

AI detectors have become an increasingly common fixture in academic settings, from high schools to universities. However, the reliability of these tools remains a subject of significant debate among educators, students, and researchers alike. To provide a comprehensive comparison between two popular options—Originality.ai and Grammarly's AI detector—I conducted an extensive test using 160 writing samples and recorded each tool's human score (where higher scores indicate text that appears more human-written). Below you'll find the complete results, including detailed charts, statistical analysis, and real screenshot examples to help you understand how these tools perform in practice.
Quick takeaways
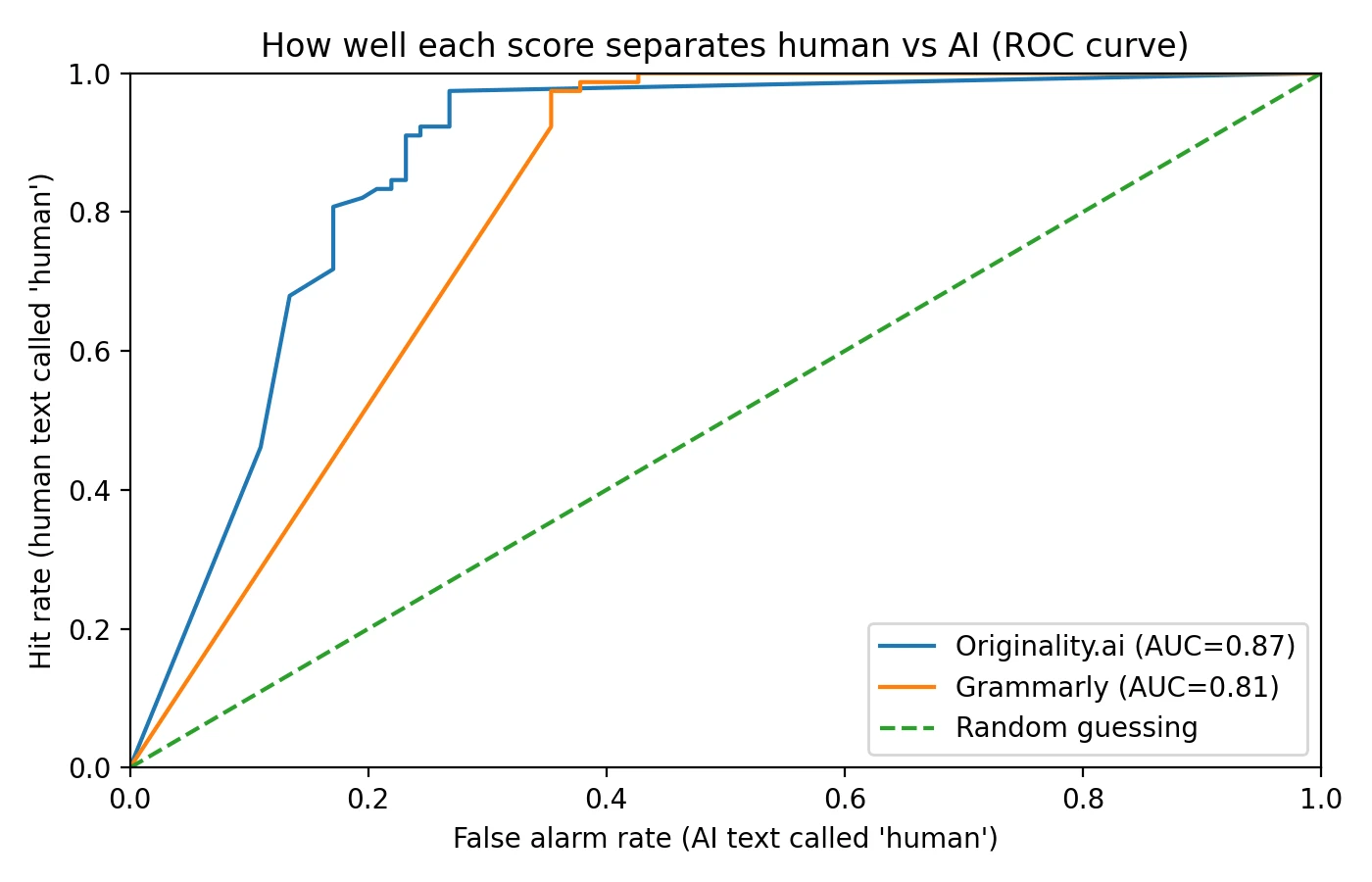
- Originality.ai demonstrated superior separation between AI and human content in my dataset, achieving an AUC of 0.87 compared to Grammarly's 0.81.
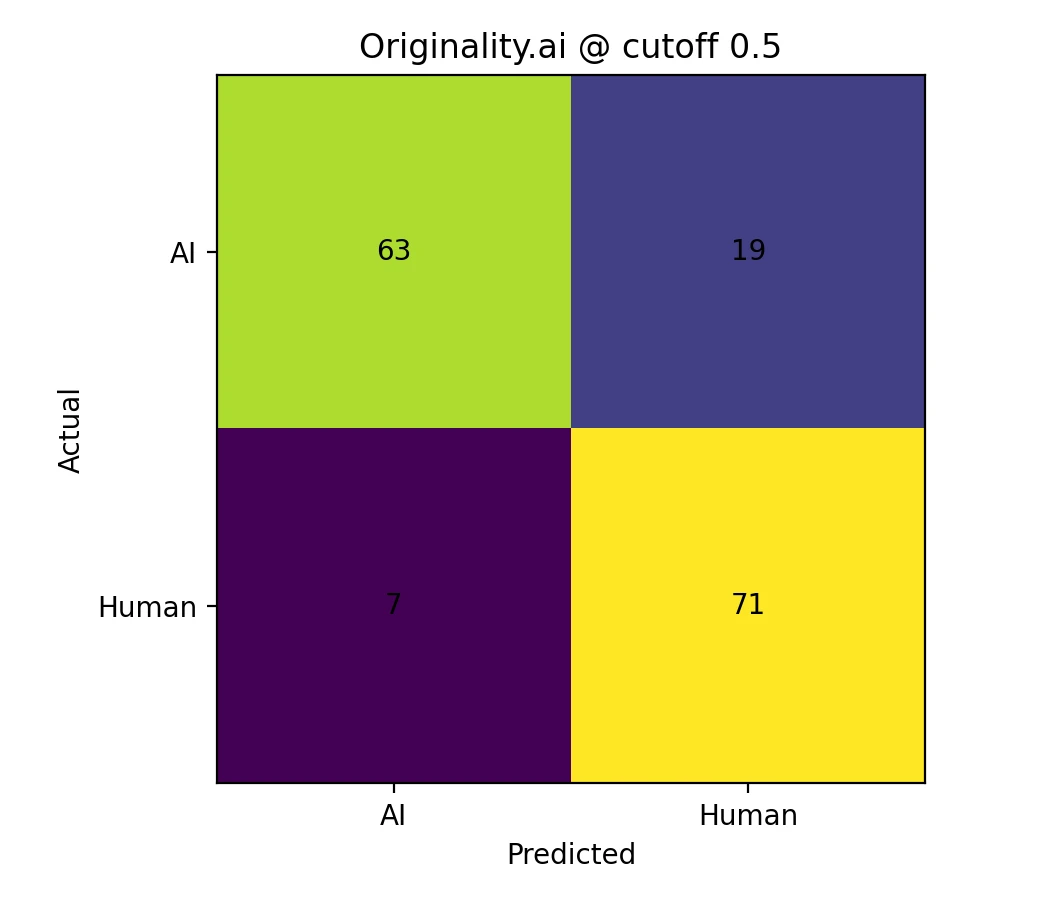
- When applying a straightforward cutoff of 0.5, Originality.ai successfully identified 76.8% of AI-generated samples, while Grammarly only caught 50.0%.
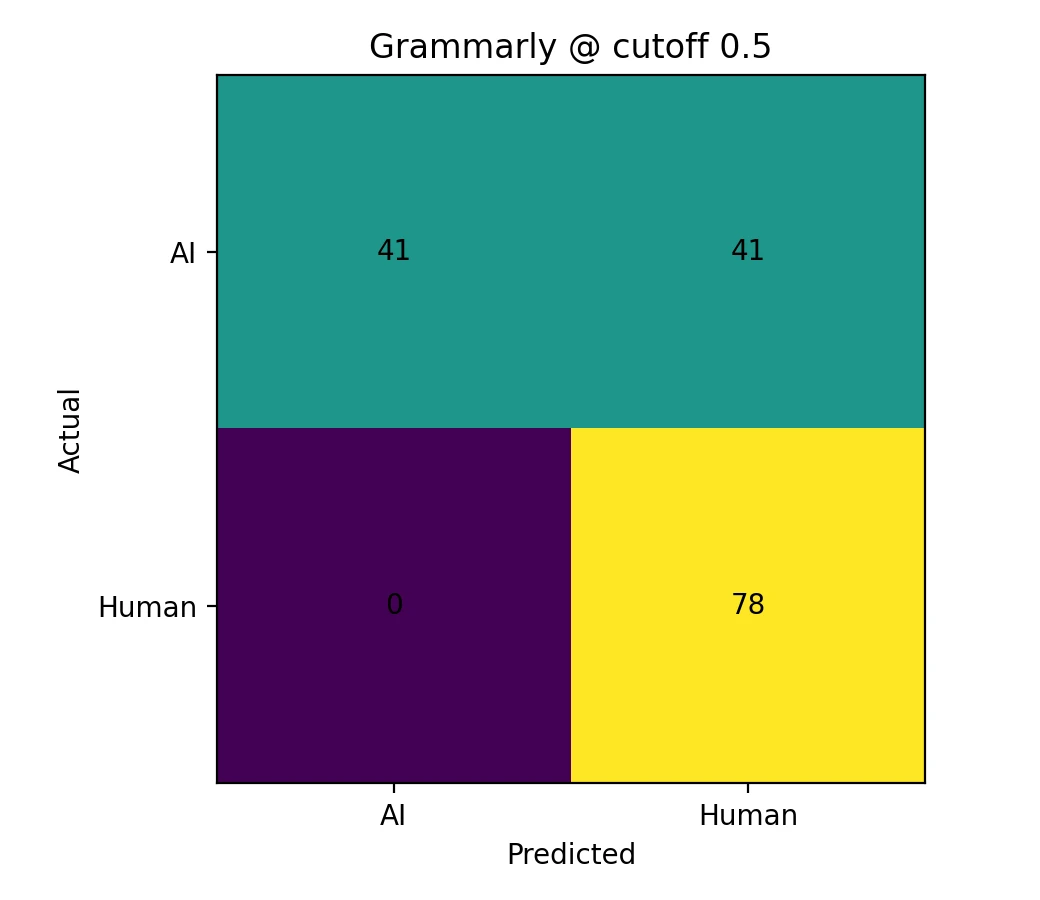
- Grammarly adopted a more conservative approach: it virtually never flagged legitimate human writing as AI at the 0.5 threshold, but this also means significantly more AI-generated content passed undetected.
Important caveat: AI detectors should never be treated as definitive proof of authorship. They function best as a “signal” or preliminary indicator, not as a final verdict that should determine academic consequences.
Understanding the test methodology
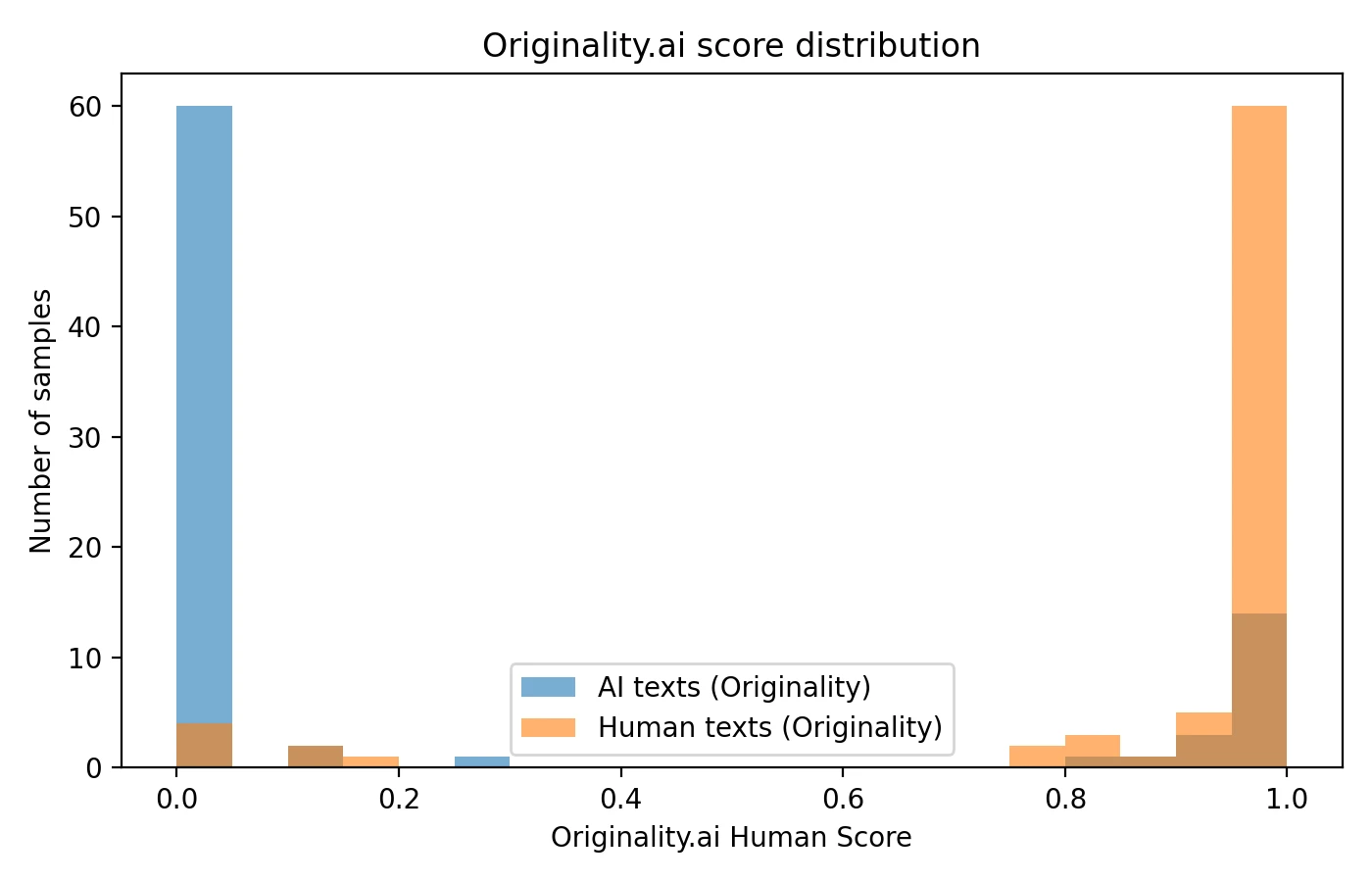
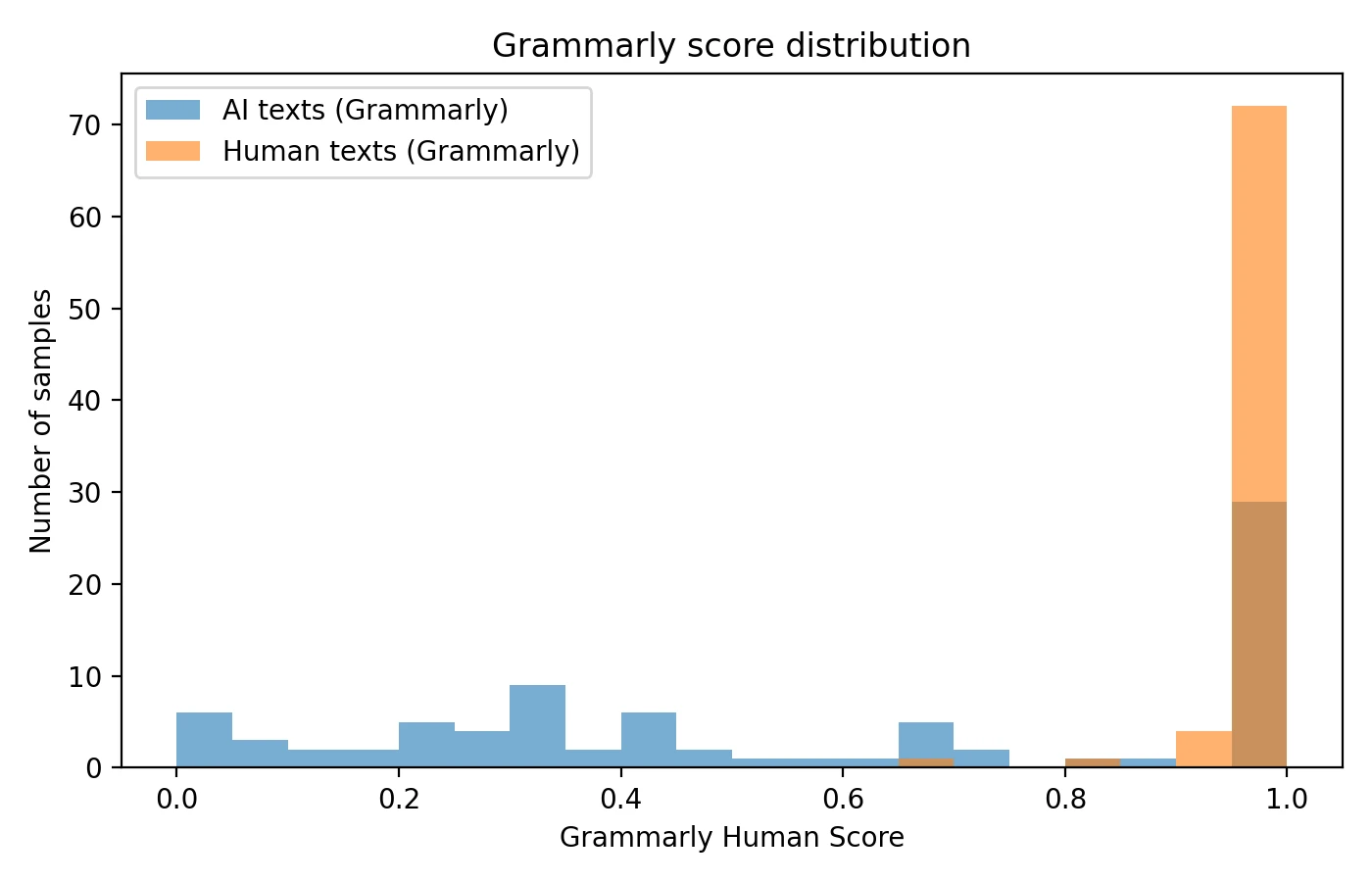
For this comparison, I collected and processed 160 writing samples through both AI detection platforms: Originality.ai and Grammarly's built-in AI detector. The sample set was carefully balanced, containing 78 confirmed human-written pieces and 82 AI-generated texts. Each tool analyzed every sample and returned a human score ranging from 0 to 1. In this scoring system, a higher value indicates the tool believes the text exhibits more characteristics typically associated with human authorship.
The AI-generated samples were created using various large language models, including different versions of GPT and Claude, to ensure the test reflected real-world diversity in AI writing. The human-written samples came from multiple sources, including academic essays, blog posts, professional articles, and informal writing, representing the broad spectrum of content that educators and students encounter daily.
Key definitions you should understand
- Cutoff (threshold): This is a predetermined numerical boundary we select (commonly 0.5) to make classification decisions. When a sample's score falls below this cutoff, we categorize the text as “AI-like” or suspicious. Choosing the right cutoff involves balancing sensitivity against specificity.
- False accusation (false positive): This occurs when a detector incorrectly flags genuinely human-written content as AI-generated. These errors can have serious consequences in academic settings, potentially leading to unjust accusations of cheating. False accusations tend to occur more frequently with certain writing styles, particularly formal academic prose, technical documentation, or content that follows strict structural conventions.
- True positive rate: The percentage of AI-generated content that the detector correctly identifies as such. Higher is generally better for catching potential misuse.
Also Read: Originality AI vs Sapling AI
| Metric (with explanation) | Originality.ai | Grammarly |
|---|---|---|
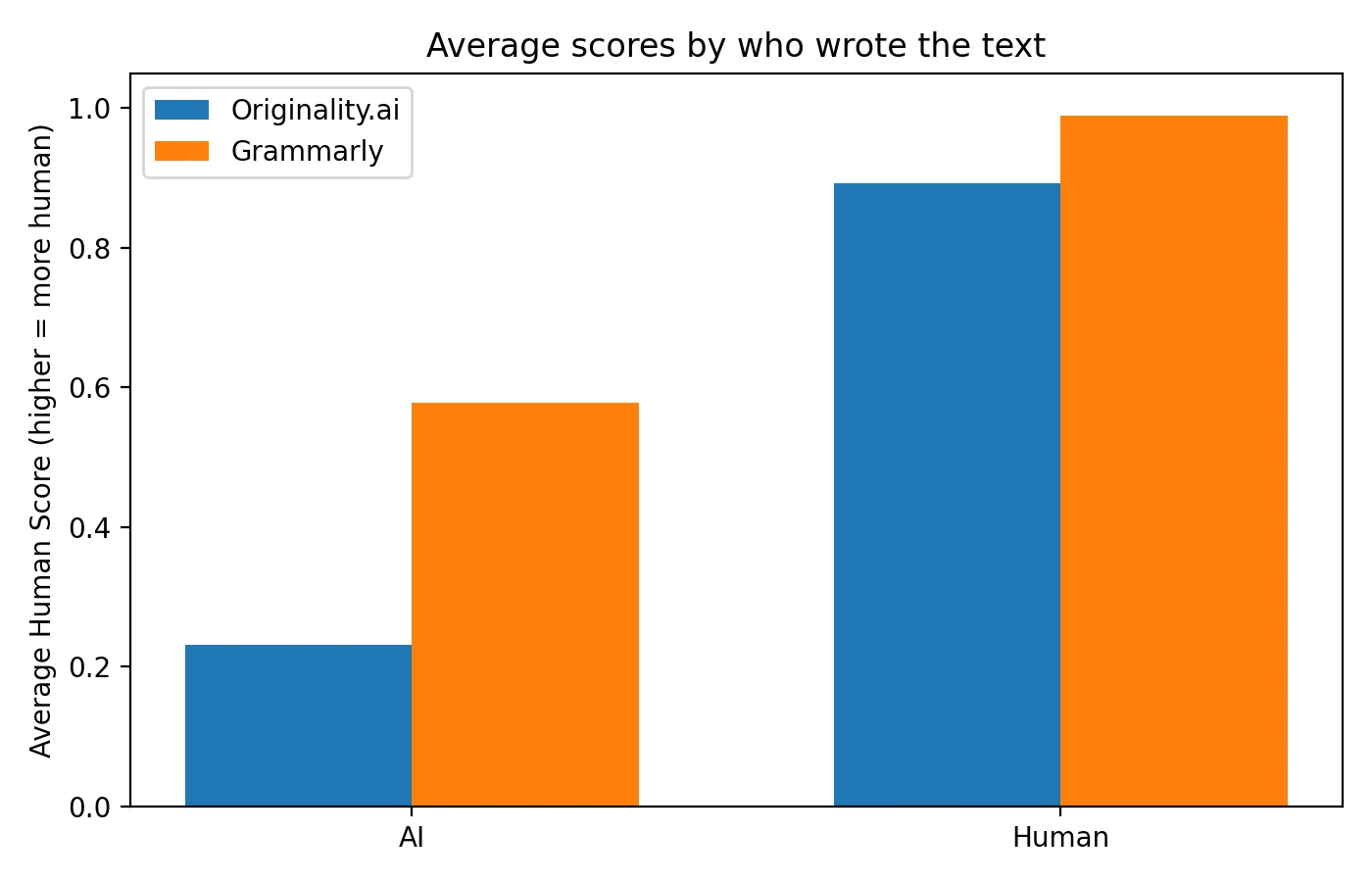
| Average score on AI-written text (lower values indicate better AI detection capability) | 0.231 | 0.578 |
| Average score on human-written text (higher values indicate better human recognition) | 0.893 | 0.990 |
| “AI caught” rate at 0.5 cutoff (percentage of AI samples scoring below threshold) | 76.8% | 50.0% |
| Human false-accusation rate at 0.5 cutoff (percentage of human samples incorrectly flagged) | 9.0% | 0.0% |
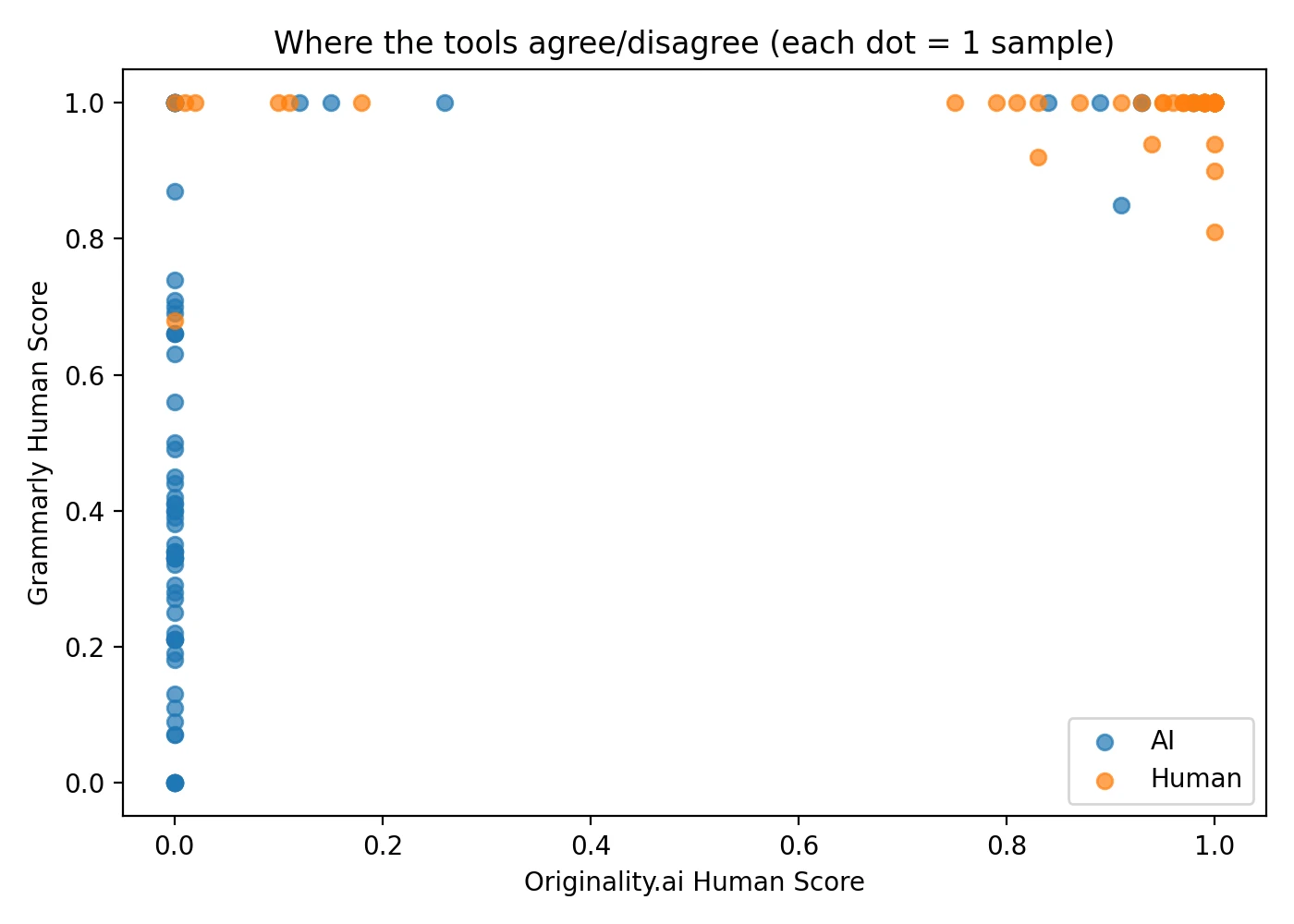
| Score correlation between tools (0 = completely unrelated, 1 = perfect agreement) | 0.75 | |
Understanding AUC: The Area Under the Curve (AUC) metric provides a comprehensive measure of a classifier's ability to distinguish between two groups—in this case, human-written versus AI-generated content. AUC values range from 0 to 1, where 0.5 represents random chance (essentially coin-flip accuracy) and 1.0 represents perfect classification. An AUC of 0.87 means that if you randomly selected one AI sample and one human sample, the detector would correctly rank them 87% of the time.
Detailed results with visual analysis
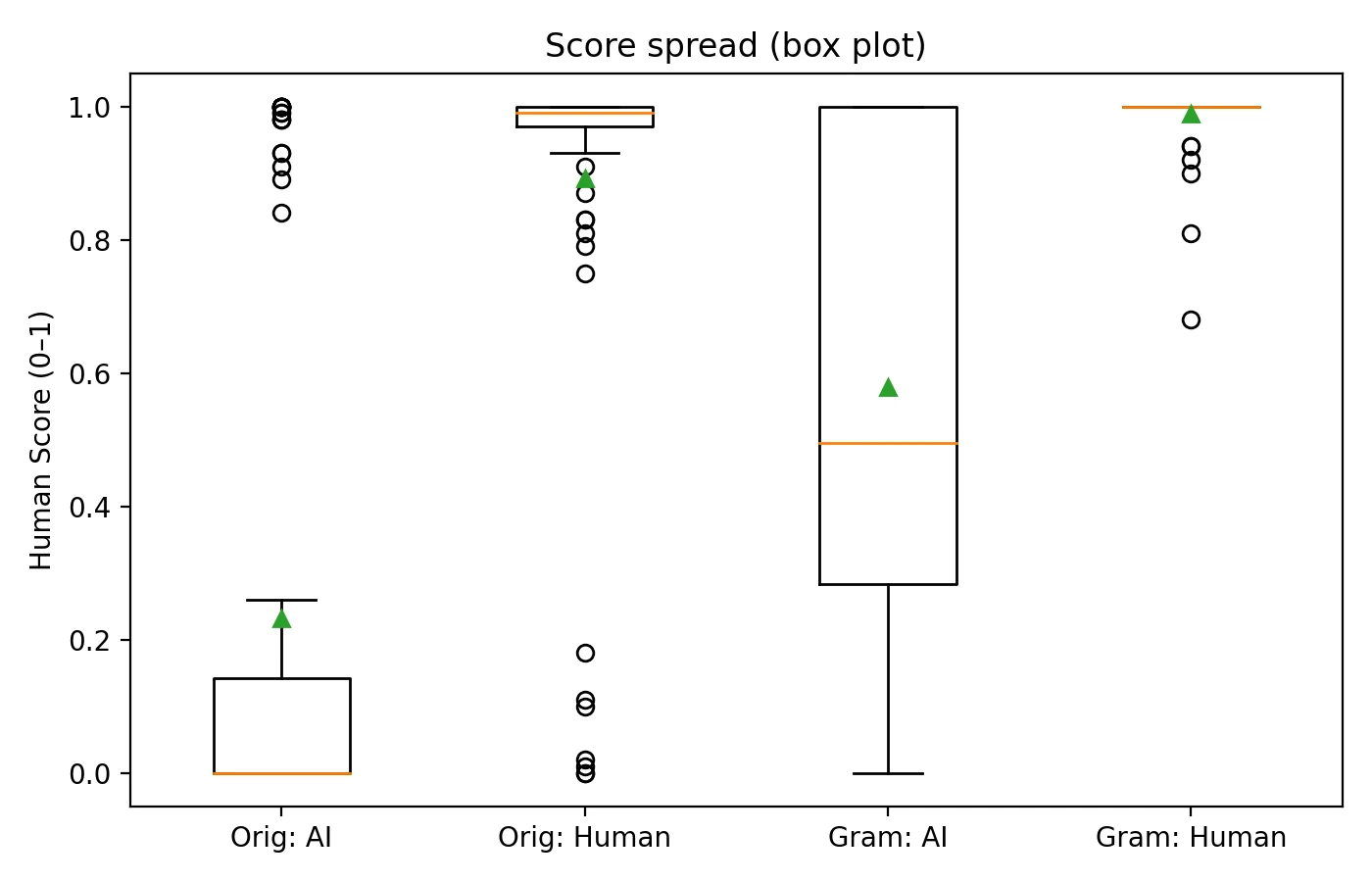
The following charts provide multiple perspectives on how each detector performed across the entire dataset. Understanding these visualizations will help you grasp not just the average performance, but also the consistency and reliability of each tool's judgments.
Also Read: Winston AI vs. Turnitin
Cutoff analysis using confusion matrices
A confusion matrix is a fundamental evaluation tool that presents classification results in a clear 2×2 table format. It counts exactly how many samples were classified correctly versus incorrectly at a given threshold. The “Predicted” labels indicate what classification the detector would assign based on whether the score falls above or below the chosen cutoff value.
Practical implications of these results
The confusion matrices reveal important trade-offs that educators and students should understand when interpreting AI detector results:
- Originality.ai demonstrated aggressive detection capabilities, successfully catching a significantly higher proportion of AI-generated samples at the 0.5 threshold. However, this heightened sensitivity came at a cost—it also produced more false accusations against legitimately human-written content.
- Grammarly took a notably conservative approach, virtually eliminating false accusations at the 0.5 cutoff. The trade-off is that substantially more AI-generated content passed through undetected, receiving scores that would classify it as human-written.
| Cutoff selection | Resulting behavior | Originality.ai performance | Grammarly performance |
|---|---|---|---|
| 0.5 (standard) | Balanced starting point for most use cases | AI detection rate: 76.8% False accusation rate: 9.0% |
AI detection rate: 50.0% False accusation rate: 0.0% |
| 0.9 (aggressive) | Catches more AI content but increases risk of false accusations | AI detection rate: 79.3% False accusation rate: 16.7% |
AI detection rate: 64.6% False accusation rate: 2.6% |
The impact of text length on detection scores
An important factor that often goes unexamined is whether document length influences AI detector scores. I analyzed the relationship between word count and assigned scores to understand if longer submissions receive systematically different treatment. The data revealed a modest positive correlation, suggesting that longer texts tend to receive slightly higher “human” scores on average, though the effect was not dramatic.
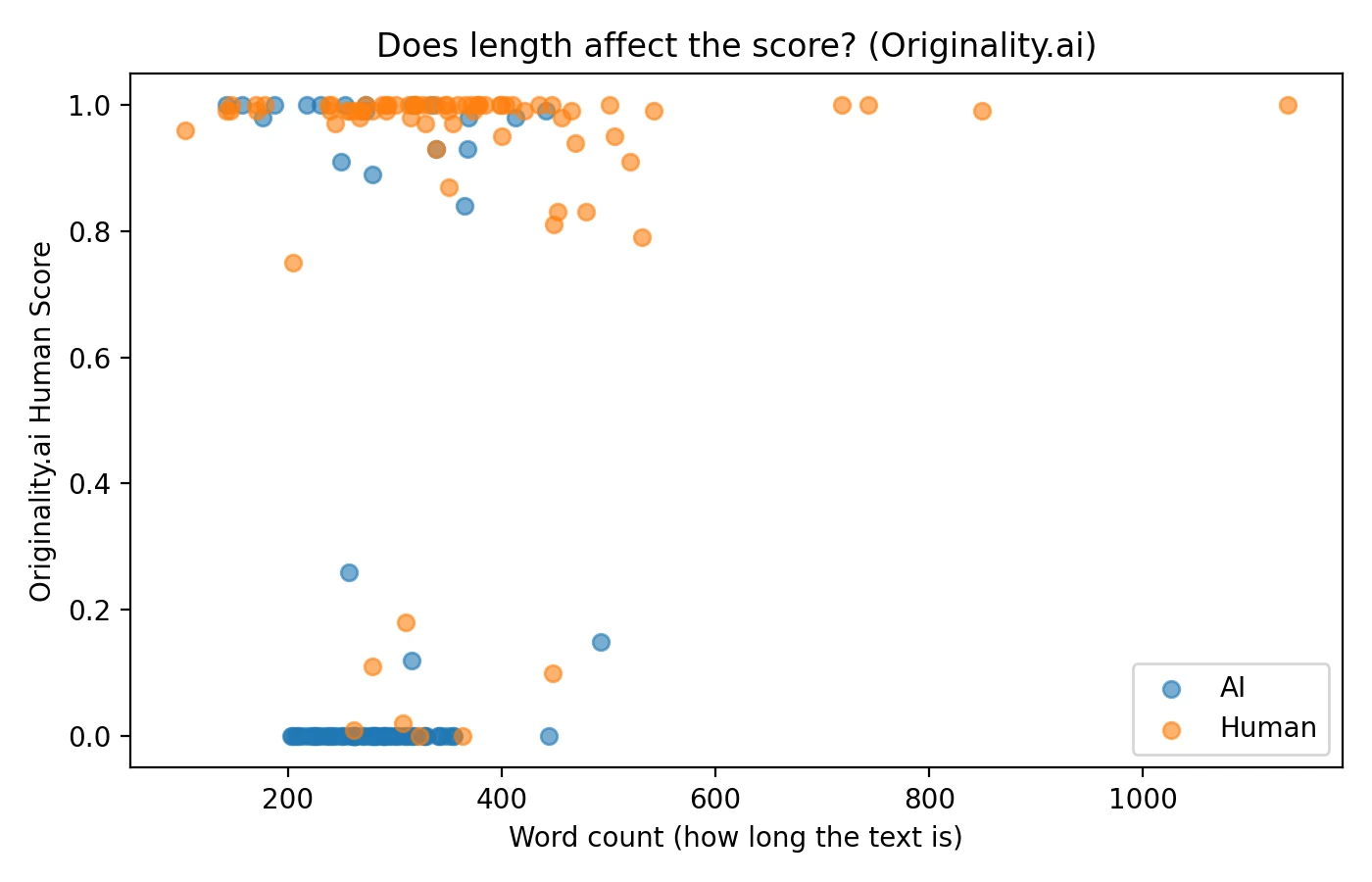
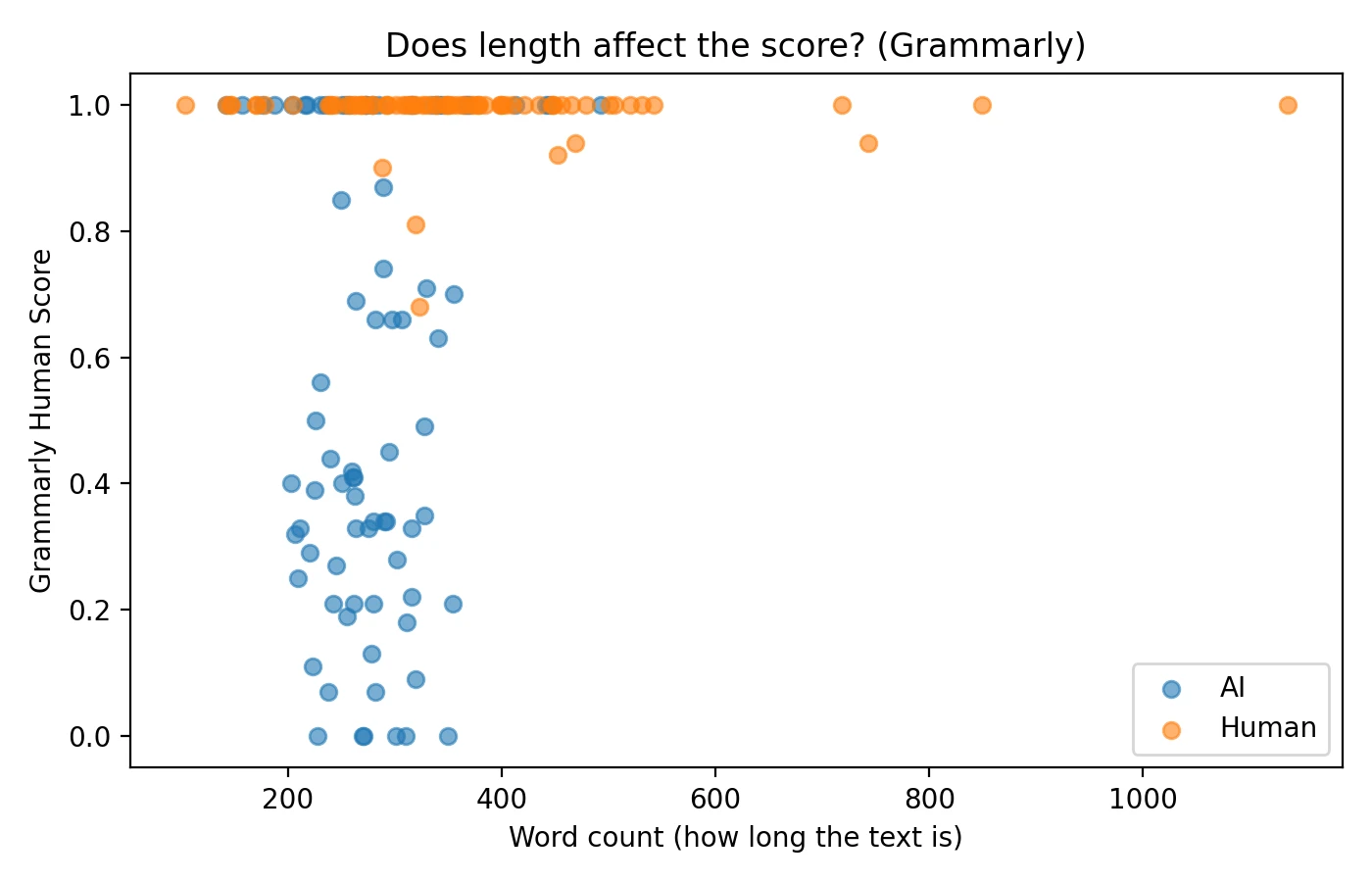
This length bias represents one reason why AI detectors can produce unfair or inconsistent results. Short-form content like brief answers, bullet-pointed lists, and highly structured formal writing often lacks the natural variation that detectors associate with human authorship, making such content more susceptible to false accusations.
Real-world screenshot comparisons
To provide concrete examples of how these tools present their findings, here are side-by-side screenshots showing actual detector outputs. These examples help illustrate the different interfaces, scoring presentations, and additional information each tool provides to users.
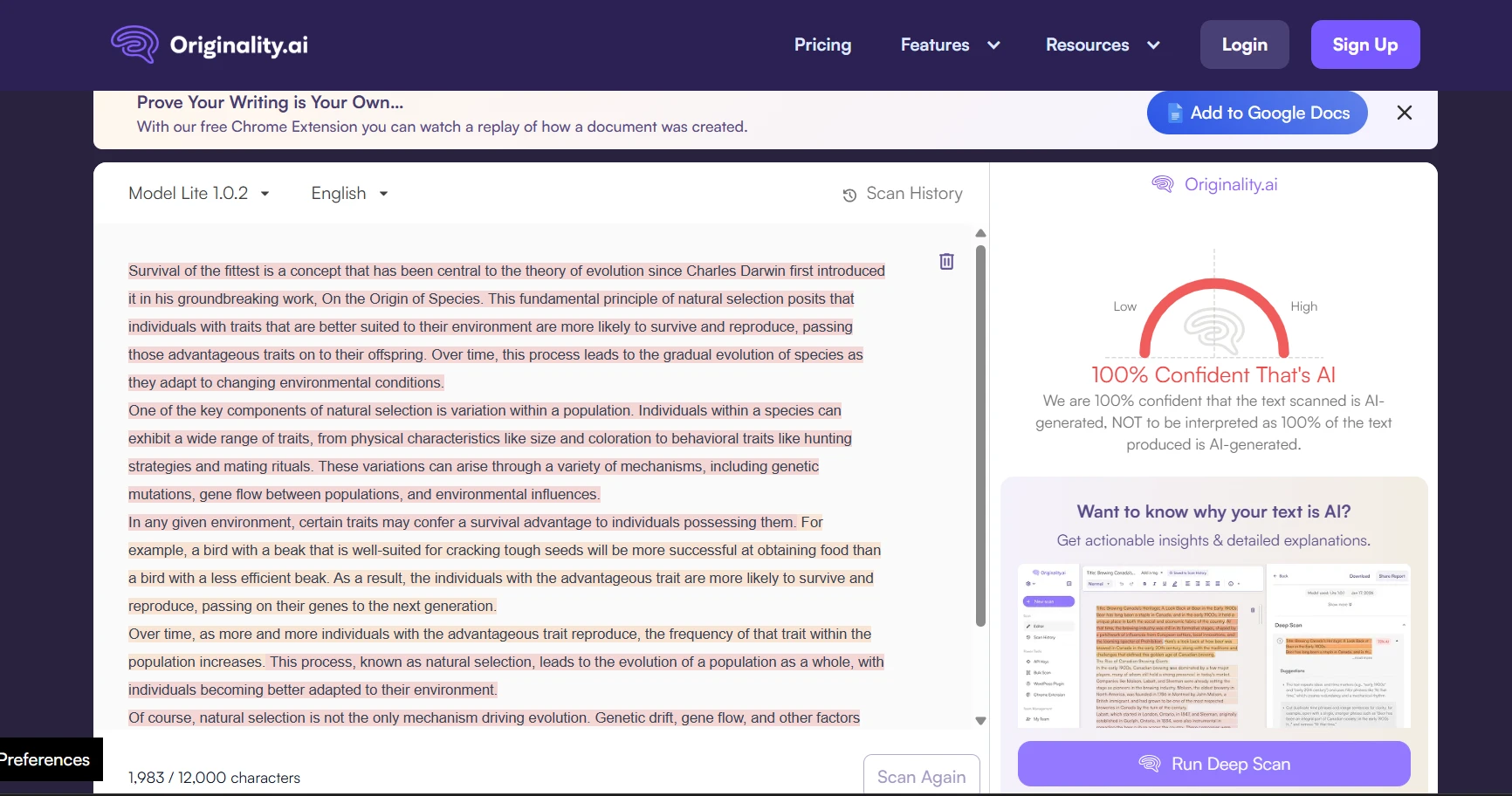
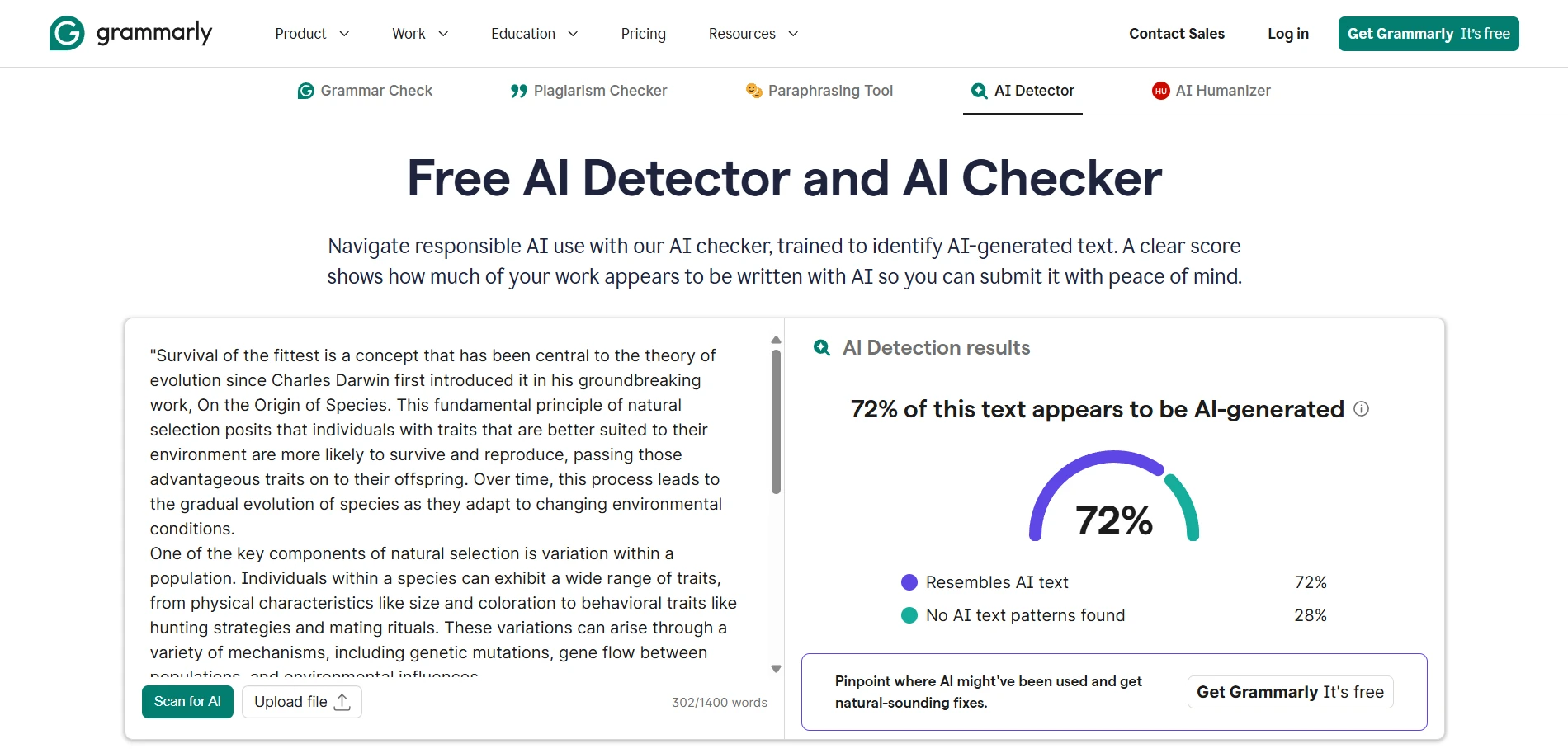
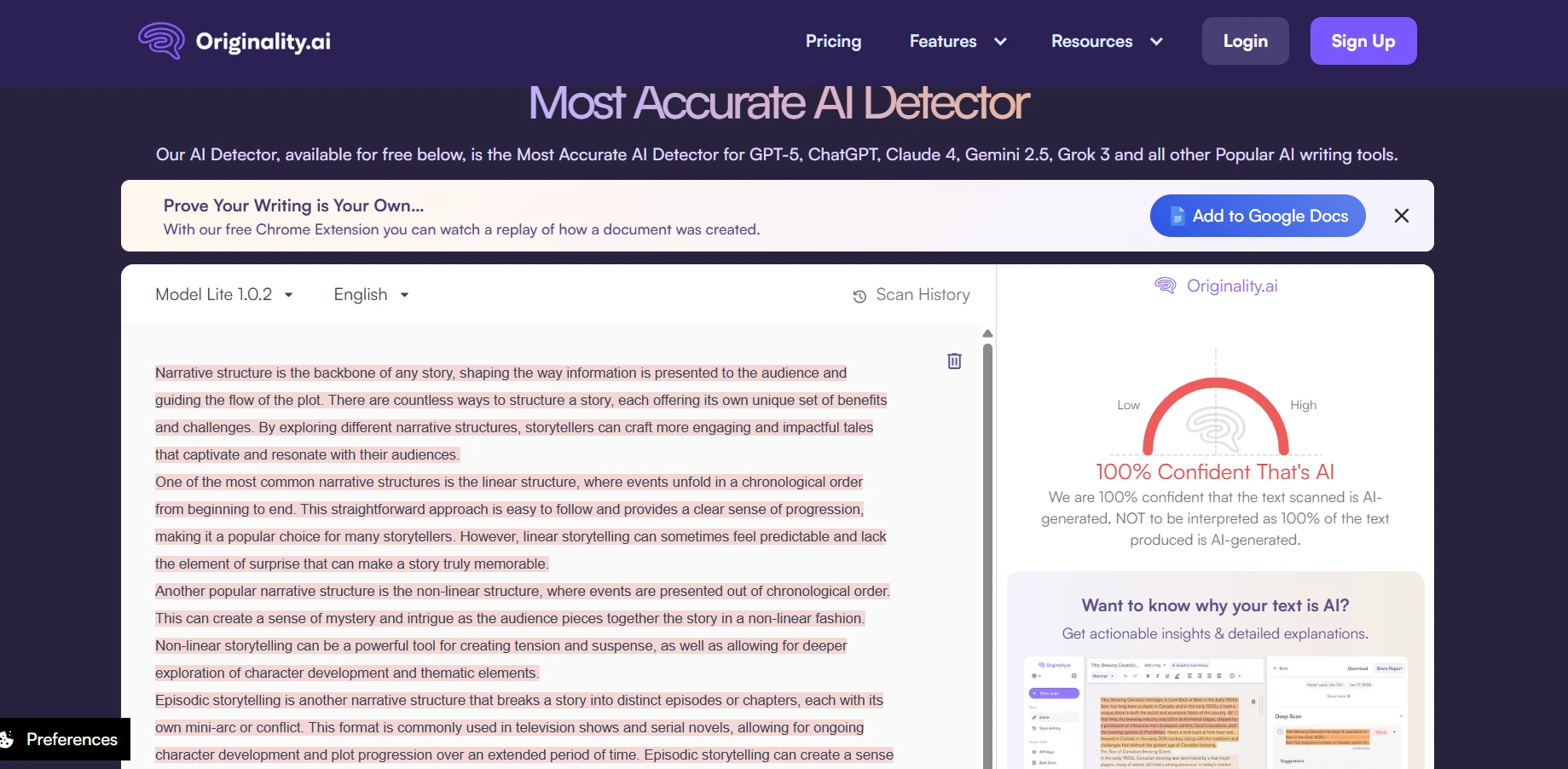
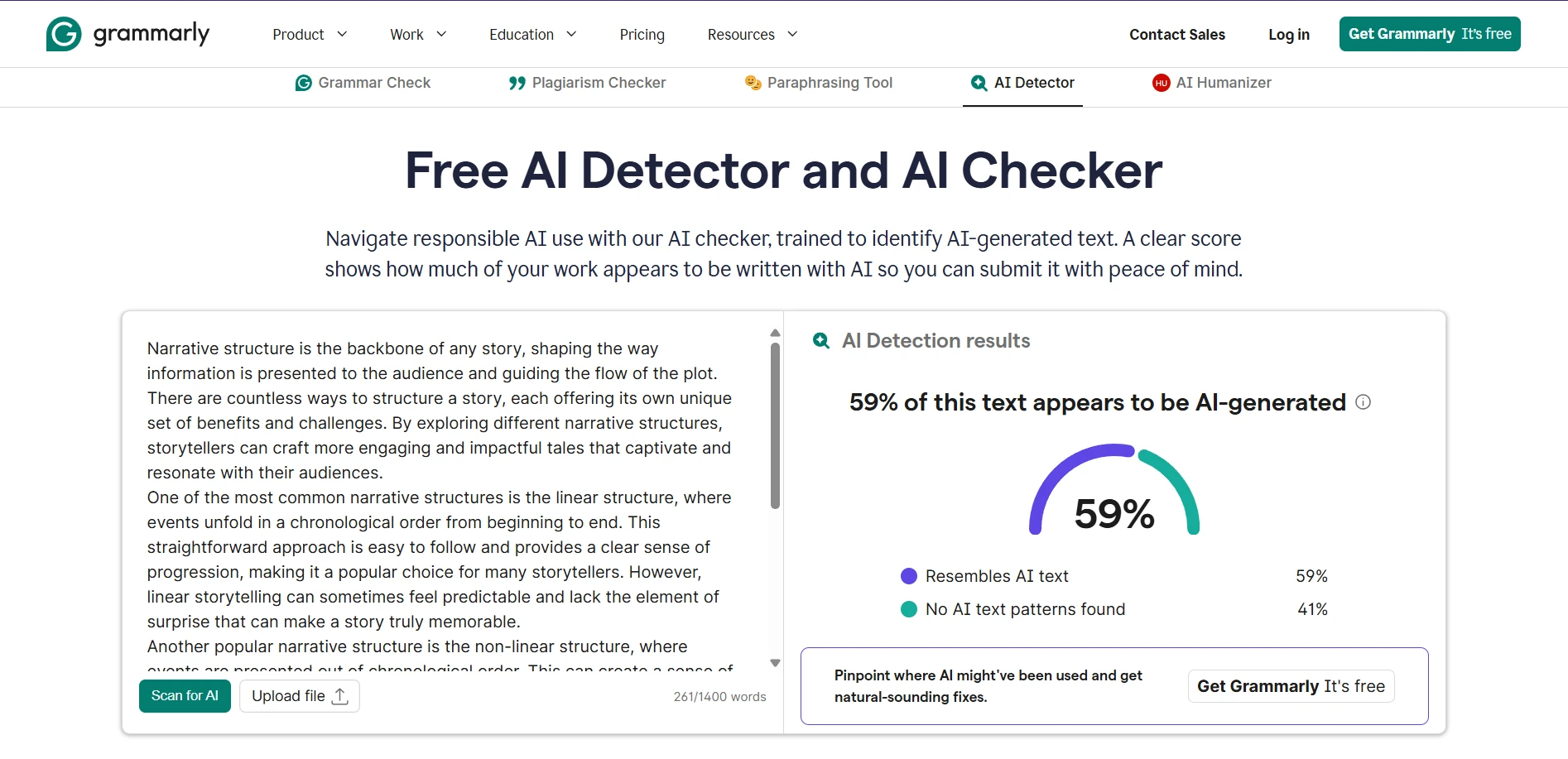
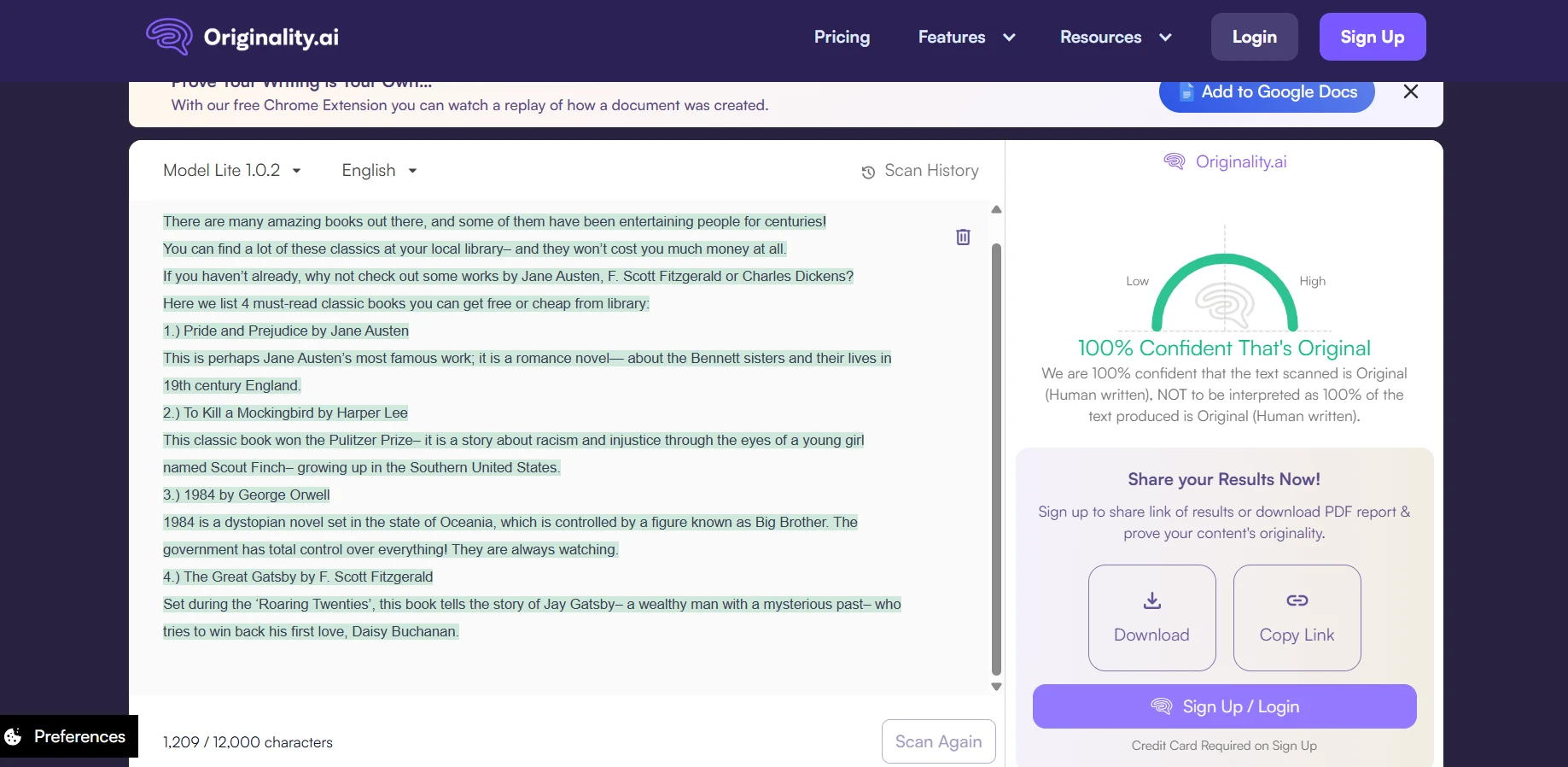
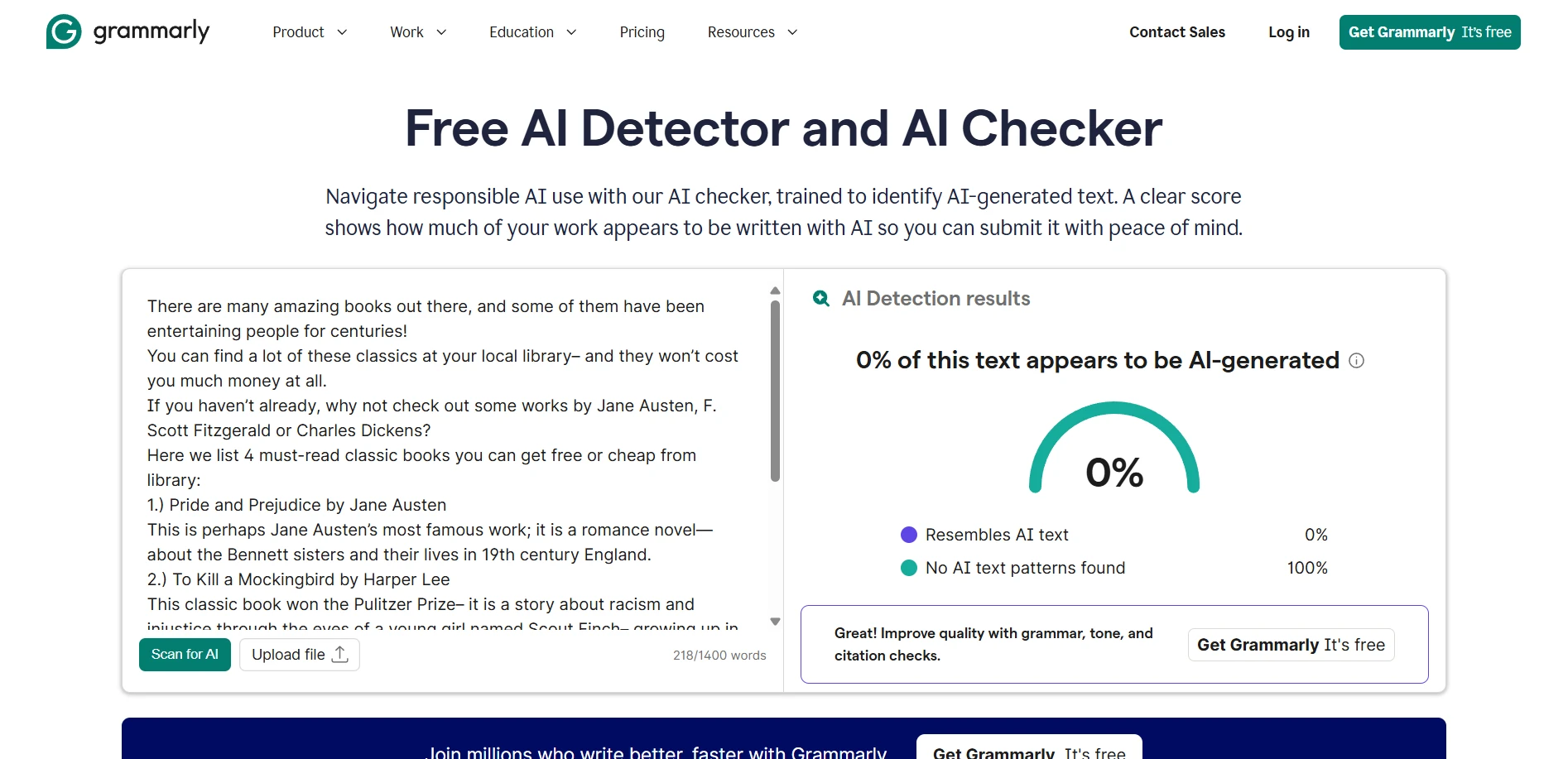
The final verdict
Key conclusions from analyzing 160 samples
- For maximizing AI detection capability: Originality.ai delivered demonstrably superior performance in this dataset, catching a substantially higher percentage of AI-generated content at equivalent cutoff thresholds.
- For minimizing false accusations: Grammarly proved significantly safer at the standard 0.5 cutoff, producing virtually zero incorrect flags against legitimate human writing—an important consideration in high-stakes academic contexts.
Practical decision framework
- If you're a student using a detector to self-check your work before submission, consider prioritizing the tool that minimizes false accusation risk (Grammarly at moderate cutoffs). This approach helps you avoid unnecessary anxiety over legitimate human writing.
- If you're an educator using a detector to investigate potential academic integrity concerns, a tool with higher detection rates may be more appropriate—but this must absolutely be combined with thorough human review. Examine drafts, check sources, discuss the writing process with the student, and never rely solely on algorithmic output.
- For institutional policy development, consider using multiple detectors in conjunction and establishing clear protocols that treat detector output as one piece of evidence among many, never as conclusive proof.
Important limitations to consider
No evaluation of AI detectors would be complete without acknowledging the significant limitations inherent in this type of testing:
- Temporal validity: Both AI detectors and the language models they attempt to identify undergo continuous updates and improvements. Results from this test may not perfectly predict future performance as algorithms evolve.
- Dataset specificity: My sample collection may not represent the specific types of content relevant to your context. Different subject areas, writing conventions, student populations, and languages can all significantly affect detection accuracy.
- Fundamental uncertainty: Scores are probabilistic estimates, not ground truth. A high “human” score cannot guarantee authentic human authorship, and a low score cannot definitively prove AI generation. Many factors—including writing style, topic complexity, and even the author's first language—can influence scores in unpredictable ways.
- Adversarial robustness: This test did not examine how well either detector handles deliberately obfuscated AI content, such as text that has been paraphrased, edited, or processed through multiple tools to evade detection.