

Students hear the same promise again and again: rewrite AI text with a humanizer, run it through a detector, and the problem goes away. That sounds convenient. It also deserves evidence. So I tested 100 Phrasly rewrites and tracked how human they looked to Originality.ai. A higher score in this article means the text looked more human. A lower score means Originality.ai still saw it as AI. After going through the full CSV, one pattern stood out: most rewrites did not just struggle to pass, they often damaged the writing on the way down.
How This Test Was Measured
The dataset contains 100 original samples, their Phrasly rewrites, and a converted human score. Originality.ai normally reports confidence that text is AI. Here, that value was flipped so the scale is easier to read: 100% means “looks fully human,” and 0% means “looks fully AI.”
This matters because raw averages can hide what is really happening. So I looked at several angles: the overall score distribution, how many rewrites crossed important cutoffs, and whether the rewriting process damaged structure. I also compared formatting before and after the rewrite to catch issues that a simple score alone would miss.
Also Read: Can Phrasly AI humanizer bypass Sapling AI?
The headline numbers
- Average human score: 9.1% human
- Median human score: 0% human (median means the middle result when all 100 scores are lined up)
- Exactly 0% human: 83 out of 100 rewrites
- Below 10% human: 90 out of 100 rewrites
- Reached at least 50% human: 9 out of 100 rewrites
- Reached 100% human: 3 out of 100 rewrites
Most Scores Never Left the Basement
The first chart tells the story fast. The results are not spread evenly across the scale. They are packed near the bottom. That is a big deal, because it means failure was not occasional bad luck. It was the dominant outcome.
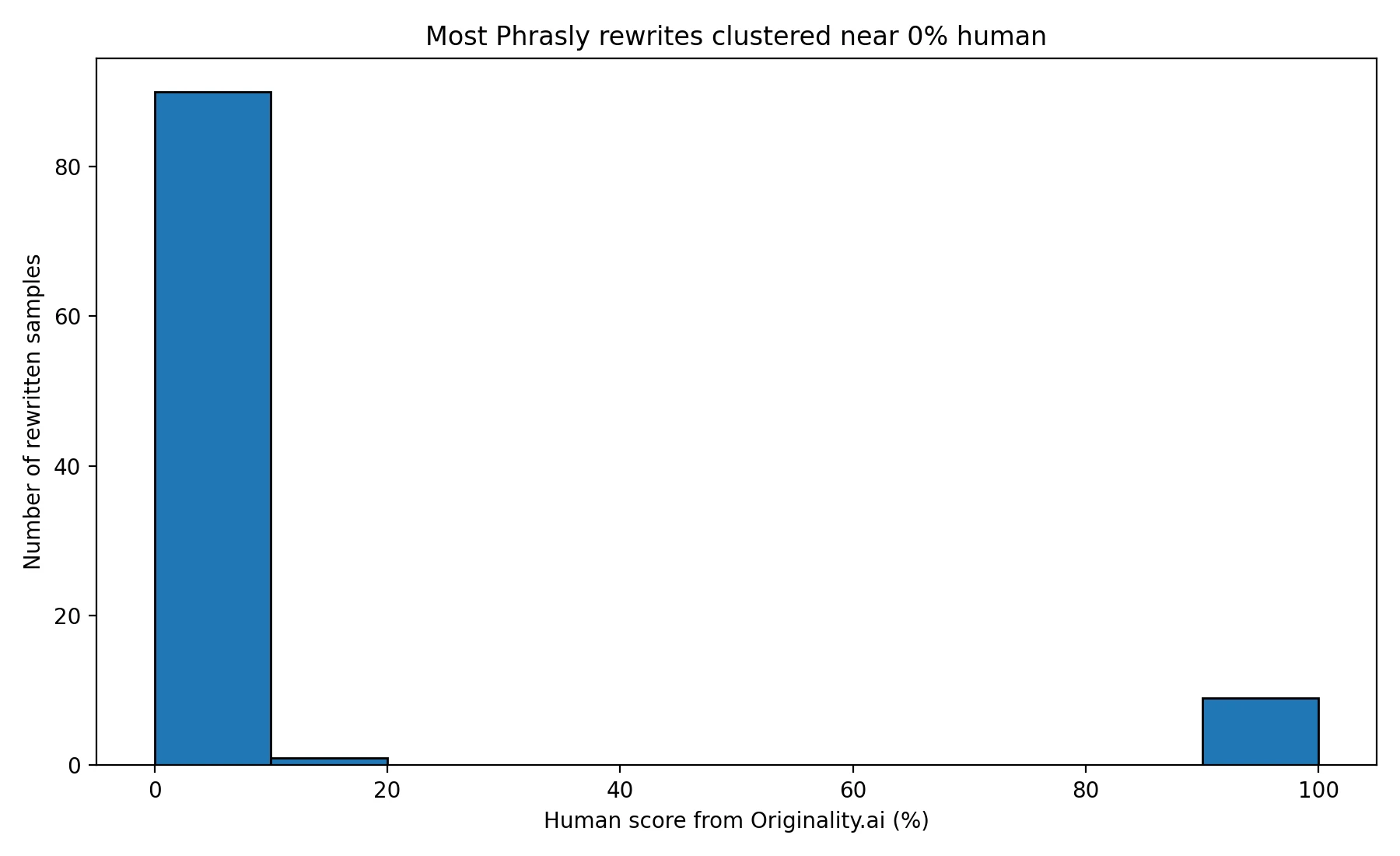
The average score was only 9.1%, but the more telling number is the median: 0%. In plain English, that means the middle sample in the set still looked completely AI-written after the rewrite. When that happens across 100 tests, it becomes very hard to argue that bypassing is reliable.
Also Read: Can Phrasly AI humanizer bypass ZeroGPT?
Passing Was Possible. It Was Just Rare.
It would be unfair to say Phrasly never worked. A small number of rewrites did score well. But “sometimes” is not the same thing as “dependable,” especially if students are thinking about using a tool under pressure. The next chart makes that gap clear.
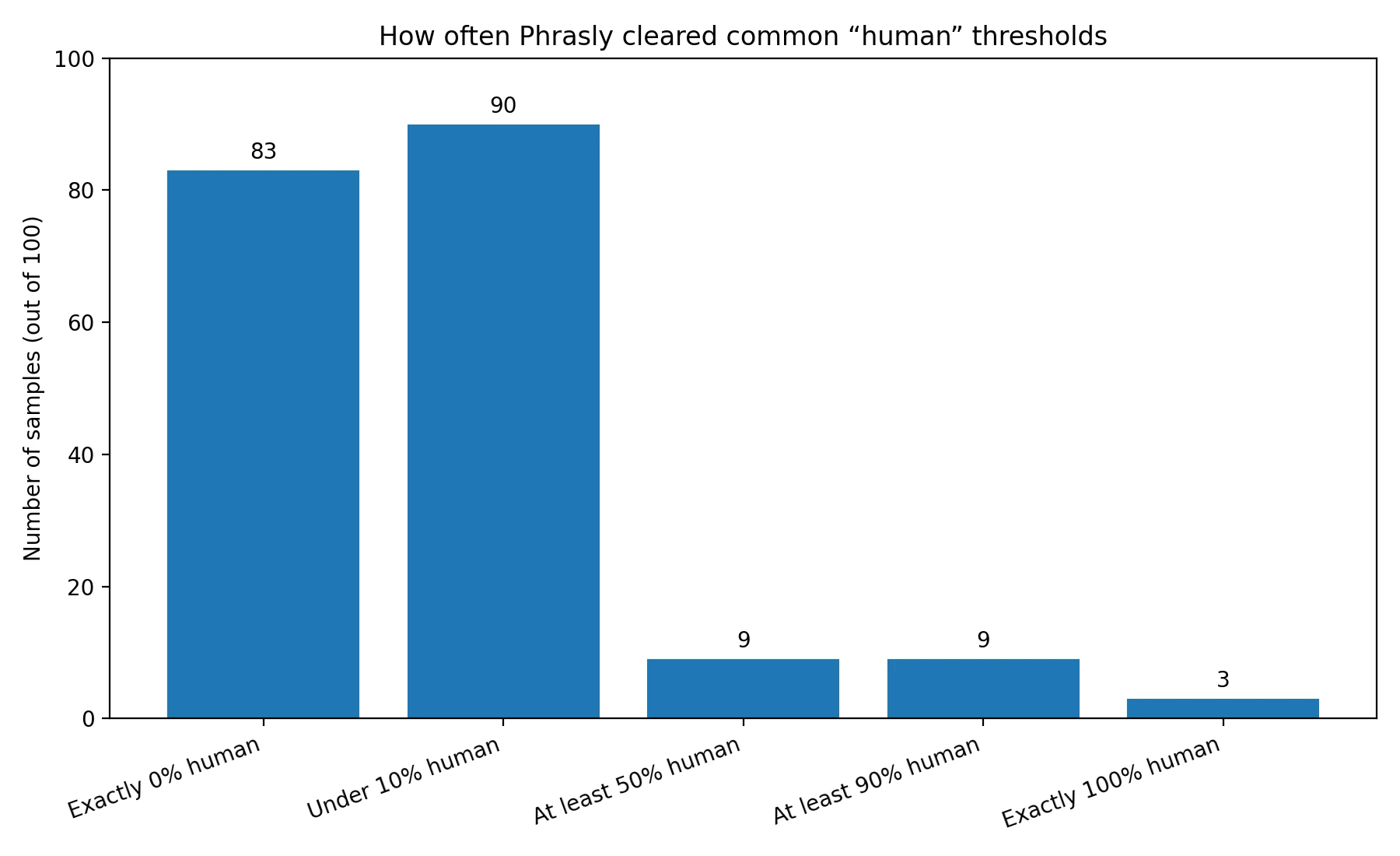
Out of 100 samples, only 9 crossed the 50% human mark, which is the kind of cutoff many people would treat as a meaningful pass. The same 9 reached 90% or higher, and just 3 landed at 100%. So yes, breakthrough cases existed. But they were clearly the exception, not the rule.
Also Read: Can GPTZero detect Phrasly AI?
The Bigger Problem: The Rewrites Often Hurt the Writing
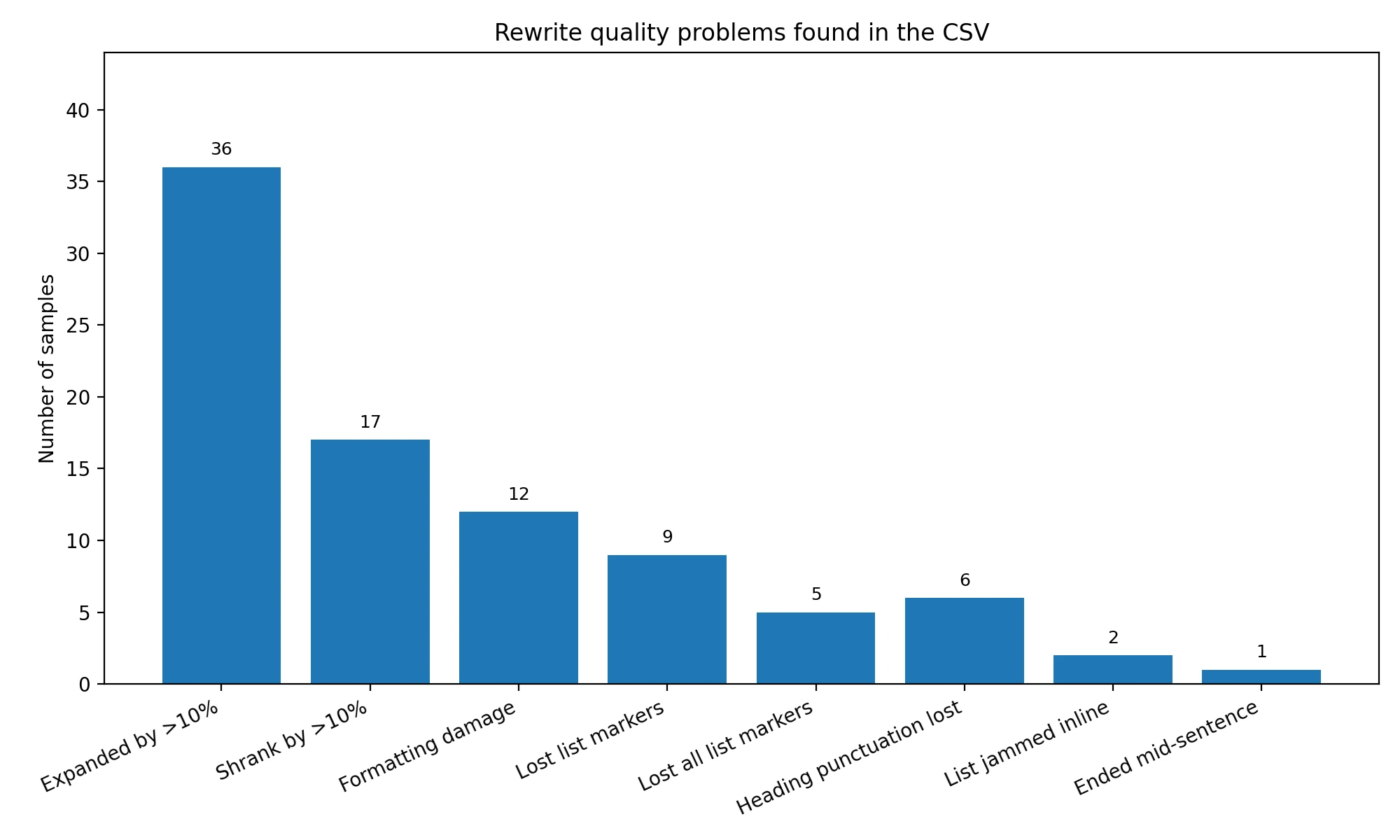
Scores are only half the story. While reviewing the CSV, I found that some rewrites introduced visible quality problems. In several instructional pieces, list markers disappeared, headings lost their punctuation or hierarchy, and numbered points were pushed into normal paragraphs. In one travel example, a destination list was jammed together so the text ran straight from the lead-in sentence into “1. Costa Rica” without a proper break. In another example, “1. Helmet:” became just “Helmet,” which made the section less scannable and less polished.
There were also signs of instability in length. 36 rewrites became more than 10% longer, often by adding filler. 17 became more than 10% shorter, which sometimes meant losing useful specifics. One rewrite even ended mid-sentence. That is not just a detector problem. That is a readability problem.
Some of the roughest rewrites also sounded less natural than the originals. One opening line turned into the awkward phrase “Graphics that are visual images or visible effects,” which reads more like a broken definition than a clean introduction. That matters for students because a rewrite tool is supposed to make text smoother, not stranger.
Also Read: Can Turnitin Detect Phrasly AI?
Structured Writing Was More Fragile
List-style and how-to articles were especially vulnerable. When the original sample used bullets or numbered structure, the average human score fell to 5.7%. For samples without that kind of structure, the average was 11.1%. That is still not strong, but it is almost double.
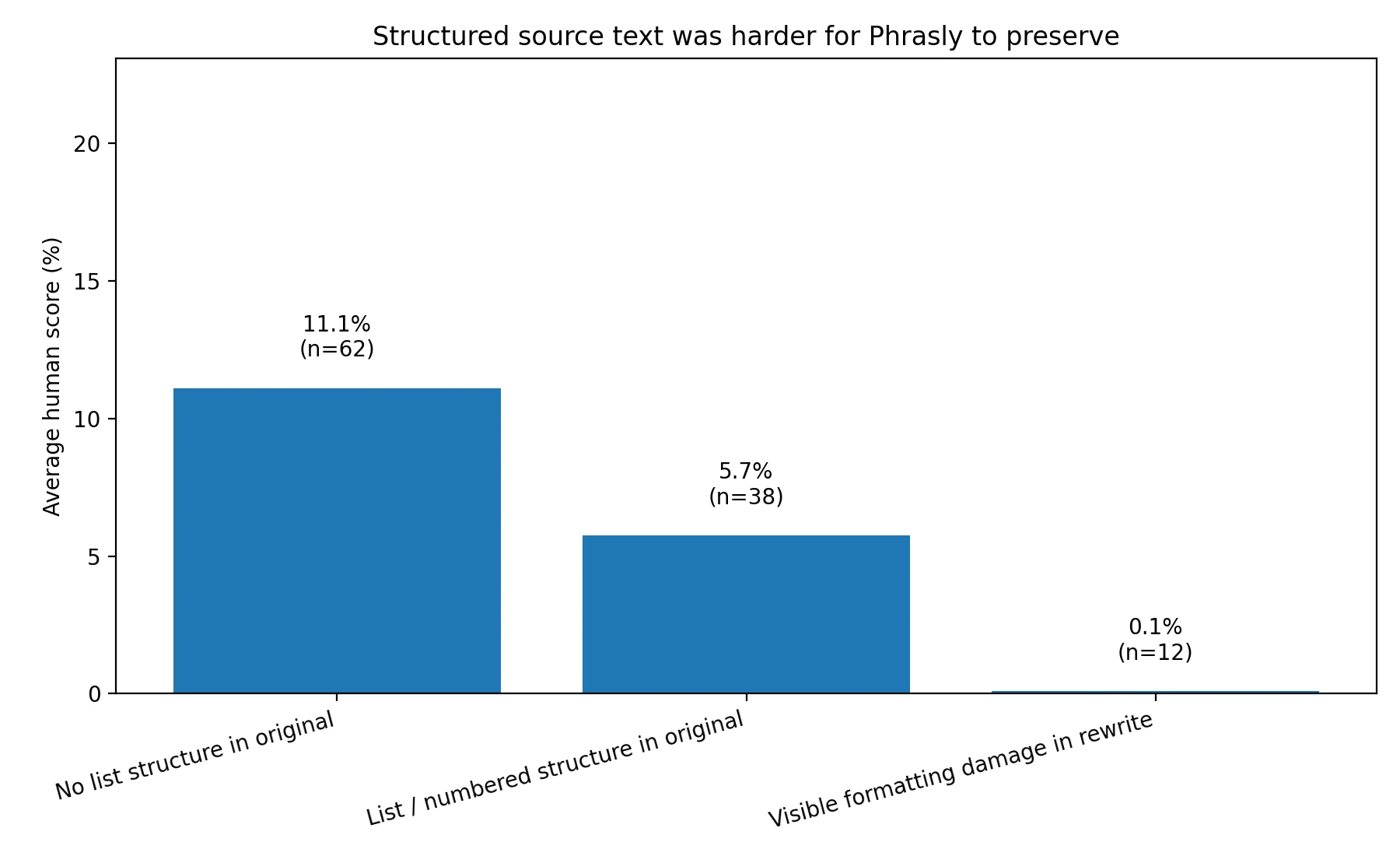
Even more revealing, the samples with visible formatting damage were almost dead on arrival. Their average human score was basically zero. That suggests the detector was not only reacting to wording. It may also have been reacting to the messy way some rewrites handled structure.
Longer Rewrites Did Not Rescue the Score
Some students assume that if a humanizer expands the text, adds extra words, or changes enough phrasing, the detector will relax. The data did not support that idea. The chart below is a scatter plot, which simply means each dot is one sample. It compares how much the rewrite changed the length with the final human score.
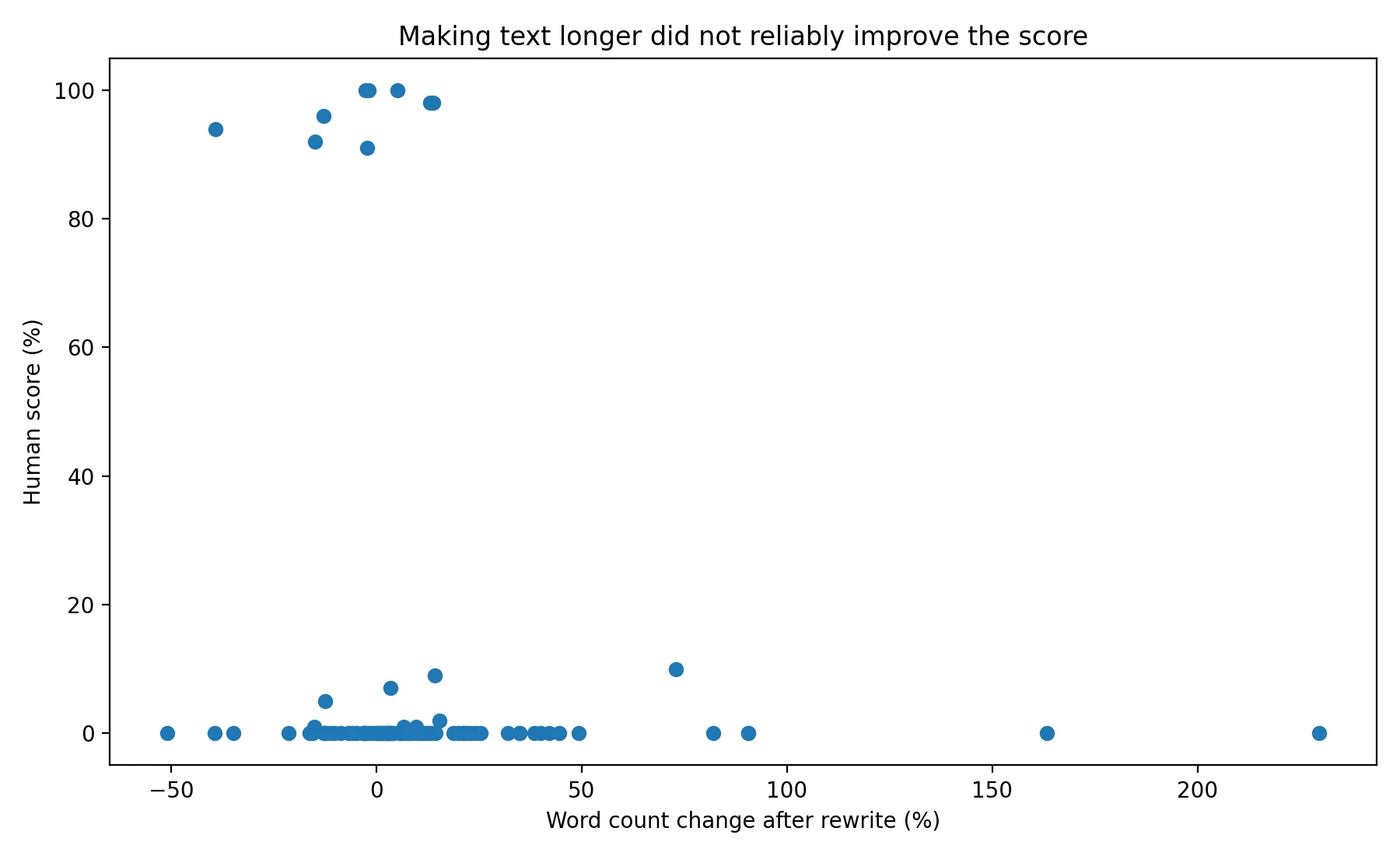
The dots are all over the place. Some rewrites got much longer and still scored near zero. Others got shorter and still failed. In other words, more words did not automatically mean more human-looking text. That is useful to know because it weakens one of the most common assumptions behind rewrite tools.
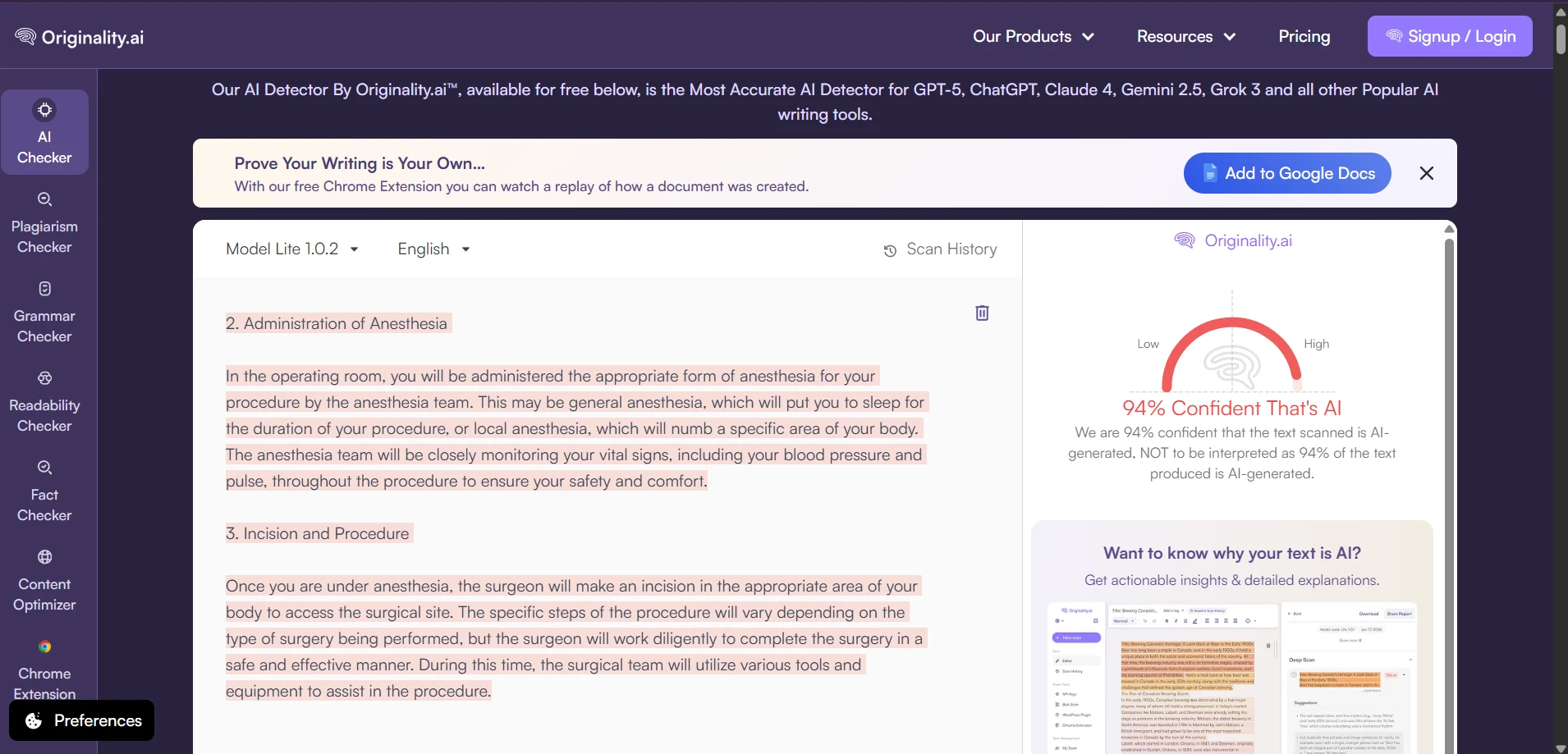
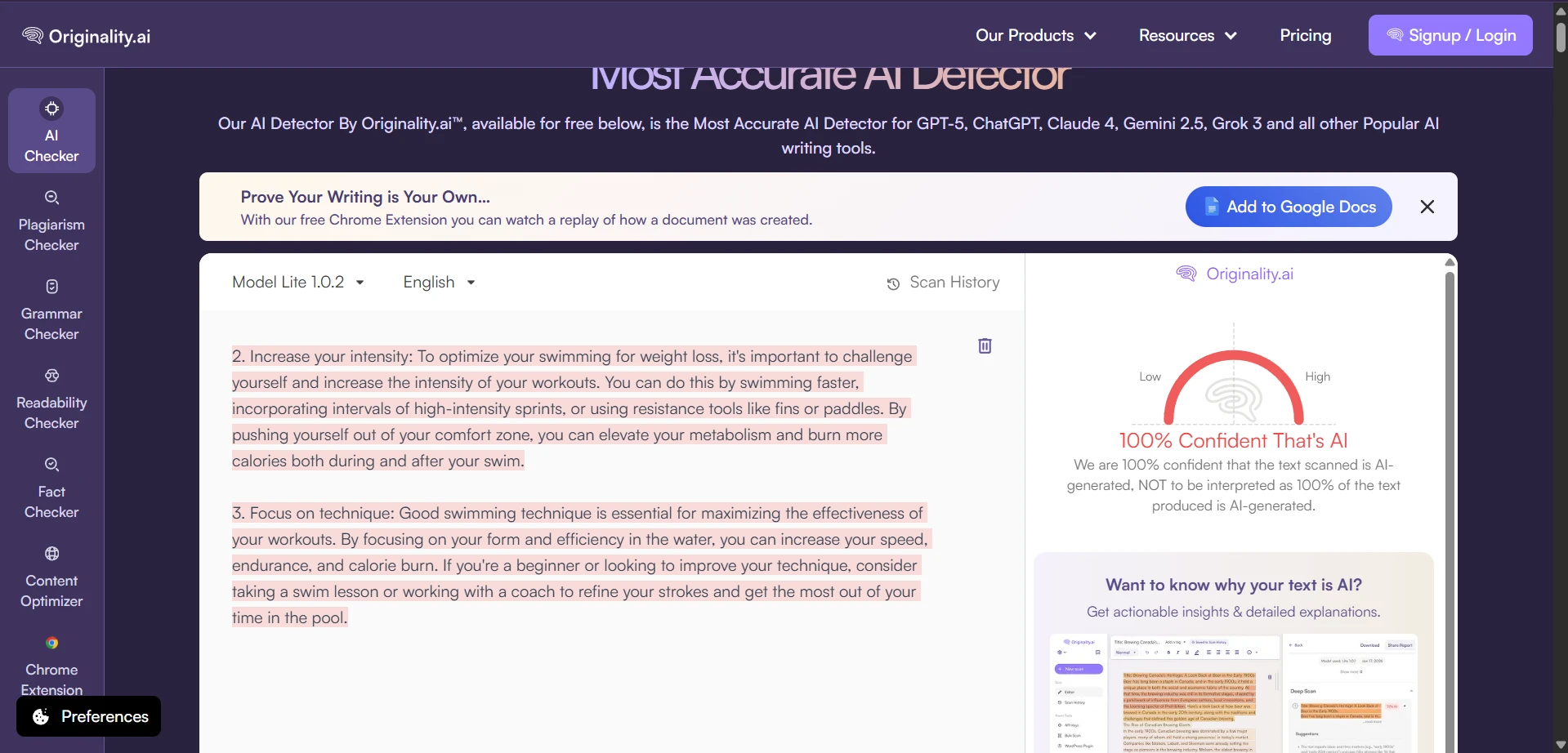
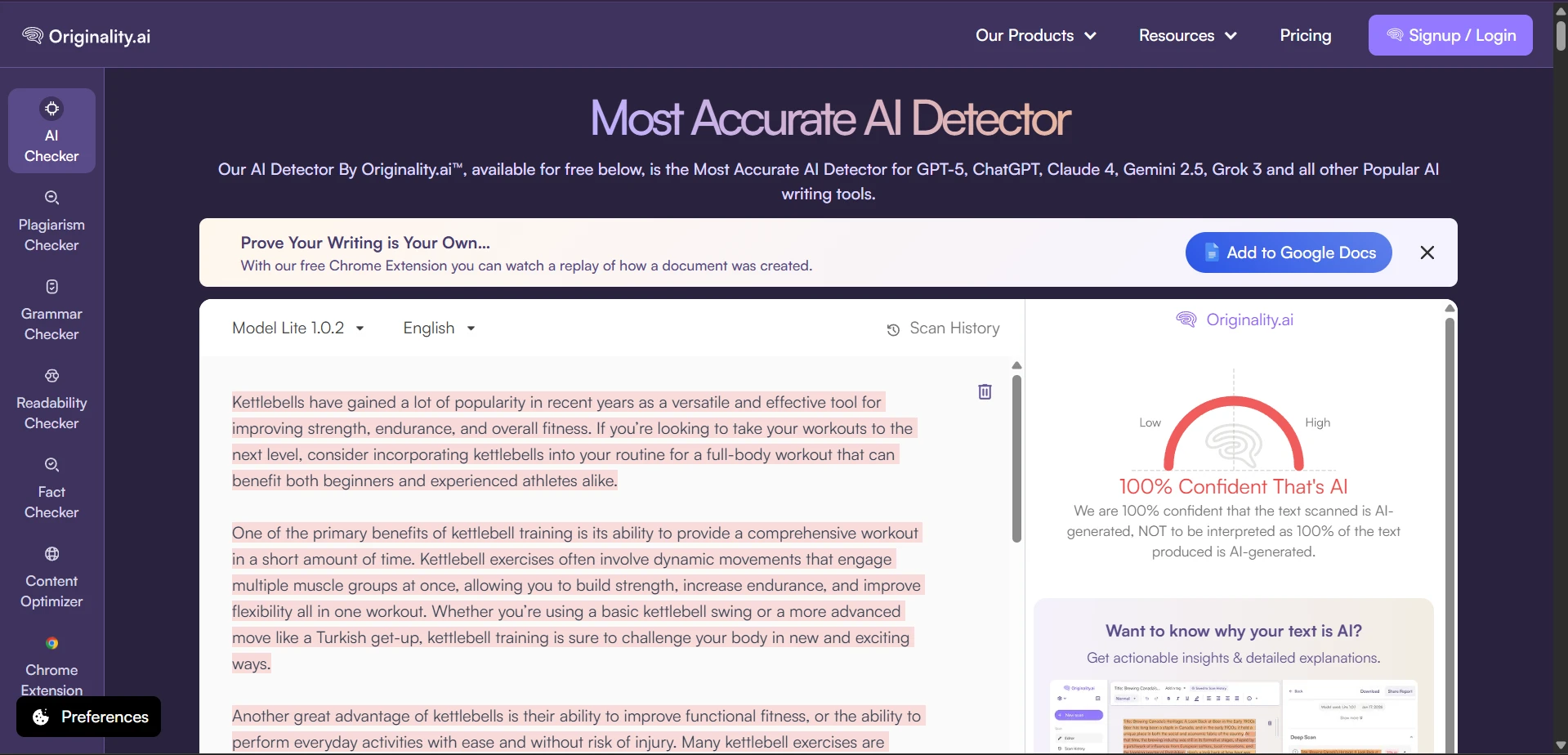
What the Raw Scans Looked Like
The screenshots below show the kind of outcomes that kept appearing during testing. Several rewrites were still flagged by Originality.ai with very high AI confidence. These are the raw detector views; the charts above simply converted those AI-heavy results into a human-score scale so the comparison was easier to understand.
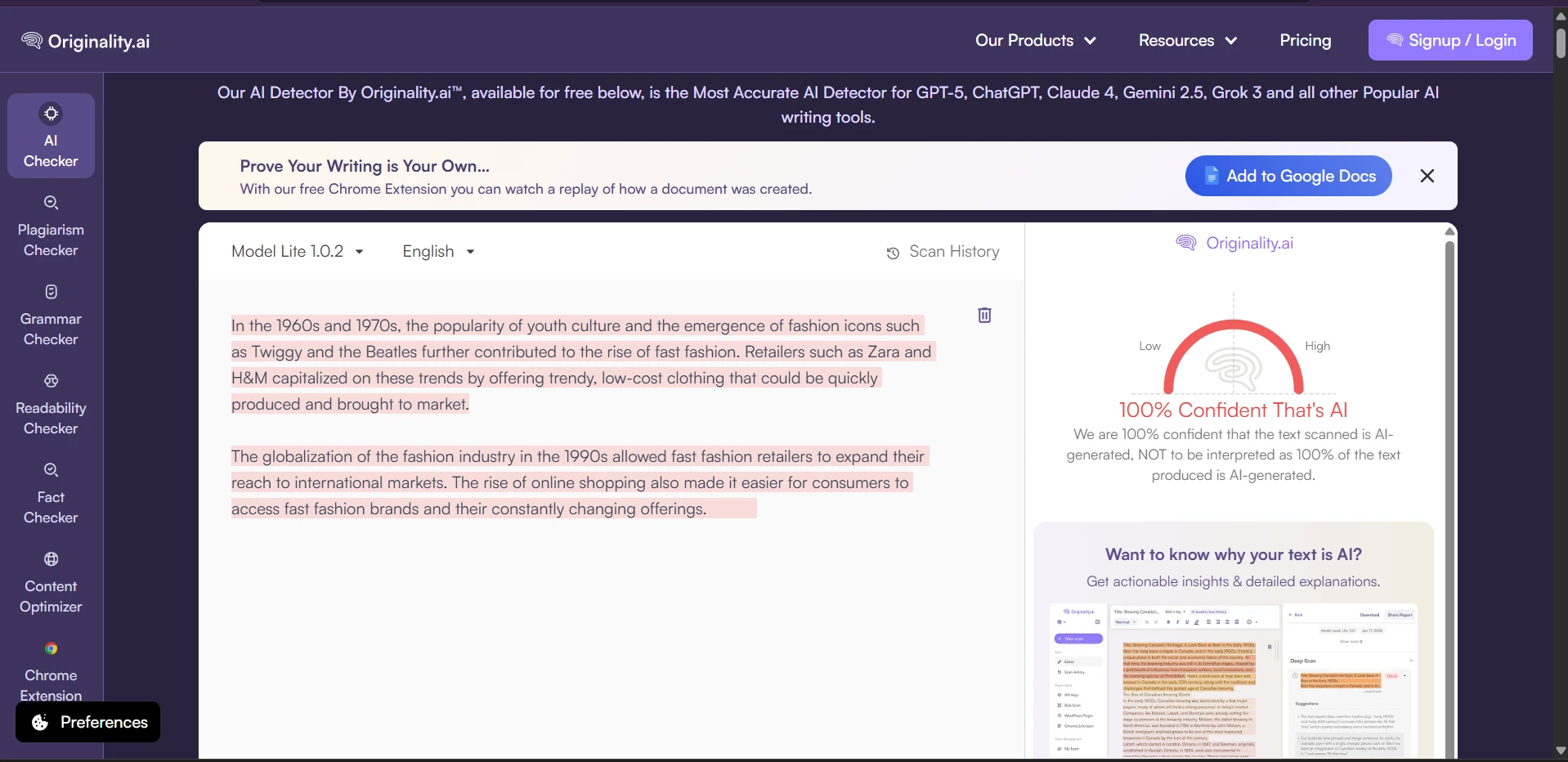
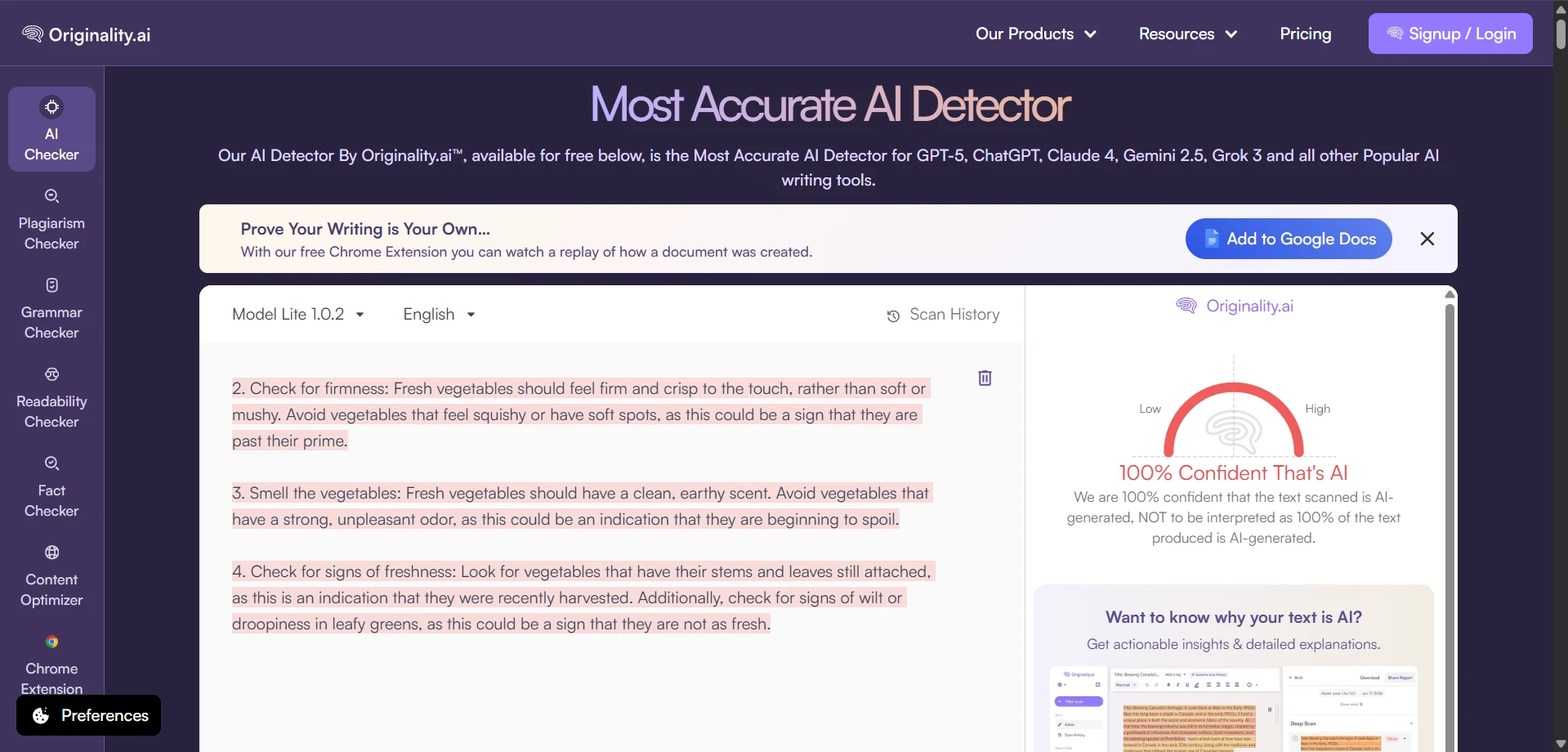
The Final Takeaway
Based on this 100-sample test, Phrasly was not an effective or reliable way to get past Originality.ai. The average human score stayed low, the middle result was 0%, and only a small minority of rewrites reached strong human-looking scores.
Just as important, the rewrite process often came with side effects: flattened lists, weaker headings, changed pacing, extra filler, occasional loss of detail, and even the odd broken ending. For students, that is the real lesson. A tool that promises to make text look safer can also make the writing look worse. And when both the score and the structure suffer, the shortcut stops looking like a shortcut at all.