![[HOT] Is CoPilot Detectable by Originality.ai?](/static/images/is-copilot-detectable-by-originality-aipng.webp)

As we all know it Copilot is an AI code and text generation tool from GitHub. However, is it detectable by Originality.ai? The short answer is YES. The longer answer is the devil lies in the details. Keep reading to know more about it.
Why Copilot gets detected by Originality.ai?
The simple answer is just like any AI text generator, Copilot is not made to bypass AI detectors. You can see this clearly in its design and marketing. Copilot is meant to help with code and text completion, it never advertises itself as a tool that can avoid AI detection. Hence, if it is not built to accomplish this task it won’t be able to do it.
Also Read: Is CoPilot detectable by ZeroGPT?
Test Results
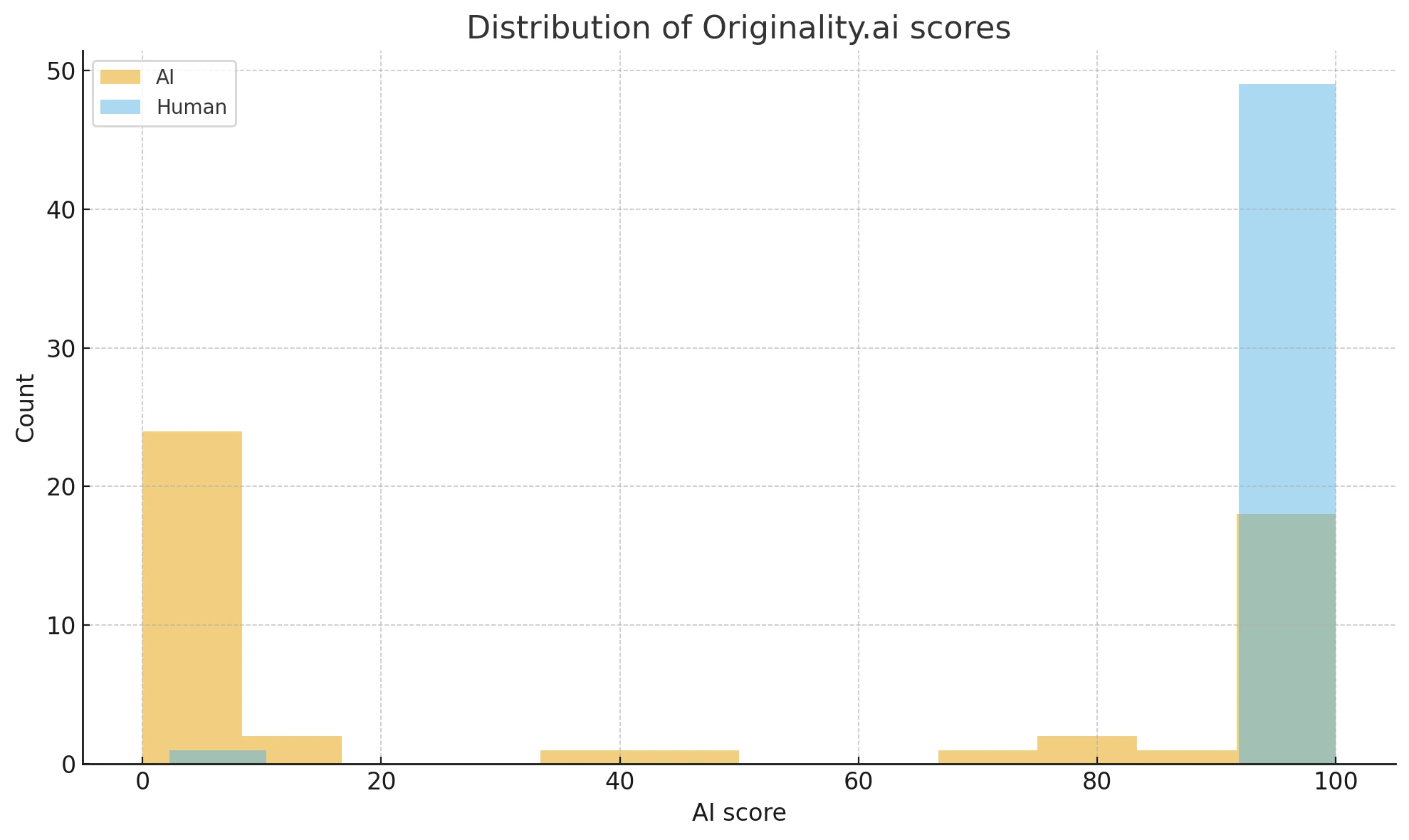
We recently tested 50 snippets generated by Copilot and 50 human-written snippets in Originality.ai. We used the continuous “ai_score” that goes from 0–100, where higher scores are more human-like. We also examined the built-in “originality_ai_label” (which says AI or Human), but we found out it was quite noisy. Let’s look at the numbers:
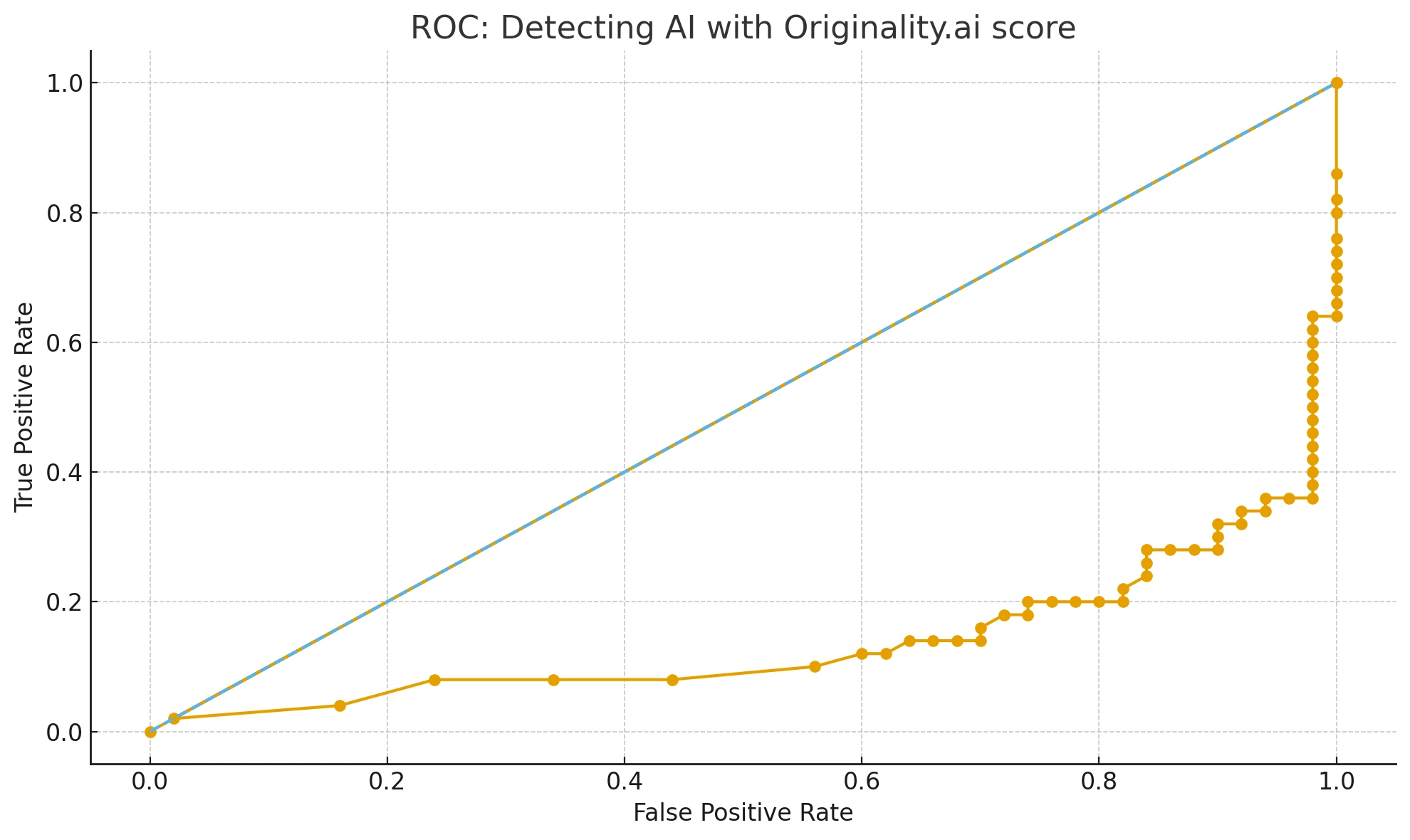
- On reversing ai_score to (100 − ai_score) as an “AI-likelihood,” we got an AUC (Area Under the ROC curve) of about 0.86. If you are wondering, AUC basically measures how well a score can separate AI from Human text: a score of 1 means perfect separation, and 0.5 means random.
- The human text had a mean ai_score of 97.2 (median 99.8), while Copilot’s mean ai_score was 44.7 (median 12.6). This is a very large gap.
- Statistics like Cohen’s d = 1.54 and KS distance = 0.62 also indicate a strong difference in the distributions of ai_score for human vs. Copilot text. In simpler terms, it means the two sets of scores are quite distinct.
Also Read: Is CoPilot Detectable by GPTZero?
Which threshold should you use?
Because the continuous ai_score is more reliable than the built-in label, you should pick a threshold based on your own needs:
- If you want to minimize false positives (like in high-stakes grading or compliance checks), then choose ai_score < 50. You will catch around 56% of Copilot text (that’s called recall), but your precision reaches ~97% (meaning if you say “AI,” you are almost always correct).
- If you want to catch more Copilot text (i.e., higher recall), you can push the threshold up to ai_score < 75 or even 90. This can pull in 70–84% of Copilot text, but you will end up with more human text flagged as well. In that case, you can do a manual review of flagged text to reduce mistakes.
One important detail
The “originality_ai_label” from Originality.ai did not match our ground truth well. It labeled almost all human text as “AI” (49 out of 50 times), and it labeled Copilot text as “AI” only 22 out of 50 times. So it was kind of backward in many cases, and ignoring it in favor of the continuous ai_score is the best strategy.
Limitations & caveats
Our dataset was just 100 snippets, so it is on the smaller side and from a single topic. If you plan to rely on Originality.ai for a wide range of text genres, you may get different results. Also, the AI detection technology (and AI text generators) will evolve over time, so you will need to do periodic checks to recalibrate your thresholds. If you use paraphrasing or translations on Copilot’s text, it might raise the ai_score more towards “human” levels.
Frequently Asked Questions
Q1. Does Originality.ai detect Copilot?
Yes, it is quite good at detecting Copilot. Our tests saw that if you pick the right threshold (like < 50 for ai_score), you have ~97% precision in tagging something as AI if it’s Copilot-generated.
Q2. What is AUC in simpler terms?
AUC, or Area Under the ROC curve, basically measures how good a score is at separating two things (e.g., AI vs. Human). If it’s close to 1, the separation is stronger. We found around 0.86, which means Originality.ai is pretty good at separating Copilot from Human.
Q3. Can I trust the built-in “originality_ai_label”?
You probably shouldn’t rely on that label alone. In our sample, it misclassified nearly all human text. Just take the continuous ai_score, pick your threshold, and you’ll get far more reliable results.
Q4. What if I post-process Copilot text (like paraphrase or translate)?
That often raises the ai_score, making it appear more “human.” So if you are detecting Copilot text that’s paraphrased heavily, it might slip through the cracks, especially at a weaker threshold.
Q5. Should I always trust AI detectors blindly?
No, detectors can have false-positives and false-negatives too. It is always better to combine automated tools with human review for high-stakes scenarios.
The Bottom Line
Copilot can be reliably detected by Originality.ai if you use the continuous ai_score the right way. If you want fewer false positives, pick a lower threshold. If you want to catch more AI content, pick a higher threshold. Also, ignoring the built-in label and focusing on the ai_score is the key takeaway. My own recommendation is that you regularly test your chosen threshold with real samples and adjust as needed—because both AI generators and AI detectors are constantly evolving.