![[STUDY] Can Phrasly AI Humanizer Outsmart Sapling? A Data-Driven Test](/static/images/can_phrasly_ai_humanizer_outsmart_sapling_a_data-driven_testpng.webp)

Students are being sold a simple idea: run AI text through a humanizer, then slip past the detector. That promise sounds convenient, especially when deadlines are tight and detection tools feel unpredictable. Instead of trusting marketing claims, I looked at the numbers. Using the spreadsheet attached to this project, I analyzed 100 Phrasly outputs and checked how “human” Sapling thought they looked. In this study, a higher score means the text looked more human, while a lower score means Sapling still saw it as AI. The result was not close.
What exactly was tested?
Each row in the uploaded CSV contains an original passage, a Phrasly-humanized version, and a converted Sapling human score. Sapling normally reports how likely a passage is to be AI, so the score here has been flipped into a human score. That makes the interpretation easier. 100% means Sapling saw the text as strongly human. 0% means it still looked fully AI to the detector.
One important note before getting into the charts: your message mentioned 160 samples, but the uploaded CSV contains 100 rows. So the analysis below reflects the file that is currently available. If you later upload the missing rows, the visuals can be refreshed quickly.
Also Read: Can Phrasly AI humanizer bypass ZeroGPT?
The numbers that matter most
- Average human score: 1.24%
- Median human score: 0%. The median is the middle value once all scores are lined up.
- Exactly 0% human: 92 out of 100 samples
- At least 10% human: 1 out of 100 samples
- At least 50% human: 1 out of 100 samples
- Without the one extreme outlier: the average falls to 0.26% human
The first chart answers the real question
If Phrasly were regularly bypassing Sapling, the scores should spread upward into the safer zones. Instead, almost the entire dataset piles up at the bottom. The bar chart below shows how many samples landed in each human score band.
Also Read: Can Phrasly AI humanizer bypass GPTZero?
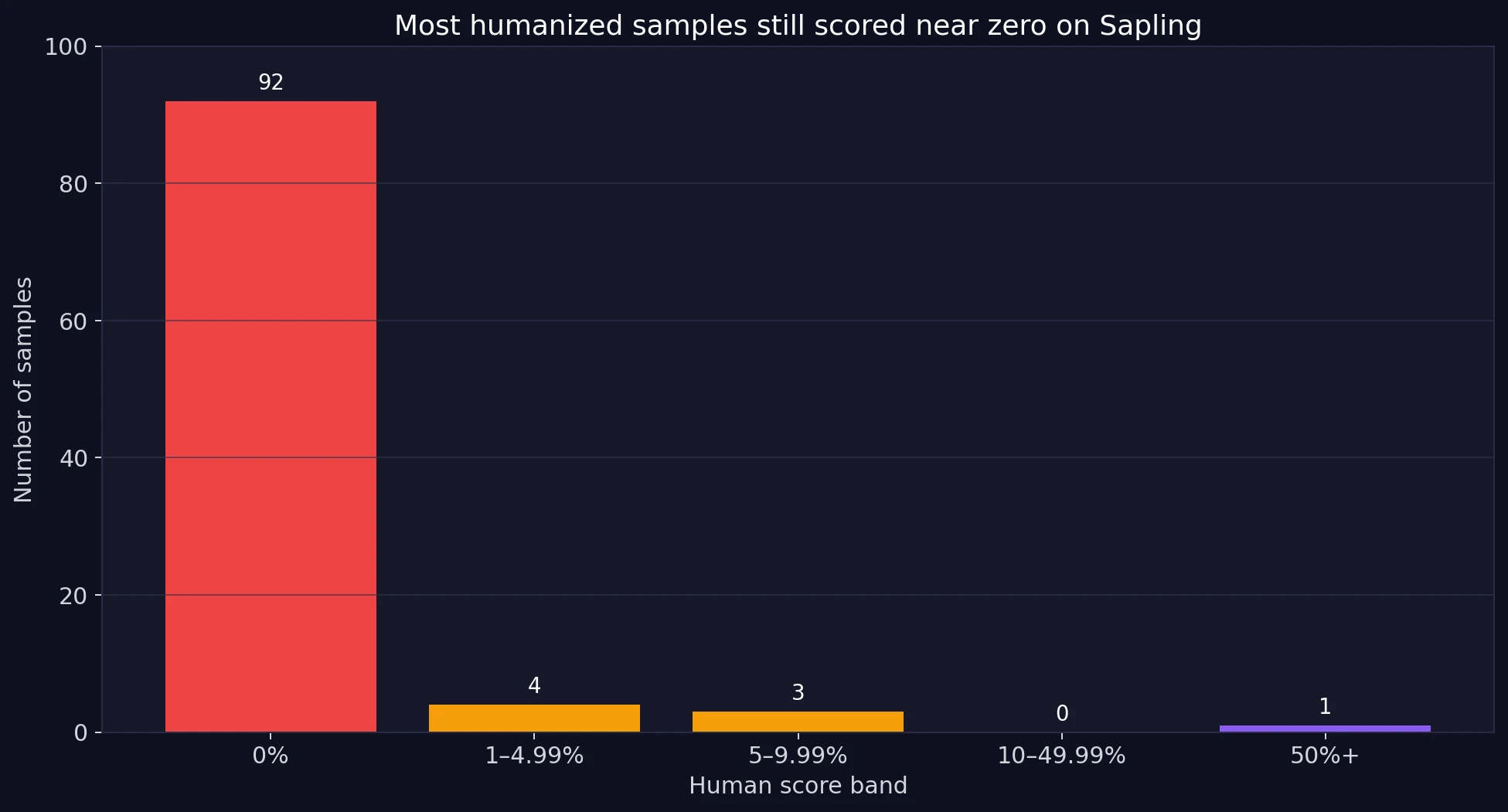
This is the clearest takeaway in the whole study. 92% of the dataset landed at exactly 0% human. Another small group only reached the low single digits. Just one sample crossed into the 50%+ range. For students, that matters more than an abstract average. A tool does not need one lucky result. It needs repeatable results. This dataset does not show that.
Also Read: Can Phrasly AI bypass Turnitin?
Looking at thresholds students actually care about
Think of score thresholds as checkpoints. A score above 50% at least gives the impression that the detector is unsure. A score above 90% looks comfortably human. The next chart shows how many Phrasly outputs crossed those practical lines.
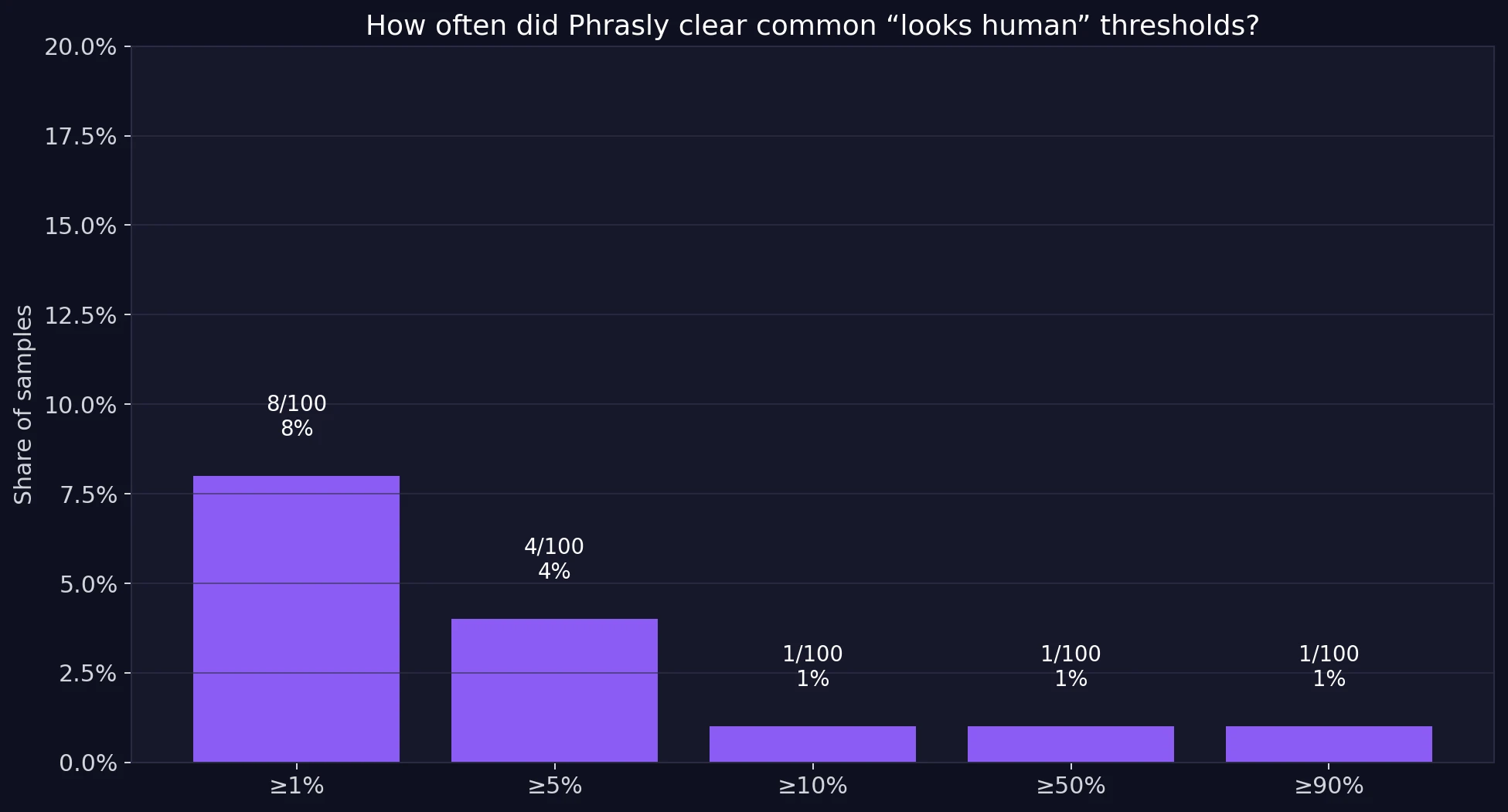
The pattern is severe. Only 8 samples even reached 1% human. Only 4 reached 5% human. Only 1 reached 10% human. And only 1 sample cleared 50%. That means the success rate was effectively 1% if we use 50% as a minimal “maybe this passed” line. That is far too weak to call a reliable bypass.
One outlier can make averages look better than reality
The average score is 1.24%, but that number is actually flattering to Phrasly. Why? Because the dataset contains one very unusual result. In statistics, this is called an outlier, which simply means a value that sits far away from the rest of the data. The ranked chart makes that visible immediately.
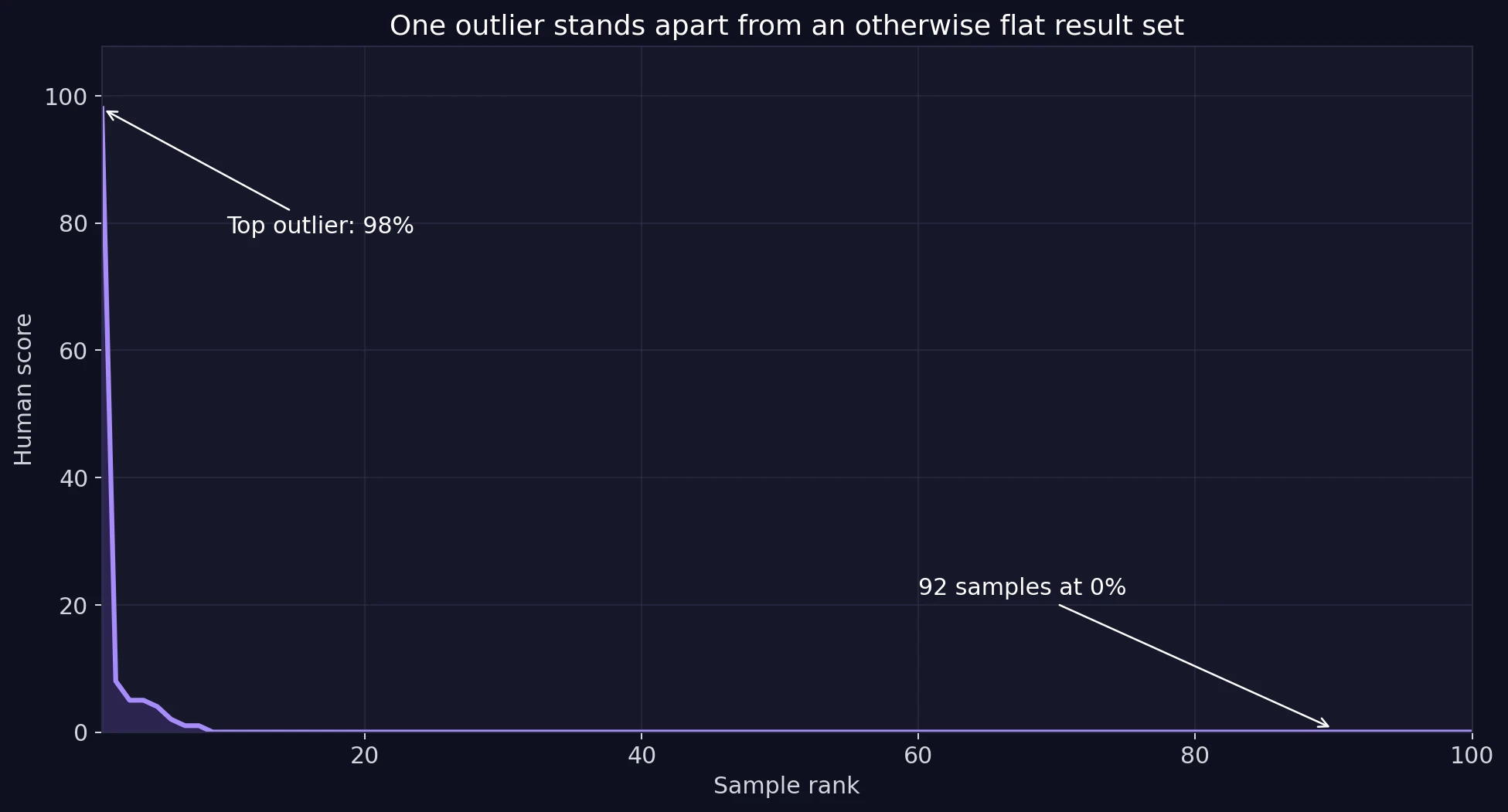
Once that single high score is removed, the average human score drops from 1.24% to just 0.26%. Even more interesting, the strongest “success” case appears to be almost unchanged from the source text. Its original and paraphrased versions were nearly identical apart from formatting, especially a line break. That makes the outlier look less like a dependable bypass and more like a one-off quirk in the detector.
Does making the rewrite longer help?
A reasonable guess is that heavier rewriting might fool Sapling more often. Phrasly did change the text length in many rows. On average, the paraphrased version was longer than the original. But a length change alone did not produce better detector outcomes.
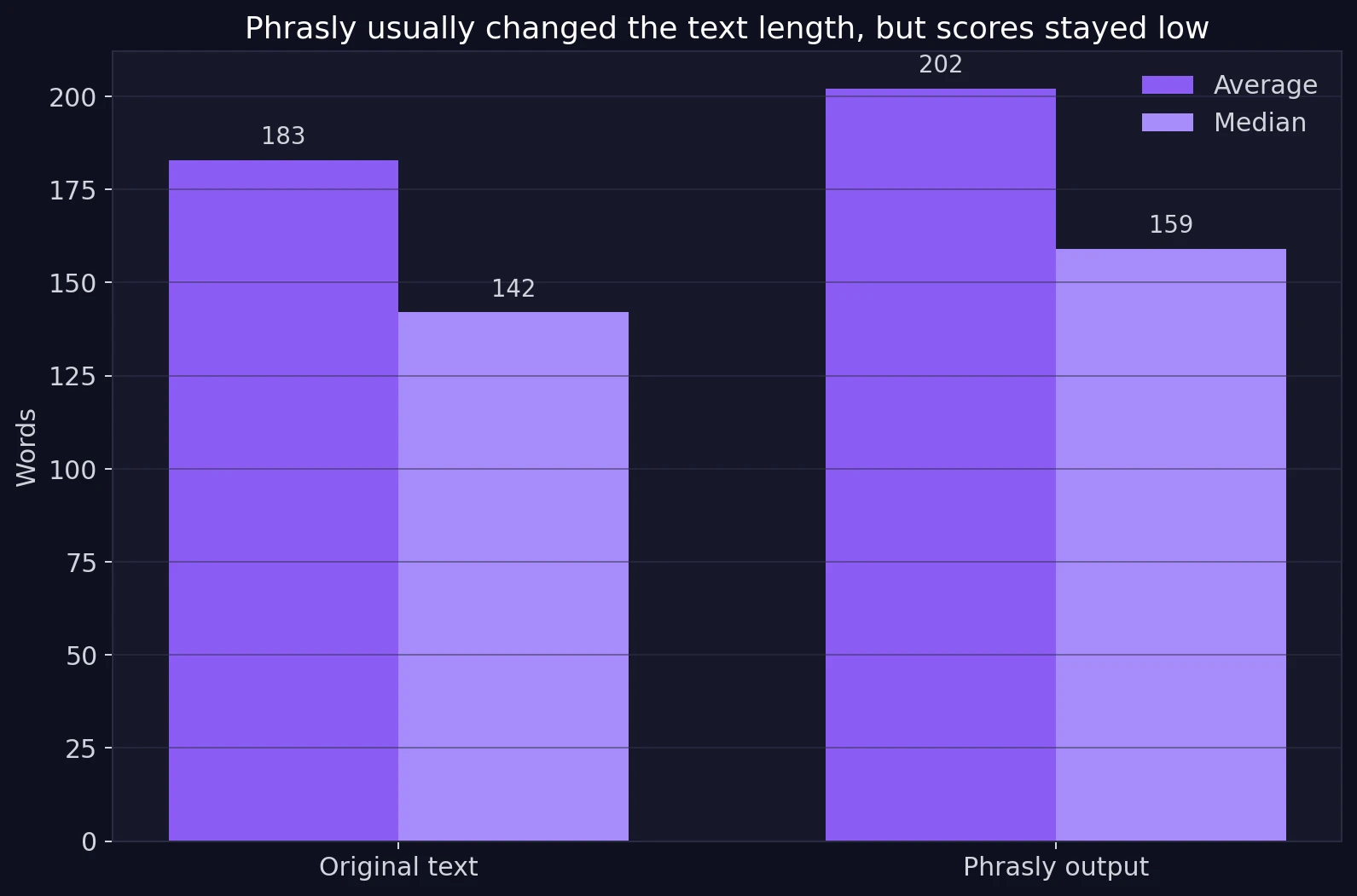
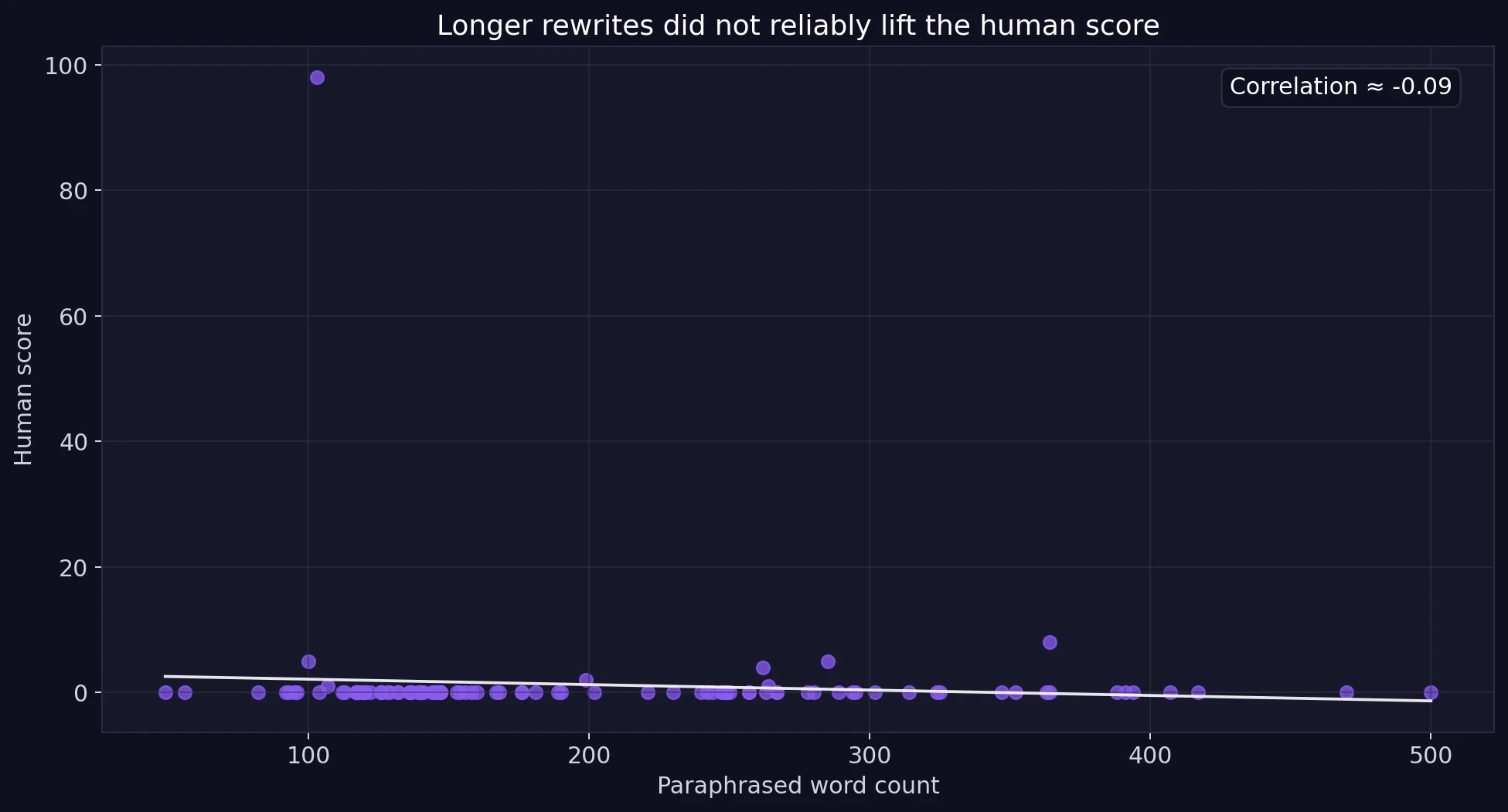
The scatter plot uses a simple idea called correlation. Correlation asks whether two things rise together. Here, the correlation between paraphrased word count and Sapling’s human score was about -0.09, which is very close to zero. In plain language, longer outputs did not consistently look more human to Sapling. So students should not assume that extra words, extra fluff, or more rewriting will automatically make a detector back off.
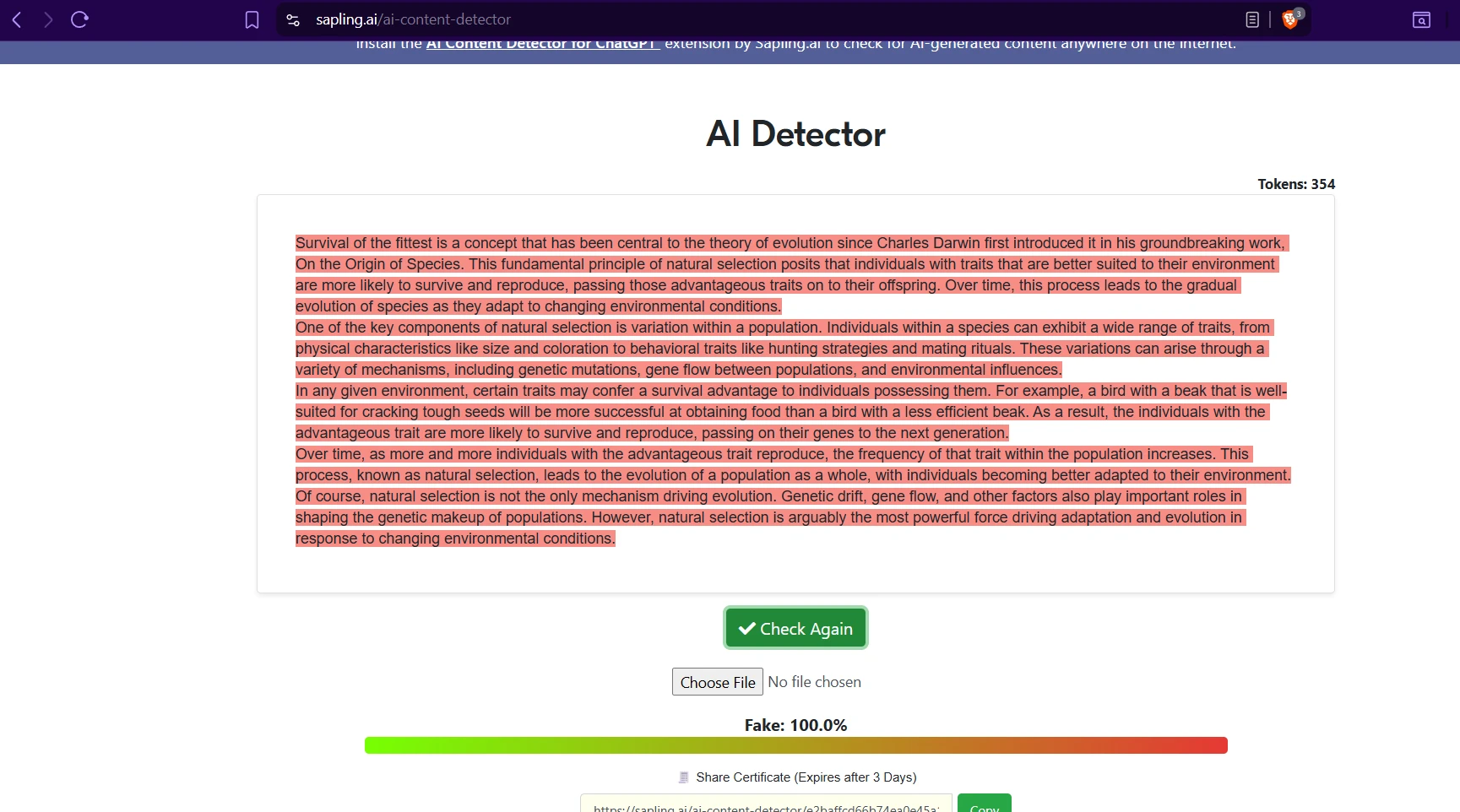
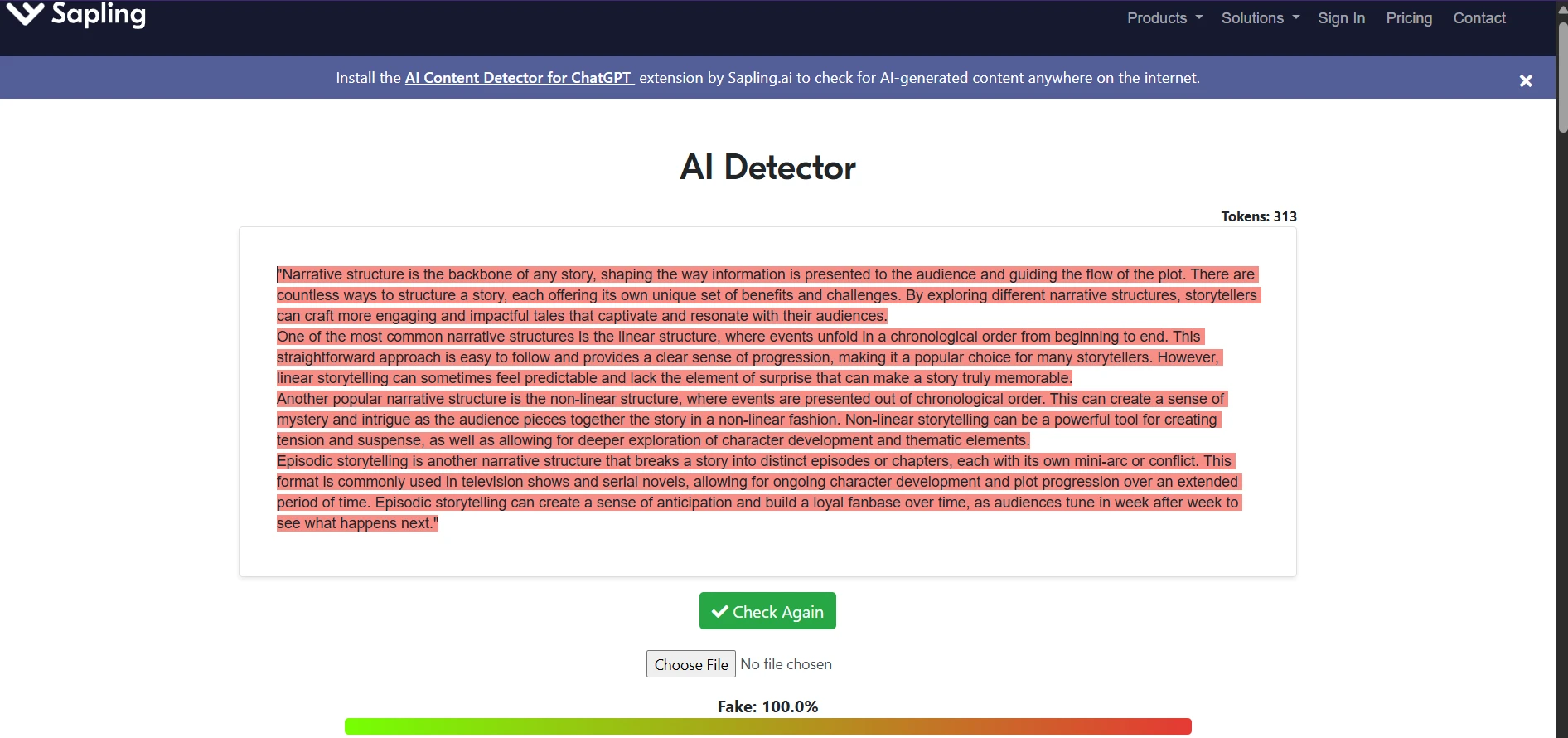
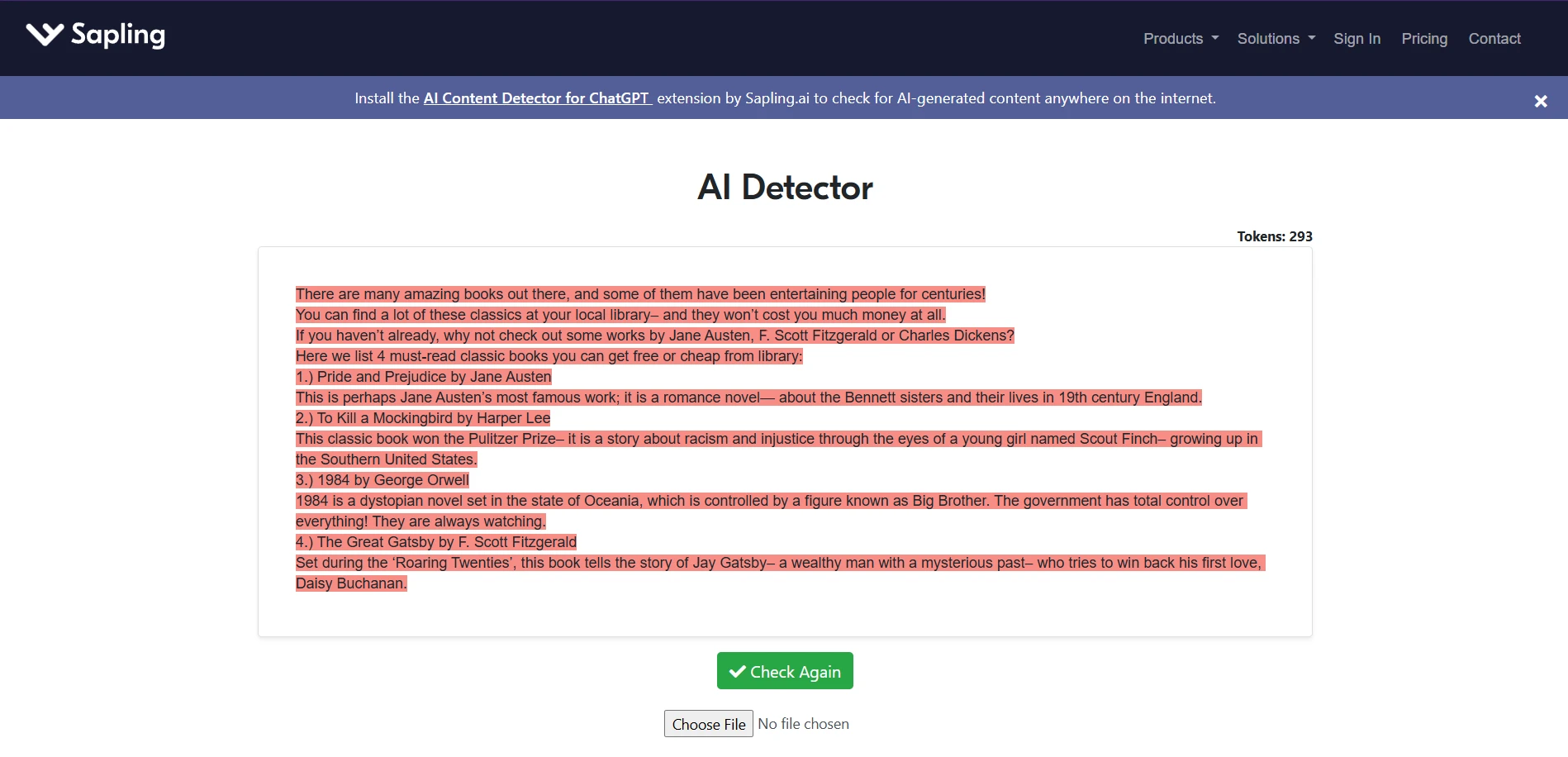
Do the screenshots support the chart story?
Yes. The screenshots collected during testing line up with the broader pattern from the spreadsheet. Across different topics and writing styles, Sapling repeatedly labeled the passages as strongly AI, often showing Fake: 100.0%. That matches the score distribution above, where the overwhelming majority of samples stayed at the floor.
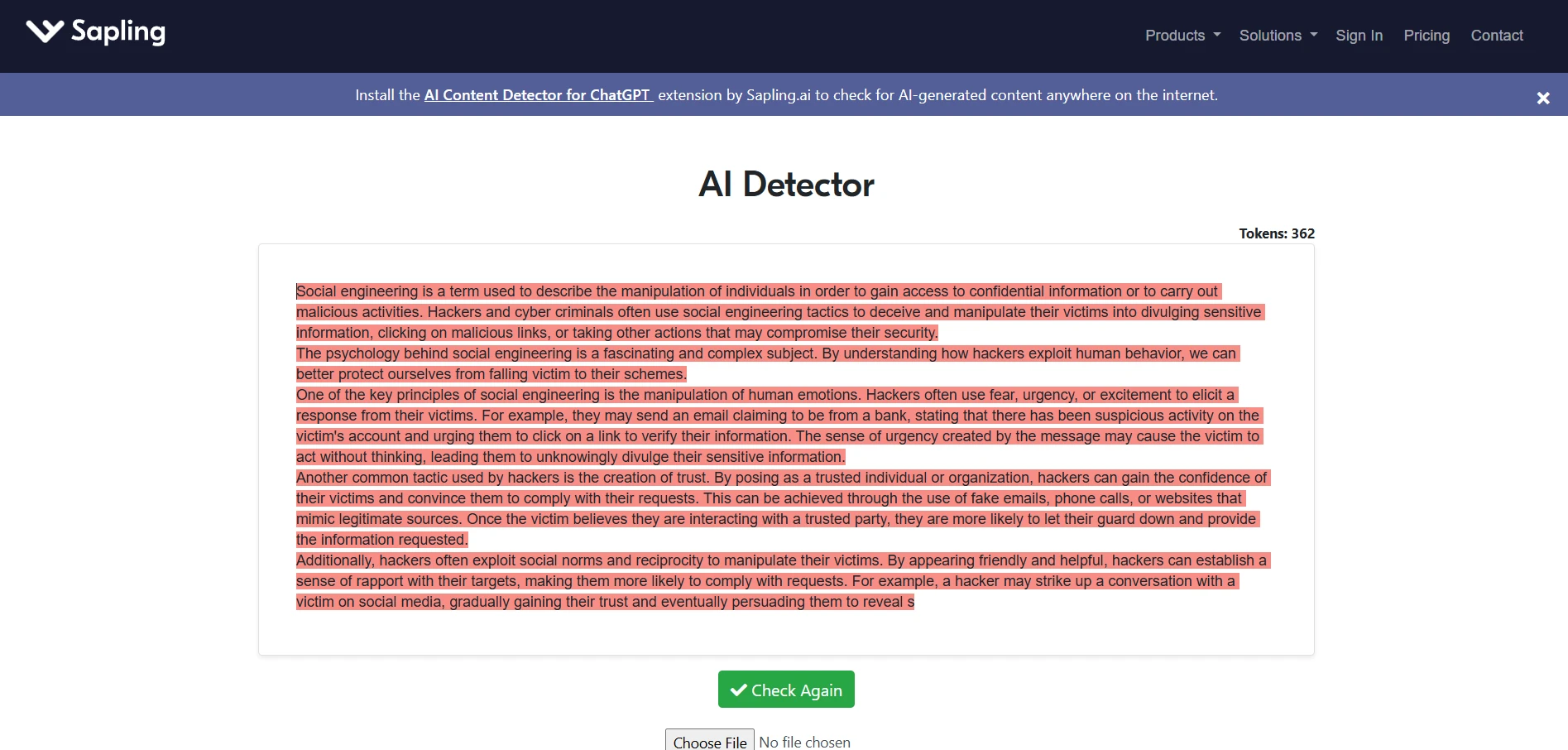
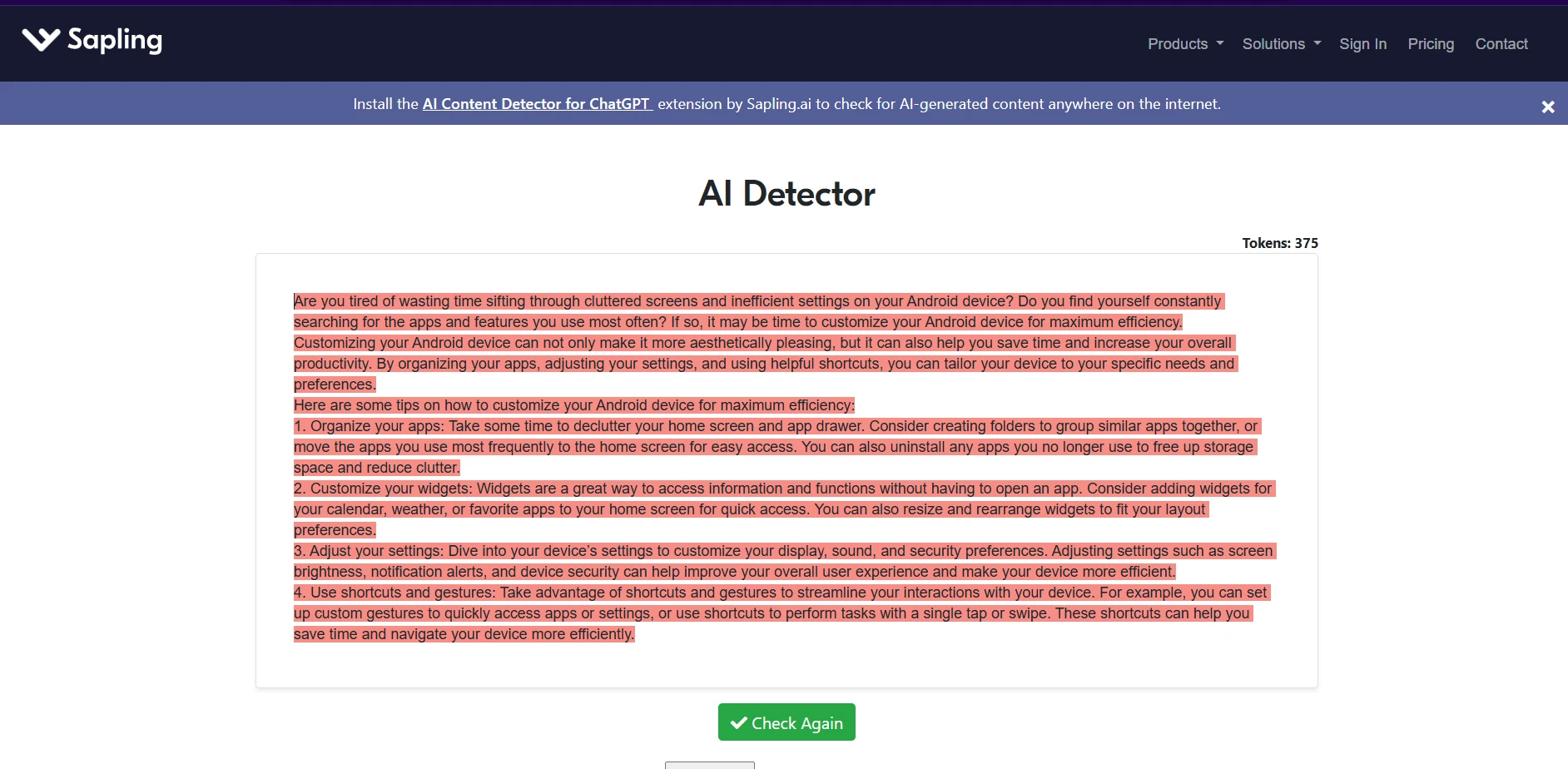
Final takeaway
Based on our dataset, the answer is not in any reliable way. A useful bypass tool should produce a meaningful cluster of human-looking scores. This one did not. Most samples were stuck at 0%. Only one result looked strong, and that case appears to be almost identical to the original input. That is not enough evidence to call the method dependable.
There is also a practical lesson here for students. Humanizers can change wording, shuffle sentence flow, and pad a paragraph with more text. But detectors often seem to react to deeper patterns too, such as predictable structure, generic phrasing, or the overall rhythm of the passage. In other words, surface-level rewriting may not be enough. A few outputs may slip through, but that is very different from having a strategy you can count on.