![[HOT TAKE] How Accurate is GPTZero Compared to Turnitin?](/static/images/how-accurate-is-gptzero-compared-to-turnitinpng.webp)

Short answer: GPTZero comes out ahead.
Longer answer: the devil lies in the details, and the details actually matter here a lot.
TL;DR
- On this dataset (n=160), GPTZero outperforms Turnitin across every metric checked.
- Best achievable accuracy (pick the cut-off that maximizes accuracy on this dataset): GPTZero 91.3% vs Turnitin 85.0%.
- Ranking quality (ROC AUC): GPTZero 0.947 vs Turnitin 0.874.
- If someone just uses a naïve 0.5 cut-off: GPTZero 90.6% vs Turnitin 82.5%.
- Scores were standardized so that higher = “more AI-likely.” Turnitin already works like this. GPTZero’s “Score (100% means human-written)” was inverted to AI-likelihood as 1 − score/100.
What was tested (in plain English)?
- There were 160 texts total. Some are AI-written, some are human-written. Each detector gives a score.
- For Turnitin, a higher “AI score” already means “more AI.” No change needed.
- For GPTZero, the raw number is “how human it looks” (100% = looks like human). So it was flipped to create an AI-likelihood: AI-likelihood = 1 − (GPTZero score / 100). This makes both tools comparable: bigger number always means “more AI-ish.”
- Then different cut-offs (called thresholds) were tested to see where each tool performs best.
Also Read: Is Winston AI accurate like Turnitin?
What does “best threshold” even mean?
Think of a threshold as a line in the sand. If the AI-likelihood is above the line, call it AI; else call it human. Move the line up or down, and the tool will make different kinds of mistakes. The “best threshold” here means the one that gave the highest accuracy on these 160 samples. It does not mean it will be best everywhere, but it is the best this dataset can show.
Headline results
- Best achievable accuracy:
- GPTZero: 91.3%
- Turnitin: 85.0%
- ROC AUC (how well it ranks AI above human across all possible thresholds):
- GPTZero: 0.947
- Turnitin: 0.874
- At a naïve 0.5 threshold:
- GPTZero: 90.6%
- Turnitin: 82.5%
Also Read: How accurate is ZeroGPT compared to Turnitin?
What AUC means without the math?
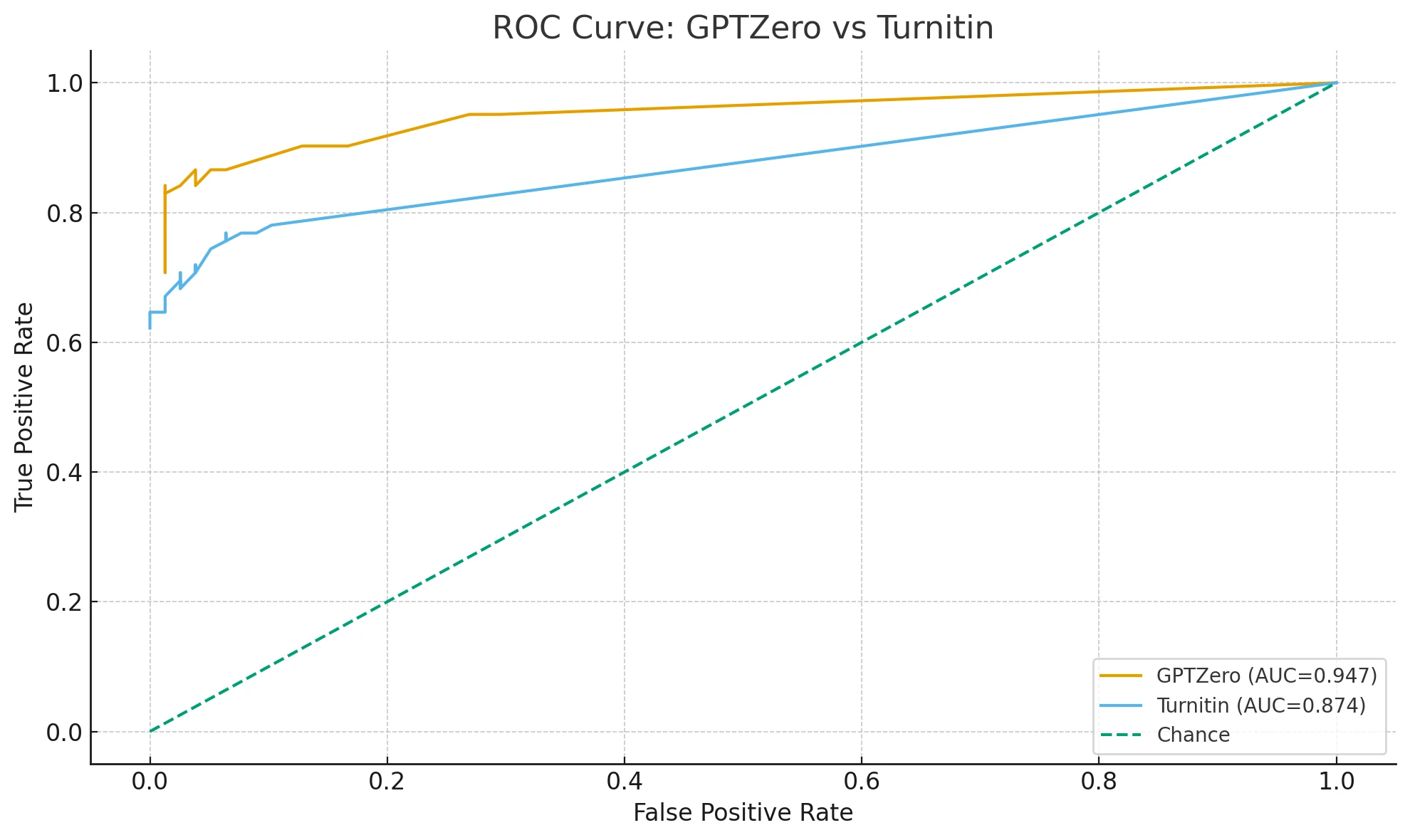
Imagine sorting all texts from “most AI-like” at the top to “most human-like” at the bottom. If a random AI text usually lands above a random human text in that list, that’s good ranking. AUC of 1.0 = perfect ranking. AUC of 0.5 = coin flip. So 0.947 is excellent, 0.874 is strong but clearly lower.
Also Read: How accurate is Turnitin?
Confusion at the best threshold (what the mistakes look like)
A “false positive” (FP) = a human text that got flagged as AI. This is the scary one for students and teachers alike.
A “false negative” (FN) = an AI text that slipped through as human.
At each tool’s own best threshold on this dataset:
- GPTZero (threshold ≈ 0.06 AI-likelihood):
- TP = 71 (AI correctly flagged)
- TN = 75 (human correctly passed)
- FP = 3 (human wrongly flagged)
- FN = 11 (AI wrongly passed)
- Turnitin (threshold ≈ 0.07 AI-likelihood):
- TP = 63
- TN = 73
- FP = 5
- FN = 19
In simple terms
GPTZero missed fewer AI pieces (11 vs 19) and also wrongly flagged fewer humans (3 vs 5). That is practically meaningful.
Both tools worked best at a surprisingly low cut-off around 0.06–0.07 AI-likelihood on this dataset. Not at 0.5. This alone explains why many folks see weird results with the defaults.
Why not just use 0.5 then?
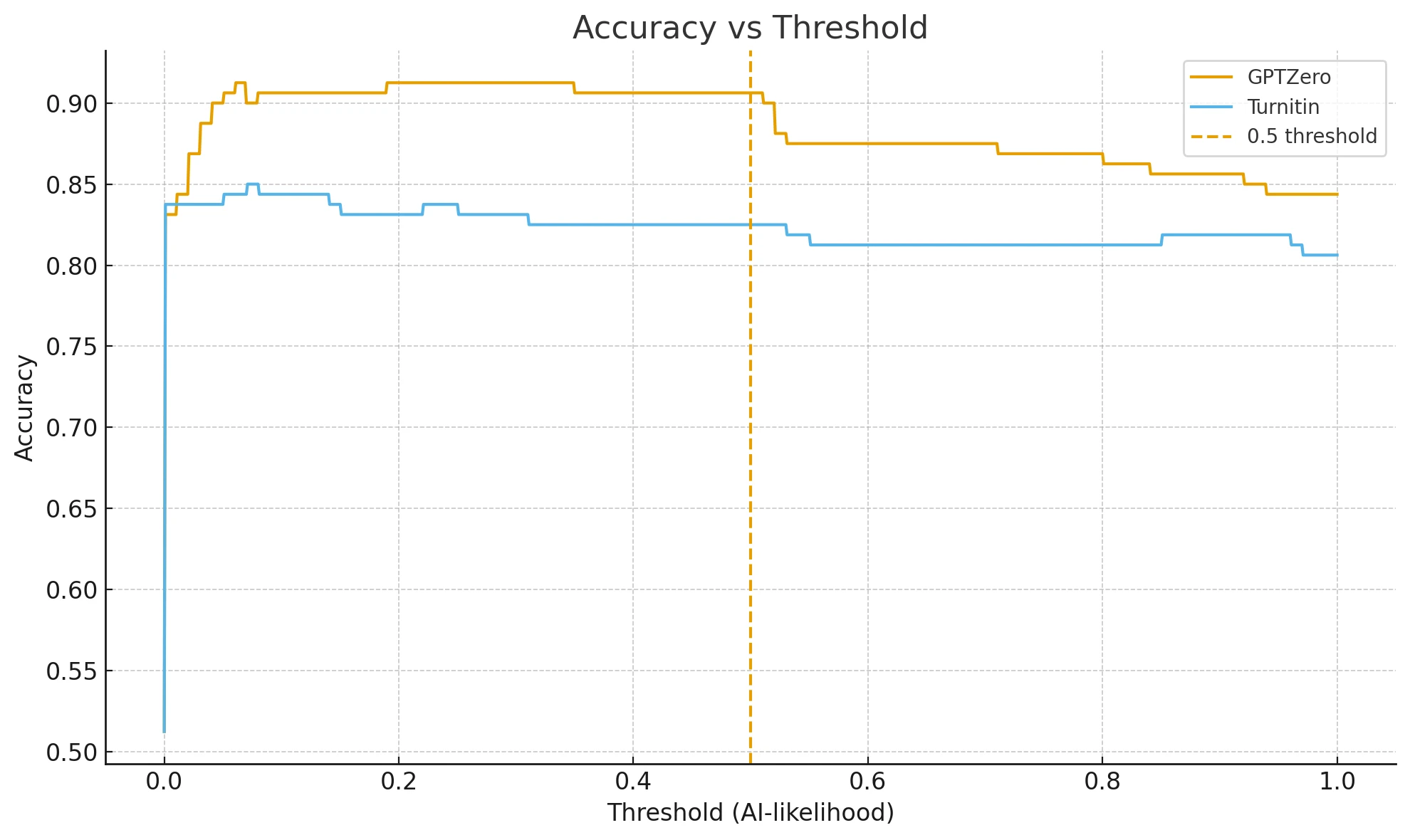
Because these raw scores look like percentages but they are not real probabilities. They are not “calibrated.” That means a 0.70 does not necessarily mean 70% chance it’s AI, it is just a higher score than 0.60. So, treat the score like a ranking signal, not a guarantee. Pick a threshold that matches the context. If a school hates false positives on human work, set a stricter threshold. If a system mainly wants to catch as much AI as possible, pick a looser one. Always test on held-out samples if possible.
What the numbers mean for a non-maths person?
- Accuracy: out of 100 decisions, how many were right. GPTZero made about 91 right calls, Turnitin about 85, when each was tuned to its sweet spot on these 160 texts.
- False positives: GPTZero had 3 humans flagged as AI, Turnitin had 5, at their best settings. Lower is better here.
- False negatives: GPTZero let 11 AI texts pass as human, Turnitin let 19 pass. Lower is better if the goal is catching AI.
Two practical takeaways
- Threshold selection matters a lot. On this dataset both detectors perform best around 0.06–0.07 AI-likelihood. A default 0.5 cut-off is sub-optimal (and it especially penalizes Turnitin).
- Calibration differs from detection. Even when scores look like percentages, treat them as ranking scores first. Tune thresholds (ideally on held-out data) to match how costly a false positive vs a false negative is in that specific setting. If needed, this can be rerun with a confusion-cost that heavily penalizes false positives on human text, and then pick the operating point that best fits the policy.
One opinion that is actually useful
If someone must pick one detector today based only on this dataset, pick GPTZero, but only with a tuned threshold near 0.06–0.07 rather than the default. The tuning step matters more than people think.
The Bottom Line
On these 160 samples, GPTZero is more accurate than Turnitin by about 6.3 percentage points at their own best thresholds (91.3% vs 85.0%). It also shows a higher ROC AUC (0.947 vs 0.874), fewer false positives, and fewer false negatives—all pointing to better overall discrimination between AI-written and human-written text on this dataset.
There is no magic single number that works everywhere. But what clearly emerges here is that:
- GPTZero ranks and classifies better on this test set, and
- Both tools need thresholds tuned to the actual risk tolerance, because 0.5 is not the right cut-off here.
That’s the detail that actually moves the needle in real use.