

AI detectors are everywhere now — in classrooms, on campus, and in submission portals. But students rarely get to see real numbers behind these tools. So I tested 160 text samples (78 human-written and 82 AI-written) and compared two popular detectors: Originality.ai and Quillbot’s AI Detector. In this post, I’ll show the data with simple charts and explain what it means in plain language.
What I Measured (In One Sentence)
Each detector gives a Human Score from 0.0 to 1.0: higher means “this looks human,” lower means “this looks AI.” (In this blog, I treat 1.0 as 100% and 0.0 as 0%.)
The Testing Methodology
I collected 78 human-written samples and 82 AI-written samples (160 total). Every sample was run through both detectors, and I recorded the “Human Score” each tool gave.
Important note: detectors are not mind-readers. They don’t know “who wrote it.” They look for patterns (like repetition, predictable sentence structure, and certain word choices) and then guess. That means results can change if the detector is updated, or if you change the prompt, topic, or writing style.
Key Findings From 160 Samples
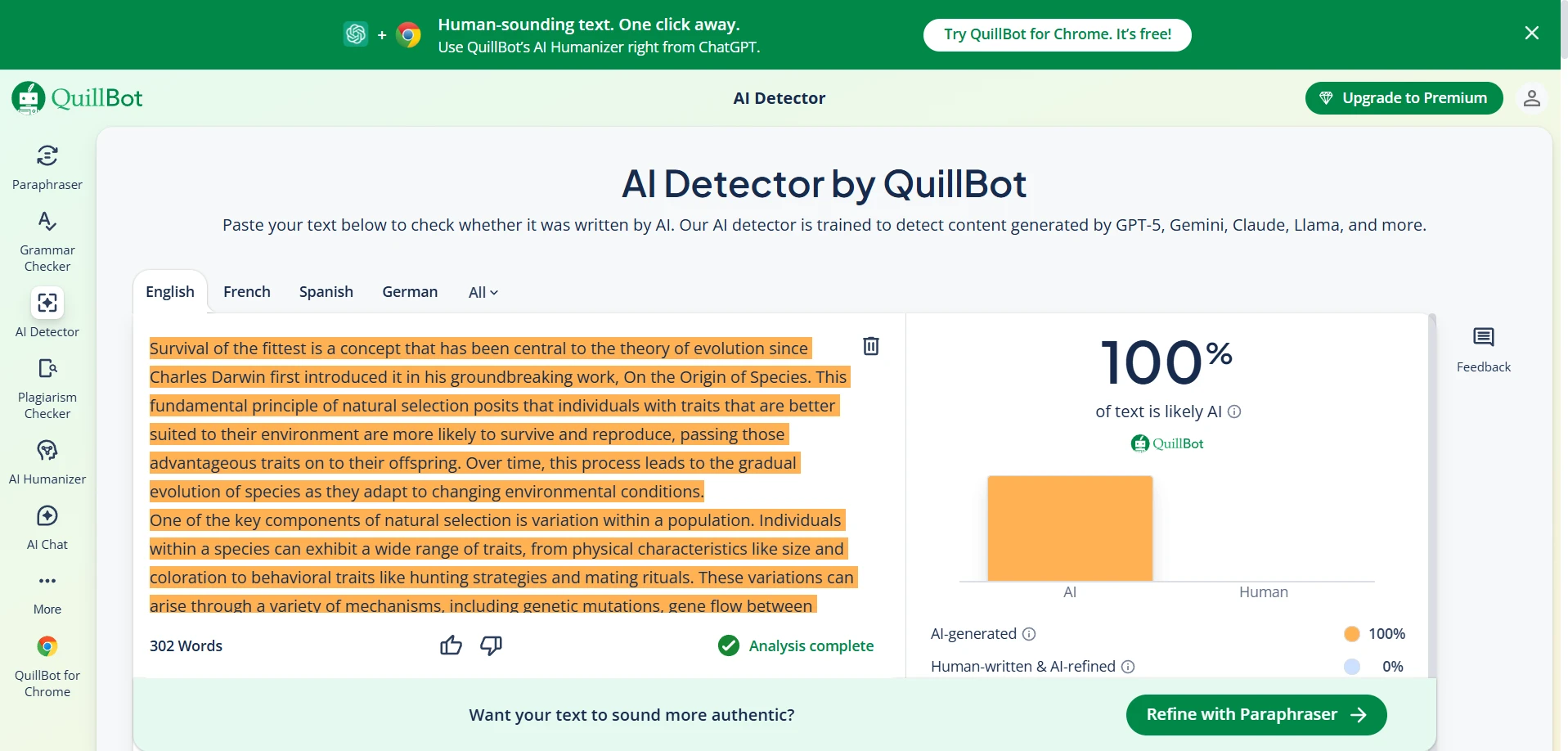
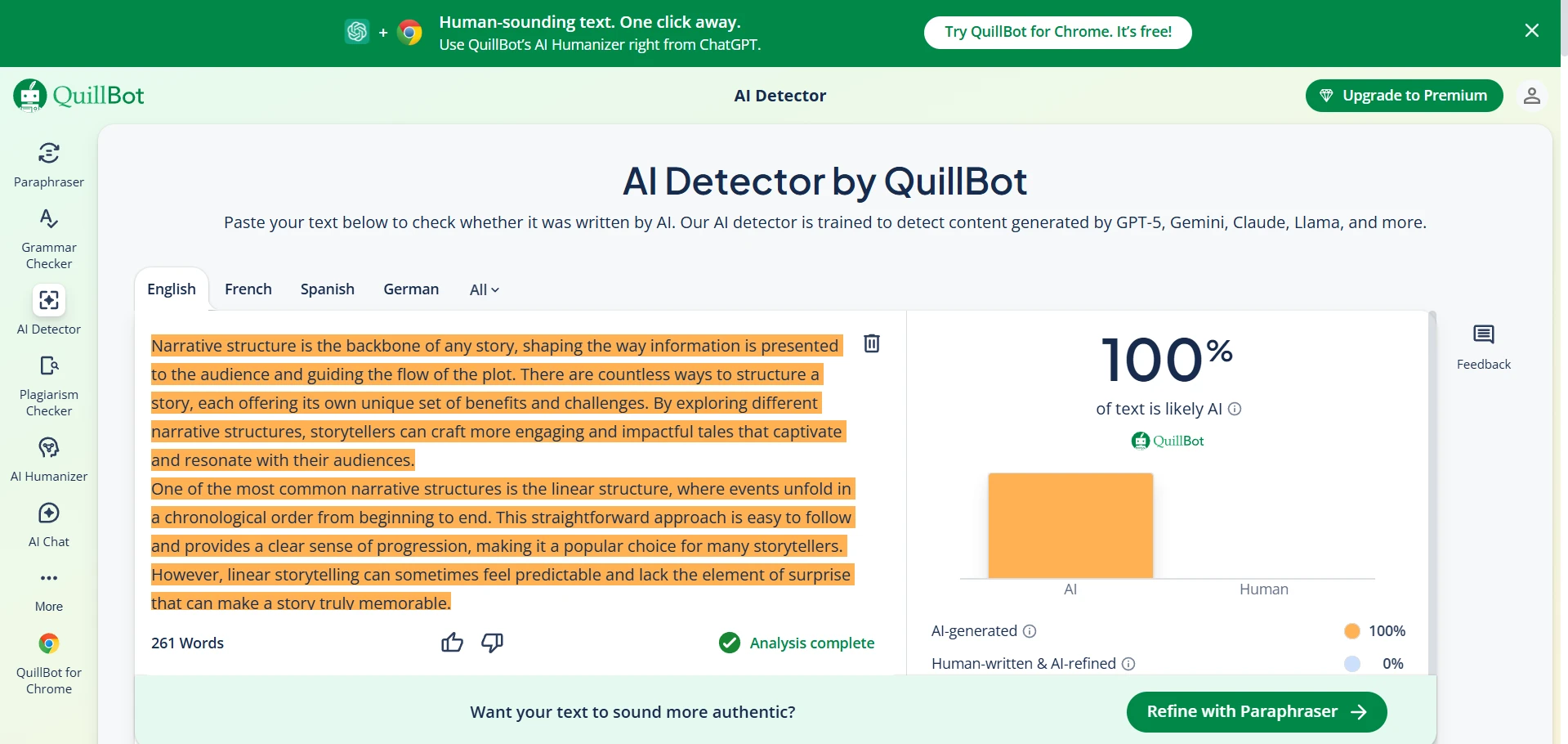
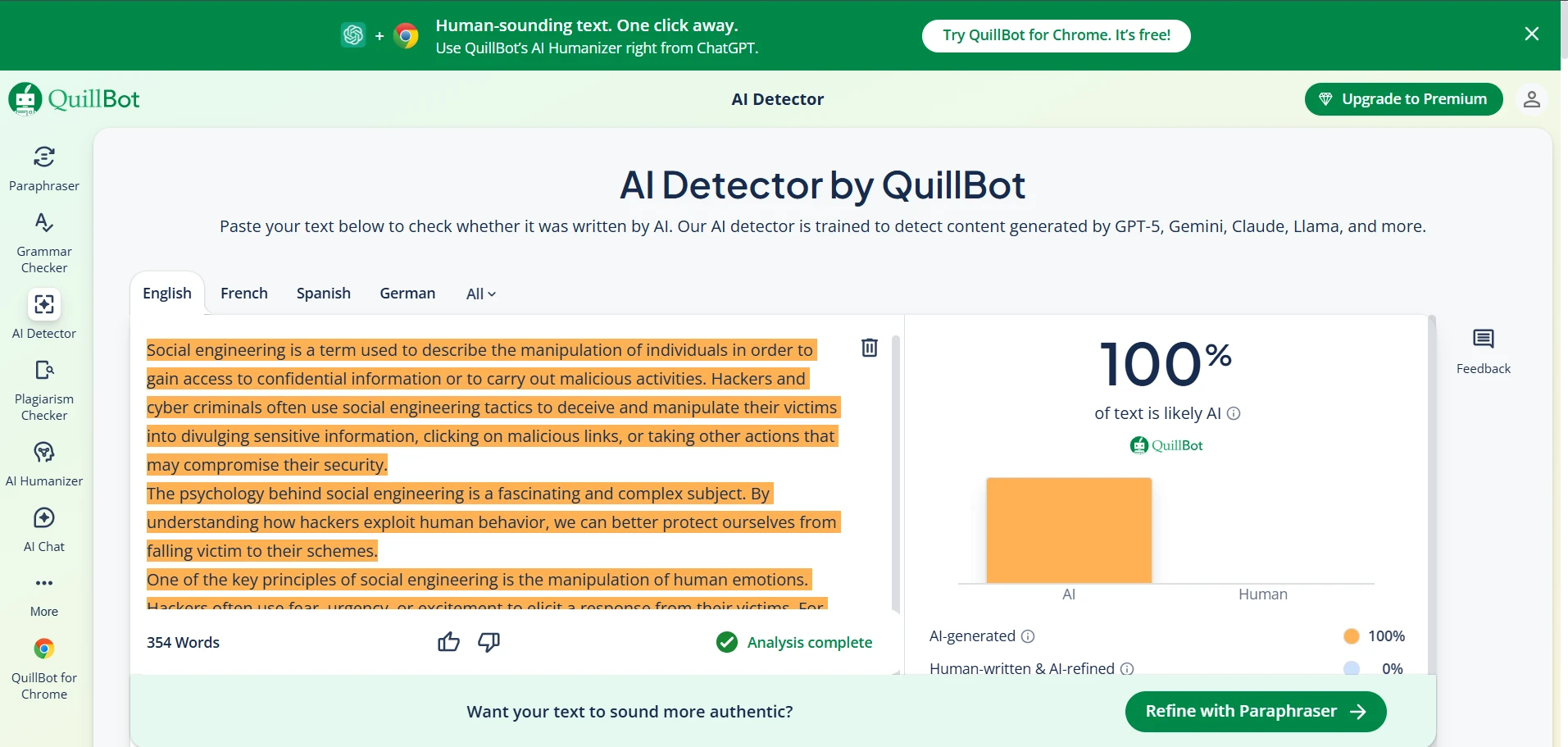
- Human-written text: Originality.ai averaged 89.3% human, while Quillbot averaged 100.0% human.
- AI-written text: Originality.ai averaged 23.1% human, while Quillbot averaged 45.2% human.
- Simple “pass/fail” view (0.5 cutoff): Originality.ai accuracy was 83.8%; Quillbot accuracy was 80.6%.
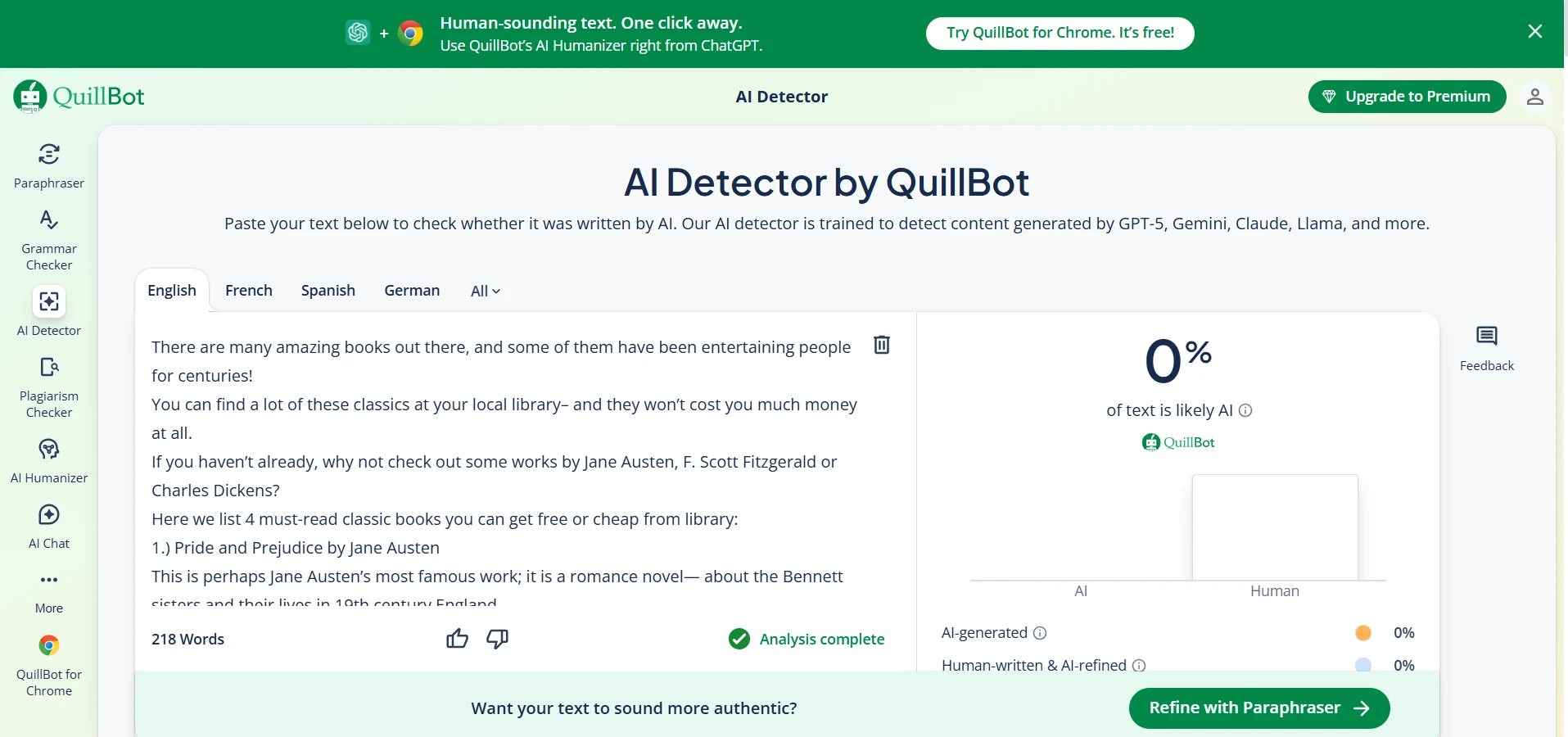
- Big pattern: Quillbot was extremely “friendly” to human writing (it never accused a human sample), but it also let more AI samples pass as human.
Chart 1: Average Scores (Human vs AI)
This first chart is the easiest way to understand what’s happening. For human-written samples, we want a high Human Score. For AI-written samples, we want a low Human Score.
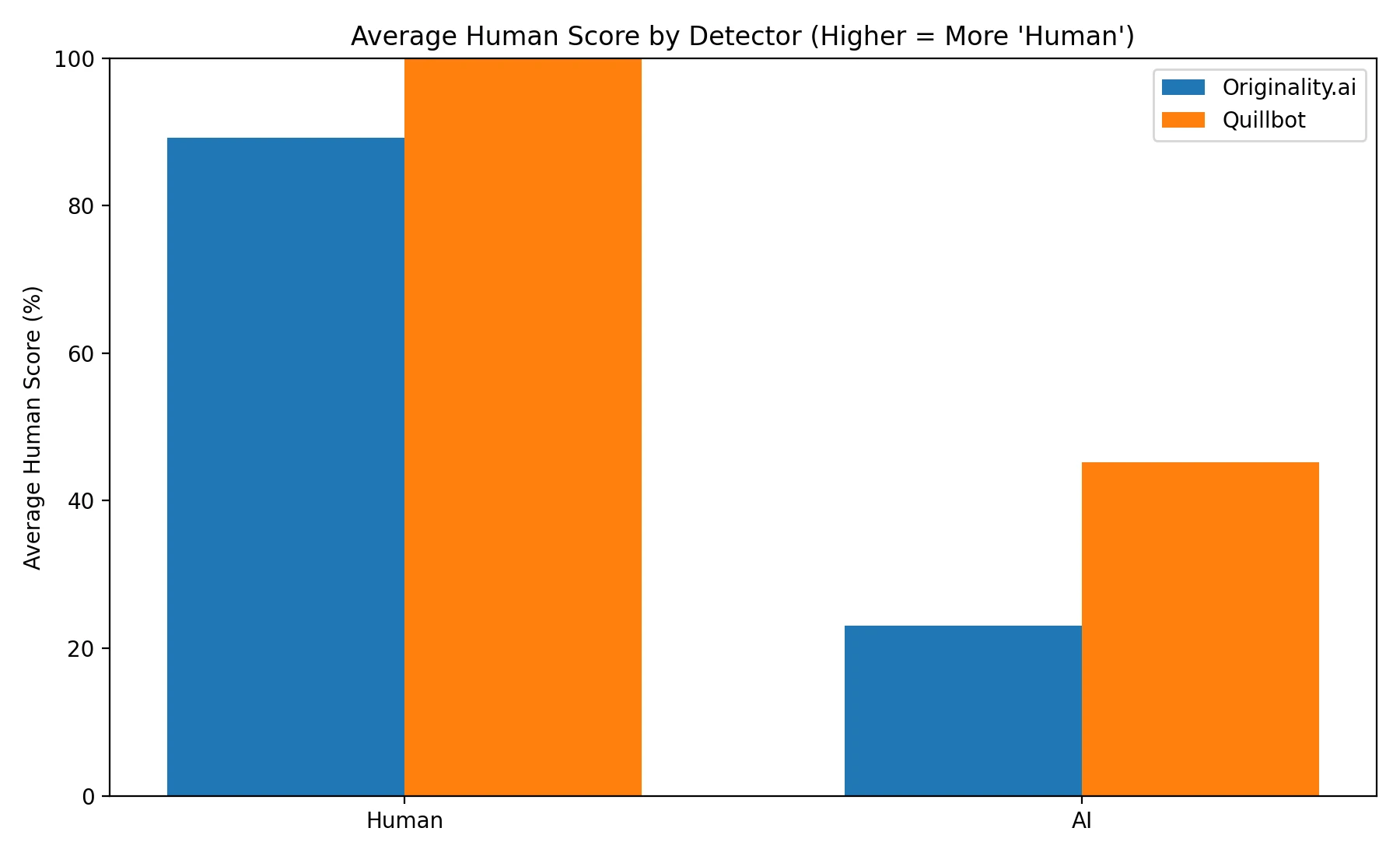
Both tools did well on clearly human writing — but they behaved very differently on AI writing. Originality.ai’s AI average was only 23.1%, while Quillbot’s AI average was 45.2%. In simple terms: Quillbot often thought AI writing looked human.
Chart 2: The “Mistake” Problem (False Positives vs False Negatives)
Two kinds of mistakes matter: false positive and false negative. These sound scary, but they’re simple:
False positive = the detector says “AI” even though the text is human.
False negative = the detector says “human” even though the text is AI.
To turn scores into a simple “AI or human” decision, I used a 0.5 cutoff: if the Human Score is 0.5 or higher, I count it as “human”; if it’s below 0.5, I count it as “AI.” (This is a basic rule just for comparison — the tools might use different internal rules.)
Also Read: Originality.ai vs Grammarly AI Detector
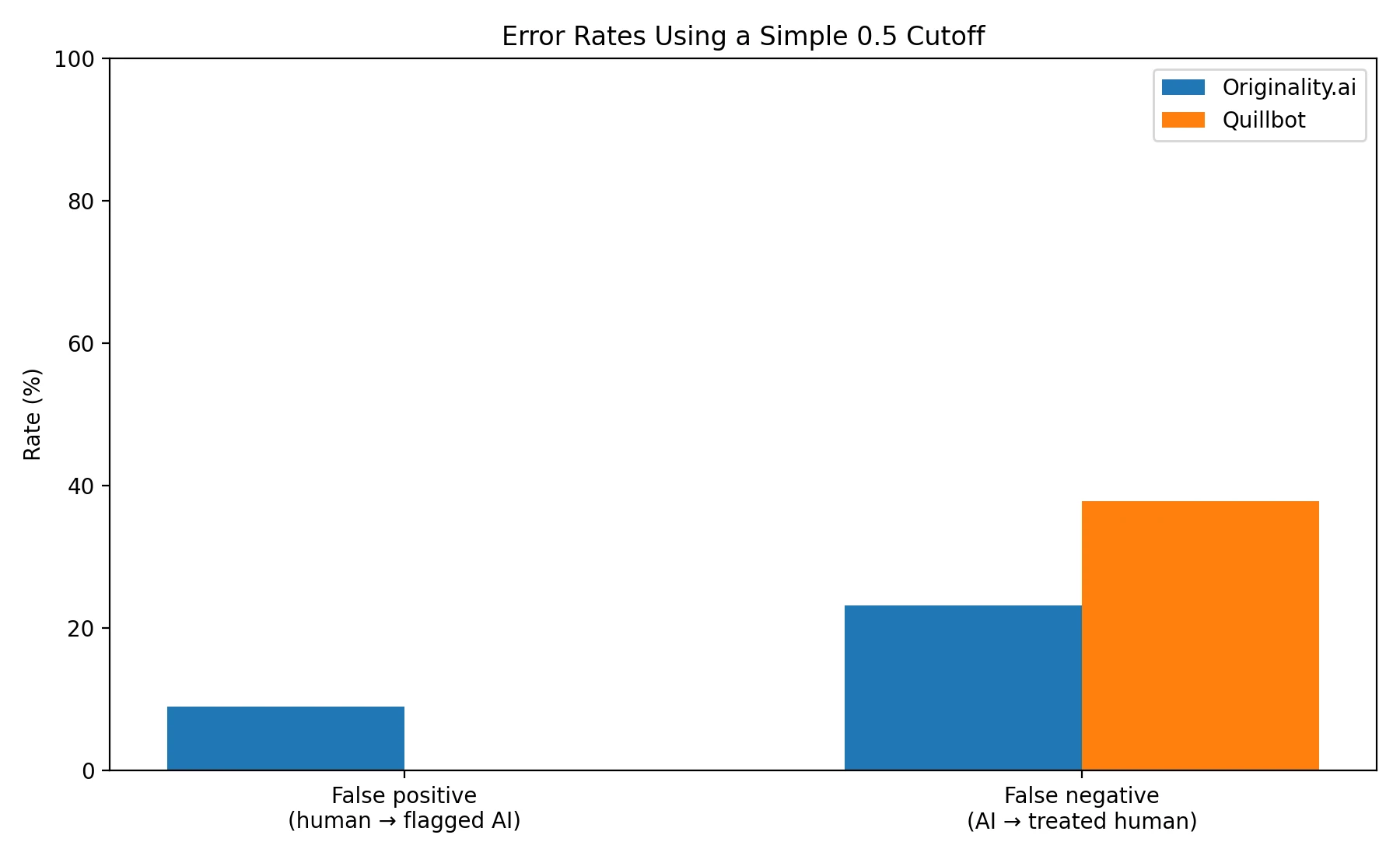
Here’s the tradeoff: Quillbot had a 0.0% false positive rate (it never accused a human sample), but a higher 37.8% false negative rate (it missed more AI). Originality.ai was stricter: it caught more AI (lower false negatives at 23.2%), but it did accuse some human samples (false positives at 9.0%).
Also Read: Originality AI vs Sapling AI
Chart 3: Score Spread (Box Plot)
A box plot is a picture of “where most scores live.” The box shows the middle chunk of results (think of it as the “typical range”), and dots beyond the box are unusual cases (often called “outliers”). You don’t need to memorize the details — just look for how separated “Human” and “AI” are.
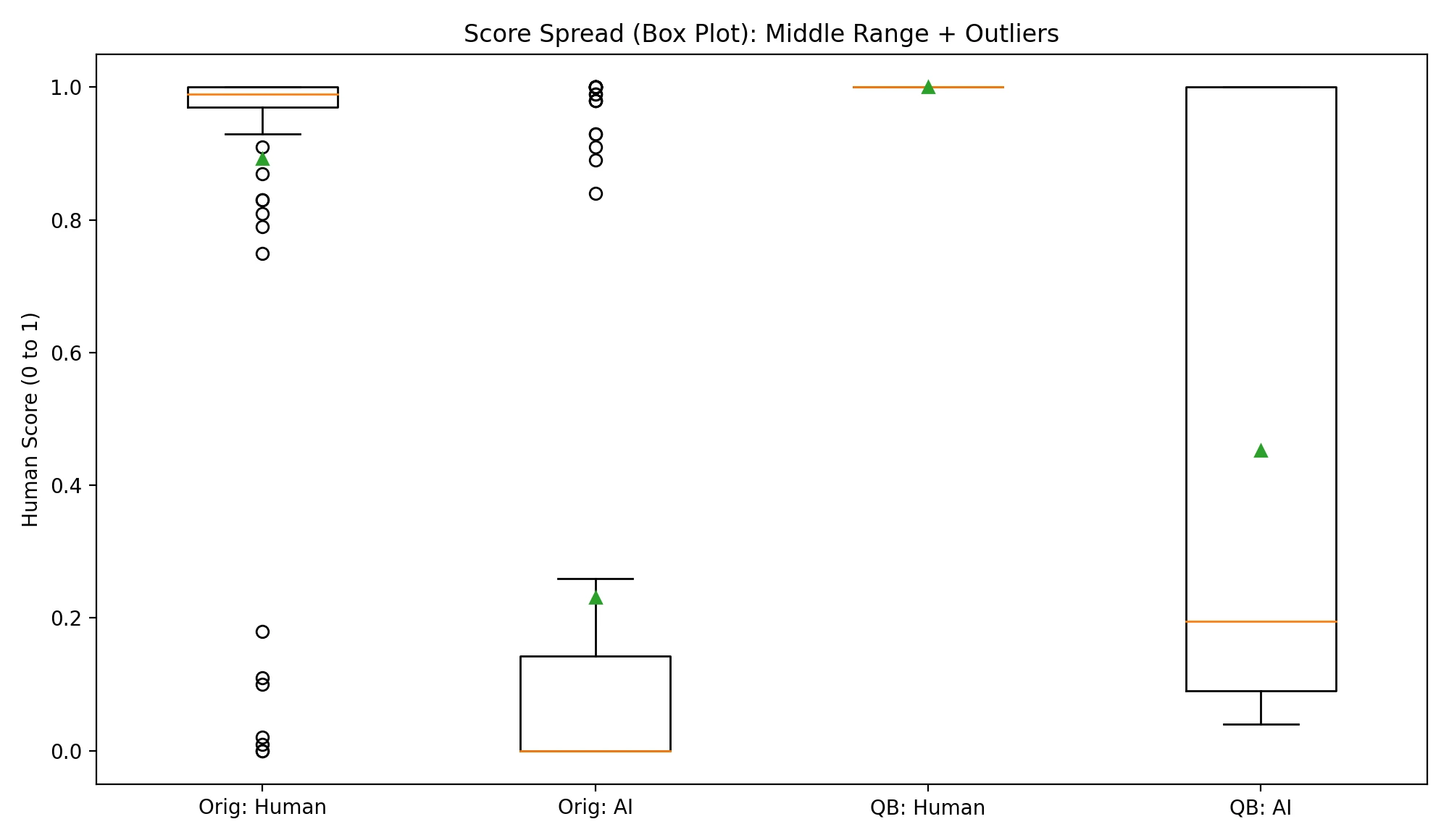
Two things stand out: (1) Quillbot gave every human sample a perfect 1.0, which looks great, but (2) it also gave 27 AI samples a perfect 1.0. Originality.ai gave 9 AI samples a perfect 1.0 — still not zero, but much lower.
Also Read: Can Originality AI Detect ChatGPT?
Chart 4: Sample-by-Sample Comparison (Scatter Plot)
This chart is “each dot is one piece of writing.” If a dot is near the top-right corner, both tools think it looks human. If a dot is near the bottom-left, both tools think it looks AI. Ideally, human samples cluster high and AI samples cluster low.
You can see the main theme again: Quillbot pushes lots of samples upward (toward “human”), including many AI samples. Originality.ai keeps more AI samples lower, but it sometimes drags a few human samples down too. In this dataset, Originality.ai flagged 7 out of 78 human samples as AI using the 0.5 cutoff, while Quillbot flagged 0.
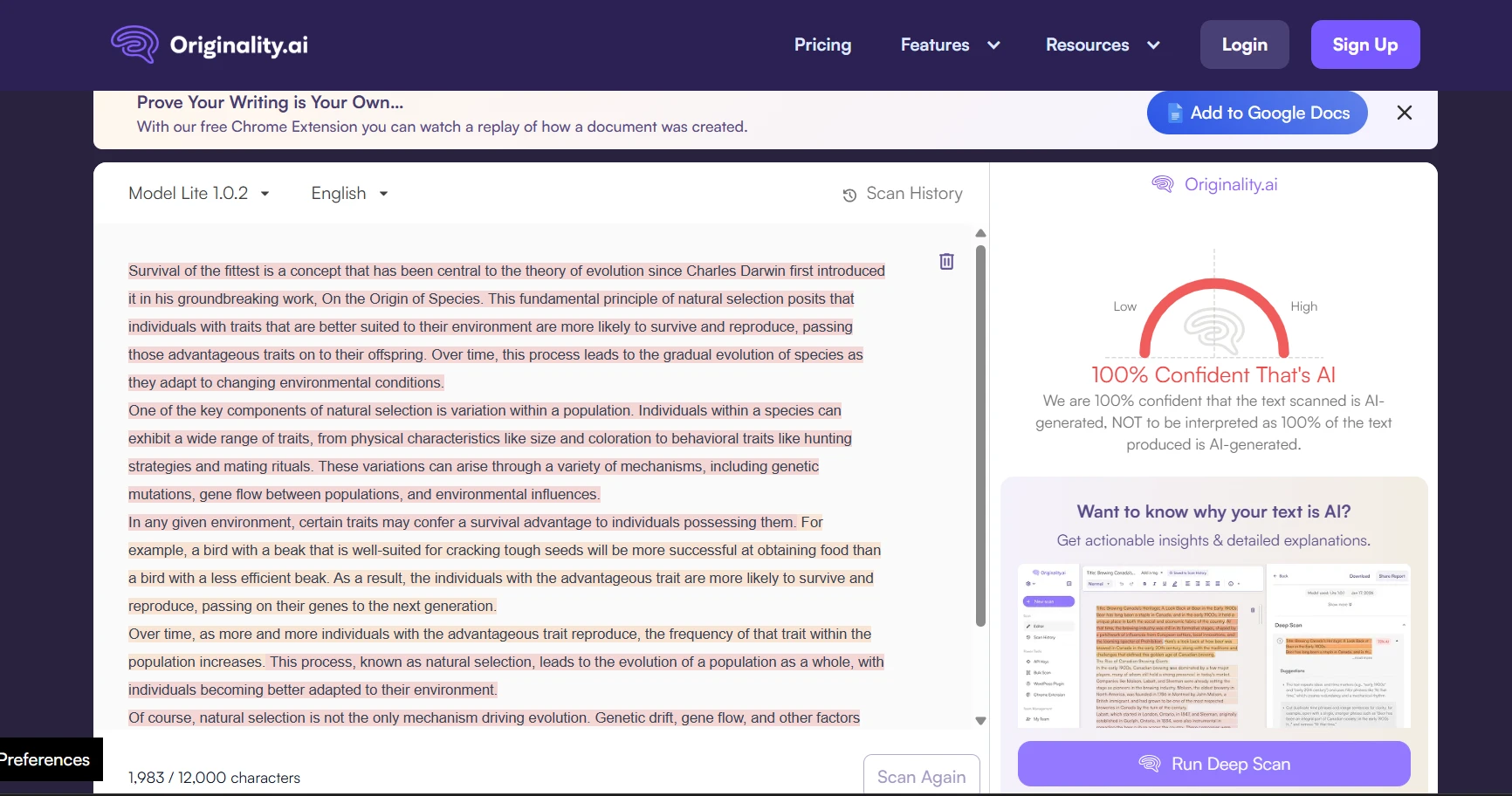
Deep Dive: Originality.ai Screenshots
If you want a stricter detector (one that is more likely to “catch AI”), Originality.ai behaved that way in this test. It did better at keeping AI scores low, but it also produced a small number of “false alarms” on human writing. Below are example screenshots (replace these image paths with your own uploaded files if needed).
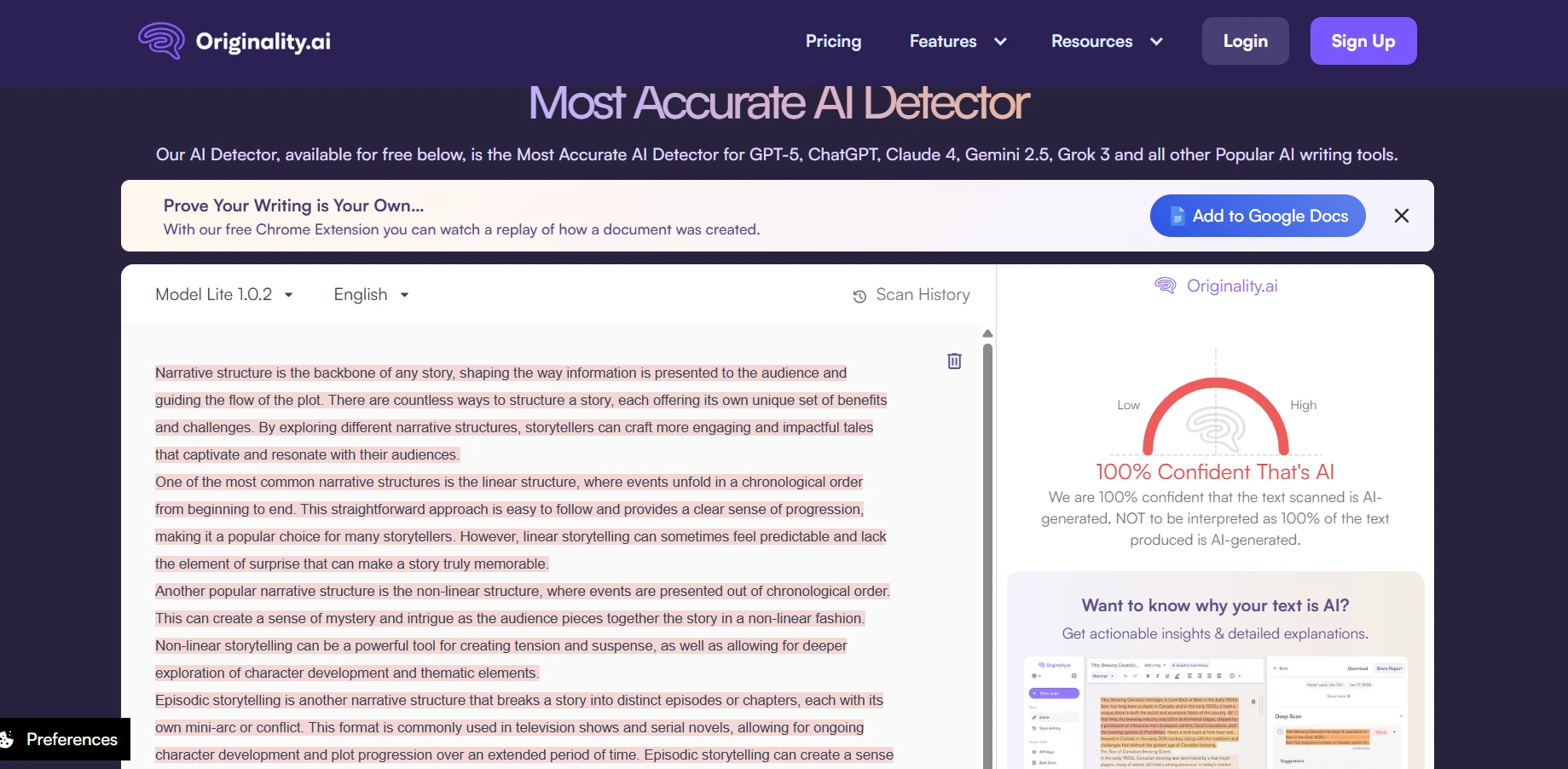
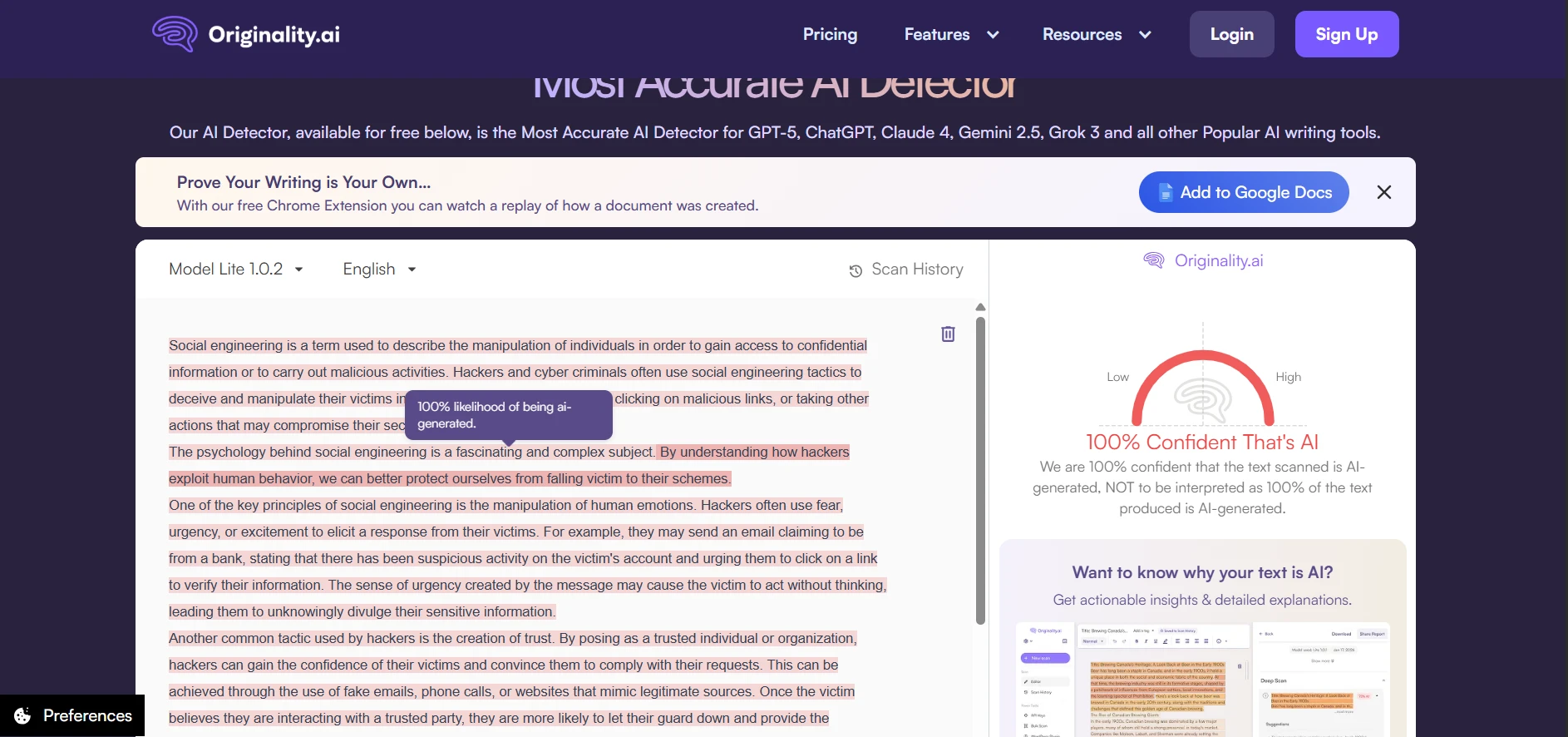
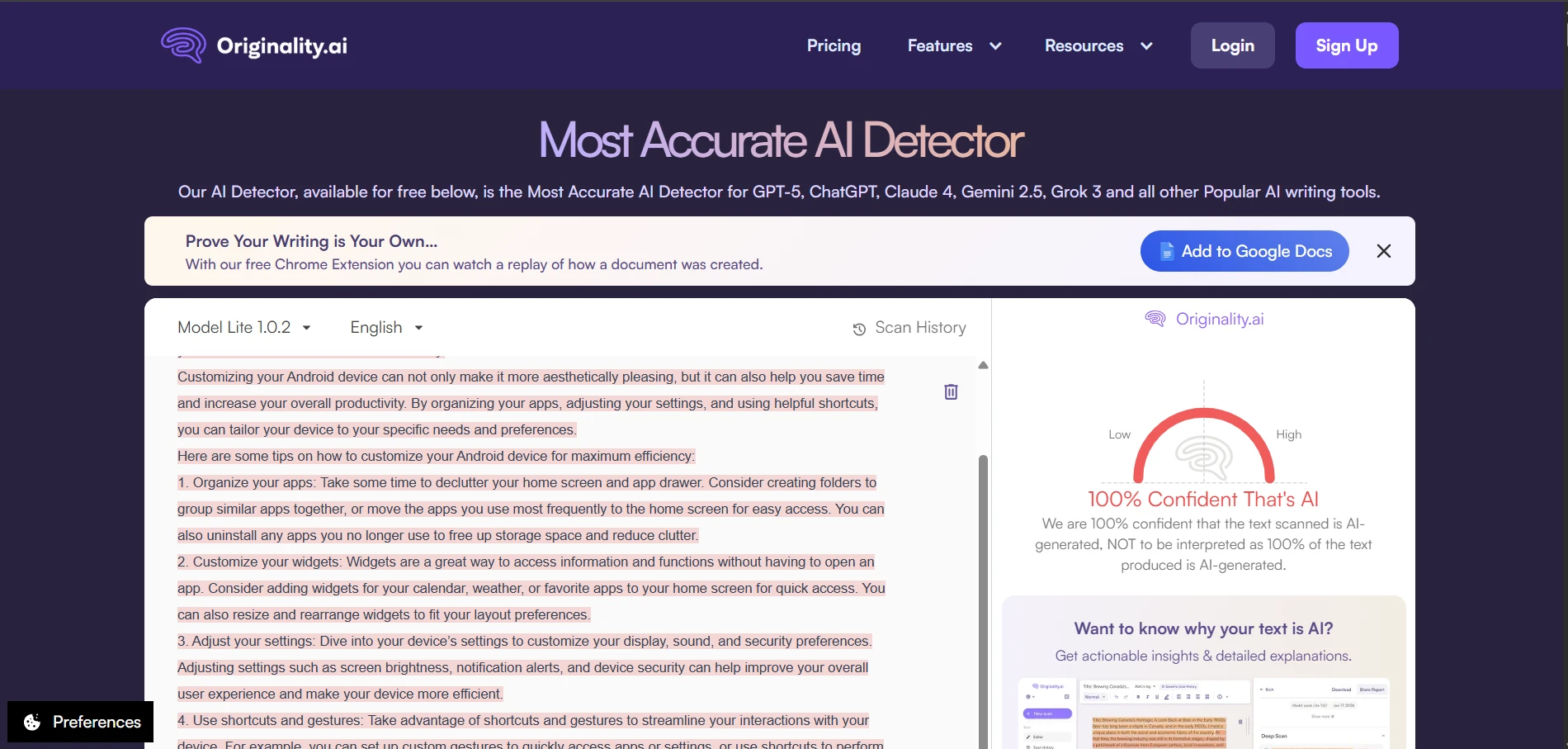
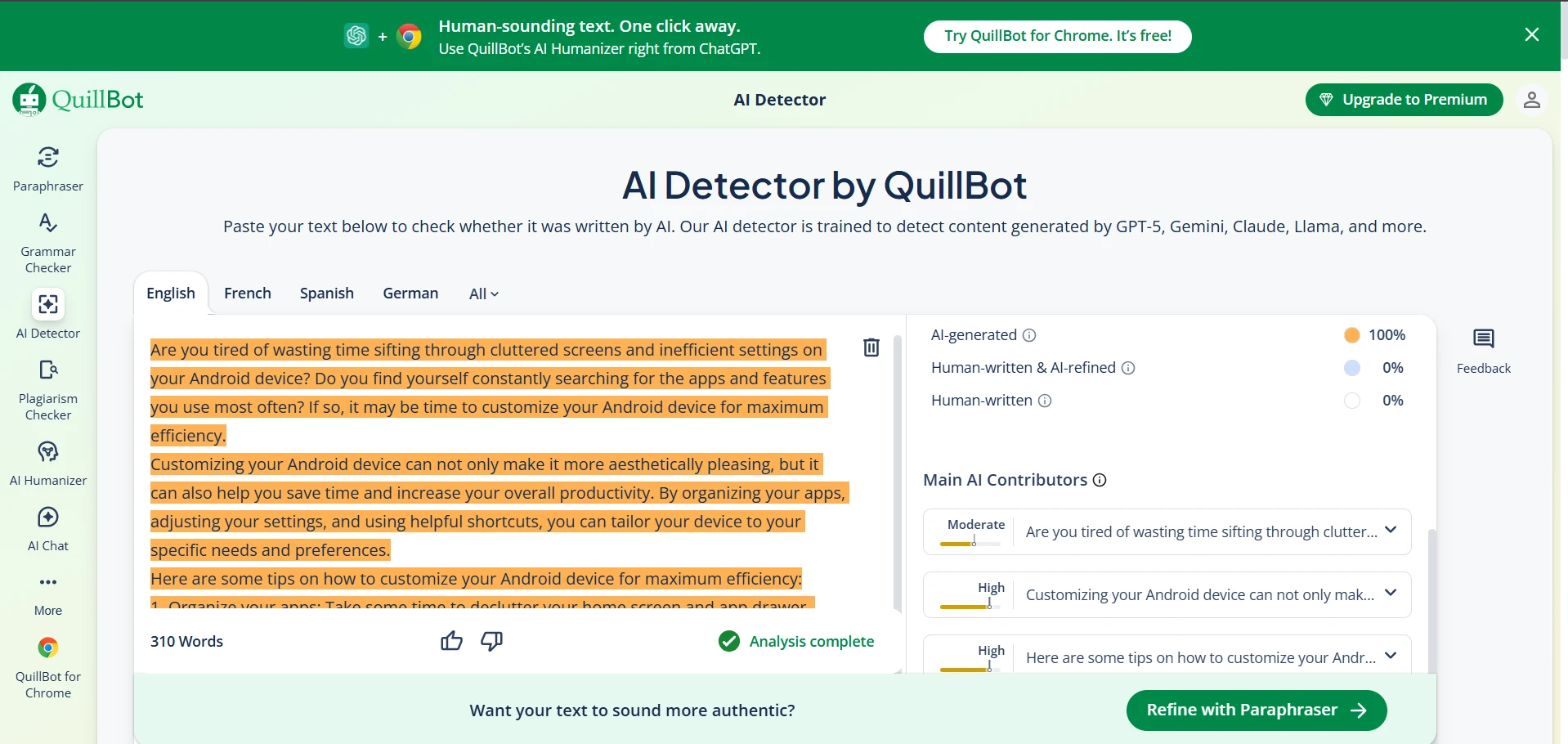
Deep Dive: Quillbot AI Detector Screenshots
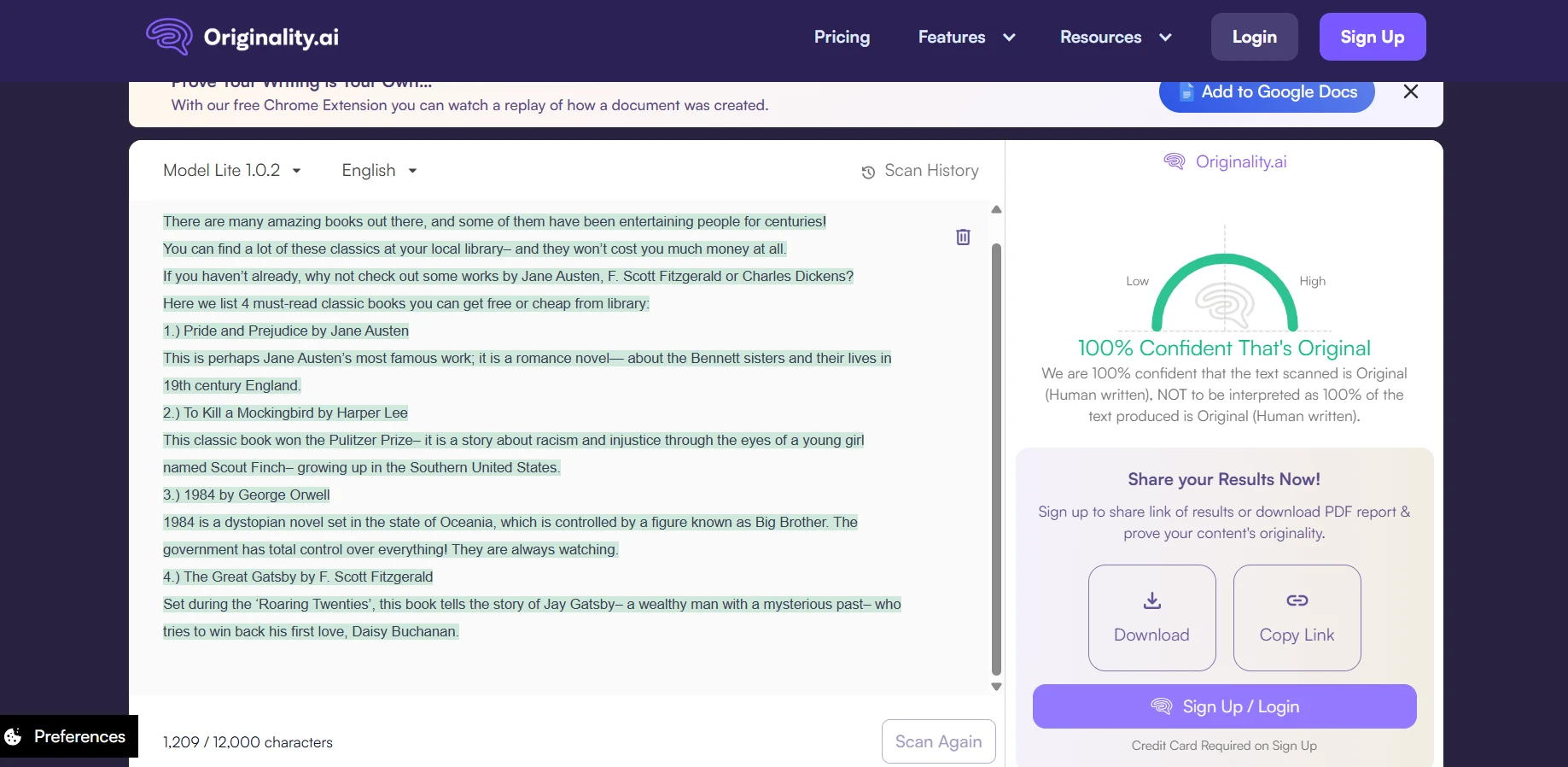
Quillbot’s detector was extremely student-friendly in one way: it did not accuse any human sample in my dataset. The downside is that it was much more likely to call AI writing “human,” which makes it weaker if your goal is to detect AI usage. Below are example screenshots (replace these image paths with your own uploaded files if needed).
So Which One Should Students Care About?
If you’re a student, the question usually isn’t “how do I catch other people using AI?” It’s “how do I avoid my honest work being wrongly flagged?”
Based on this dataset: Quillbot is less likely to falsely accuse you (0 false positives here), but Originality.ai is more strict and catches more AI.
A Practical Decision Rule
- If you want fewer false accusations: Quillbot behaved safer in this test (it didn’t flag any human sample).
- If you want stronger AI catching: Originality.ai performed better on AI samples (lower AI “human” scores, fewer AI passes).
- For an MVP student workflow: run your draft through both. If one tool screams “AI” but the other says “human,” that’s a signal to revise phrasing and add more personal detail.
How to Make Your Writing Look More Like You (Not a Bot)
This is not about “beating” a detector — it’s about writing more clearly and personally. Detectors tend to penalize writing that is overly generic. These small changes often help:
Add specifics: include a concrete example, a personal observation, or a small detail from your class material.
Vary your sentence lengths: mix short and long sentences so your writing doesn’t sound like a template.
Show your thinking: explain why you picked an argument, not just the argument itself.
This experiment is strong because it uses 160 samples, but it still has limits. It’s based on the specific topics and writing styles in my dataset. If you test different subjects, different AI models, or different versions of the detectors, numbers may change. Treat this as a useful snapshot — not a permanent law of nature.
The Final Verdict
In this 160-sample test, Originality.ai was the stronger “AI catcher” overall, while Quillbot was the safer “don’t accuse humans” option.
If you’re a student worried about being falsely flagged, Quillbot’s behavior may feel reassuring — but don’t use it as proof that your work will never be questioned. If your school uses a stricter detector (or human review), the best protection is still the same: write with specific examples, show your reasoning, and keep drafts or notes that prove your process.