![[STUDY] Can GPTZero Detect Code?](/static/images/can_gptzero_detect_codepng.webp)

As AI coding assistants like ChatGPT and Claude become standard tools for developers, a pressing question has emerged in universities and hiring committees: Can we distinguish between human-written code and AI-generated code?
Text detection tools like GPTZero have made headlines for spotting AI-generated essays, but code is different. It follows strict syntax, logic, and patterns that are often identical whether written by a machine or a human.
To find out if current detection tools are up to the task, I conducted a controlled experiment using 100 unique code samples. The results were surprising—and they might change how you think about AI detection.
The Experiment Methodology
I curated a dataset of 100 code snippets across various programming languages (Python, JavaScript, Java, C++, etc.) from three distinct sources:
AI (GPT-5.2-Extended-Thinking): 30 samples generated by one of the most advanced models available.
AI (Claude-Opus-4.6): 30 samples from Anthropic’s top-tier model.
Human Developers: 40 samples of verified human-written code (from open-source projects, coding challenges, etc.).
I then ran each snippet through GPTZero to obtain its "AI Probability Score" (ranging from 0 to 1, where 1 means "definitely AI").
Also Read: Can Turnitin Detect AI Code?
The Results: A Coin Flip?
After analyzing the data, the most shocking finding was the sheer difficulty of separation.
1. The Distribution of Scores (Box Plot)
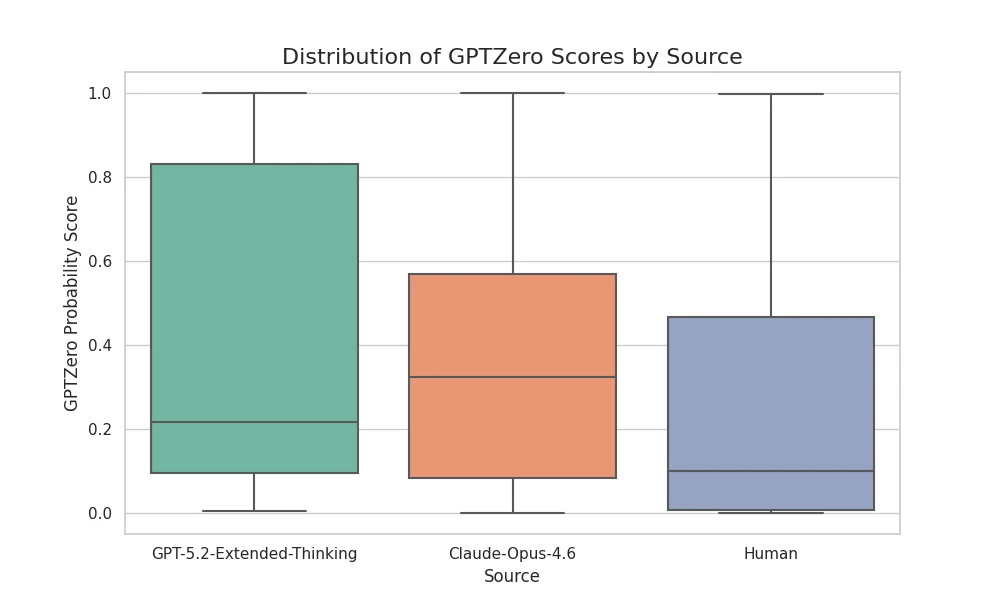
Figure 1: A box plot showing the spread of AI probability scores for each source.
As you can see in the chart above, there is massive overlap between the "Human" and "AI" categories.
The "Human" box extends well into the high-probability range.
The "AI" boxes (GPT-5.2 and Claude) dip frequently into the low-probability range.
This overlap suggests that for many code snippets, the "AI signal" is simply too weak to be detected reliably.
Also Read: Can Turnitin Detect Blackbox AI?
2. Average Probability Scores
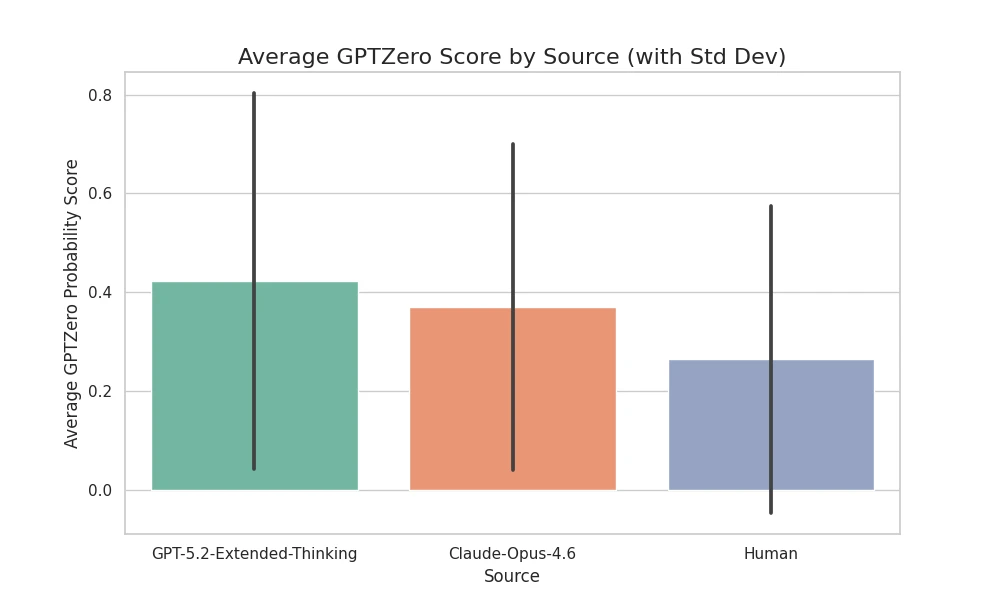
Figure 2: The average AI probability assigned to each group.
GPT-5.2 Avg Score: 0.42
Claude Opus Avg Score: 0.37
Human Avg Score: 0.26
While the AI models do have a slightly higher average score, the difference is not statistically confident. The standard deviation (represented by the black error bars) is huge for all groups.
3. Accuracy & Reliability
If we use the standard threshold of 0.5 (50%) to classify code—meaning anything above 0.5 is "AI" and anything below is "Human"—the performance is underwhelming:
Accuracy: 56% (Barely better than a random coin toss)
Precision: 73.5% (If it says "AI", it's likely right... but wait for the catch)
Recall: 41.7% (It misses nearly 60% of actual AI code!)
This means that more than half the time, GPTZero looked at code written by GPT-5.2 or Claude and confidently labeled it as "Human."
Also Read: Does Claude Watermark AI Text?
4. ROC Curve Analysis
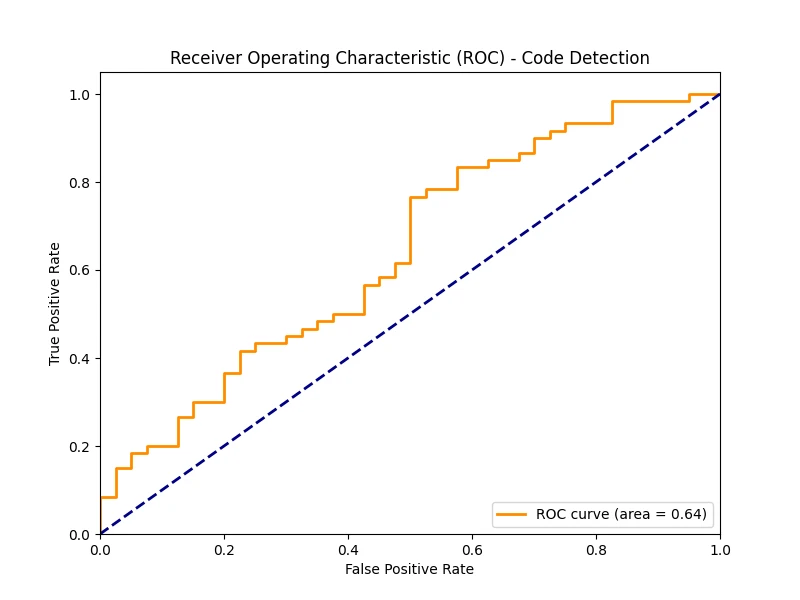
Figure 3: The Receiver Operating Characteristic (ROC) curve.
The AUC (Area Under the Curve) score is 0.64. A perfect detector would have an AUC of 1.0, while a random guess is 0.5. A score of 0.64 indicates a "poor" to "fair" predictive ability.
Why Did It Fail? (The "Boilerplate" Problem)
Digging into the False Positives (Human code flagged as AI) and False Negatives (AI code flagged as Human) revealed a critical insight:
Code is often generic.
False Positive Example: A human-written SQL query using a Common Table Expression (CTE) received a score of 0.74 (AI). Why? Because SQL syntax is rigid. There are only so many ways to write a SELECT statement.
False Negative Example: A complex Python algorithm written by GPT-5.2 received a score of 0.004 (Human). The logic was so "clean" and standard that it looked perfectly human.
Verdict: Should You Trust AI Code Detectors?
No, not yet.
Based on this dataset of 100 samples, relying on tools like GPTZero to catch AI-generated code is risky.
High Risk of False Accusations: You might falsely accuse a student or employee of using AI simply because they wrote clean, standard code.
Easy to Bypass: AI models are generating code that is statistically indistinguishable from human work more than half the time.
The Bottom Line: Code detection is a much harder problem than text detection. Until these tools evolve significantly, human review and understanding the logic of the code remain the only reliable ways to assess authorship.