![[HOT] Quillbot vs Sapling AI Detector: Which One is Fairer to Student Writing?](/static/images/quillbot-vs-sapling-featured-imagepng.webp)

AI detectors are often presented as if they can settle the question of authorship in seconds. In real classrooms, the stakes are much higher. A detector that is too forgiving can miss AI-written work, but a detector that is too aggressive can wrongly cast doubt on honest students. To see where these trade-offs show up, I tested 160 samples and compared Quillbot with Sapling using the detectors’ scores converted into human scores. In this format, higher means “more likely written by a person” and lower means “more likely written by AI.”
How this comparison was set up
The dataset contains 78 human-written samples and 82 AI-written samples. Every sample was run through both tools. Because the original tools report AI scores, I converted those into human scores so the charts are easier to read. A score near 100% means the detector leans strongly toward human writing. A score near 0% means it leans strongly toward AI.
This matters because the same number means something different depending on what kind of text you are testing. On a human essay, a high human score is good. On an AI sample, a high human score is bad, because it means the detector was fooled.
Also Read: Grammarly AI vs Quillbot AI Detector
What jumped out immediately
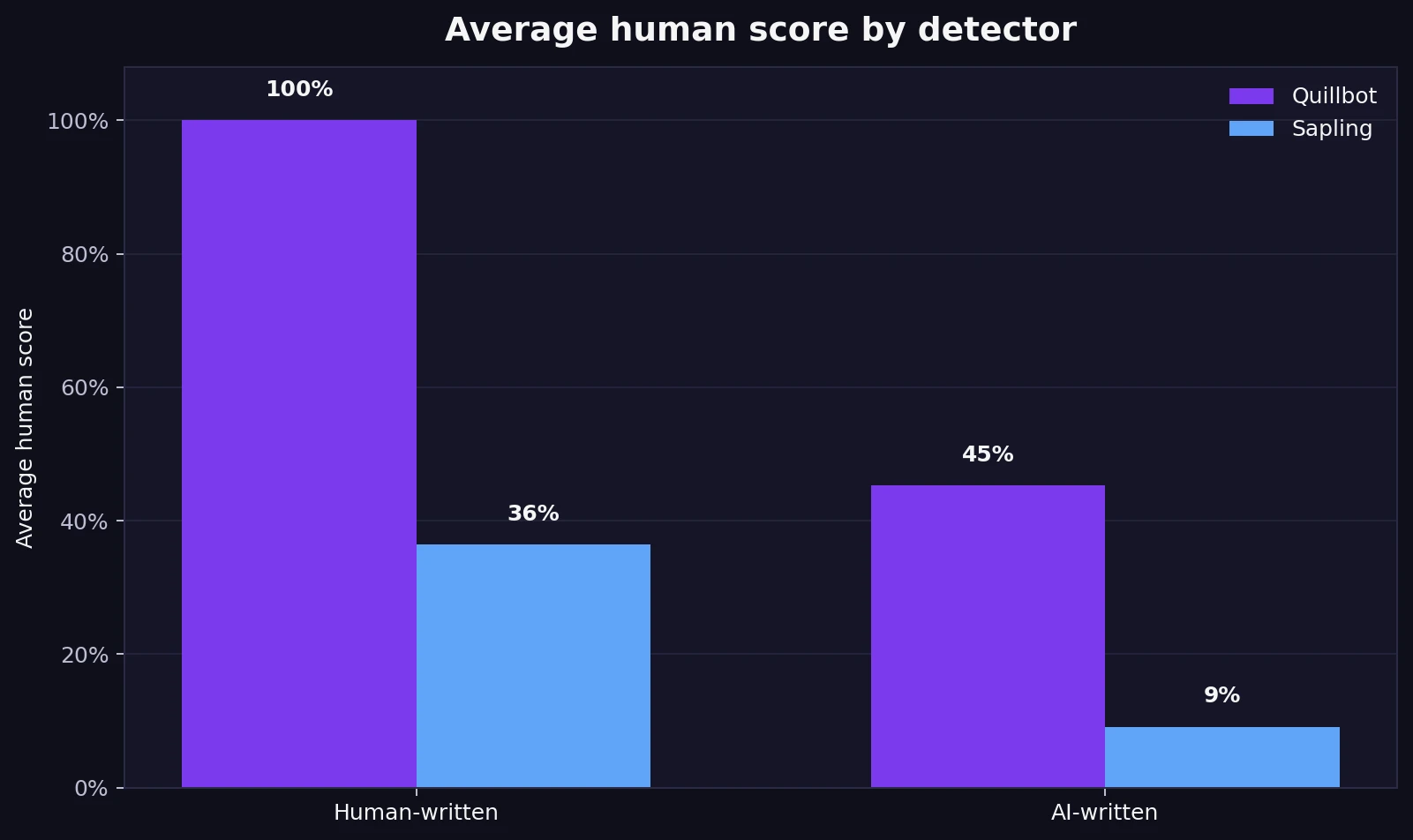
- On the human-written texts: Quillbot gave an average human score of 100.0%, while Sapling gave 36.4%.
- On the AI-written texts: Quillbot still gave an average human score of 45.2%, while Sapling dropped much lower to 9.1%.
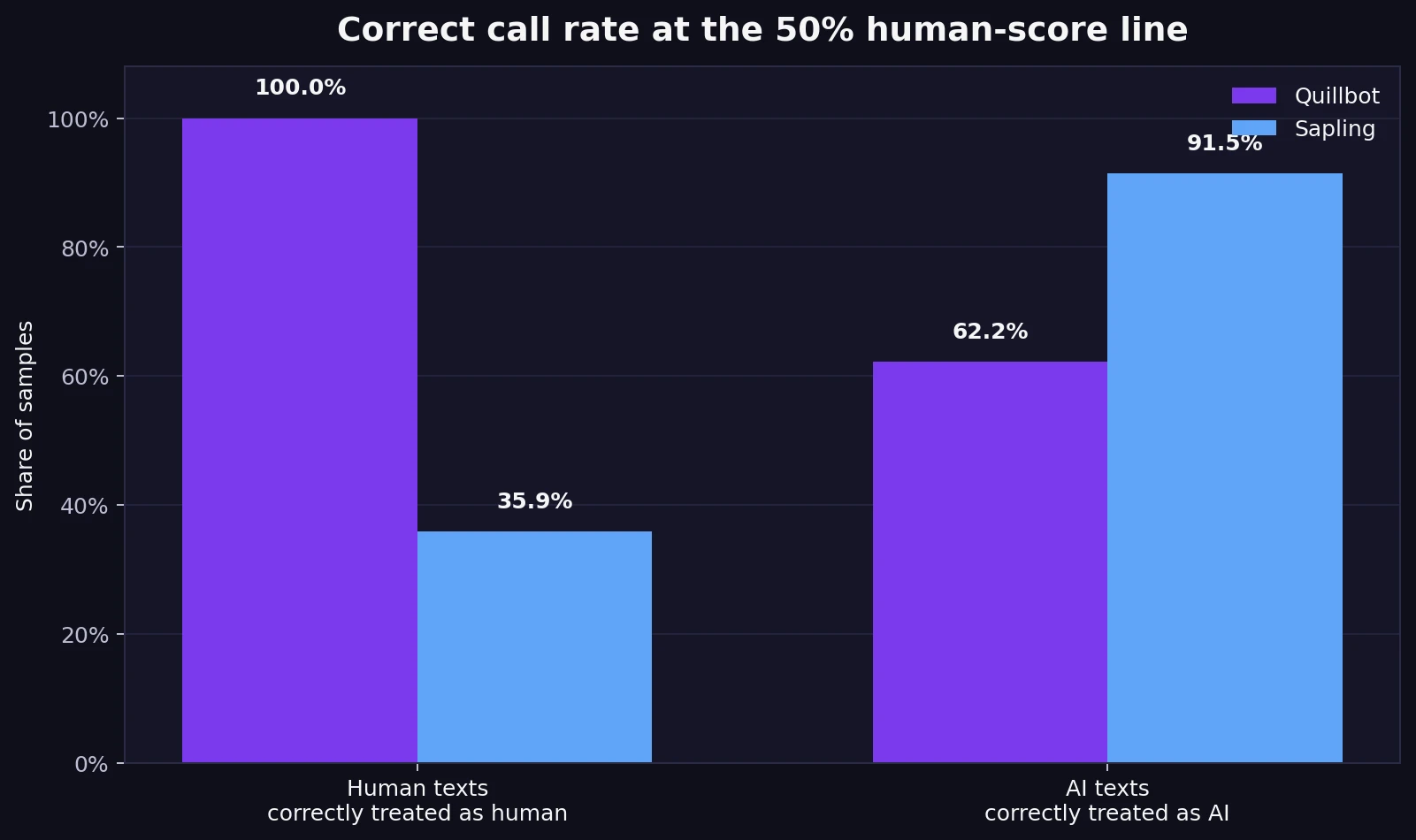
- Using the 50% line as a simple cutoff: Quillbot correctly treated 100.0% of human samples as human, but only 62.2% of AI samples as AI.
- Sapling showed the opposite pattern: it correctly treated 91.5% of AI samples as AI, but only 35.9% of human samples as human.
The first chart shows the trade-off clearly
The bar chart below gives the quickest overview. Quillbot is extremely generous to human writing, at least in this dataset. It gave every human sample a perfect human score, which is why its average lands at 100%. That sounds impressive, but the second half of the chart tells a more complicated story: on AI-written text, Quillbot still averaged 45.2% human. In plain English, it often gave AI content the benefit of the doubt.
Sapling behaved very differently. It was far stricter overall. That helped it keep the AI-written samples low, averaging just 9.1% human. The downside is that it was also harsh on genuine human writing, which only averaged 36.4% human.
Also Read: Grammarly AI vs Sapling AI Detector
Why students should care about false positives
A false positive happens when a detector labels human writing as AI. This is one of the most important ideas in the whole comparison, so it is worth defining simply: it means a real student could be treated as suspicious even when they wrote the work themselves.
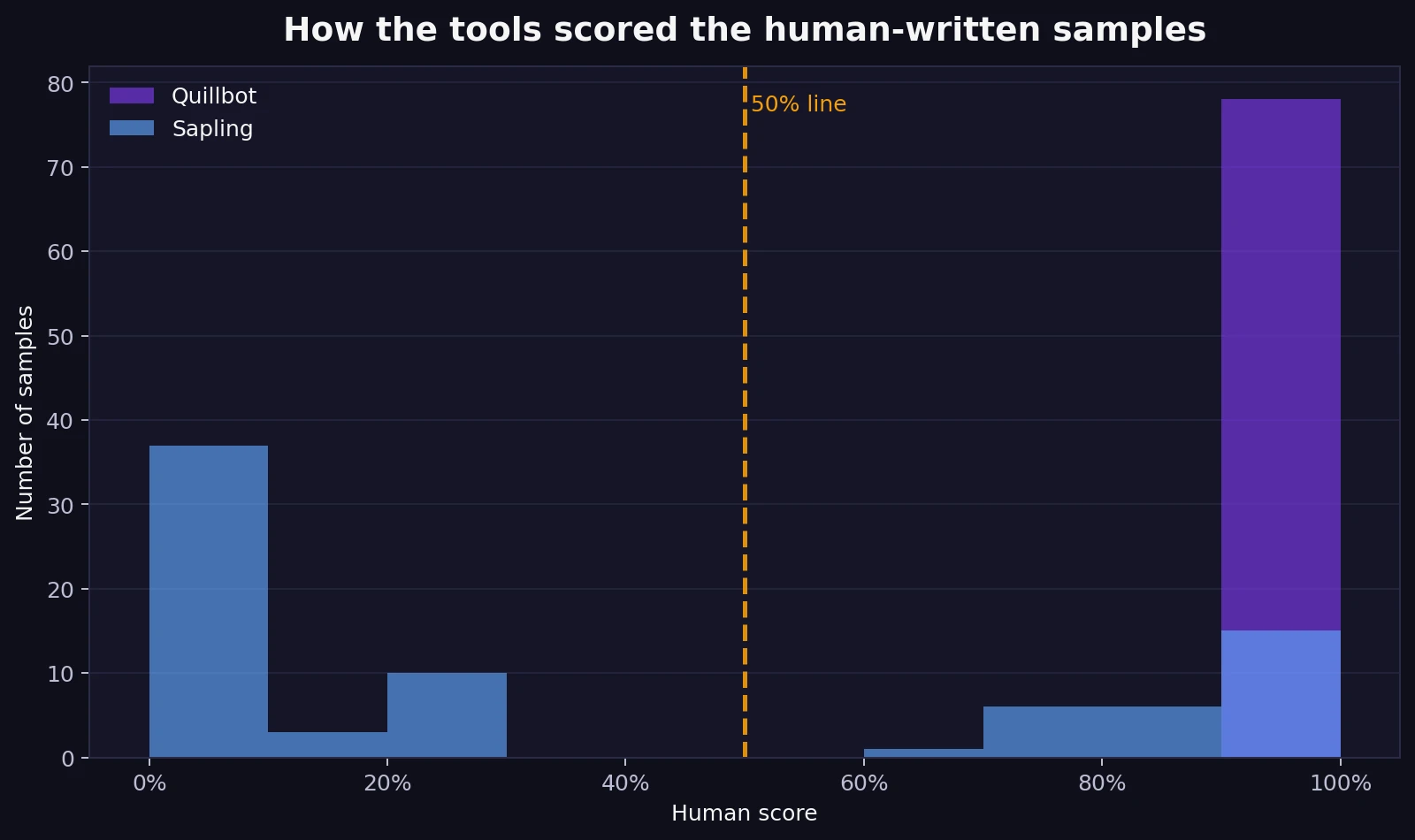
Using a basic 50% human-score line, Quillbot correctly kept 100.0% of the human samples on the human side. Sapling only kept 35.9% of them there. That means about 64.1% of the human texts in this dataset fell below the 50% line in Sapling. Even more striking, 24 of the 78 human samples received a 0% human score from Sapling.
That is the fairness problem in one sentence: Sapling is stronger at catching AI, but it is much more likely to make honest writing look suspicious. For a student audience, that should not be treated as a small side issue. It is the difference between a tool being “strict” and a tool being risky to rely on without human review.
Also Read: ZeroGPT vs Quillbot AI Detector
The score distributions tell an even stronger story
Averages are useful, but they can hide how scattered the individual results are. That is why the next two charts matter. They show how the scores were spread out rather than only showing one average number.
On the human-written samples, Quillbot is simple: everything sits at the far right near 100%. Sapling is much more spread out. Many of its human scores cluster low, which means the detector repeatedly treated normal human writing as if it were suspicious. You do not need advanced statistics to read this chart. Just look at where the bars pile up.
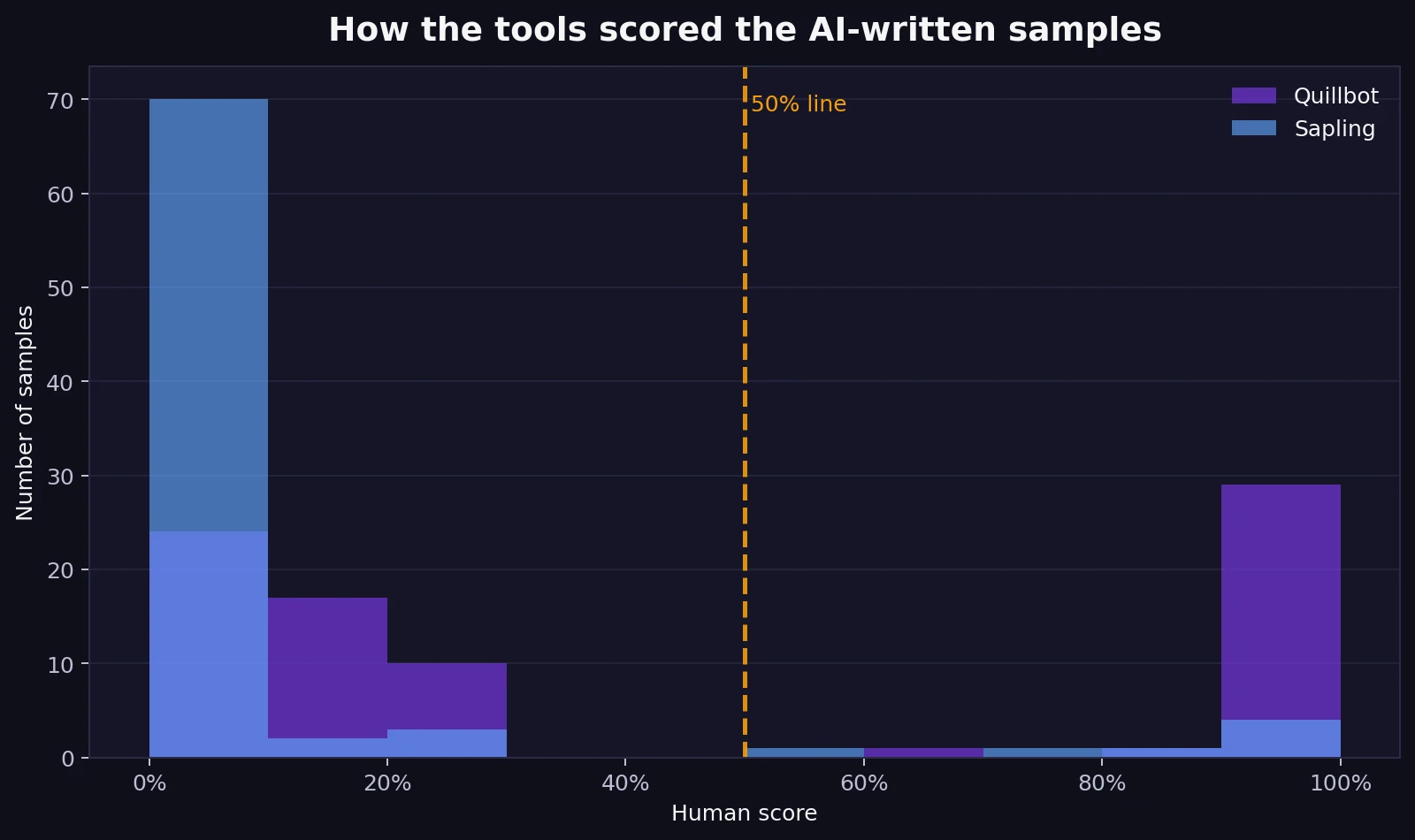
The AI-written set flips the story. Sapling’s bars stack close to zero, which means it usually recognized AI text as AI. Quillbot is more mixed. Some AI samples do score low, but a large chunk are scored surprisingly high. In fact, 35.4% of the AI samples received a human score of at least 90% from Quillbot, and 27 AI samples were scored as 100% human. That is a major weakness if your main goal is catching AI reliably.
Simple takeaway: Quillbot is more forgiving, which lowers the risk of wrongly accusing human writers. Sapling is more suspicious by default, which helps it catch AI but creates more false alarms on real student writing.
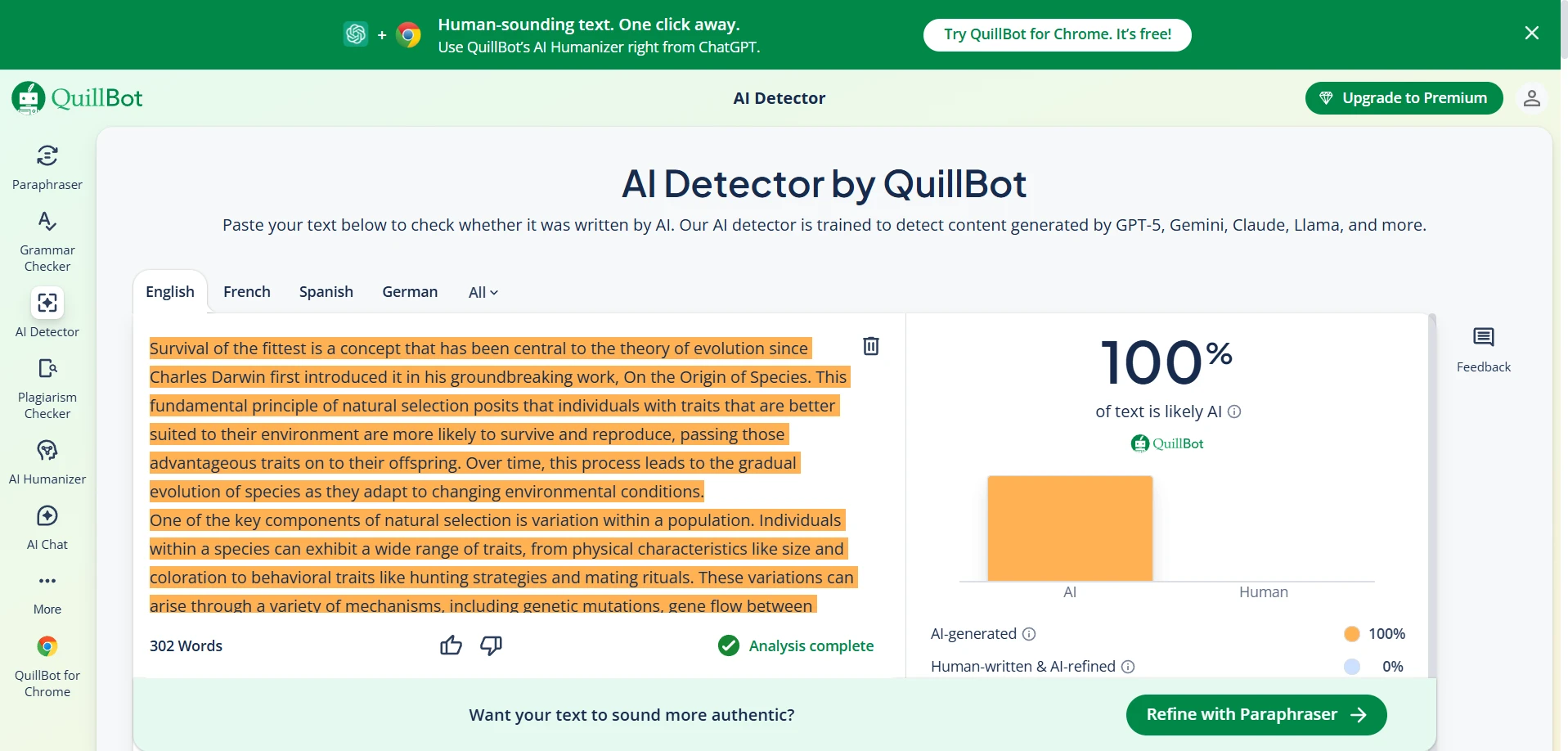
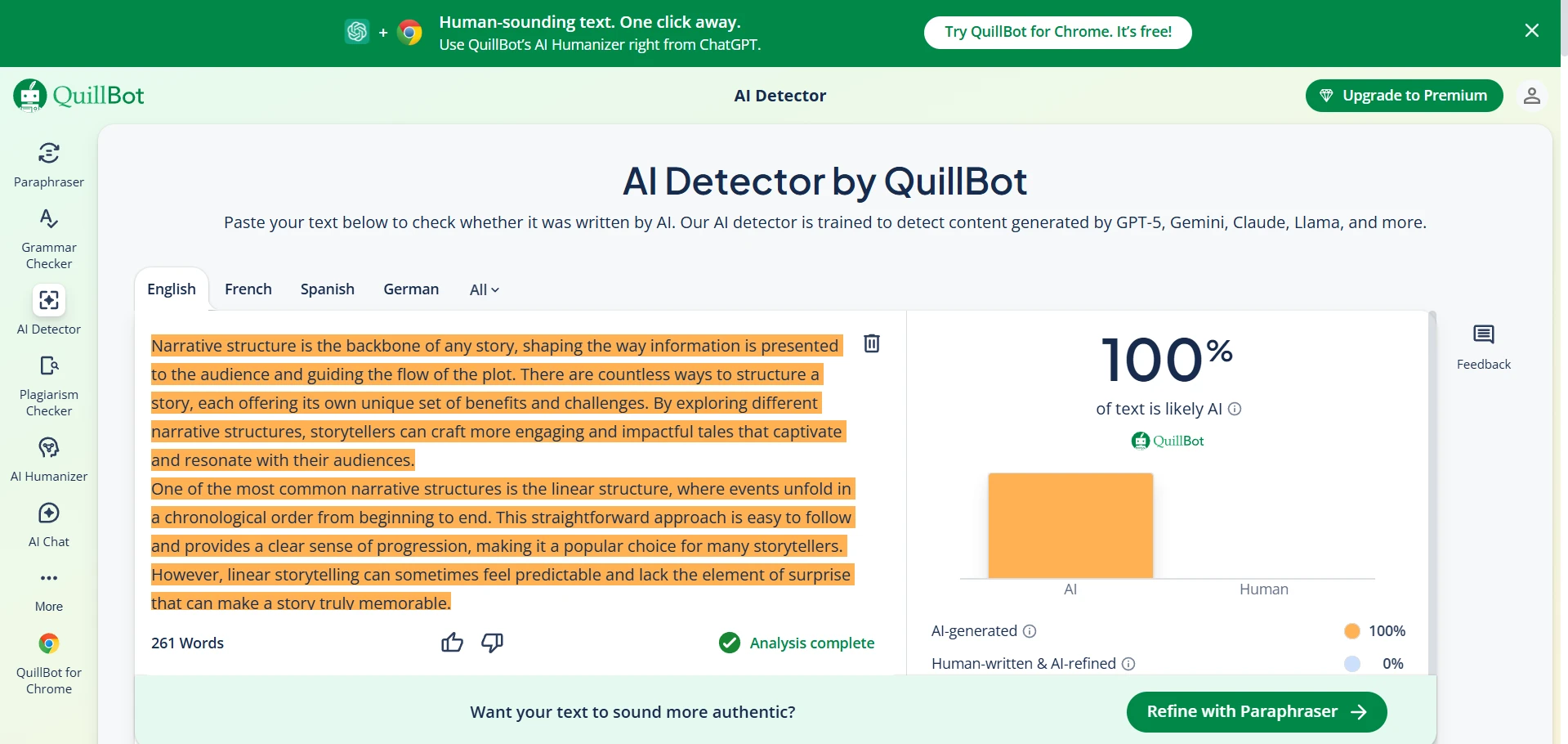
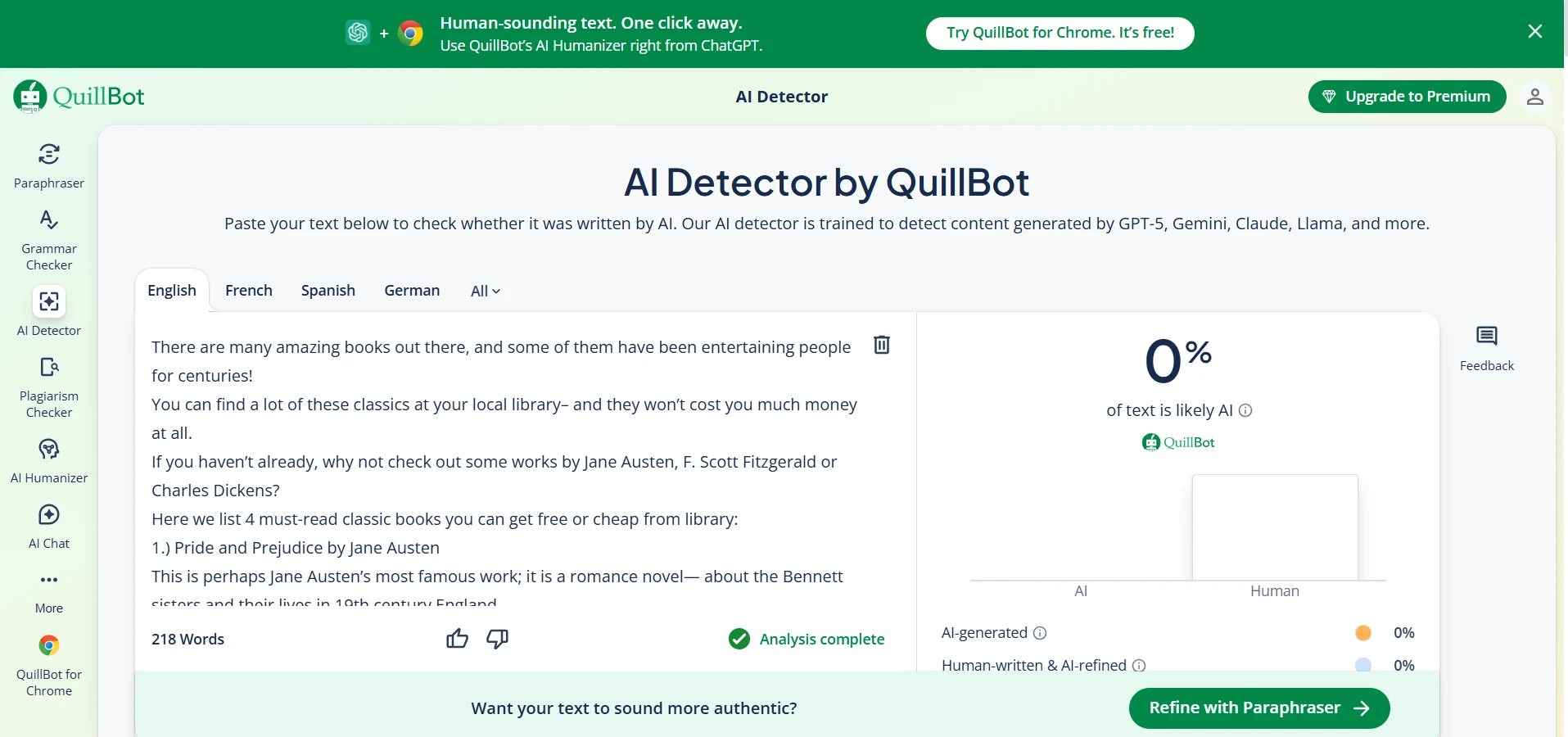
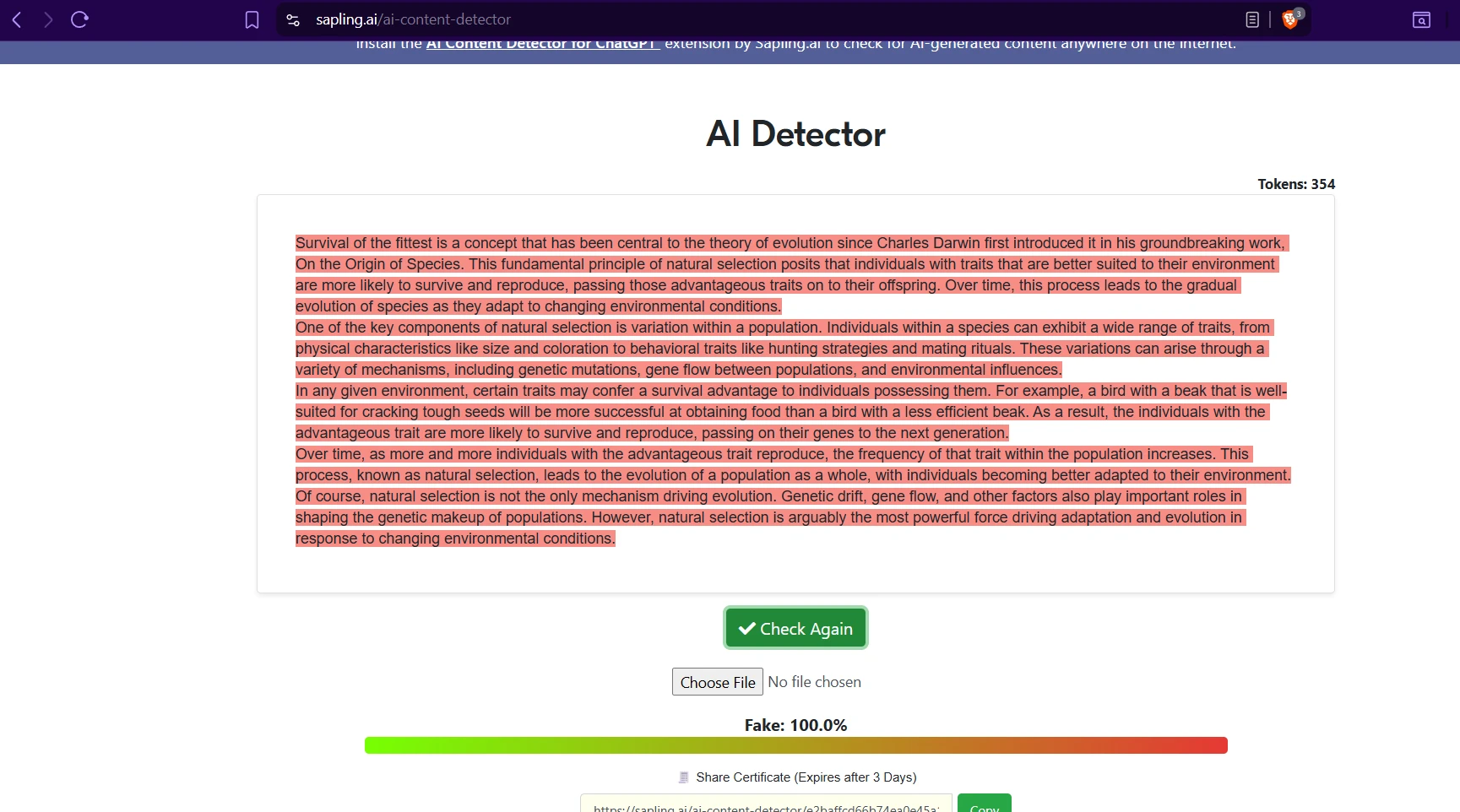
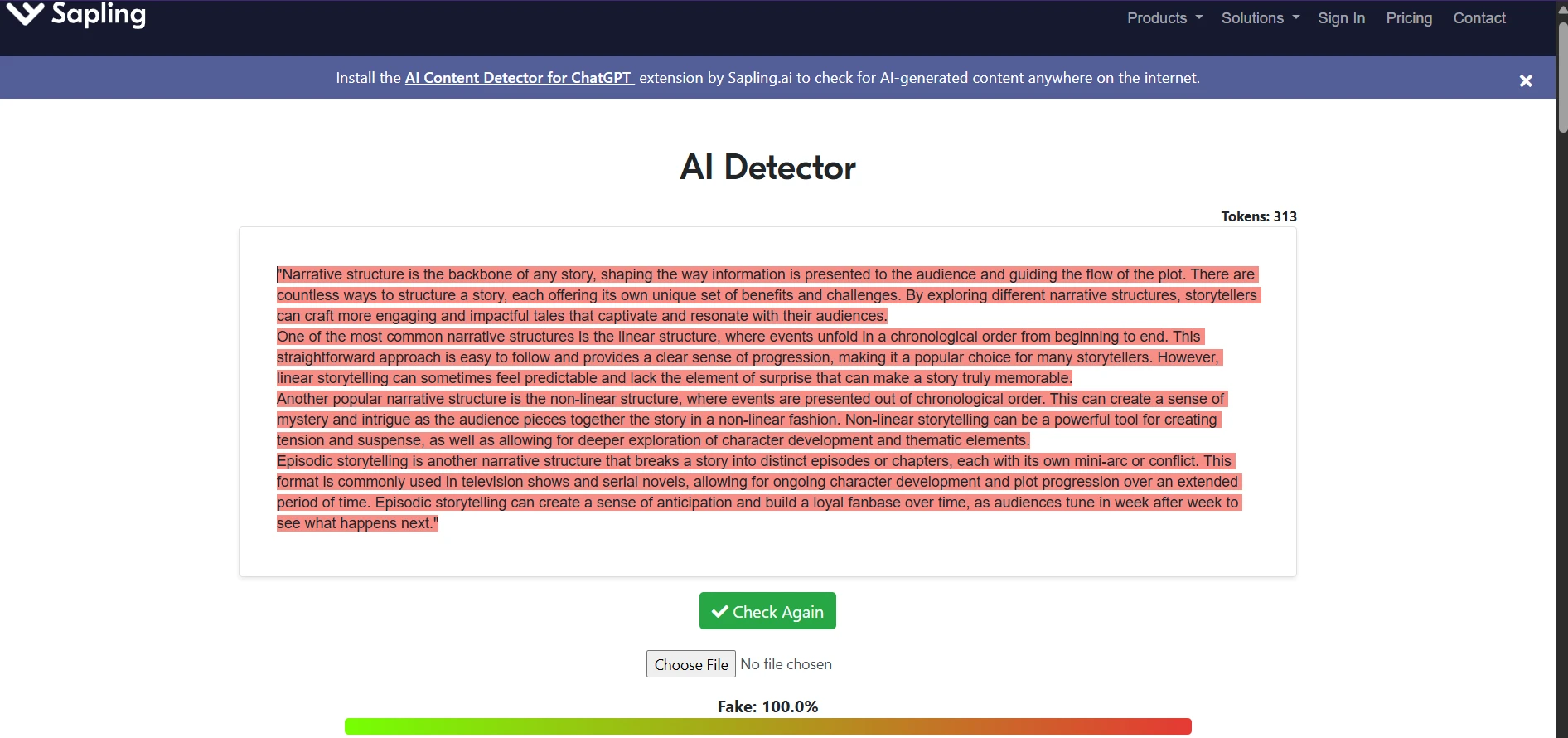
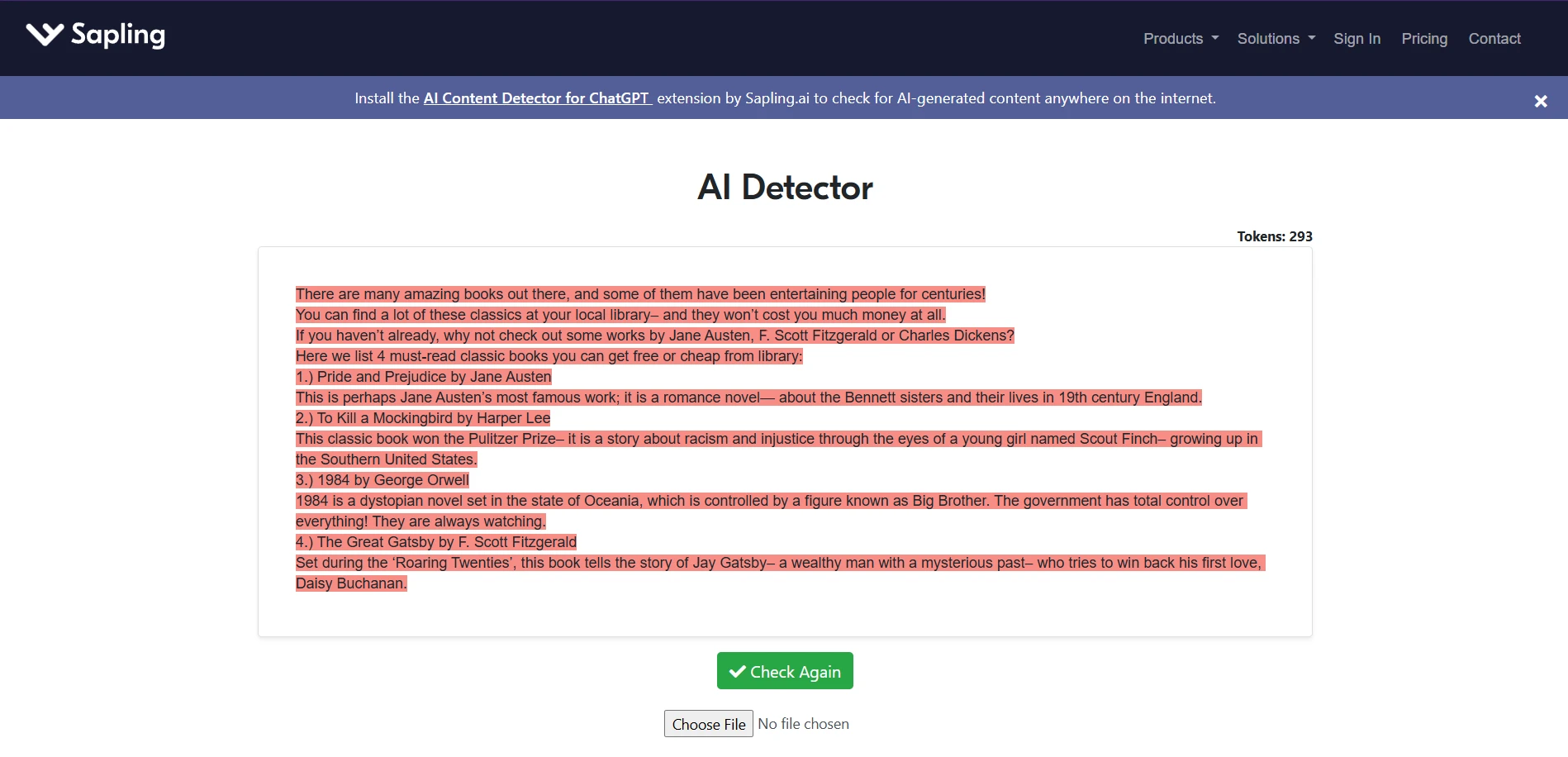
What the tool screens suggest in practice
The screenshots below line up with the pattern in the data. Quillbot’s interface often looks confident and clean, but that confidence does not always mean strong discrimination between human and AI. Sapling, on the other hand, often pushes hard toward an AI judgment. That may look decisive, but decisiveness is not the same thing as fairness.
This is why students, teachers, and editors should treat detector output as a clue, not a verdict. A single score cannot see your drafts, your research process, your revision history, or the context of your assignment.
Final takeaway
If your top priority is not wrongly flagging human writing, Quillbot came out ahead in this dataset. It was far more generous to the human-written samples and did not push genuine writing below the 50% line.
If your top priority is catching AI aggressively, Sapling performed better. It kept most AI samples near zero and correctly treated 91.5% of them as AI at the 50% cutoff. But that strength came with a serious cost: it also treated many human-written samples as suspicious.
For students, that leads to the most important conclusion of all: an AI detector should never be the final judge of authorship on its own. Based on these 160 samples, Quillbot looks safer from a false-accusation point of view, while Sapling looks tougher from an enforcement point of view. Neither one deserves blind trust. If a detector is used in an academic setting, it should be paired with common-sense review, draft evidence, and actual human judgment.