![[HOT] Grammarly vs Sapling AI Detector: Which One Is Fairer to Student Writing?](/static/images/grammarly-vs-sapling-featured-imagepng.webp)

Grammarly vs Sapling AI Detector: Which One Is Fairer to Students?
AI detectors are no longer just side tools. In classrooms, they can shape suspicion, trust, and even grades. That is why the real question is not simply “Which detector is stricter?” The better question is: Which detector makes fewer unfair mistakes on student writing? To answer that, I compared Grammarly’s AI detector and Sapling’s detector across 160 samples and looked at how each tool scored human-written and AI-written text.
How this test worked
The dataset included 160 samples in total: 78 human-written pieces and 82 AI-written pieces. Each sample was run through both detectors. The score used in this analysis is a human score, which means a higher number suggests the detector thinks the text was written by a person.
That makes the reading simple. On real human writing, a good detector should give a high human score. On AI writing, a good detector should give a low human score. In other words, the strongest tool is not the one that yells “AI” the loudest. It is the one that can separate real student writing from machine-generated writing without punishing the wrong group.
Also Read: Originality.ai vs Sapling.ai
Quick read of the main numbers
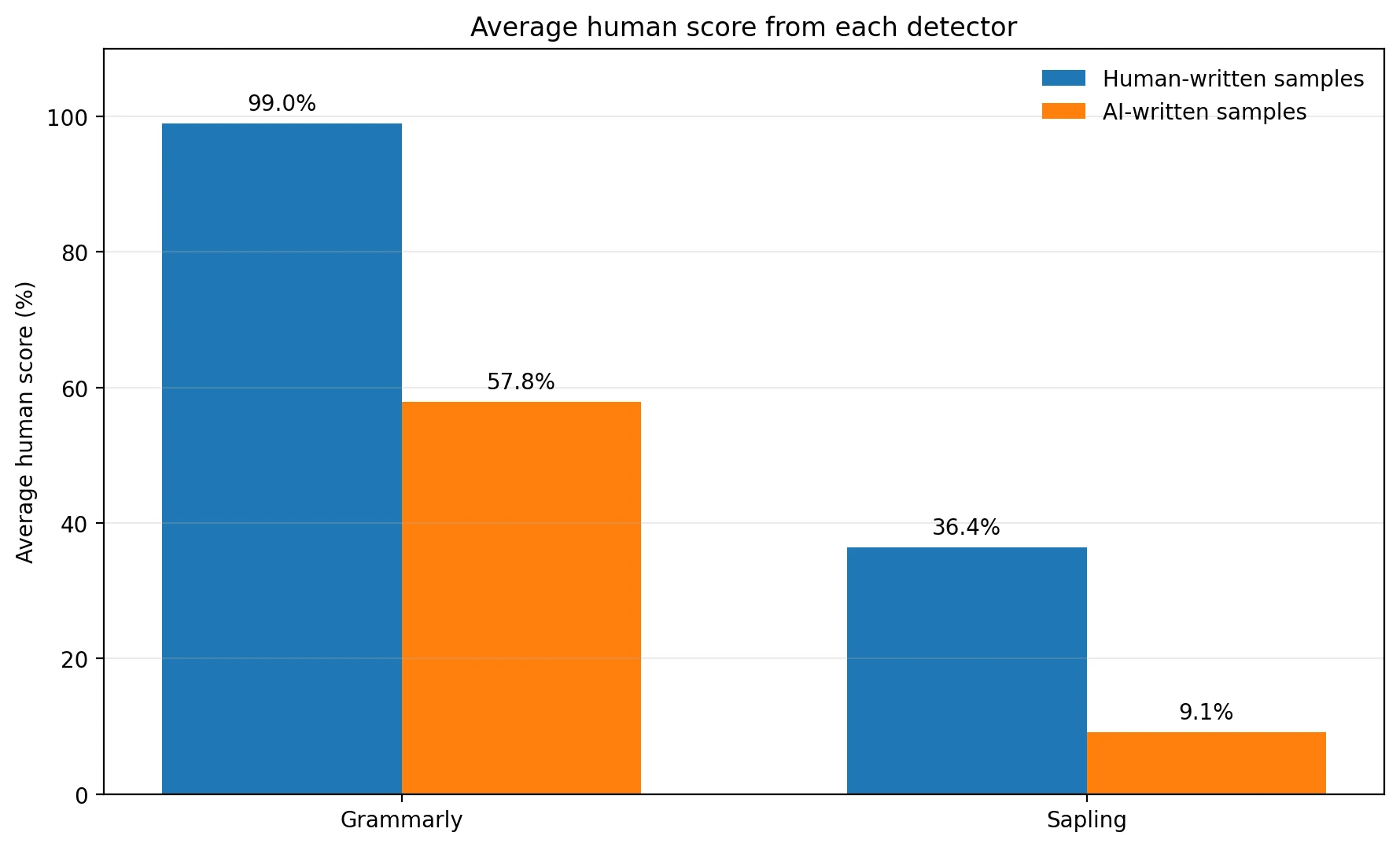
- Grammarly on human writing: 99.0% human on average.
- Grammarly on AI writing: 57.8% human on average.
- Sapling on human writing: 36.4% human on average.
- Sapling on AI writing: 9.1% human on average.
The first chart reveals the big trade-off
The averages already show that these tools behave very differently. Grammarly is extremely generous to human writing. In this dataset, it gave real human text an average score of 99.0% human, which is about as student-friendly as an AI detector can be. But there is a catch: it also gave AI text a fairly high average of 57.8% human. That means a lot of AI-generated writing still looked human enough to slip through.
Sapling goes in the opposite direction. It pushed AI text down to just 9.1% human on average, which sounds impressive at first. The problem is that it also scored human writing at only 36.4% human. For a student audience, that is a serious warning sign. A detector that often treats real writing as suspicious creates stress even when the student did nothing wrong.
Also Read: ZeroGPT vs Quillbot AI Detector
Why averages are not enough
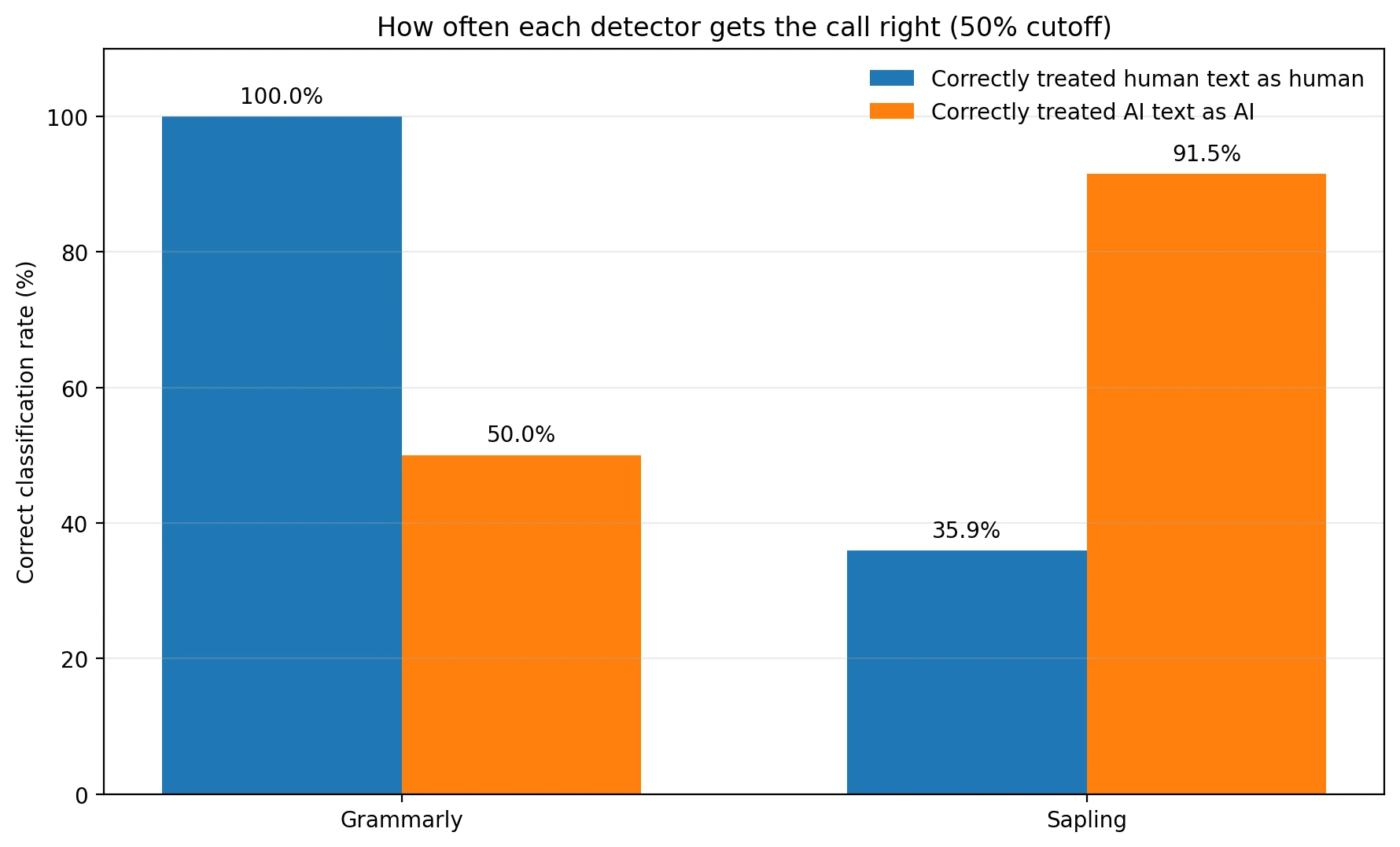
Averages are helpful, but students do not get graded on averages. They get judged one submission at a time. So I also looked at what happens when we use a simple cutoff: if a sample scores 50% or higher, treat it as human; if it scores below 50%, treat it as AI. This is not the only possible cutoff, but it is easy to understand and useful for comparing the tools on equal terms.
Using that rule, Grammarly correctly treated 100.0% of human samples as human. That is excellent for avoiding false accusations. But it only correctly caught 50.0% of AI samples. Put plainly, Grammarly missed half of the AI-written texts in this dataset.
Sapling showed the reverse pattern. It correctly caught 91.5% of AI samples, which is much stronger on pure detection. But it only recognized 35.9% of real human samples as human. That means nearly two out of every three human-written pieces were pushed into the suspicious zone.
Also Read: Originality.ai vs Quillbot AI detector
The most important chart for students: mistake rates
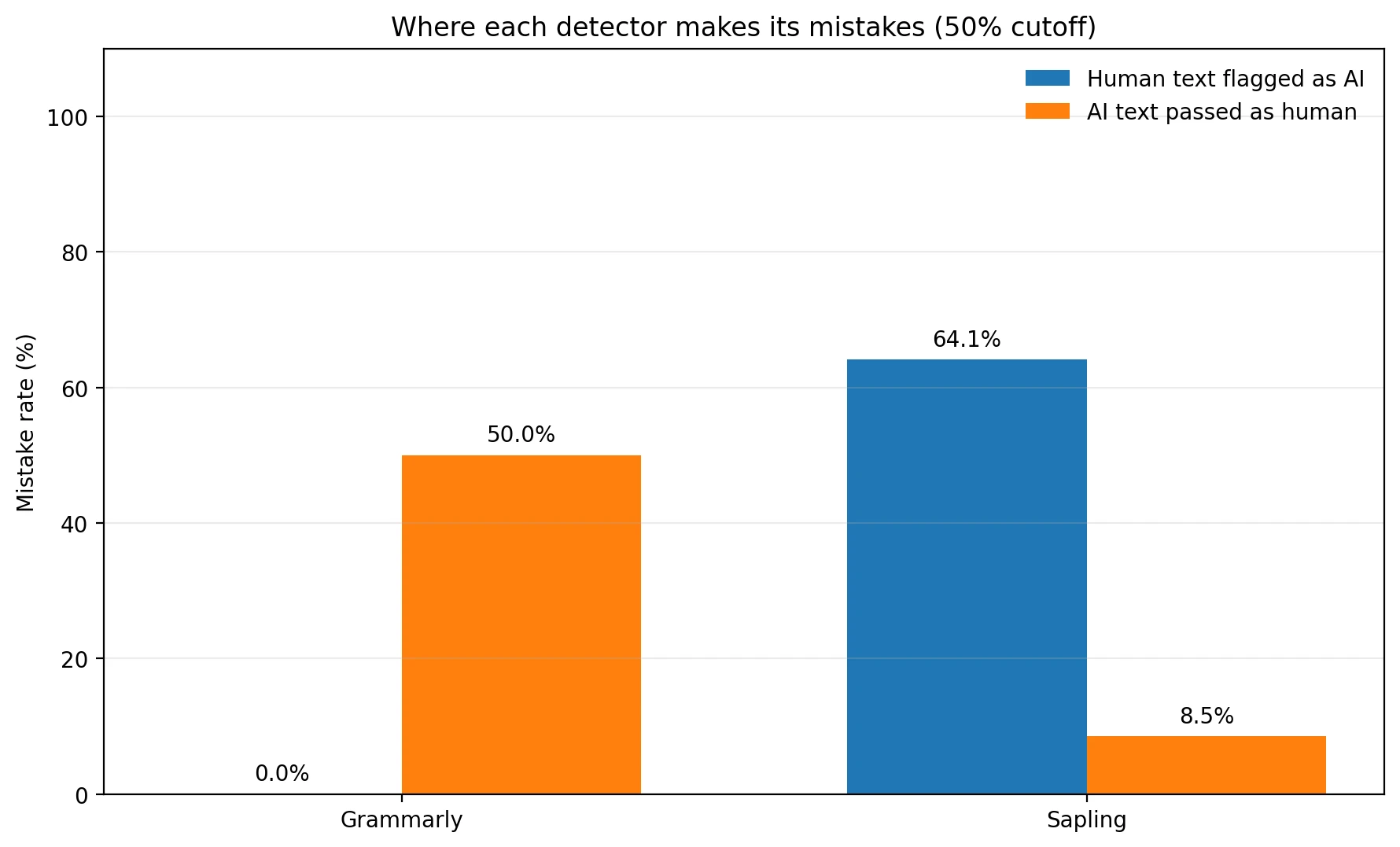
If you are a student, the most painful error is not “the detector missed some AI.” The most painful error is “the detector said my own writing looks fake.” That kind of mistake is often called a false positive. The term sounds technical, but the idea is simple: the tool raises the alarm when it should not.
Grammarly produced 0.0% false positives on human writing in this sample. Sapling produced 64.1%. That gap is enormous. At the same time, Grammarly let 50.0% of AI samples pass as human, while Sapling let through only 8.5%.
This is the heart of the comparison. Grammarly is safer for honest students but weaker as a filter. Sapling is stronger as a filter but much harsher on real writers. Whether one looks “better” depends on which mistake you think is more damaging.
What the score spread tells us
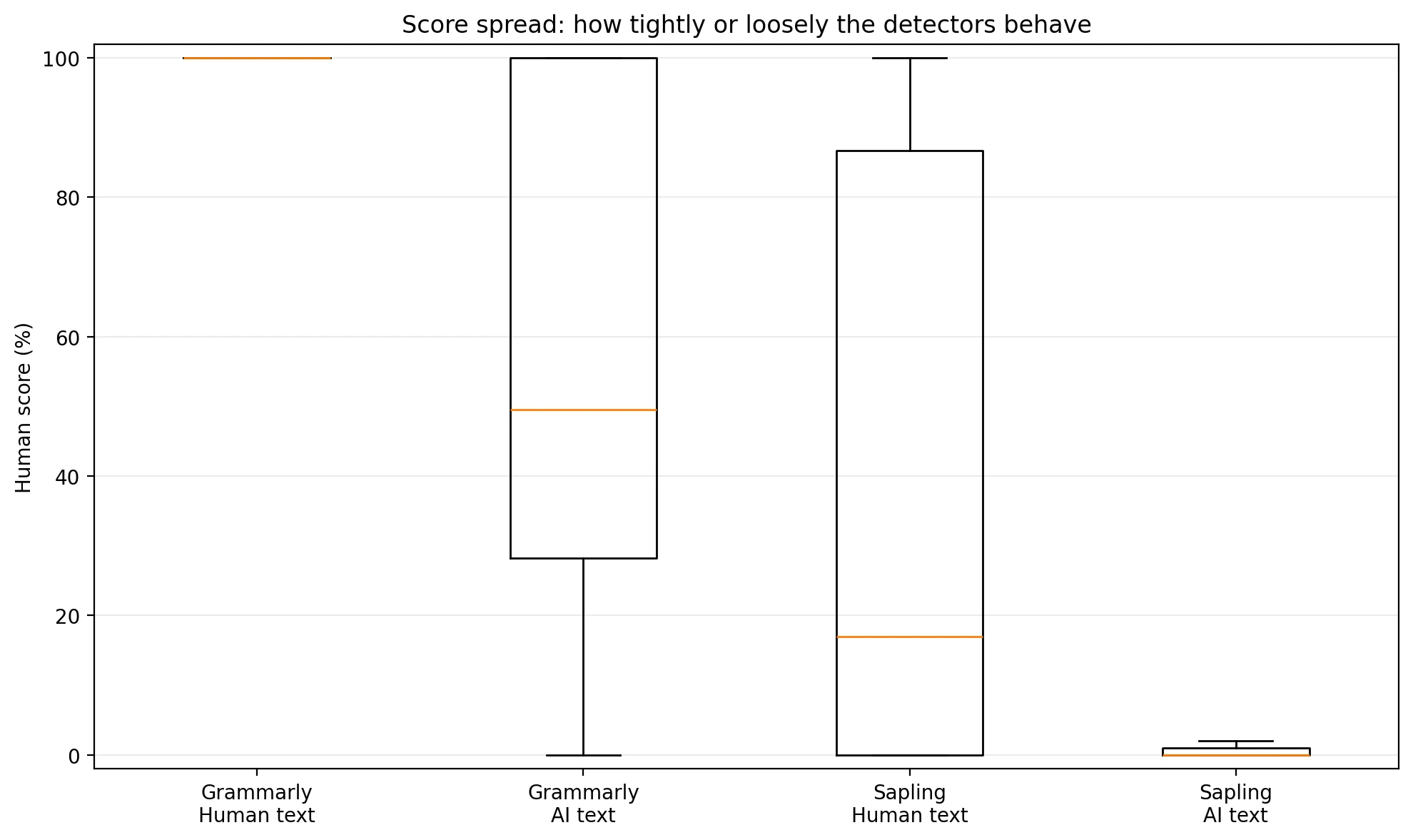
There is one more useful way to read the data: look at how spread out the scores are. A median is the middle score after all the scores are lined up from lowest to highest. It is helpful because it is less affected by a few extreme values.
For Grammarly, the human scores were packed at the top. The median human score was basically 100%, which means human writing almost always looked very human to Grammarly. But its AI scores were all over the place, with a median of only 49.5% human. That wide spread explains why half of the AI samples still escaped the detector.
For Sapling, the AI scores were tightly clustered near zero, with a median of 0.0% human. That is why it catches AI so often. But its human scores were unstable, with a median of just 17.0% human. In plain English, Sapling seems much less confident about what real human writing looks like in this dataset.
So which detector wins?
If the goal is to protect students from being wrongly flagged, Grammarly comes out ahead. It was far more respectful of human writing in this test, and that matters because a false accusation can do more harm than a missed alert. Its overall accuracy at the 50% cutoff was 74.4%, compared with 64.4% for Sapling.
If the goal is to catch as much AI writing as possible, Sapling is clearly more aggressive. But that aggressiveness comes with a heavy cost. A tool that catches AI while repeatedly casting doubt on genuine student work is not a fair judge on its own. At best, it can be one signal among many, not final proof.
Final takeaway
Grammarly is the fairer detector for students, while Sapling is the stricter detector overall. That difference matters. Fairness and strictness are not the same thing. Grammarly gave human writers room to sound like themselves, but it also struggled to stop AI from passing. Sapling did a much better job catching AI, yet it was so suspicious of human writing that it would be risky to use without human review.
For teachers, editors, and students alike, the lesson is bigger than this head-to-head comparison: AI detector scores should be treated as clues, not verdicts. A number on a dashboard is not the same as evidence of intent. The closer these tools move into education, the more important that distinction becomes.