![[STUDY] Is CoPilot Detectable by ZeroGPT? - The Surprising Truth!](/static/images/is-copilot-detectable-by-zerogptpng.webp)

As AI integration becomes the norm in development workflows, a critical question arises: Can ZeroGPT actually detect text generated by GitHub Copilot?
The short answer is yes, but with a massive catch. While the tool is effective at flagging AI-generated content, its scoring system is fundamentally counterintuitive. If you are relying on GitHub Copilot for documentation, comments, or technical writing, you need to understand how these detectors interpret its output. Keep reading to dive into our experimental data.
Why Does ZeroGPT Flag GitHub Copilot?
The technical reality is that Copilot, much like ChatGPT or Claude, is built on large language models (LLMs). It wasn't designed to bypass detection; it was designed for utility. Since ZeroGPT explicitly markets itself as a premier AI detection solution, it is specifically tuned to identify the linguistic patterns common to LLM outputs.
However, ZeroGPT provides two distinct metrics that often confuse users:
- Categorical Labels: A definitive "AI" or "Human" tag.
- Numeric Score: A percentage intended to represent human-likeness.
As our testing shows, these two metrics don't always play well together.
Also Read: Is Copilot Detectable?
The Experiment: Putting ZeroGPT to the Test
To find the truth, we conducted a controlled study using a dataset of 100 texts: 50 authored by humans and 50 generated by GitHub Copilot. Our goal was to see if ZeroGPT’s "Human Score" actually correlates with reality.
Related Reading: Is Copilot Detectable by GPTZero? A Comparison
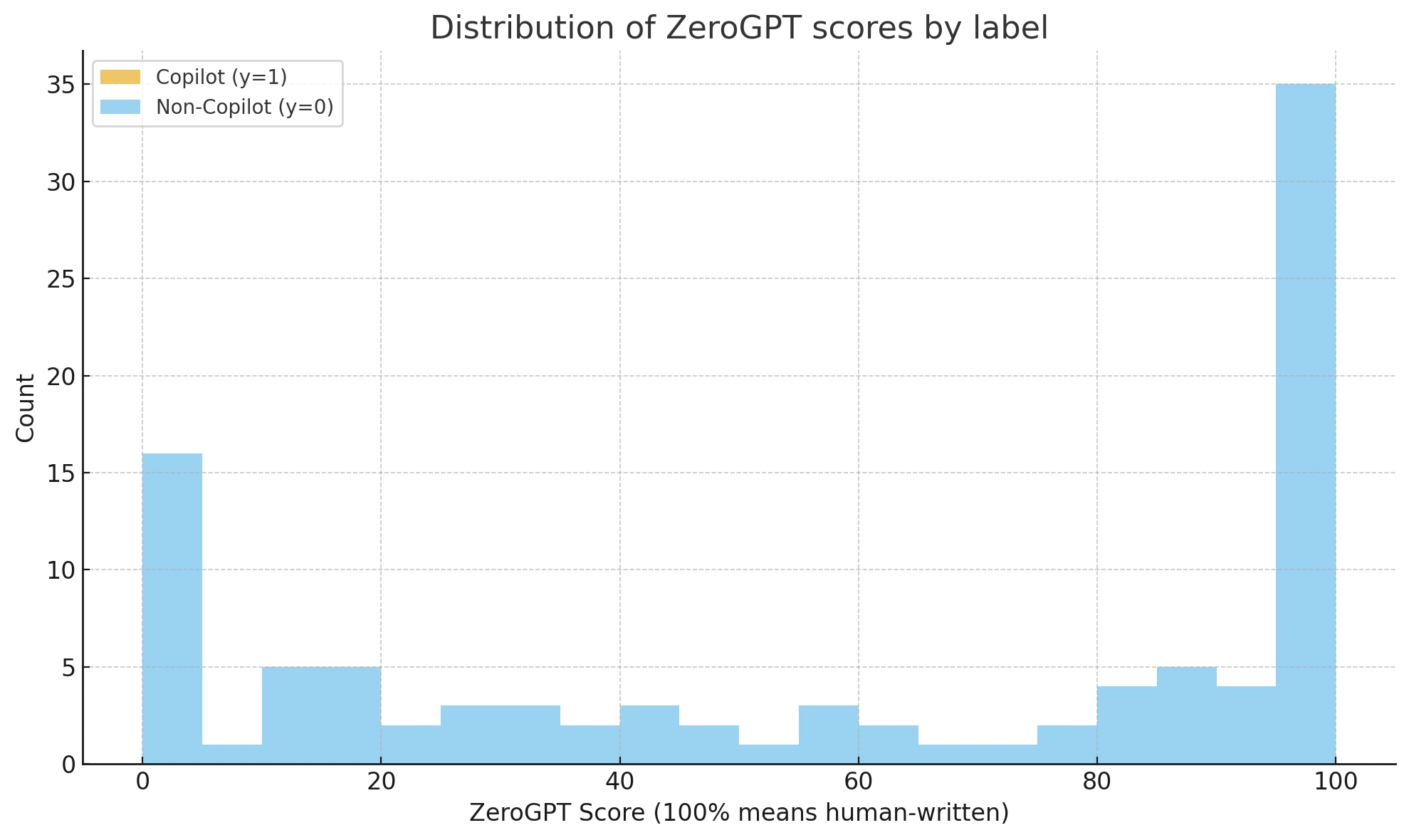
Key Findings: High Accuracy, Low Reliability
Our analysis revealed that while the tool is "accurate" in its labels, its internal logic for Copilot is almost entirely reversed.
1. Categorical Accuracy (The "Label" Success)
ZeroGPT performed surprisingly well at simply "guessing" the source of the text. With an 82% overall accuracy, it is a formidable gatekeeper.
| Metric | Value | What it Means |
|---|---|---|
| Recall (AI) | 90.0% | It caught 45 out of 50 Copilot texts. |
| Precision (AI) | 0.776 | When it says "AI," it's right 77% of the time. |
| F1 Score | 0.833 | A strong balance of precision and recall. |
The Confusion Matrix: ZeroGPT correctly identified 37 human texts and 45 AI texts. However, it flagged 13 human texts as AI (False Positives), which is a significant margin of error for professional environments.
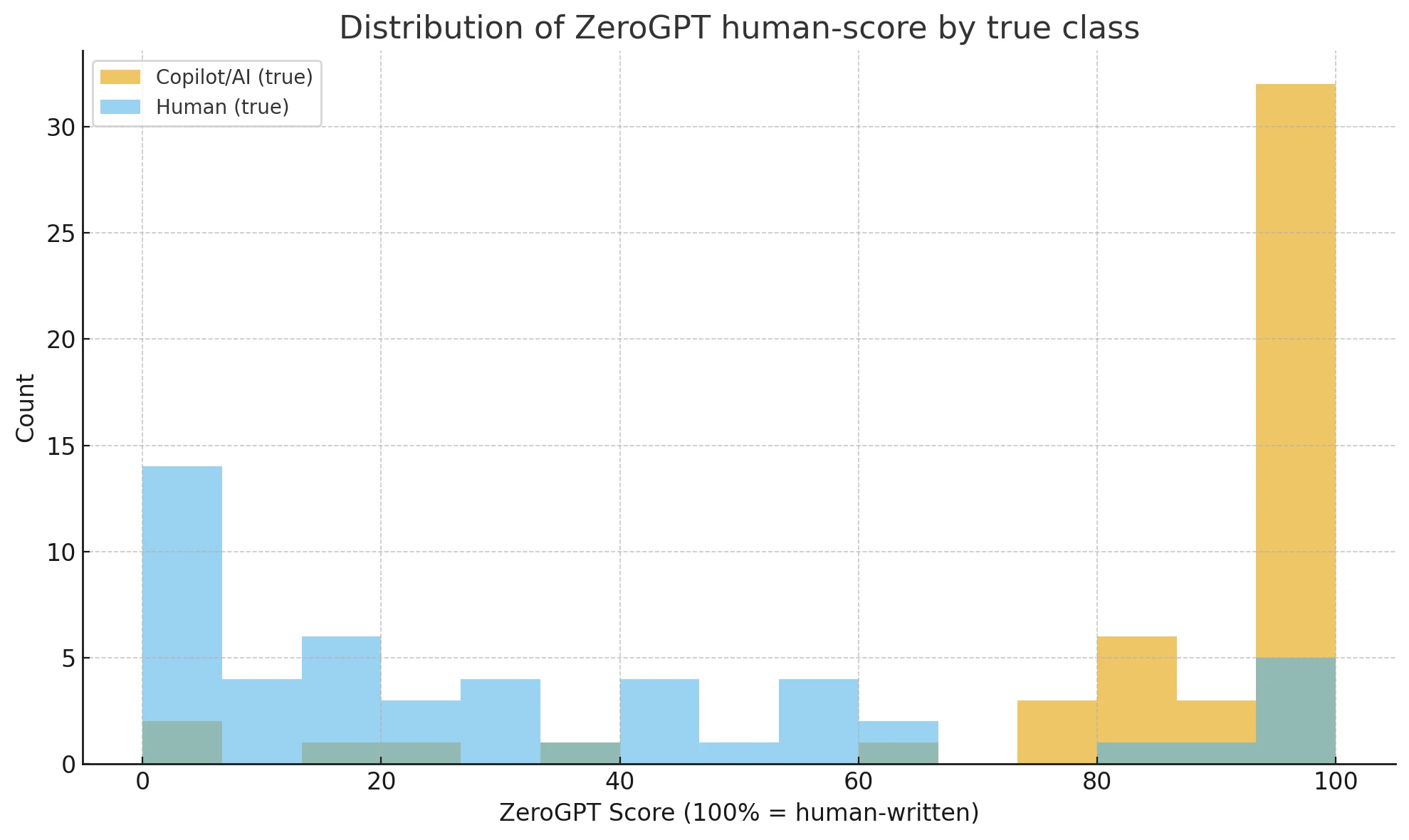
2. The Numeric "Human-Score" Paradox
Warning: Do not trust the percentage score for Copilot content.
In a bizarre twist, our data showed that the numeric scores were the inverse of reality:
- Mean Human-Score for Copilot: 86.2 (Rated highly "Human")
- Mean Human-Score for Humans: 32.4 (Rated highly "AI")
Essentially, if you look at the number alone, ZeroGPT thinks Copilot is more human than actual people. With an AUC of 0.12 on the ROC curve, the numeric score is statistically unreliable for detection purposes.
Frequently Asked Questions
Does ZeroGPT really detect Copilot?
Yes. In our testing, it correctly labeled AI-generated content 90% of the time. However, it also has a tendency to flag human writing as AI roughly 26% of the time.
Why is the numeric score contradictory?
This likely happens because Copilot’s training data (often public code and documentation) has a specific structure that triggers ZeroGPT’s "human" markers, even though its "classifier" recognizes the underlying LLM patterns.
Is using GitHub Copilot considered cheating?
It depends on context. While not inherently "cheating"—as it functions like an advanced autocomplete—it can violate academic or corporate policies. Is using Copilot cheating? Check your specific organization’s guidelines. Note that ZeroGPT typically flags natural language (comments and docs), not the logic of the code itself.
The Bottom Line
If you need to check if a document was written by GitHub Copilot, look only at ZeroGPT’s categorical label (the "AI" or "Human" tag). Ignore the numeric "human-score" entirely, as it is ironically reversed for this specific tool. For high-stakes decisions, never rely on a single detector—always verify the content manually.