

The hardest part of AI detection is not catching machine-written text. It is avoiding damage when a real student gets treated like a cheater. This analysis compares GPTZero.me and Sapling.ai using the same dataset and asks a more useful question: which tool is less likely to misjudge honest writing?
I converted both tools into the same scale: a human score. So a higher score means the detector thinks a person wrote the text. That makes the comparison easier to read and much easier to explain.
What makes this comparison useful
This is not a screenshot war and it is not based on a handful of dramatic examples. Every one of the 160 samples was run through both tools. I looked at average scores, how spread out those scores were, and how often each detector would make the classroom mistake students fear most: accusing a human writer of using AI.
To make the results practical, I used a simple 50% cutoff. In plain terms, anything below 50% human is treated as suspicious. That is not the only way to use detector scores, but it reflects how many people actually interpret them in the real world: they turn a probability into a yes-or-no judgment.
False positive means a human text gets treated like AI. This is the most serious classroom mistake because it creates suspicion around honest work.
A detector should not jump wildly on genuine writing. If scores swing too much, two honest students can be judged very differently for style alone.
Also Read: Grammarly vs Sapling AI Detector
The headline numbers
- On human writing: GPTZero.me averaged 99.8% human, while Sapling.ai averaged 36.4% human.
- On AI writing: Sapling.ai averaged 9.1% human, while GPTZero.me averaged 25.4% human.
- At a 50% cutoff: Sapling.ai wrongly flagged 64.1% of human samples as AI. GPTZero.me flagged 0% of the human samples.
- The trade-off: GPTZero.me let 23.2% of AI samples look human, compared with 8.5% for Sapling.ai.
- Overall balance: GPTZero.me reached about 88.4% balanced accuracy, compared with 63.7% for Sapling.ai.
Also Read: Originality AI vs Grammarly AI Detector
The first chart tells the story fast
If you only had ten seconds to understand this dataset, this is the chart I would show. GPTZero.me gave genuine human writing almost the maximum possible score. Sapling.ai did not. That gap is so large that it changes the meaning of the whole comparison.

Sapling.ai does have one clear strength: it pushes AI-generated text much lower. That makes it look tougher. But toughness is not the same thing as fairness. In education, a detector should not earn praise for being aggressive if it reaches that result by pulling large amounts of genuine human writing into the danger zone.
Student-first takeaway: a detector that catches more AI but also wrongly punishes real writers can still be the worse tool for school use.
The false-positive problem is not small here
A false positive happens when a human sample gets marked as AI. That is the result students should care about most, because it can start a difficult conversation even when the writing is original. In this dataset, Sapling.ai made that mistake on 50 out of 78 human samples. GPTZero.me made it on 0 out of 78.

This is where the comparison becomes less about abstract accuracy and more about consequences. If a tool is being used to review student work, the cost of a false positive is not just a number in a chart. It can become stress, extra scrutiny, and a weaker starting point for the student before anyone has looked at drafts, notes, or revision history.
Also Read: Originality AI vs Sapling AI
Consistency matters almost as much as accuracy
A good detector should be stable on real human writing. GPTZero.me looks much steadier in that sense. Its human scores cluster close to the top, which means the detector treated most human samples as clearly human. Sapling.ai is much more scattered. Some human texts still scored well, but many dropped much lower than you would want for a student-facing tool.

That spread matters because students do not all write in the same way. A detector that reacts badly to clean, organized, or highly structured prose can end up penalizing style instead of detecting authorship. That is a fairness problem, not just a technical quirk.
Where Sapling.ai does better
To be fair, Sapling.ai is stronger at pushing AI-written text below the 50% line. In this dataset, it only treated 7 out of 82 AI samples as human. GPTZero.me treated 19 out of 82 AI samples as human. So if your only goal is to catch as much AI text as possible, Sapling.ai looks more forceful.

But this is exactly where context matters. In a classroom, a detector should not be judged only by how suspicious it can be. It should also be judged by how responsibly it handles honest work. That is why GPTZero.me comes out ahead overall in this dataset even though Sapling.ai is stricter on AI samples.
What the screenshots add to the data
Charts show the pattern across the full dataset. The screenshots make the tools feel real. They show the actual interfaces, the language each detector uses, and the kind of visual confidence a teacher or student would see on screen during a scan.
The GPTZero screenshots show a polished interface with percentage-based confidence labels. In several examples, it gives strong AI judgments, but the full dataset shows it is still much more cautious around genuine human work.
The Sapling screenshots show a much harsher visual style, often washing entire passages in warning colors. That design feels decisive, but the dataset shows that this same harshness often spills onto human-written work.
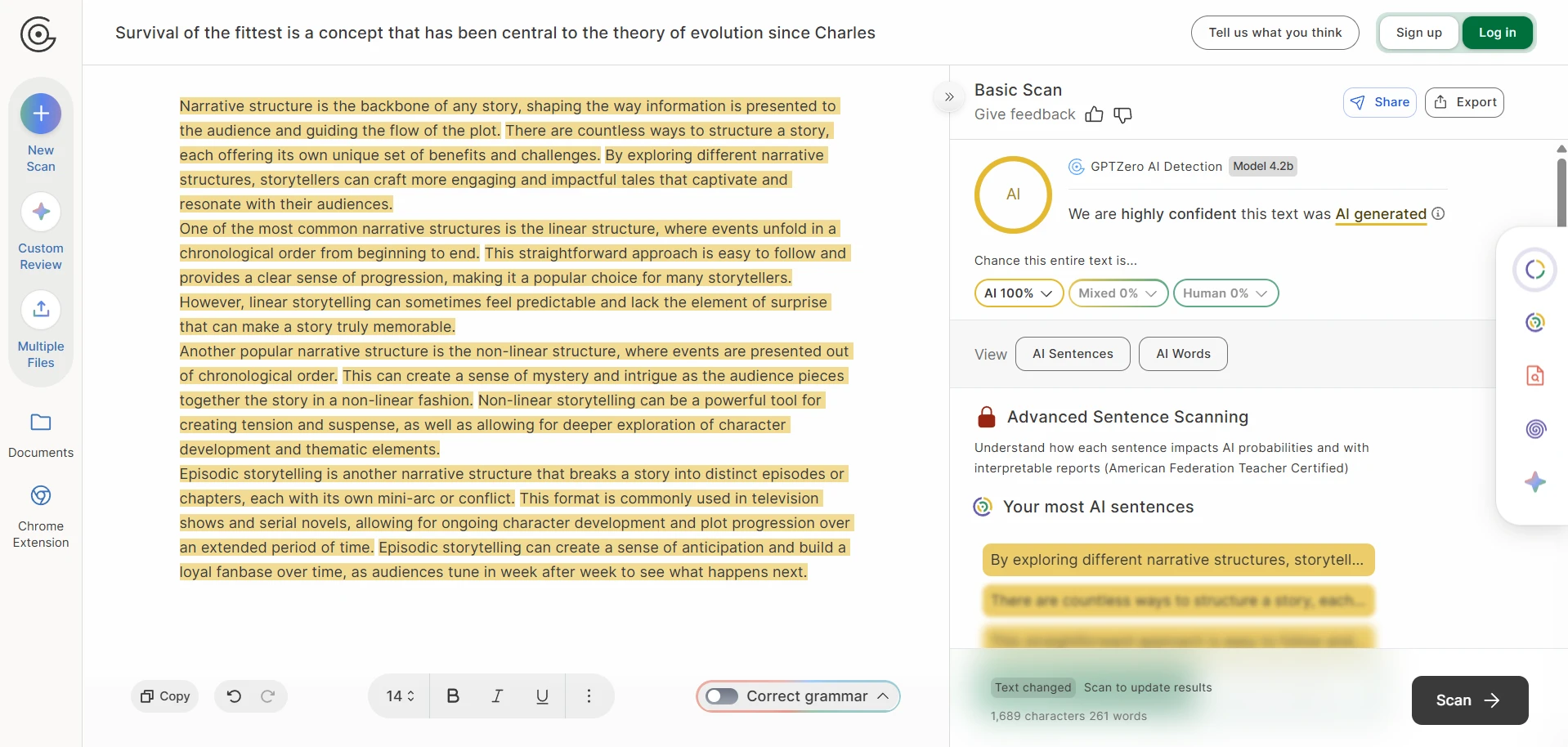
GPTZero.me examples from the test set
These screenshots give a quick visual feel for how GPTZero presents its verdicts. They work well as supporting evidence, but the bigger point still comes from the full 160-sample comparison rather than any one isolated scan.




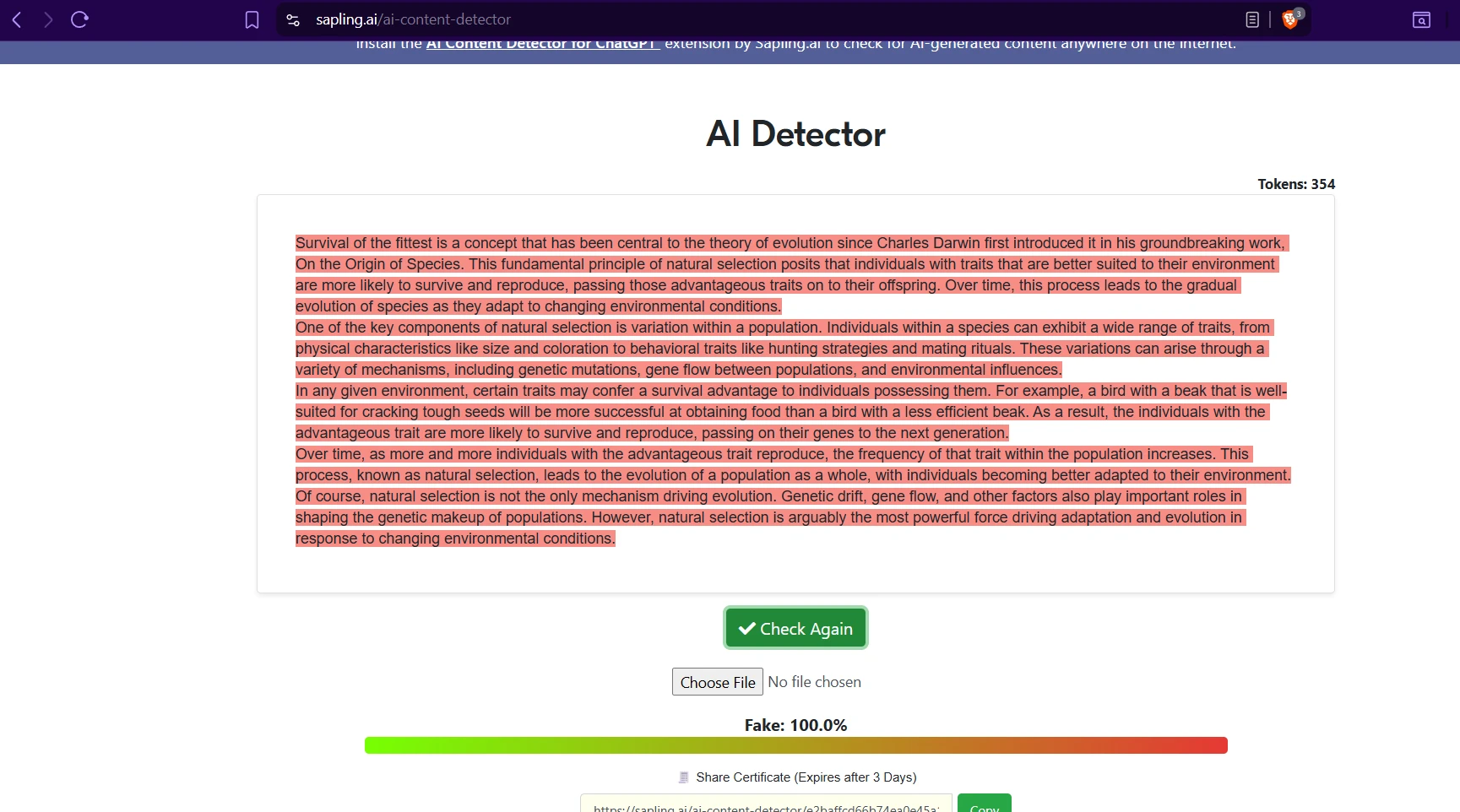
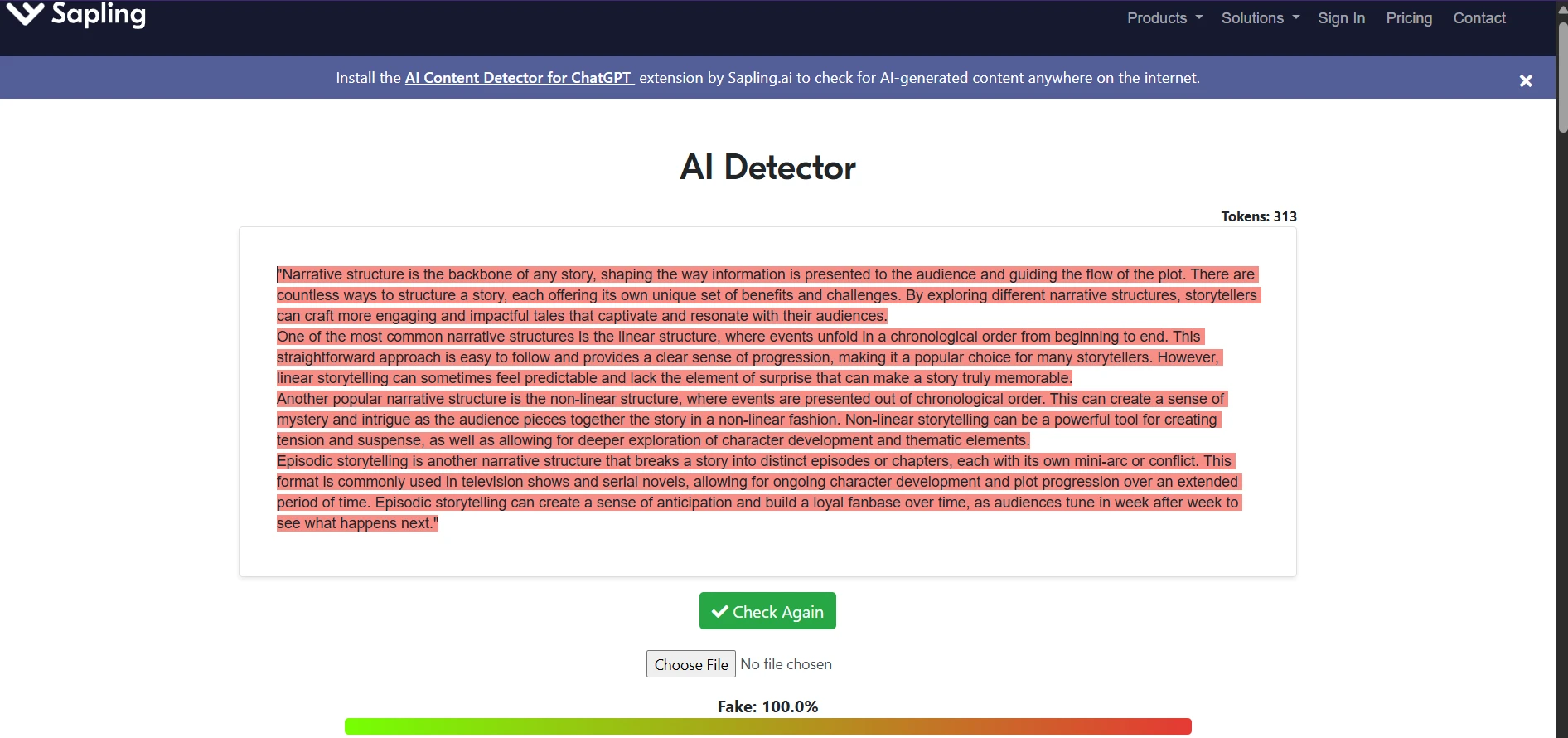
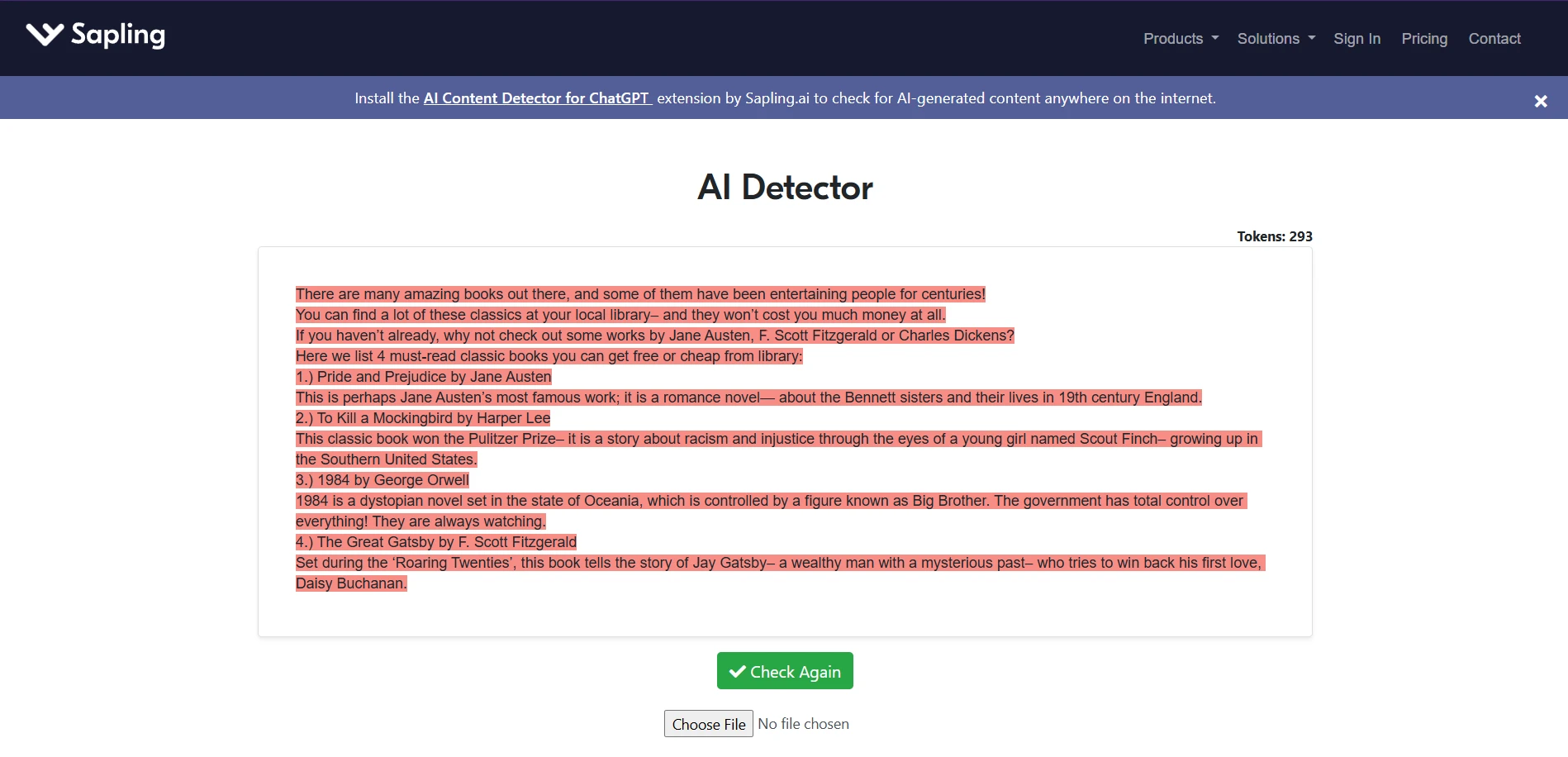
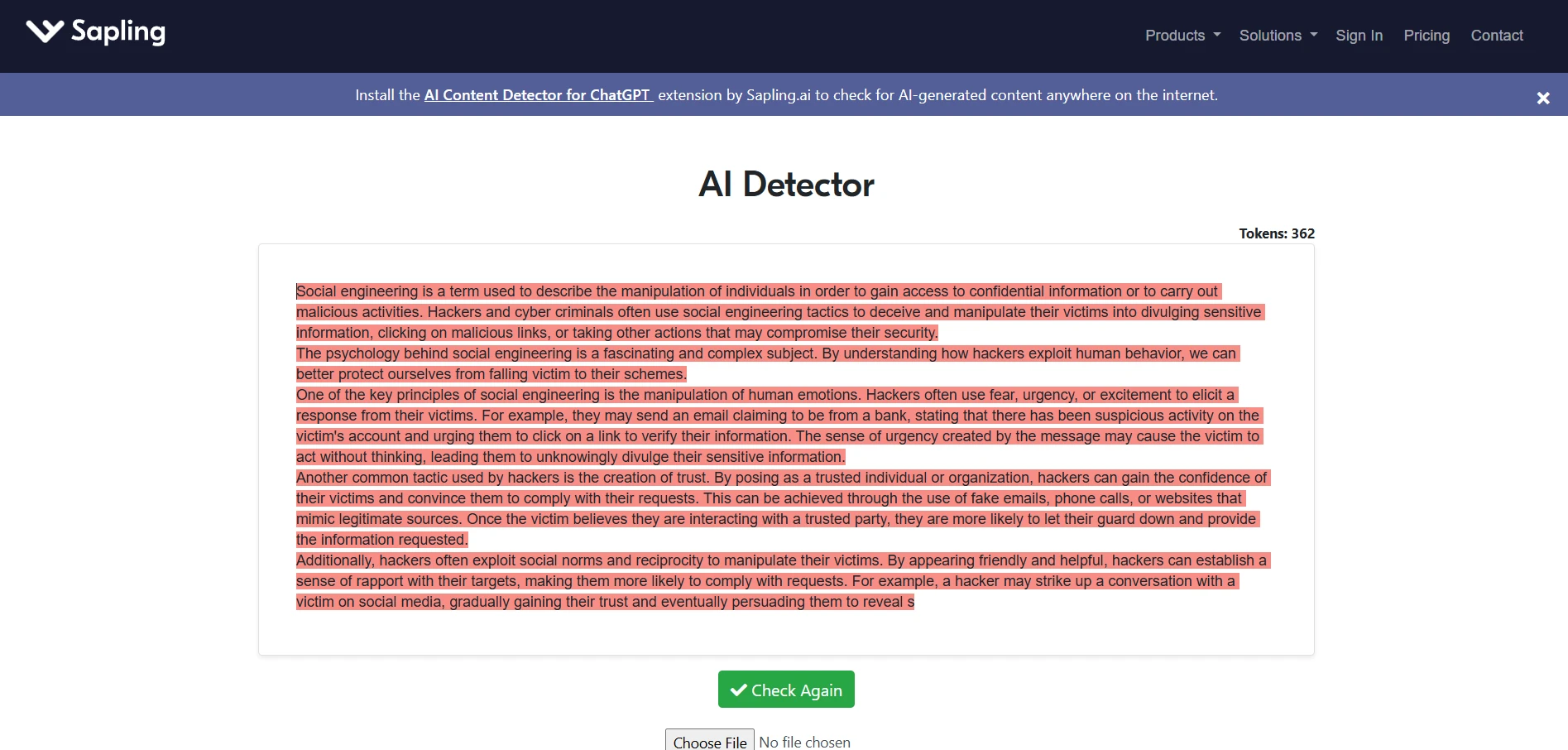
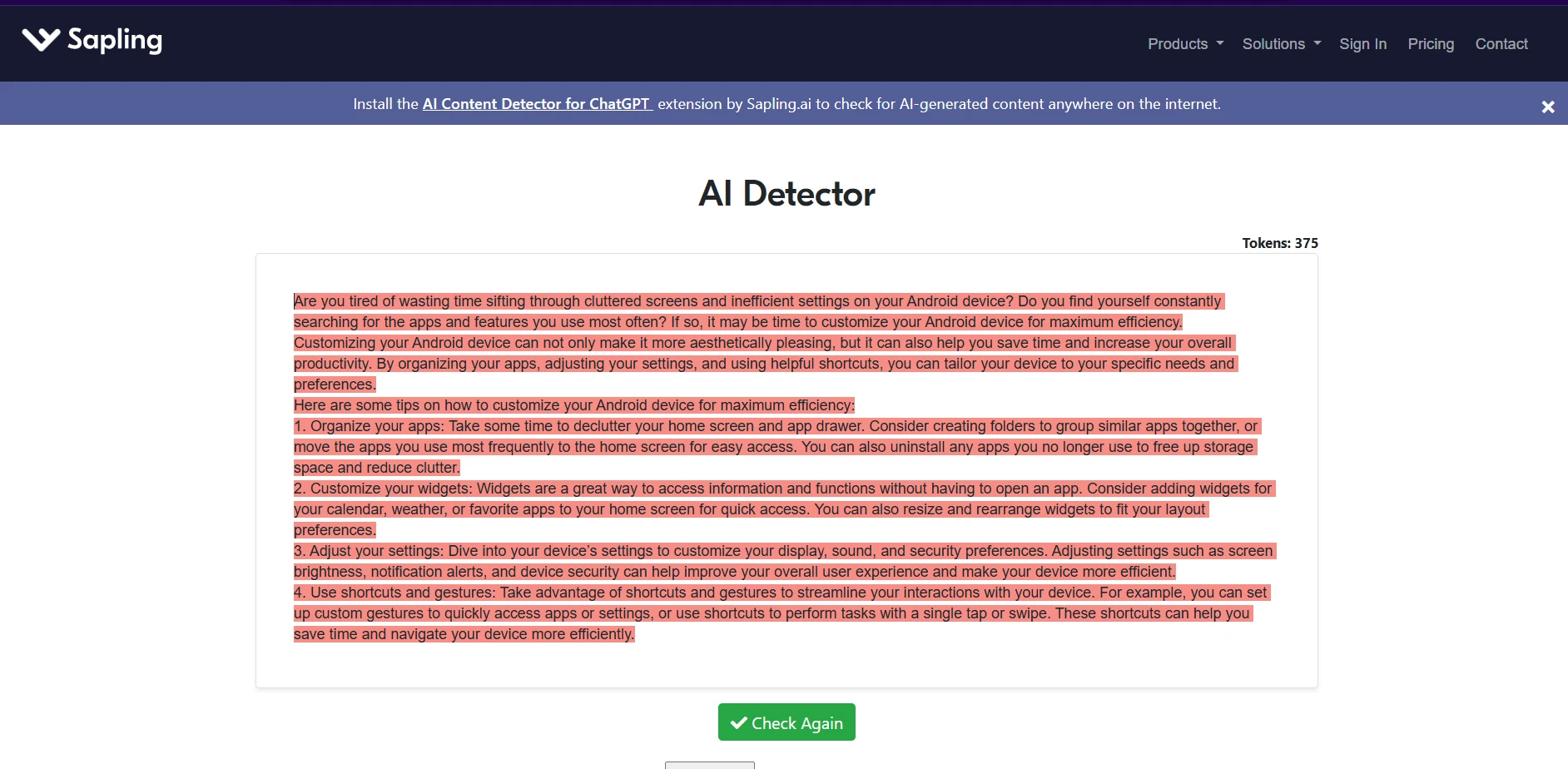
Sapling.ai examples from the test set
The Sapling screenshots are visually striking because the detector tends to color whole passages as suspicious. That makes its outputs feel very certain. The issue is that the wider dataset shows this certainty does not stay limited to AI text.
Final verdict
For students, the most important question is not which detector is harsher. It is which detector is less likely to be unfair. Based on these 160 tests, GPTZero.me is the safer choice between the two. It handled human-written text far more reliably and avoided the false-positive problem that weakened Sapling.ai throughout the dataset.
Sapling.ai is better at pushing AI-generated writing toward low human scores, so it will appeal to people who want a stricter filter. But the trade-off is severe. When a detector mislabels a large share of human writing as suspicious, that stops being a small technical weakness and starts becoming a trust problem.
The bigger lesson is broader than this one comparison. AI detectors should never be treated as final proof of cheating. They can be a starting point for review, but they should sit beside drafts, revision history, writing samples, and human judgment—not above them.