![[HOT] Is Copilot Detectable by GPTZero?](/static/images/is-copilot-detectable-by-gptzeropng.webp)

As we all know it Copilot gets pretty easily detected by GPTZero. However, is it the same for all kinds of Copilot outputs? The short answer is YES. The longer answer is that the devil lies in the details. Keep reading to know more about it.
Why Copilot gets detected by GPTZero?
The simple answer is Copilot is not specifically made to bypass AI detectors like GPTZero. They never advertise “bypassing AI detectors” as a feature anywhere. Hence, if it is not made to accomplish this task it won't be able to do it. GPTZero is purpose-built to detect AI-generated text by analyzing certain text patterns, so it easily flags Copilot outputs in most cases.
The Dataset
GPTZero’s detection capabilities were tested on a set of 100 samples: 50 of them were AI text from Copilot, and the other 50 were entirely human-written. This balanced dataset was specifically created so that there were an equal number of AI and human texts.
Methodology
In this test, GPTZero provided a “Human Score” between 0–100% for each piece of text. Higher Human Score means GPTZero thinks it’s more likely to be human. To get the probability of being AI, we subtracted that from 1. After all the predictions were gathered, they compared them to the ground truth labels (i.e., whether each text was actually from Copilot or from a human). This made it possible to calculate a bunch of metrics, such as accuracy, precision, recall, F1, specificity, MCC, Brier score, and ROC AUC.
Anyone not familiar with these terms can think of them this way:
- Accuracy: Measures how many total items GPTZero correctly classified out of 100.
- Precision for AI: Out of all the texts labeled AI, how many were truly AI?
- Recall for AI: Out of all the AI texts in the dataset, how many were caught by GPTZero?
- F1: The balance between precision and recall. It’s another way to check overall performance.
- Specificity: Out of all the human texts, how many were correctly identified as human?
- MCC (Matthews Correlation Coefficient): A single number that captures how well GPTZero is doing overall, considering both AI and human classes.
- Brier score: A way to check how well GPTZero’s probability predictions match reality, a lower score is better.
- ROC AUC: Imagine a graph that shows how well GPTZero can rank AI texts higher than human ones. A value of 1.00 is a perfect score, while 0.50 would be random guessing.
Headline Results
In this test, GPTZero achieved 0.96 accuracy, which means it was right 96% of the time. The precision for AI was 1.00—yes, that’s perfect. This basically means GPTZero never flagged real human text as AI in this dataset. The recall for AI was 0.92, indicating it missed 4 Copilot outputs. Its ROC AUC was 0.987, which is near-perfect in ranking AI text more AI-like than human text.
At a more granular level:
- F1 score for AI: ~0.958
- Specificity for human: 1.00 (no false alarms)
- Balanced accuracy: 0.96
- MCC: 0.923
- Brier score: 0.047
What the Charts Reveal
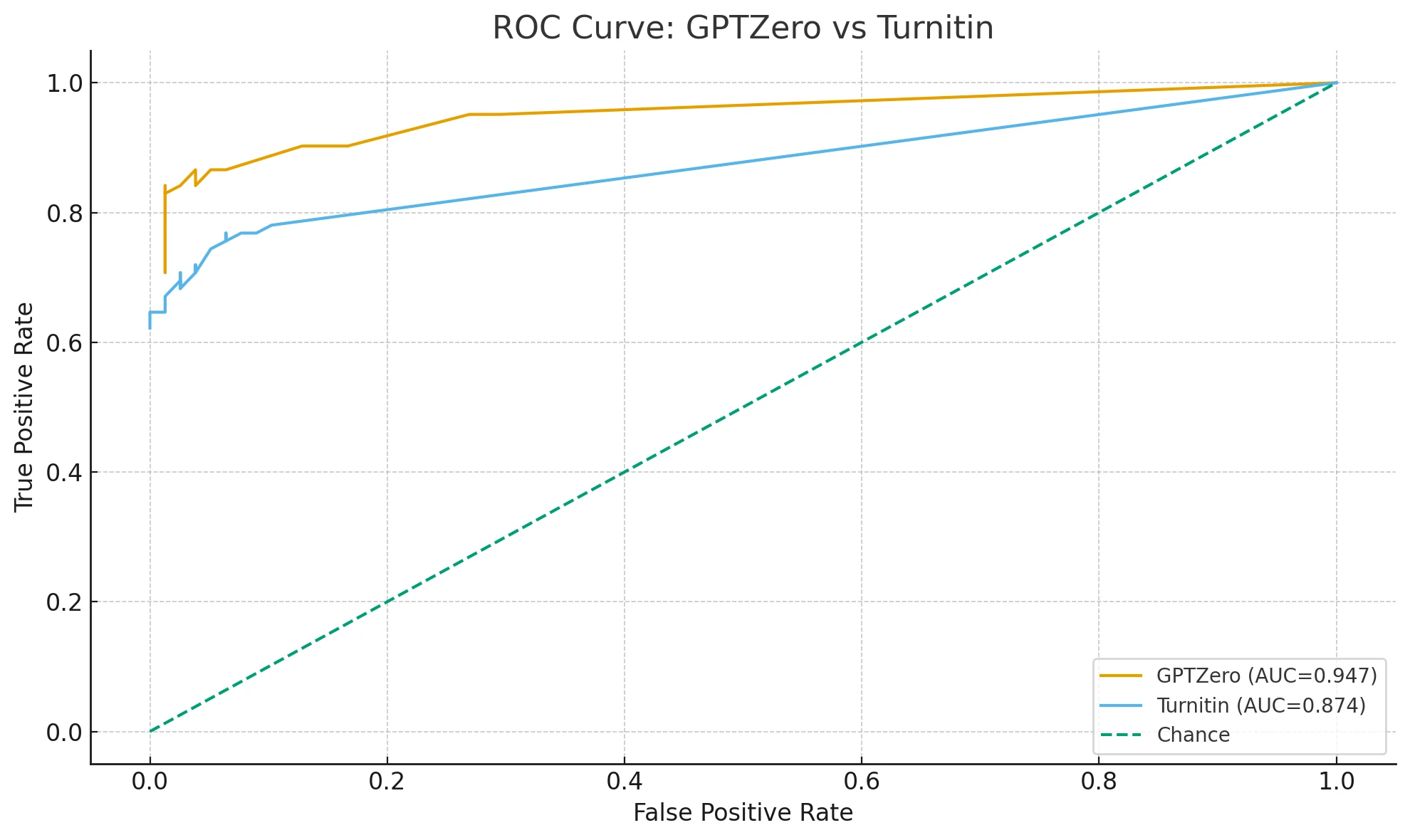
When we plotted all the probability scores, there was only a small overlap between Copilot and human text. Also, the calibration curve showed that when GPTZero says “this text is 90% AI,” it’s likely correct about 90% of the time. So GPTZero’s confidence in labeling AI text matched the actual outcomes pretty closely.
Threshold Tuning
GPTZero has a default threshold that decides whether a text is flagged as AI or not. By default, it sets the AI probability bar in a way that ensures zero false positives on human text. For those who want to catch more AI text, one can lower the threshold, but that also means there might be more false alarms on real human text.
Effect of Text Length
Performance remained consistently high across different document lengths. So short or long texts from Copilot were still mostly flagged correctly, and human documents of any size were left alone.
Limitations & Caveats
There are a few caveats to keep in mind here. First, GPTZero was only tested on Copilot outputs, so the results may differ with text from other AI tools. The dataset was balanced (50 AI, 50 human), which might not always be the case in real-world scenarios. Also, if a user heavily edits the AI output or uses rewriters specifically designed to fool detectors, GPTZero may not perform the same way. Finally, the writing style or domain might matter, and updates to GPTZero or Copilot can change future results.
Practical Takeaways
So, the test shows that Copilot text is highly detectable by GPTZero with no false alarms on human pieces at their default setting. Anybody wanting to reduce missed Copilot outputs can choose to lower the threshold, but that would boost the chances of incorrectly flagging human text. It is suggested to combine GPTZero’s findings with other checks (like metadata or version history) if something important depends on catching AI writing.
Ethics & Policy Considerations
Institutions that rely on GPTZero or similar detectors should be aware that no system is perfect. GPTZero’s high precision is good for fairness but also means some AI text might go unnoticed if the threshold is too high. People might want to create policies that allow appeals or re-checking of flagged text. Transparency is also important: telling writers that GPTZero is being used, explaining how it works, and informing them of their privacy rights.
The Bottom Line
GPTZero, under these test conditions, easily flagged Copilot text with high accuracy (96%) and perfect precision on human text. But it’s important to remember that there can be debates about real-world class imbalance, potential editing of AI outputs, and future changes in AI writing. Still, it is quite clear that Copilot outputs, at least in this controlled environment, are pretty reliably detectable by GPTZero.