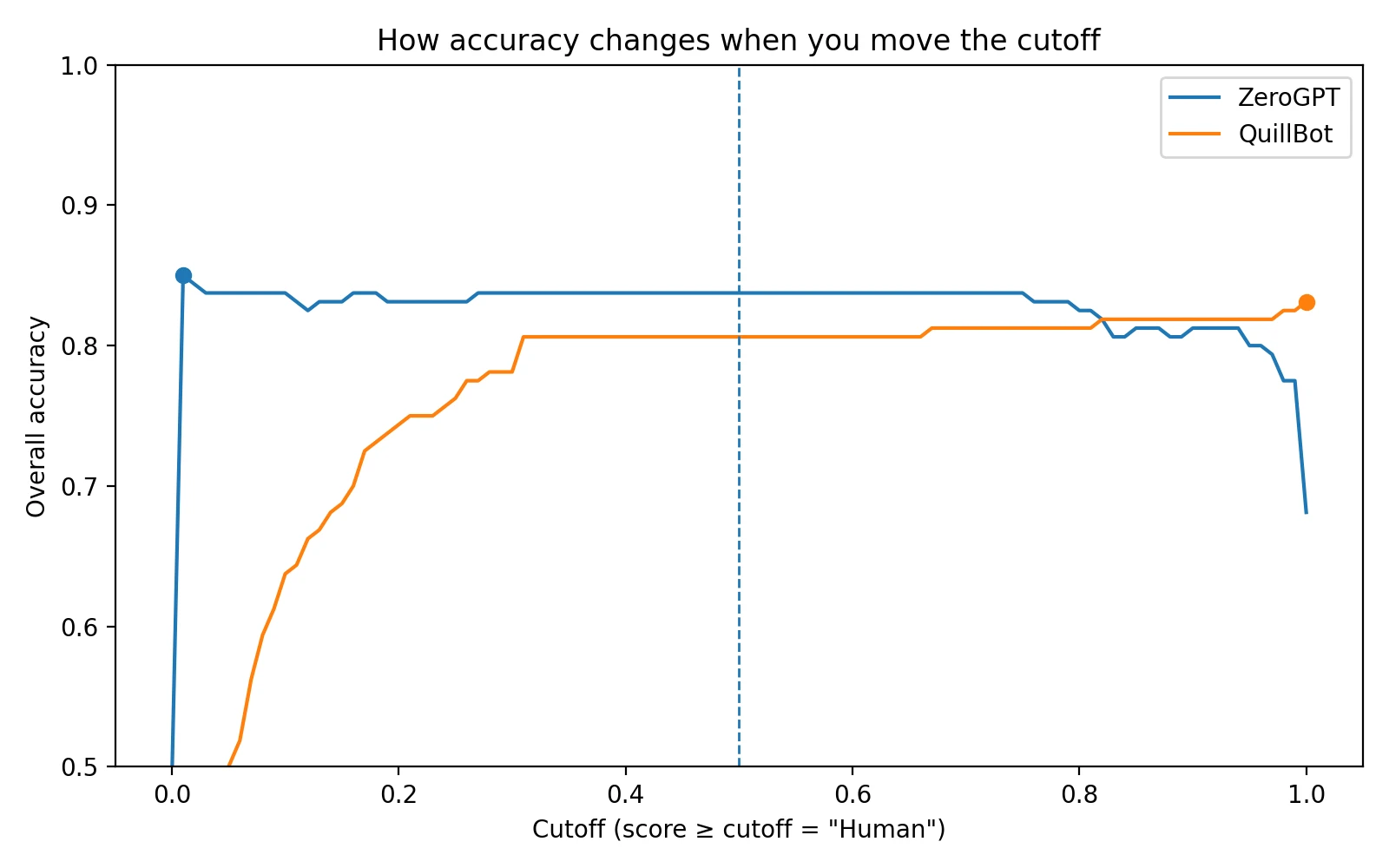
Student tip: if a detector score is used in a serious decision, ask what cutoff is being used and what extra evidence is required (drafts, outlines, revision history, sources). A single number shouldn't be treated like proof.
What These Results Mean for Students
If you're writing honestly, the scary part isn't "getting caught." It's getting misjudged by a tool that can be wrong. Based on this dataset, QuillBot was less likely to accuse a human writer, while ZeroGPT was better at spotting AI writing. That's a tradeoff, and it's why detector scores shouldn't be treated as final proof.
Here's a simple checklist to protect yourself if a detector result is ever questioned:
- Keep your drafts: save versions (Google Docs version history counts) so you can show how the work evolved.
- Keep your planning notes: outlines, bullet points, or sources you used are strong evidence of real work.
- Explain your process: being able to describe why you chose certain examples or arguments helps a lot.
- Don't chase a perfect score: rewriting just to "beat" a detector can make your writing worse and still isn't a guarantee.
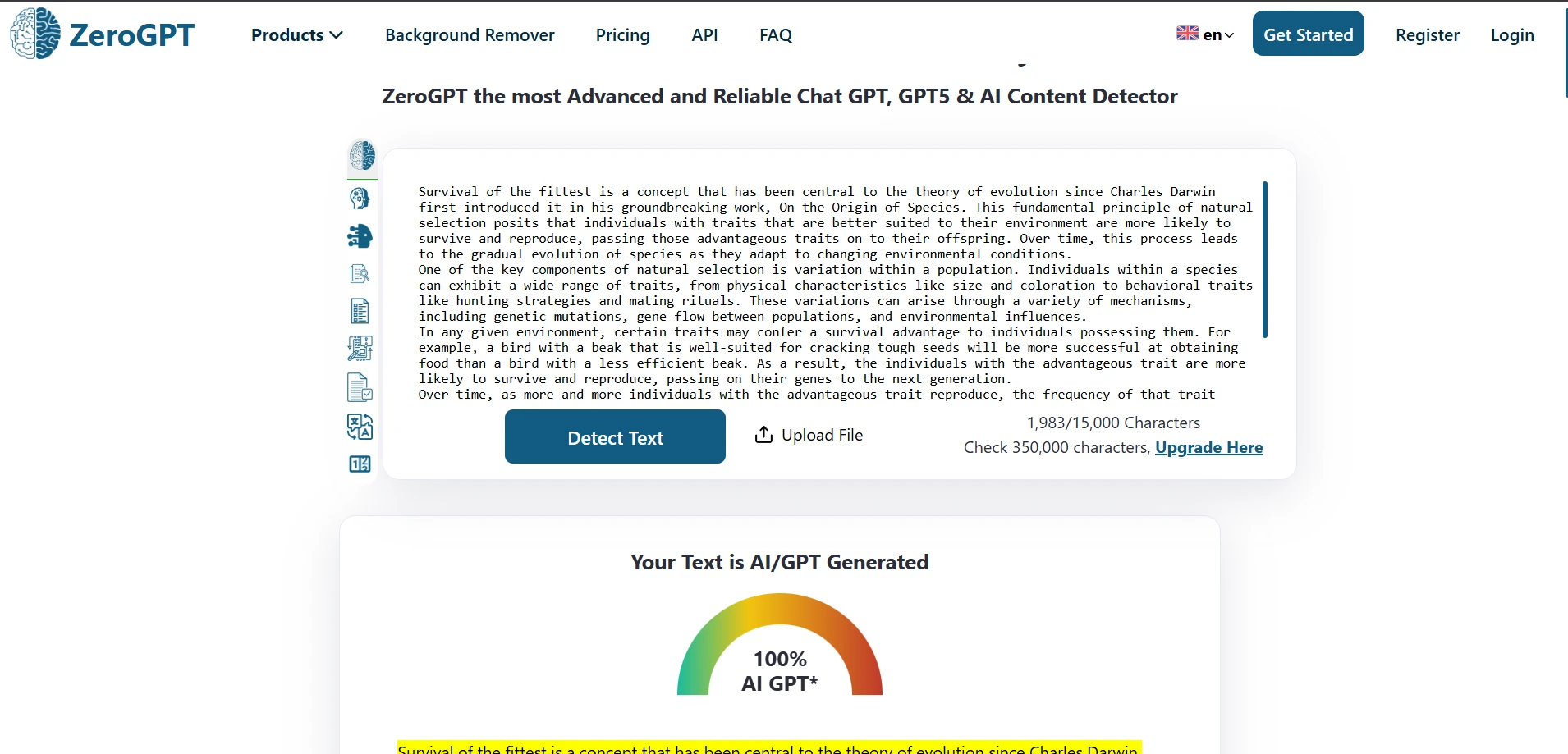
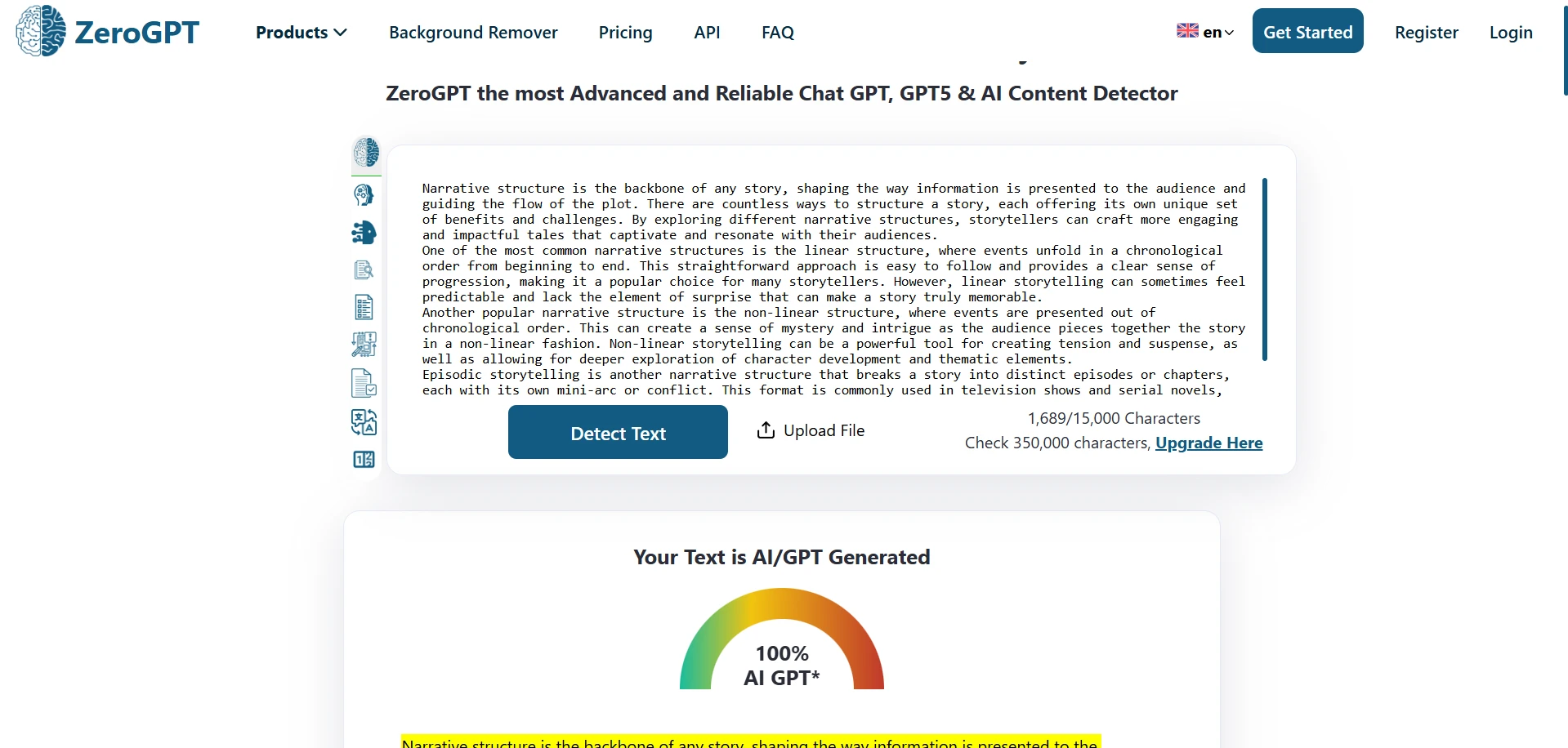
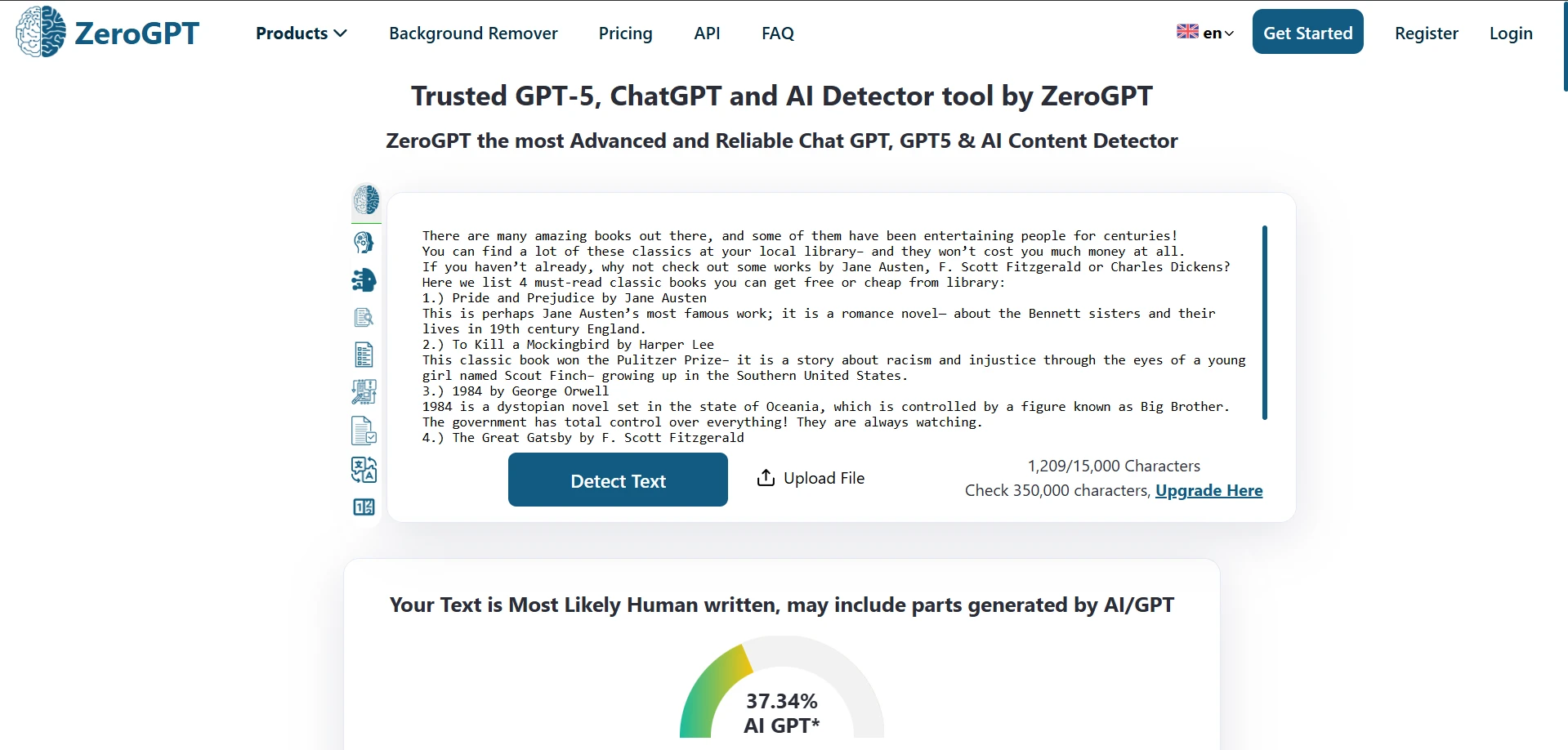
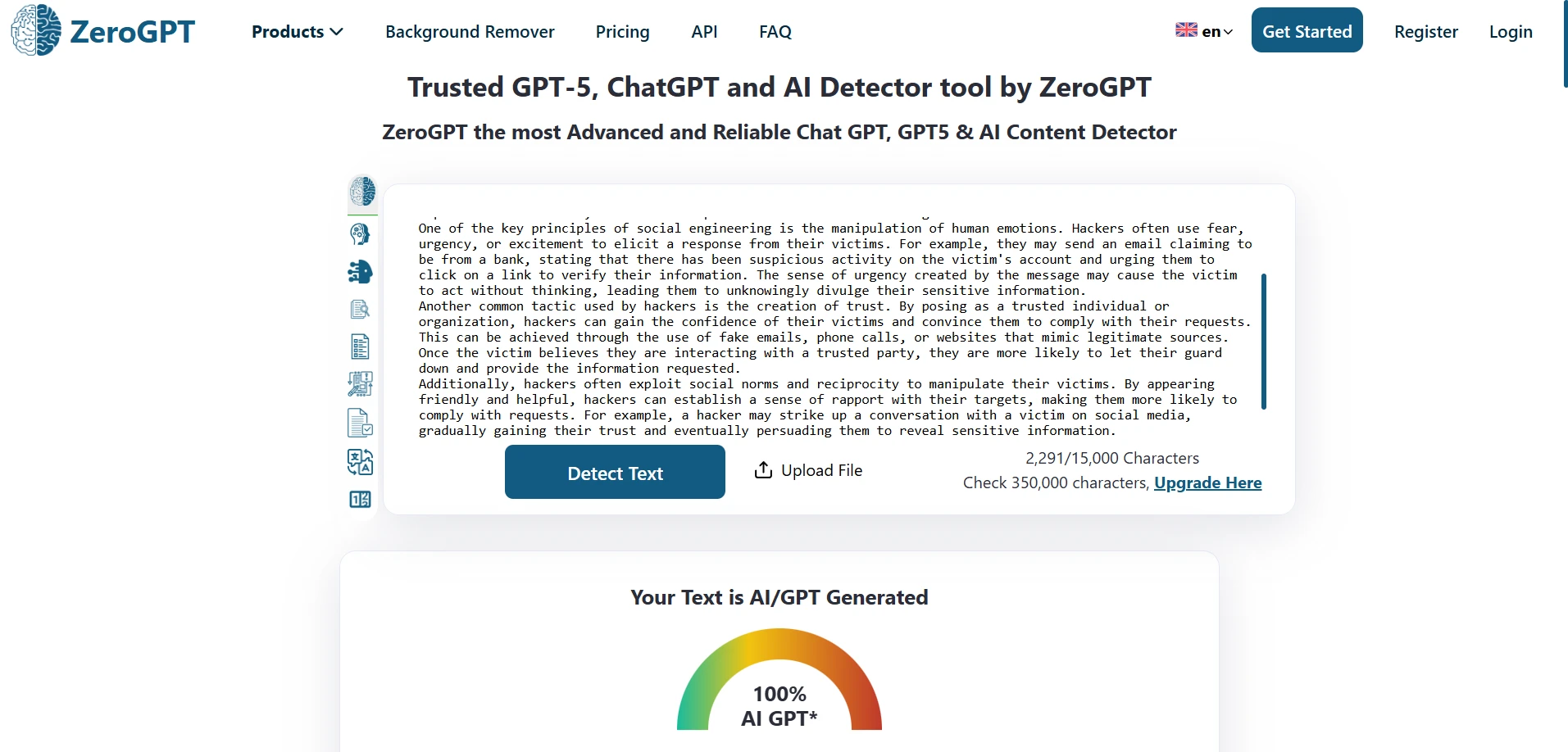
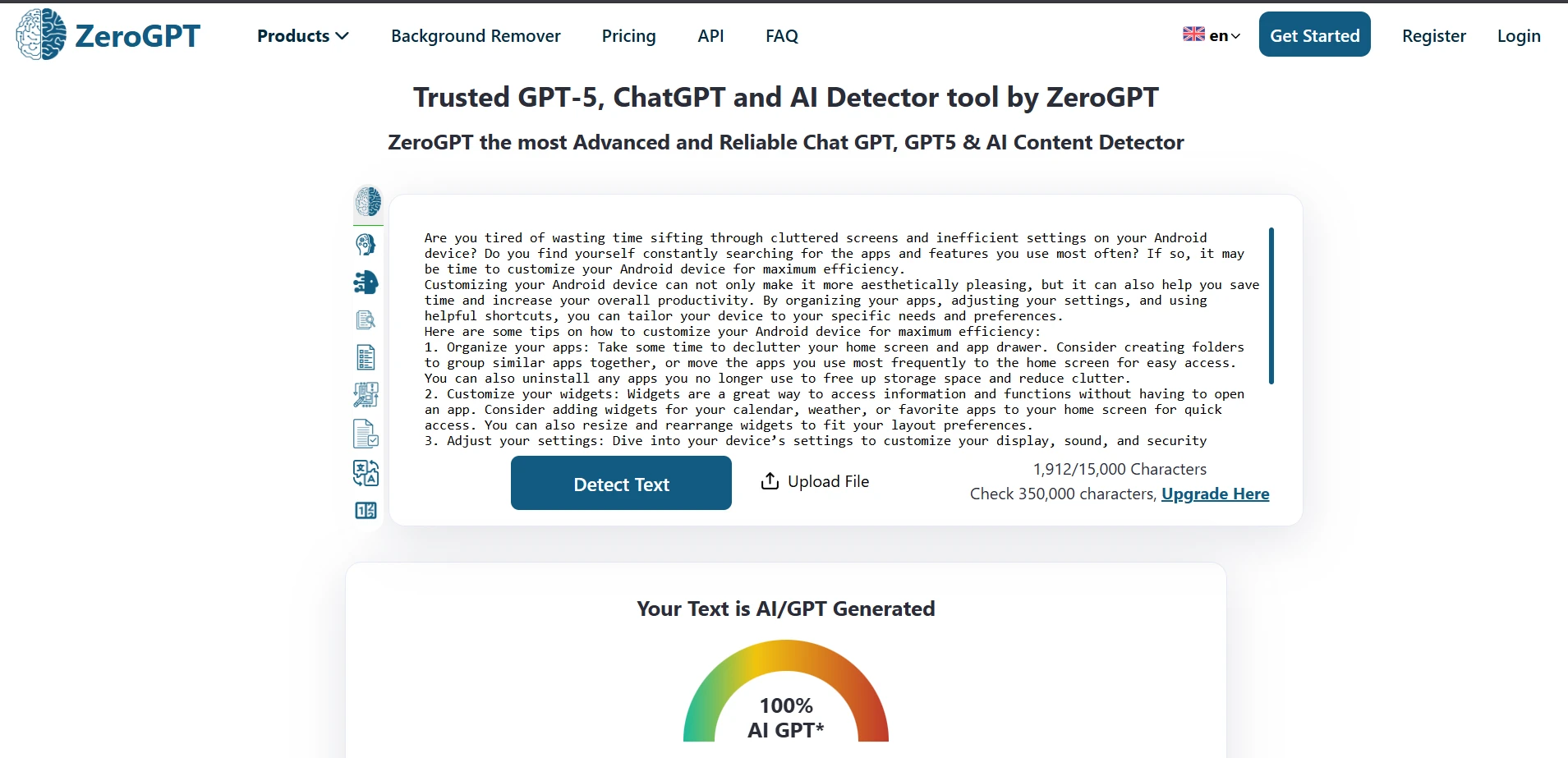
ZeroGPT in Action (Screenshots)
These screenshots show typical ZeroGPT outputs from the test set.
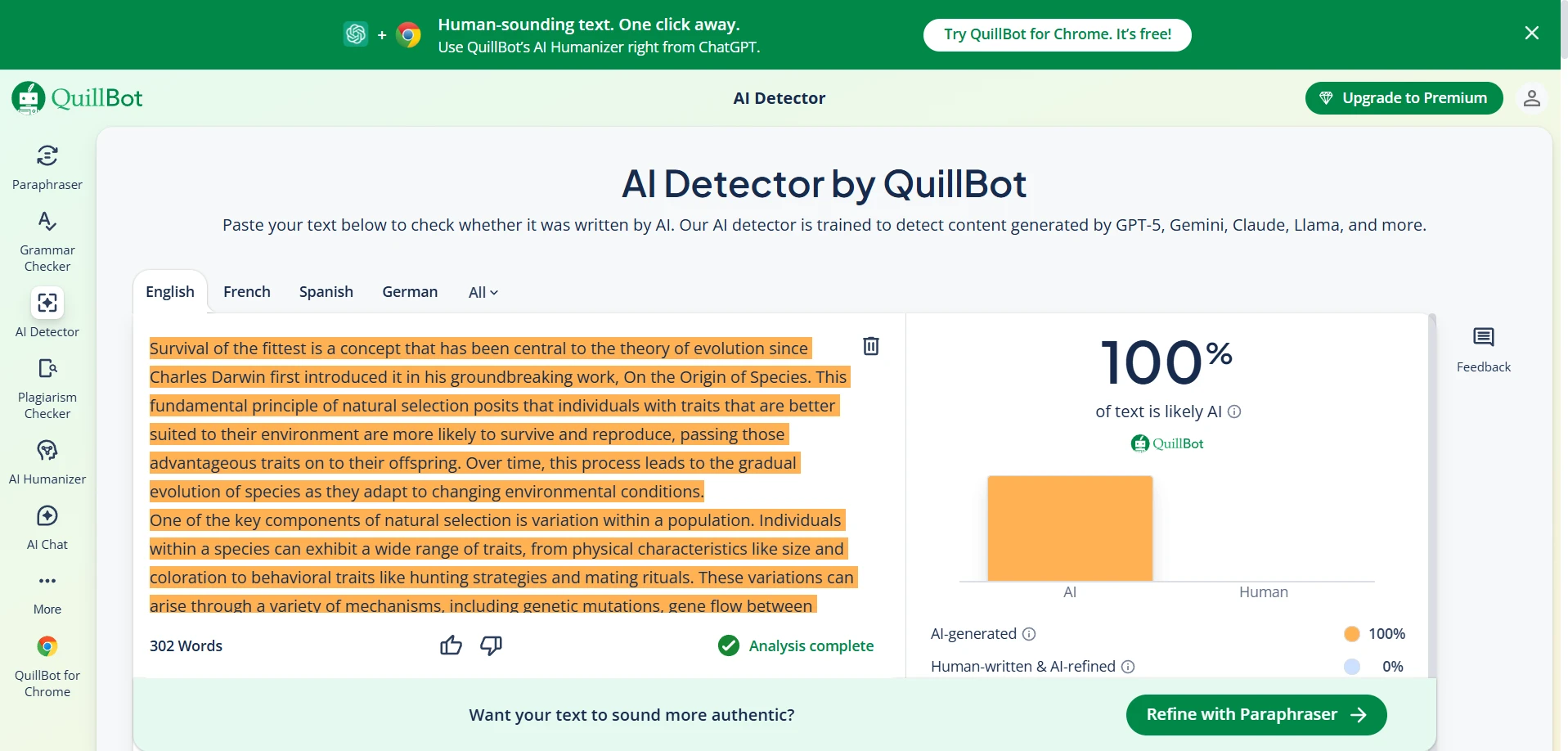
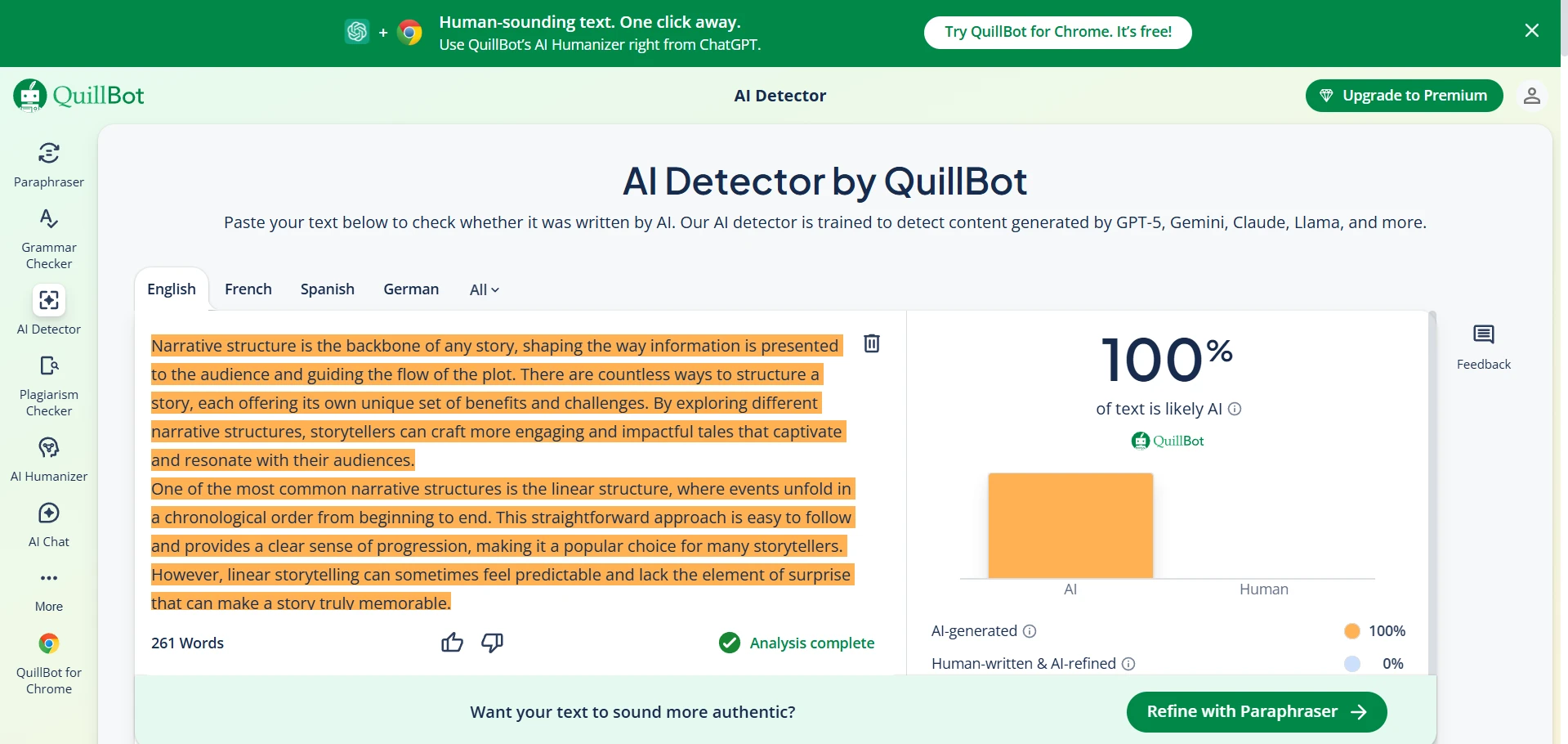
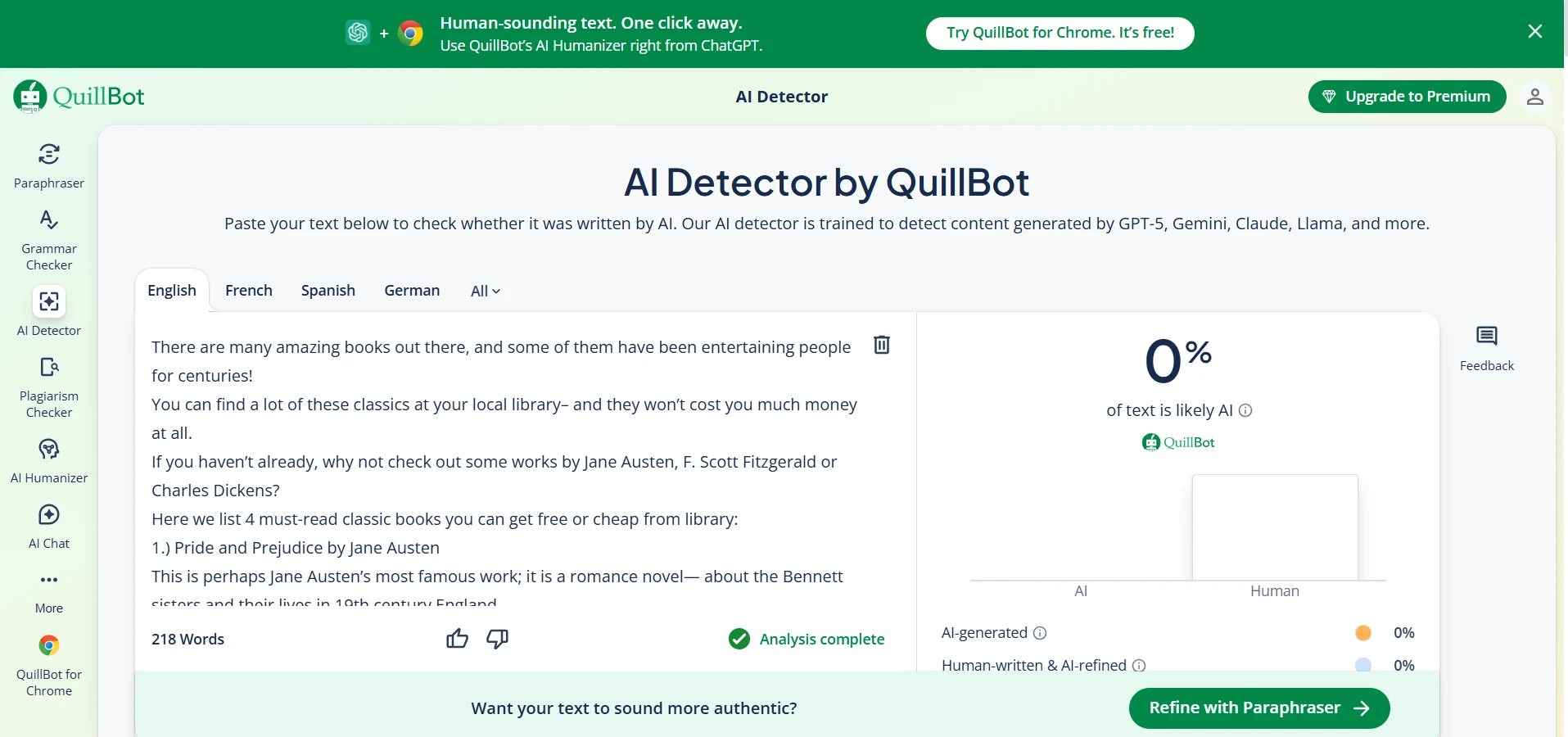
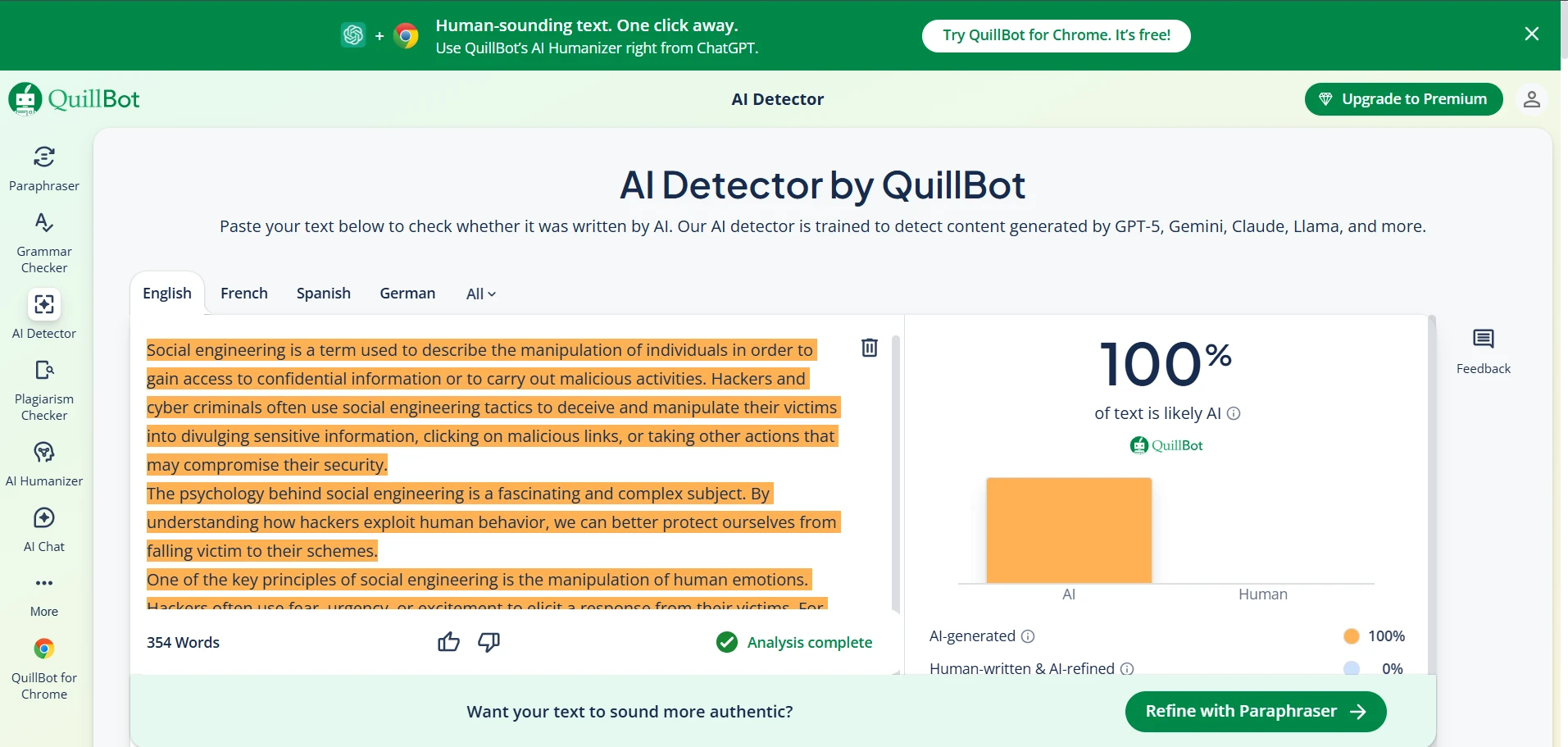
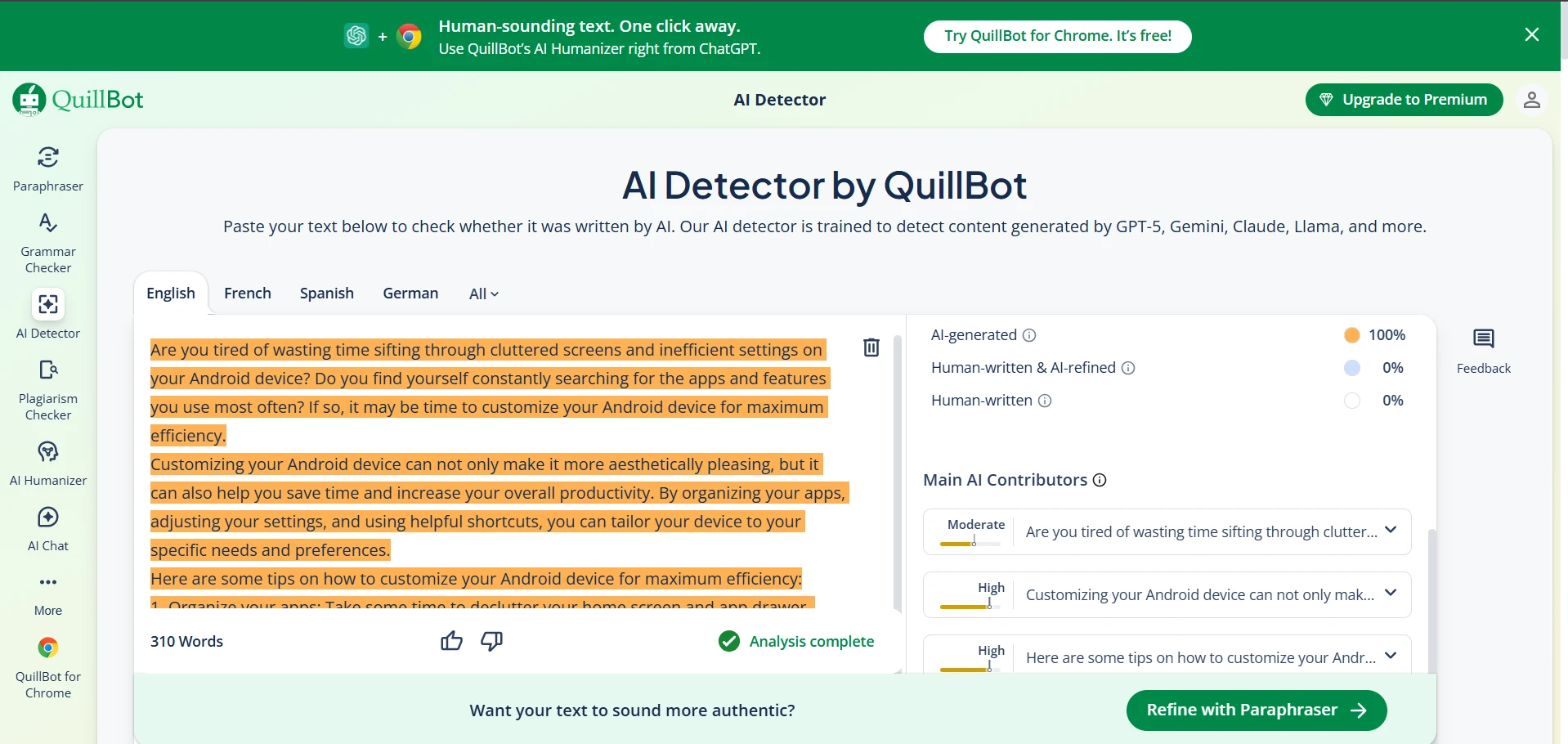
QuillBot AI Detector in Action (Screenshots)
These screenshots show typical QuillBot outputs from the same test set.
The Final Verdict
If you mainly want to avoid false accusations: QuillBot looked safer in this dataset (0 false positives), but it missed more AI samples.
If you want stronger AI detection: ZeroGPT caught more AI at the same cutoff, but it occasionally flagged human writing.
Best practice: treat detectors like a warning light. If it turns on, double-check with evidence from the writing process before jumping to conclusions.