![[STUDY] Sapling AI vs Winston AI Detector: Which One Is Fairer to Student Writing?](/static/images/sapling-vs-winston-featured-imagepng.webp)

I tested both tools on 160 samples and converted their outputs into human scores, where a higher score means the detector believes the text was written by a person. The results show a sharp trade-off between catching AI and avoiding unfair flags on real writers.
As AI detectors move from novelty tools to gatekeepers in classrooms and admissions workflows, one question matters more than the sales page: what happens when the detector is wrong? For students, that is not a small problem. A weak detector does not just miss AI-written work. It can also cast doubt on genuine writing, and that can damage trust very quickly.
The test was simple, but the implications are not
To compare Sapling AI and Winston AI in a way that feels practical rather than theoretical, I ran both tools on 160 text samples. The dataset included 78 human-written pieces and 82 AI-generated pieces. Both detectors originally returned AI-style scores, but I converted them into human scores so the comparison is easier to read: a higher score means the tool thinks the text is more likely to be written by a person.
The headline result is easy to understand. Winston AI was much better at recognizing real human writing, while Sapling AI was far more aggressive at calling text AI. That aggressiveness helped Sapling catch more AI samples, but it also created a major downside: many real human texts were dragged into the “probably AI” zone.
Also Read: Quillbot vs Winston AI Detector
What stood out most in the dataset
- Average score on human-written text: Winston AI gave human writing an average human score of 92.4%, while Sapling AI averaged just 36.4%.
- Average score on AI-written text: Sapling AI was stricter, giving AI samples an average human score of 9.1%. Winston AI averaged 34.1%.
- At a 50% cutoff: Winston kept 93.6% of real human texts on the safe side of the line. Sapling kept only 35.9%.
- Overall accuracy: Winston finished at 79.4% overall accuracy, compared with 64.4% for Sapling.
Why “50% cutoff”? It is just a simple decision line. Scores above 50% count as “likely human,” and scores below 50% count as “likely AI.” It is not perfect, but it gives both tools the same rule.
Also Read: Winston AI vs Turnitin: Real Tests & Surprising Results
The first chart reveals the central problem
The chart below compares the average human score each detector gave to human-written and AI-written text. This matters because a useful detector should do two things at once: give high human scores to real people, and low human scores to AI text.
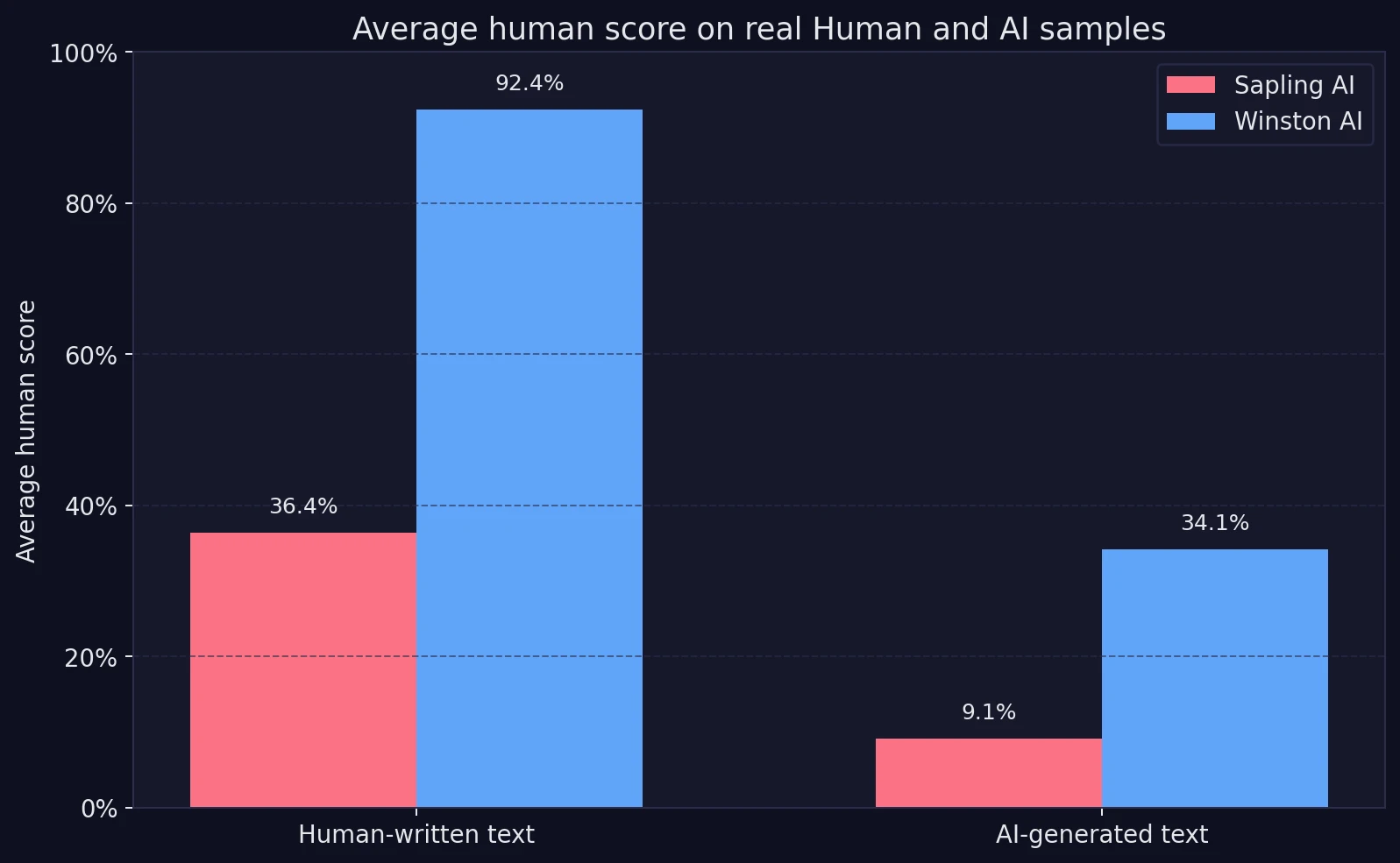
Winston separates the two groups much more clearly. On real human text, it stays high at 92.4%. Sapling, by contrast, gives human writing an average of just 36.4%. That is the number students should notice first. It means Sapling often treats genuine writing as suspicious even before any deeper review happens.
At the same time, Sapling’s low 9.1% average on AI text shows why some users may still like it. It is not shy. It is willing to call AI text AI. The issue is that this strictness does not come for free.
Once you add a decision line, the trade-off becomes impossible to ignore
Averages are helpful, but classroom decisions are usually made with some kind of cutoff. So I also looked at what happens when 50% is treated as the dividing line between “likely human” and “likely AI.”
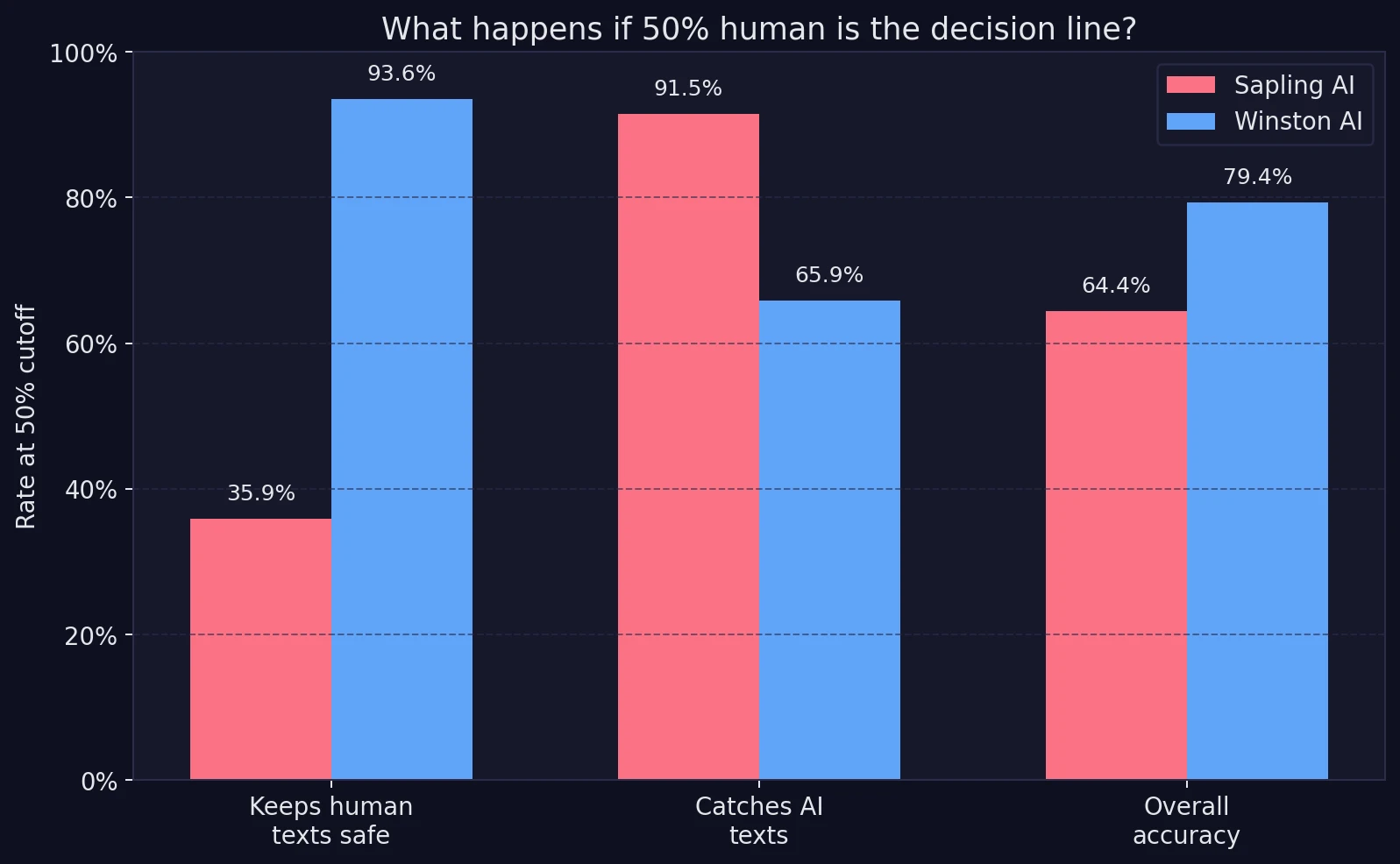
This chart makes the trade-off plain. Sapling catches more AI text, scoring 91.5% on that measure. Winston catches 65.9%. But when the question becomes “How often does the detector avoid wrongly flagging real people?”, Winston dominates. It keeps 93.6% of human texts above the line. Sapling keeps only 35.9%.
That matters because the most painful mistake in education is usually the false positive. That phrase sounds technical, but the idea is simple: a false positive is when a detector says a real student probably used AI even though they did not. In this dataset, Sapling produced far more of those mistakes.
Also Read: [HOT TAKE] Is Winston AI or GPTZero more accurate?
It is not just about averages. The score spread tells its own story
The next graph shows the spread of the scores. “Spread” simply means how tightly grouped or widely scattered the scores are. A tighter cluster usually means a tool is behaving more consistently.
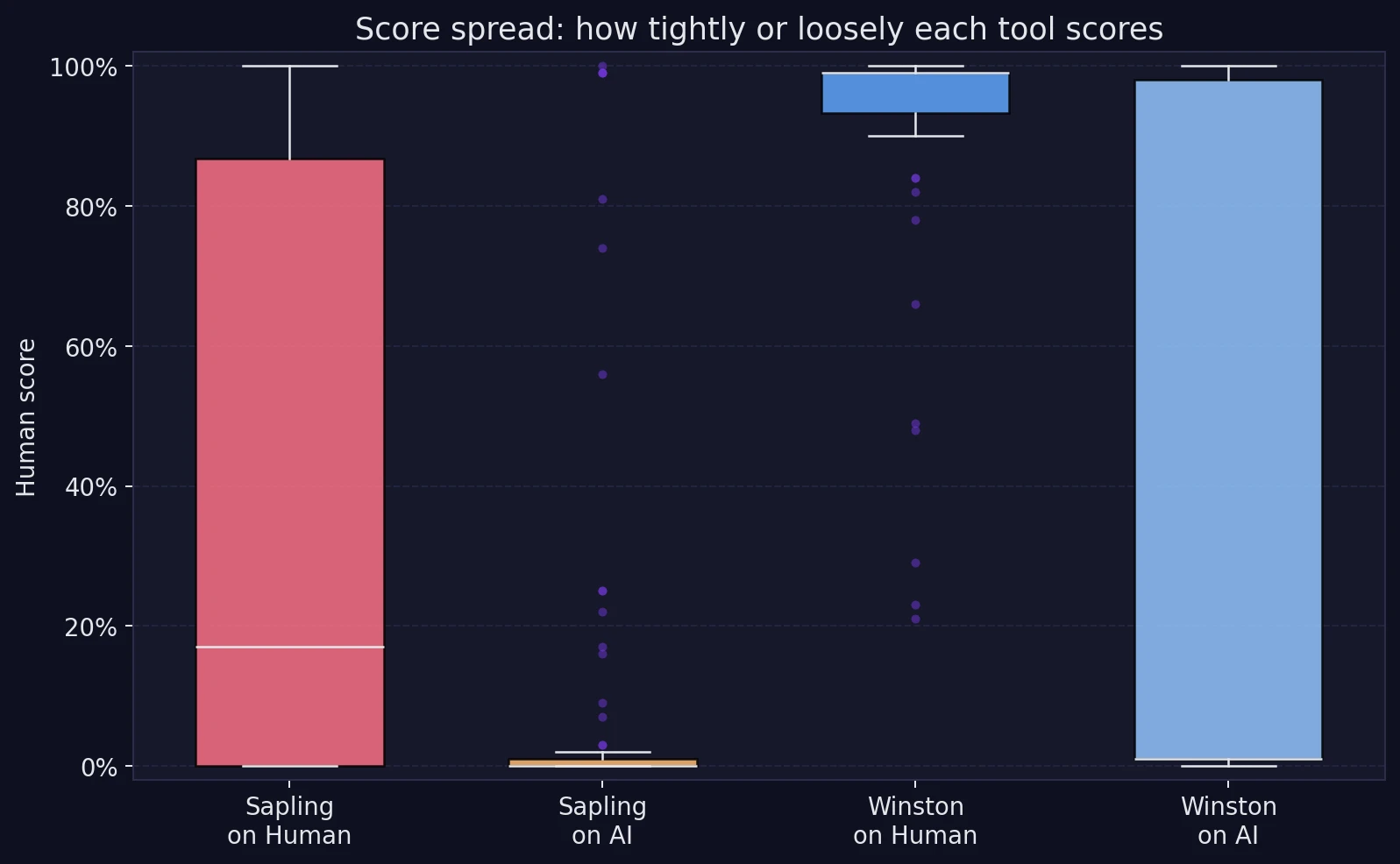
Winston’s scores on human-written text stay packed near the top of the chart, which is exactly what you want. Sapling’s human scores are much more scattered, and the middle of that group sits far lower. That suggests Sapling often struggles with polished, organized prose, the kind of writing students are actually encouraged to produce.
Winston is not flawless, though. Its scores on AI text are much more spread out. Some AI samples were judged correctly as very unlikely to be human, while others were scored surprisingly high. So Winston appears to be the safer detector for genuine writers, but it can also be easier to fool with clean, readable AI copy.
When the same sample gets opposite verdicts
The most interesting part of the dataset is not the average. It is the disagreement. The scatter plot below compares both detectors on the same sample at the same time. Each dot is one text. The horizontal and vertical dashed lines mark the 50% cutoff.
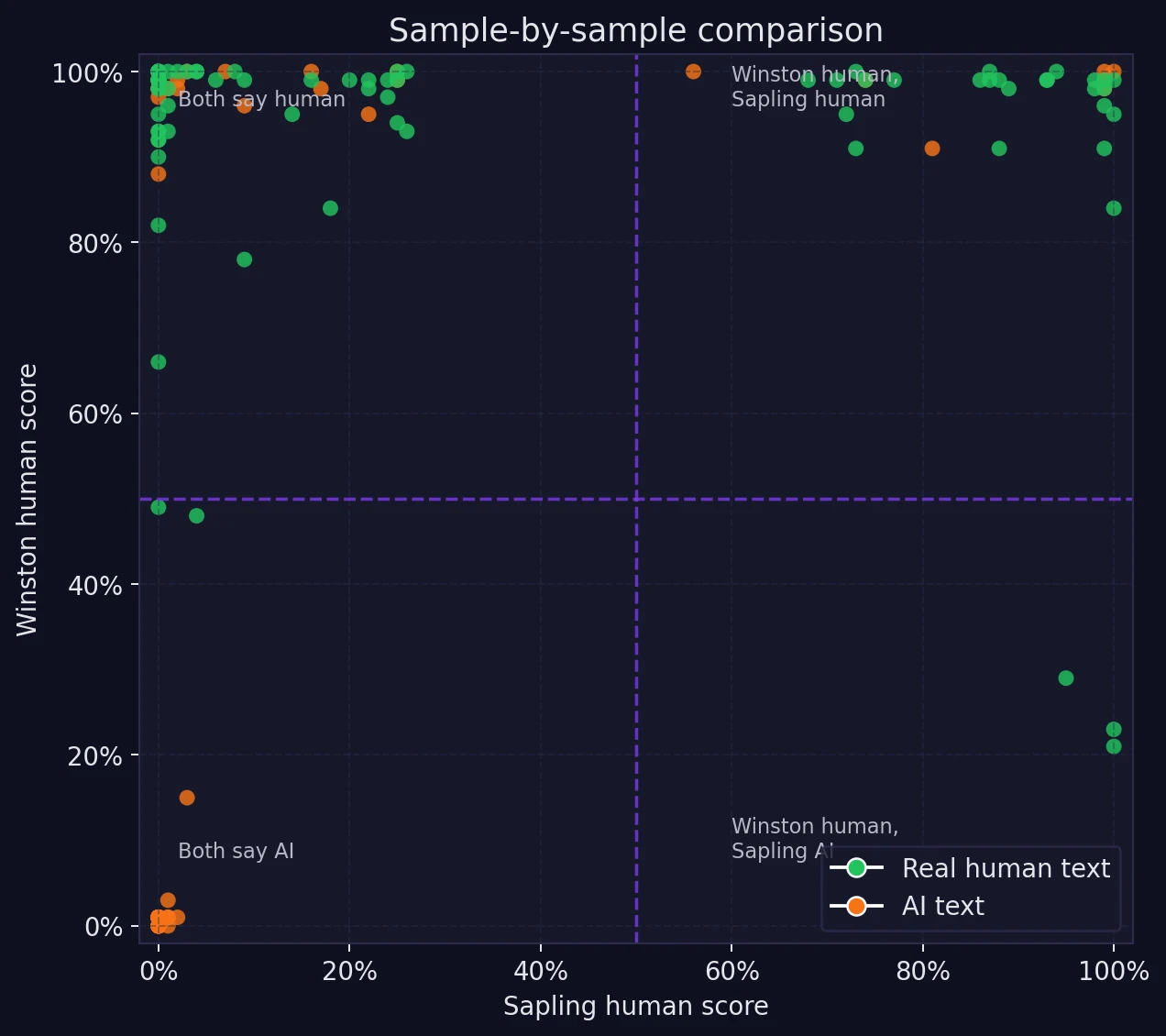
Notice how many samples fall in the top-left area. That is where Winston says “likely human” but Sapling says “likely AI.” There are far fewer samples in the opposite corner. In other words, the disagreement is not random. Sapling is systematically harsher on borderline or highly polished writing.
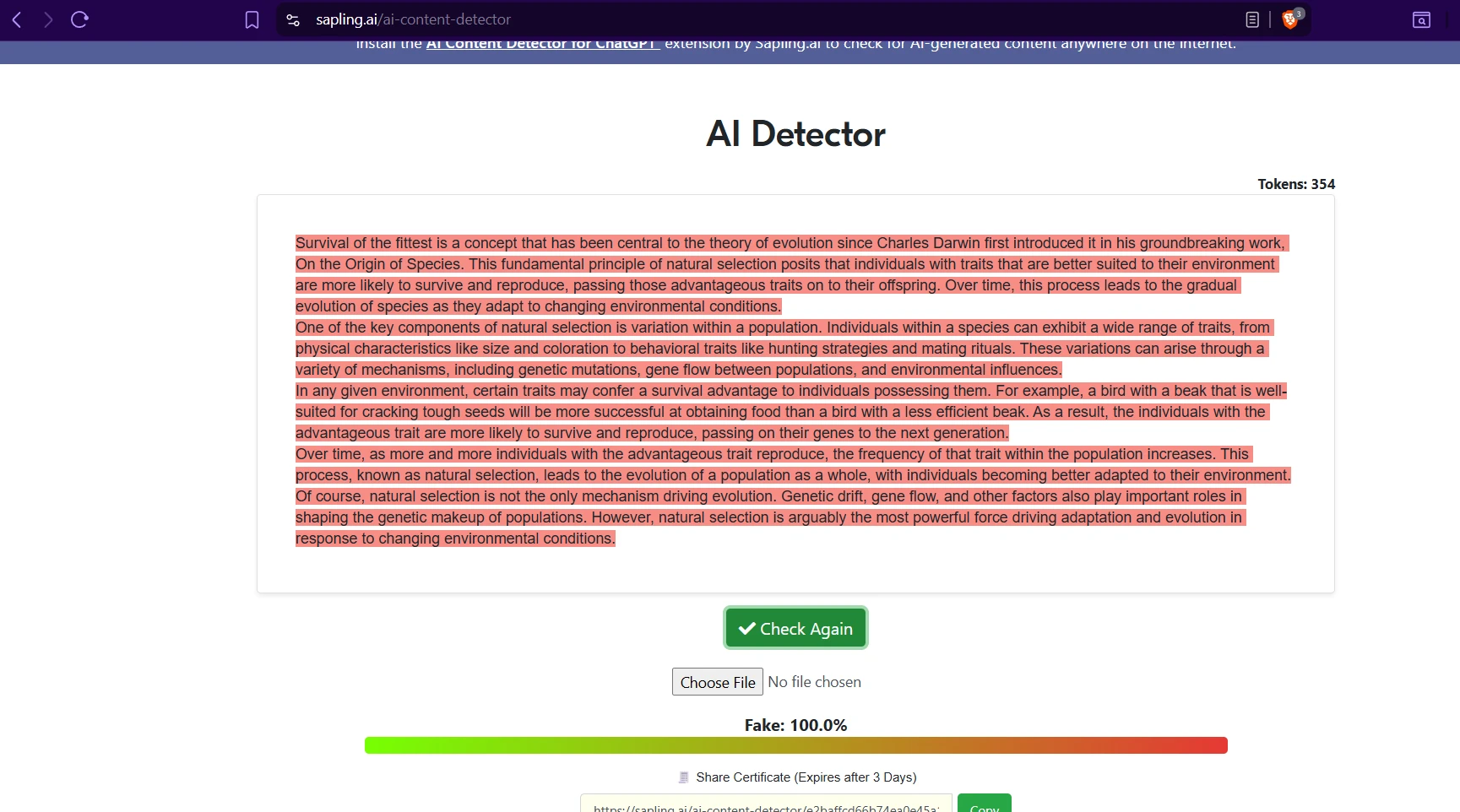
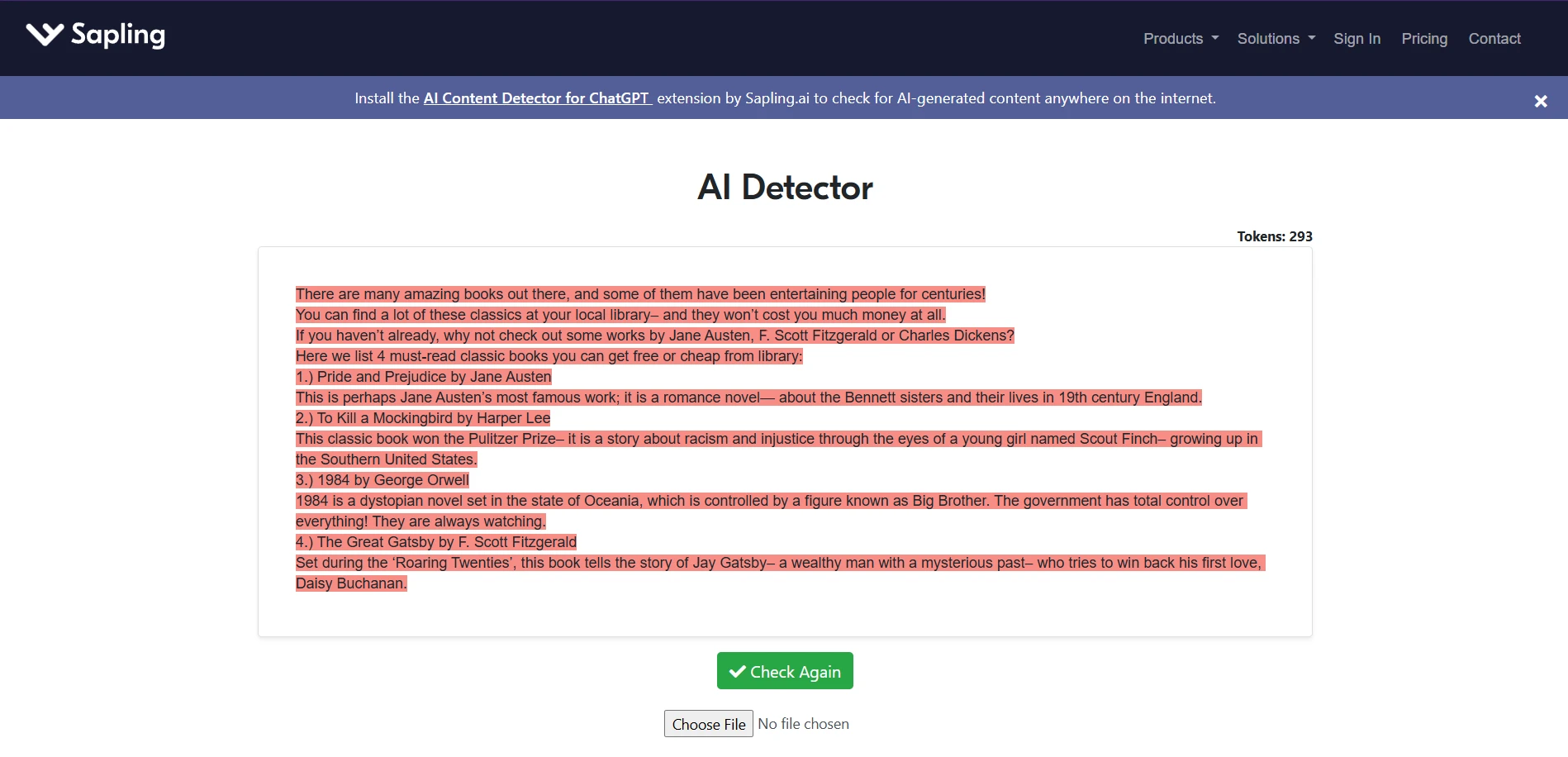
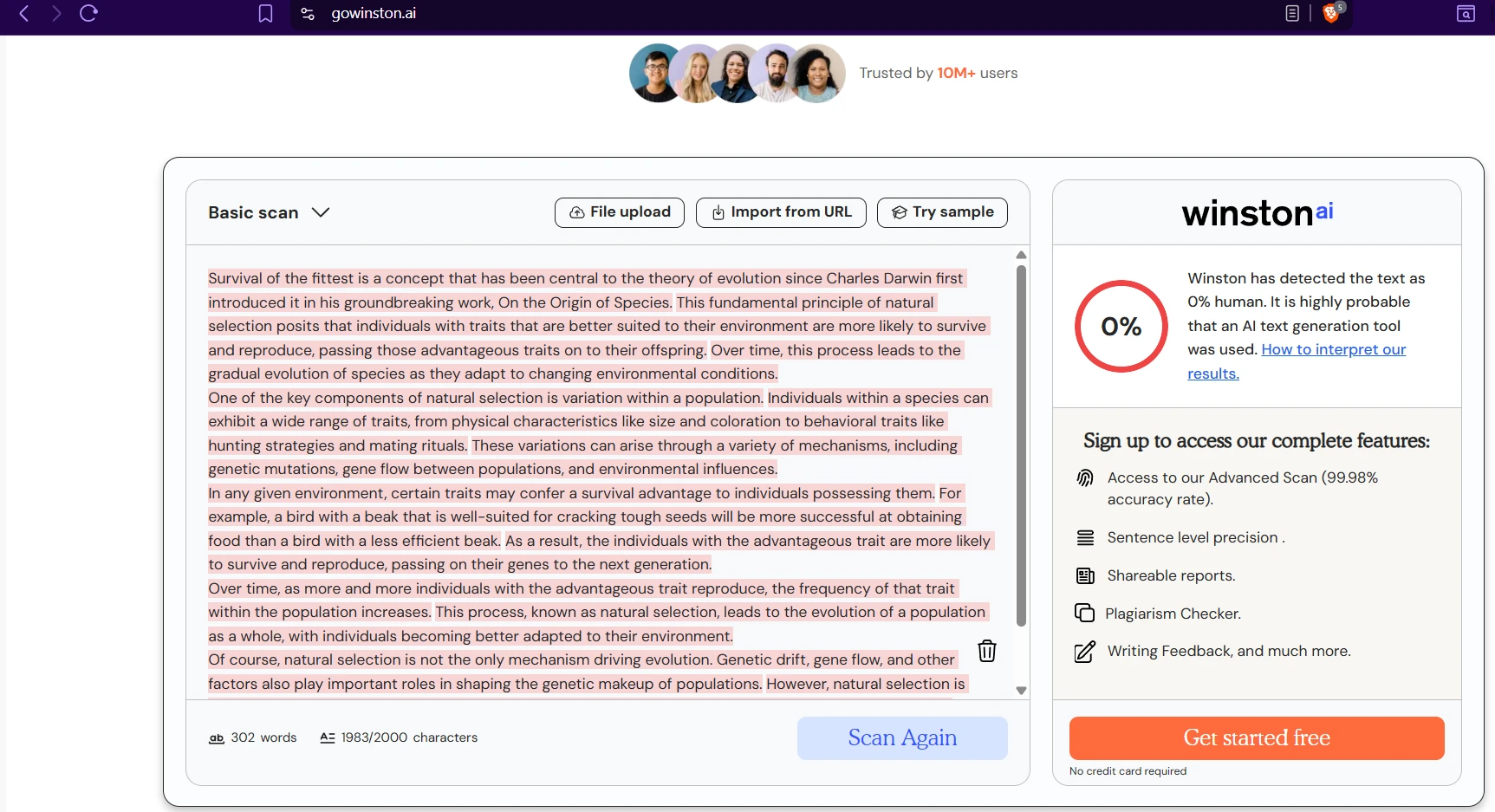
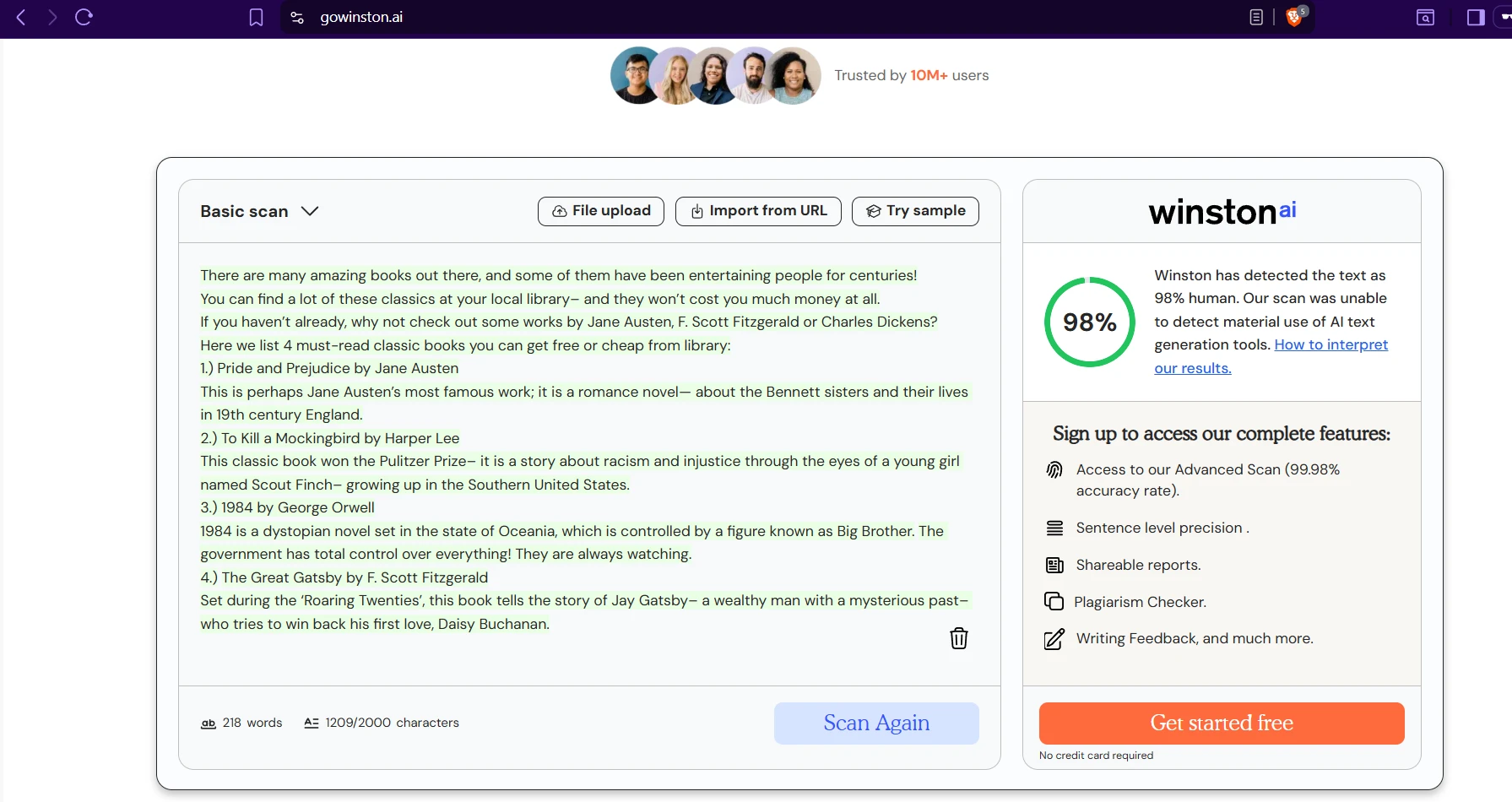
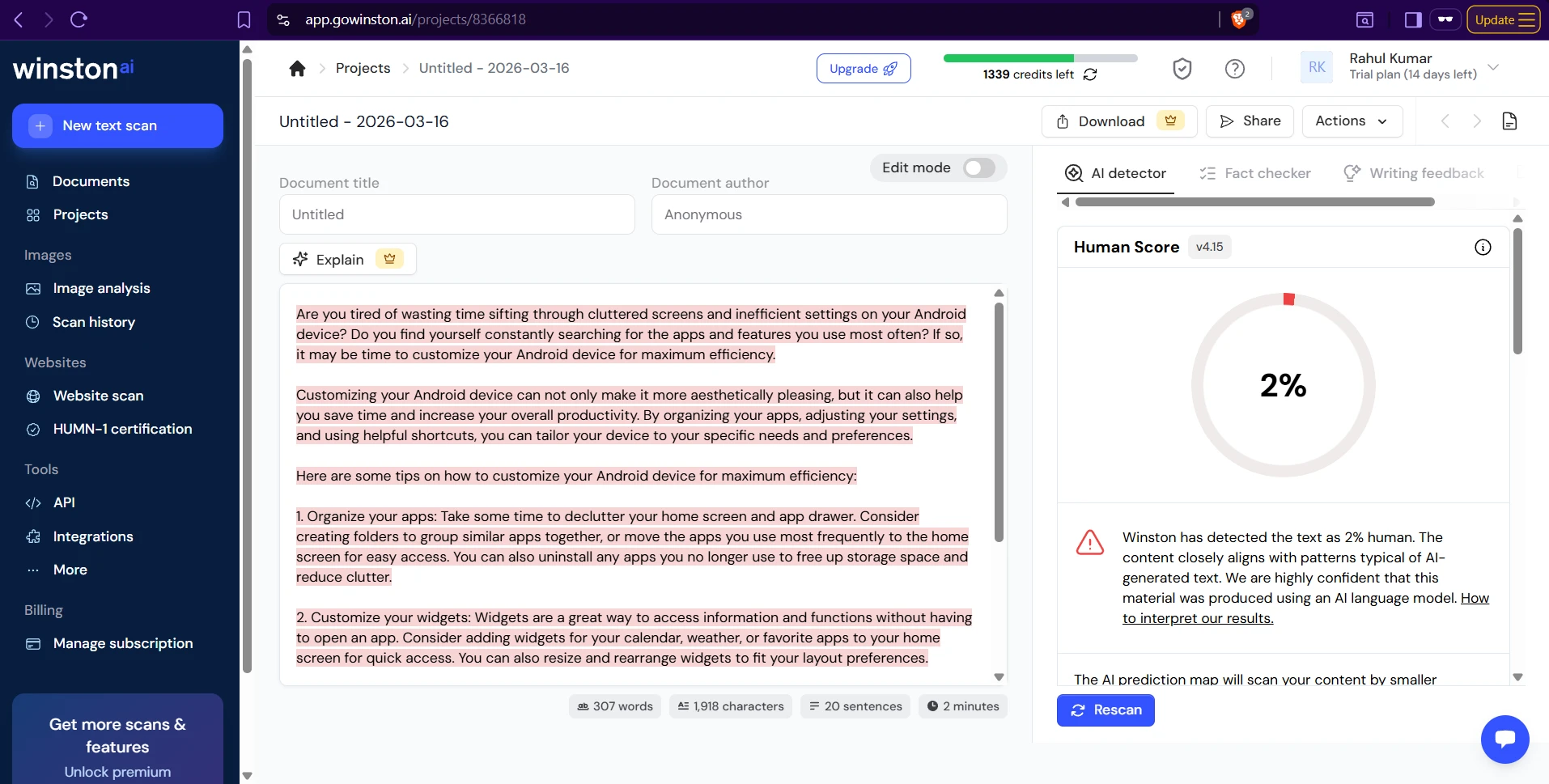
The screenshots below show that in practice. On several AI-written samples, both tools agree the writing looks machine-generated. But one sample about classic books produced a dramatic split: Sapling scored it as fake, while Winston gave it a 98% human score. That single example captures the overall pattern well. Sapling is stricter; Winston is more forgiving.
Also Read: Originality.ai vs Sapling AI
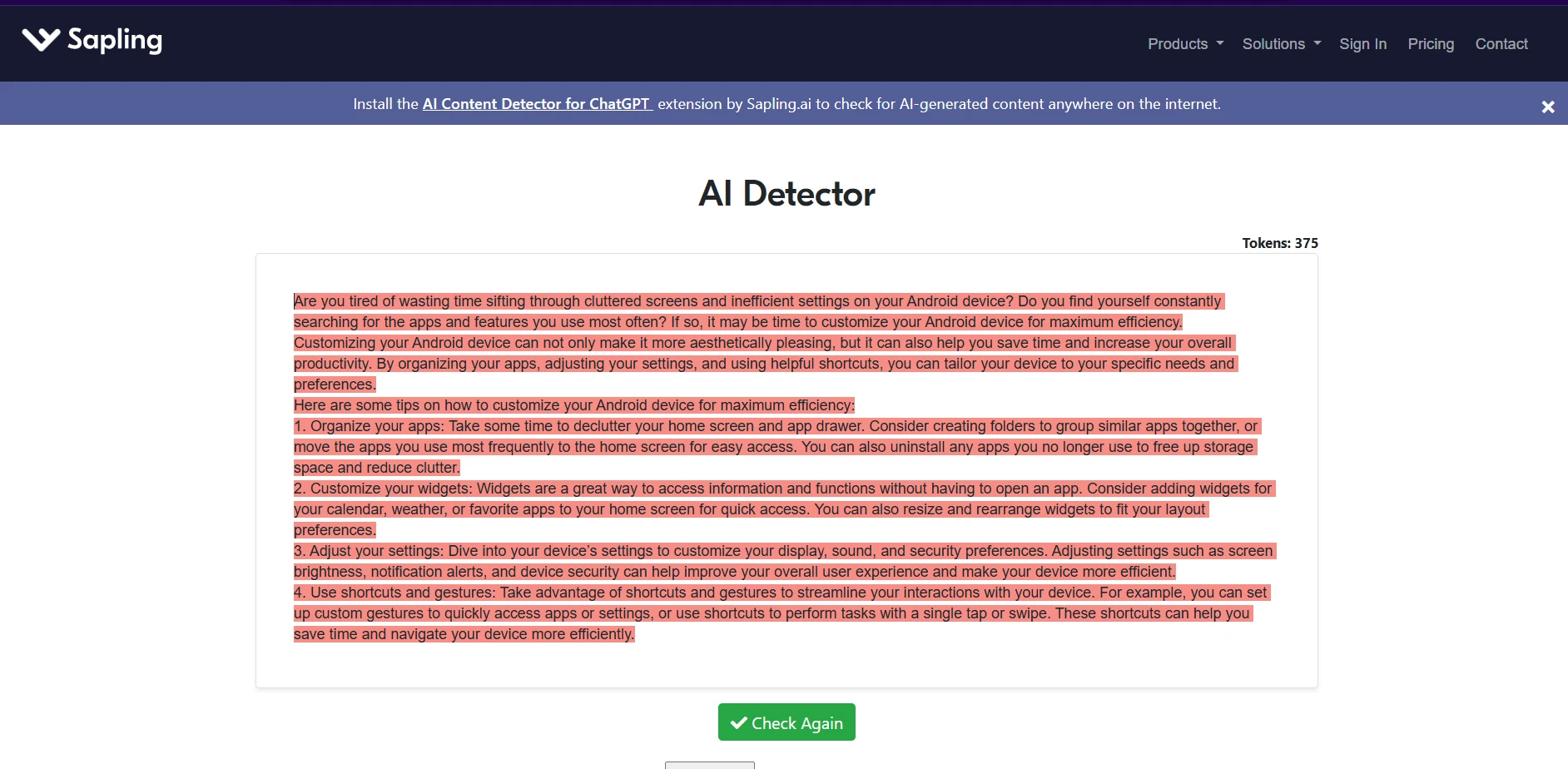
Sapling AI examples
Winston AI examples
What students should actually take from this
For students, the biggest lesson is that an AI detector is not a lie detector. It is a scoring system. Scores are influenced by writing style, sentence predictability, structure, and sometimes even the genre of the piece. A neat explainer, a list-based article, or a tightly organized essay may look “too clean” to one tool and perfectly natural to another.
That is why no teacher, reviewer, or institution should rely on one detector score by itself. A fair process should also consider drafts, revision history, notes, sources, earlier writing samples, and the student’s own voice. Detector output can be a clue. It should never be the whole case.
The final verdict
Based on this 160-sample dataset, Winston AI is the better choice for student-facing use cases. It is much better at recognizing real human writing, and it finishes with stronger overall accuracy. That makes it the safer option when the biggest concern is avoiding unfair accusations.
Sapling AI does have one clear strength: it is more aggressive at catching AI-generated text. But that strength comes with a serious downside. In this test, it pushed a large share of genuine human writing below the 50% line, which makes it hard to trust in settings where a false accusation can have real consequences.
The deeper takeaway is bigger than either brand. AI detection works best as a supporting signal, not a final verdict. For students, that distinction matters a lot.